Flink 集群
1. 服务器规划
| 服务器 |
|---|
| h1、h4、h5 |
2. StandAlone 模式(不推荐)
2.1 会话模式
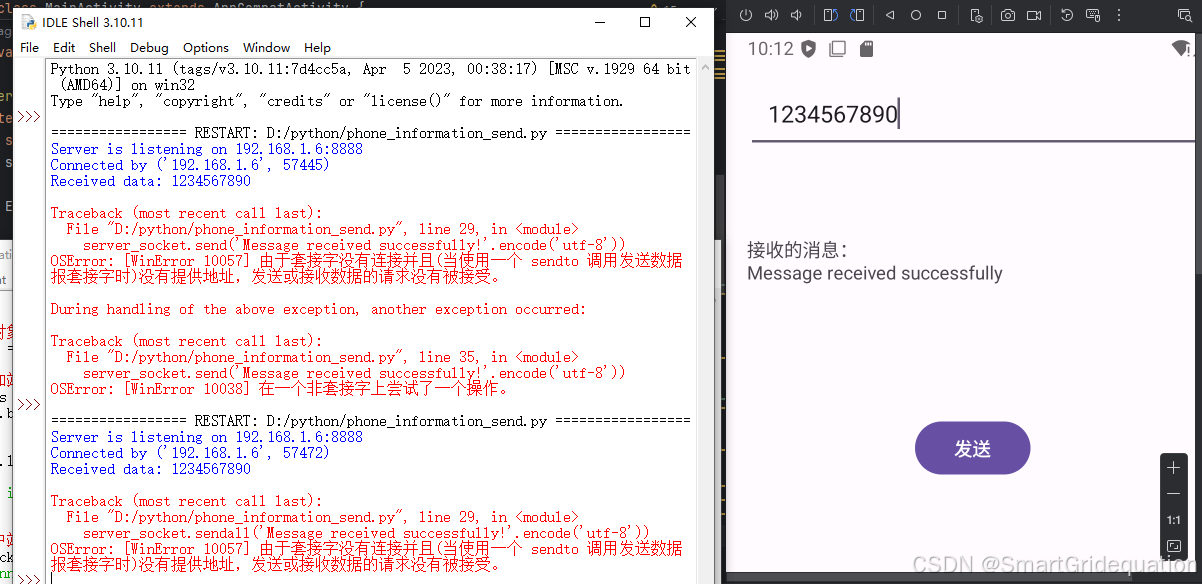
在h1操作
#1、解压
tar -zxvf flink-1.19.1-bin-scala_2.12.tgz -C /app/#2、修改配置文件
cd /app/flink-1.19.1/conf
vim conf.yaml
##内容:##
jobmanager:rpc:address: h1bind-host: 0.0.0.0
rest:address: h1bind-address: 0.0.0.0
# TaskManager节点地址.需要配置为当前机器名
taskmanager:bind-host: 0.0.0.0host: h1
#配置jdk地址
env:java:home: /usr/java/jdk-11.0.2
##内容结束###3、设置从节点
vim workers
##内容:##
h1
h4
h5
##内容结束###3、设置主节点
vim masters
##内容:##
h1:8081
##内容结束###4、把安装包分发
cd /app
scp -r flink-1.19.1/ h4:$PWD
scp -r flink-1.19.1/ h5:$PWD#5、分别在h4、h5上修改taskmanager.host为自己的地址
#h4:
taskmanager.host: h4#h5:
taskmanager.host: h5#6、在h1启动测试
#因为组件混合配置,flink在启动之前需要先配置java环境为jdk11
cd /app/flink-1.19.1/
vim bin/start-cluster.sh
##内容##
# 指定新的 JAVA_HOME use jdk11
export JAVA_HOME=/usr/java/jdk-11.0.2
export PATH=$JAVA_HOME/bin:$PATH
##内容结束##bin/start-cluster.sh#停止
bin/stop-cluster.sh#7、查看启动
jps
h1:8081 #浏览器
2.2 单作业模式
Flink 的 Standalone 集群并不支持单作业模式部署。因为单作业模式需要借助一些资源管理平台
2.3 应用模式
应用模式下不会提前创建集群,所以不能调用 start-cluster.sh 脚本。我们可以使用同样在 bin 目录下的 standalone-job.sh 来创建一个 JobManager
#上传jar包到lib目录
cd /app/flink-1.19.1/lib
rz -Ecd /app/flink-1.19.1/
bin/standalone-job.sh start --job-classname com.mywind.bg.wc.SocketStreamWordCount
bin/taskmanager.sh start#测试
nc -lk 7777
ni hao
wo hao#停止
bin/taskmanager.sh stop
bin/standalone-job.sh stop
3. Yarn 运行模式(推荐)
前面的配置文件不会影响
3.1 配置环境
#启动Hadoop集群(HDFS、YARN)
vim /etc/profile.d/my_env.sh
##内容##
HADOOP_HOME=/opt/cloudera/parcels/CDH/
export PATH=$PATH:$HADOOP_HOME/bin
export HADOOP_CONF_DIR=/etc/hadoop/conf
export HADOOP_CLASSPATH=`hadoop classpath`#export HADOOP_CONF_DIR=/etc/hadoop/conf
#export HBASE_CONF_DIR=/etc/hbase/conf
##内容结束##
