大家好,文本嵌入技术能够将文字信息转换成高维向量表示的数字,提供了一种理解和处理文本数据的新方式,帮助我们更好地理解和处理文本数据。这些向量能够捕捉文本的深层特征,进而支持多种应用,比如理解语义、进行文本分类、聚类、信息检索,甚至优化搜索结果排序等。本文将介绍优化文本嵌入方法,据不同的应用需求,灵活调整嵌入向量的维度,大幅提升检索效率。
1.文本嵌入
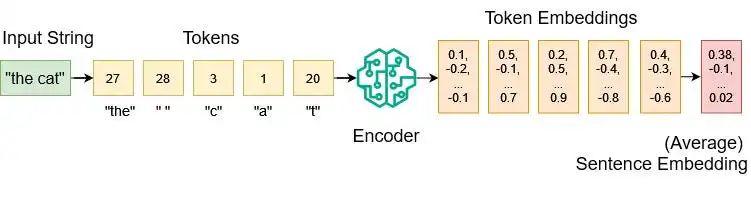
从输入字符串到句子嵌入
定义一个词汇表,这个表把所有可能输入的字符,包括字母、特殊符号、短词和子词,都映射到整数值。比如:
{"a": 1,"b": 2,"c": 3,..."z": 26,"the": 27," ": 28
}
经过标记化处理后,可以将令牌(token)列表输入到编码器模型中。这个模型经过大量数据的训练,能够将每个令牌转换为高维数值向量嵌入。
例如,OpenAI的text-embedding-3-large模型的嵌入向量输出维度为3072。如果想要获得单个句子嵌入,需要从多个令牌嵌入中提取信息,常见的做法是对所有令牌嵌入求平均值。
2.套娃嵌入
套娃嵌入(Matryoshka Representation Learning)是一种先进的文本表示技术,由华盛顿大学、谷歌研究院和哈佛大学的学者们在2022年发表的论文《Matryoshka Representation Learning》中首次提出。
套娃嵌入技术能够在单一的嵌入向量中嵌入多个层次的信息,它不是只训练一个单一维度为1024的嵌入向量,而是同时优化一组不同大小的维度,如1024、512、256、128、64等。
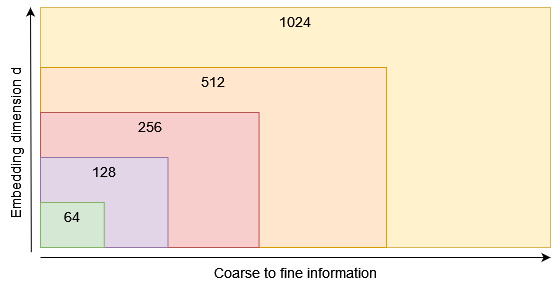
这样的设计让嵌入向量像套娃一样,外层包含着较为概括的信息,而内层则逐渐包含更细致的信息。这种结构能够在几乎不影响性能的情况下,根据实际需求来调整嵌入向量的长度,从而更好地适应各种不同的应用环境。
3.套娃嵌入的重要性
假设要在向量数据库中存储一大批文本嵌入向量。每个嵌入有 d 个维度,每个维度都是一个32位的浮点数。这样算下来,存储空间就需要n * d * 4 个字节。
如果想要计算这些向量的相似性,如点积或余弦相似性(只是归一化的点积),维度 d 越高,需要做的数学计算量就越多。
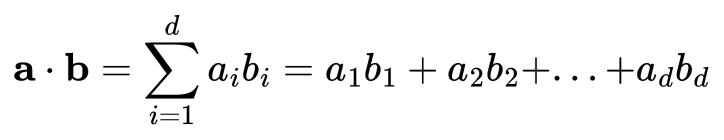
点积公式
有