source /etc/profile.d/my_env.shscp /etc/profile.d/my_env.sh h4:/etc/profile.d/
scp /etc/profile.d/my_env.sh h5:/etc/profile.d/
#分别到h4、h5 source
source /etc/profile.d/my_env.sh#h1、h4、h5创建用户mflink
useradd mflink
passwd mflink
mflink
mflink#创建提交作业的用户目录,并设置权限
sudo -u hdfs hdfs dfs -mkdir /user/mflink
sudo -u hdfs hdfs dfs -chown mflink:supergroup /user/mflink3.2 会话模式(测试使用)
YARN 的会话模式与独立集群略有不同,需要首先申请一个 YARN 会话(YARN Session)来启动 Flink 集群
#执行脚本命令向YARN集群申请资源,开启一个YARN会话,启动Flink集群
cd /app/flink-1.19.1/
#以后都用mflink用户提交作业
su mflink
bin/yarn-session.sh -nm test #建议后台提交(加参数 -d)
#in/yarn-session.sh -d -nm yarn-session-test#提交作业测试
./bin/flink run examples/streaming/WordCount.jar
3.3 单作业模式
在 YARN 环境中,由于有了外部平台做资源调度,所以我们也可以直接向 YARN 提交一个单独的作业,从而启动一个 Flink 集群
cd /app/flink-1.19.1/conf/
vim conf.yaml
##内容##
classloader:check-leaked-classloader: false
####
cd /app/flink-1.19.1/
bin/flink run -d -t yarn-per-job examples/streaming/WordCount.jar
3.4 应用模式(生产使用)
应用模式同样非常简单,与单作业模式类似,直接执行 flink run-application 命令即可
3.4.1 命令行提交
cd /app/flink-1.19.1/
bin/flink run-application -t yarn-application examples/streaming/WordCount.jar
3.4.2 上传 HDFS 提交
通过 yarn.provided.lib.dirs 配置选项指定位置,将 flink 的依赖上传到远程
cd /app/flink-1.19.1/
#创建flink文件目录
sudo -u hdfs hdfs dfs -mkdir /flink-dist
sudo -u hdfs hdfs dfs -put lib/ /flink-dist
sudo -u hdfs hdfs dfs -put plugins/ /flink-dist#创建jar包目录
sudo -u hdfs hdfs dfs -mkdir /flink-dist/flink-jars
sudo -u hdfs hdfs dfs -put examples/streaming/WordCount.jar /flink-dist/flink-jars#执行任务
bin/flink run-application -t yarn-application -Dyarn.provided.lib.dirs="hdfs://namenode1/flink-dist/" hdfs://namenode1/flink-dist/flink-jars/WordCount.jarflink 的依赖和作业 jar 预先上传到 HDFS,不需要单独发送到集群,可以让作业提交更加轻量






![[生物信息]单细胞数据分析入门学习笔记1](https://i-blog.csdnimg.cn/direct/48a3f19f38af43f8b7eb2462dbac01b0.png)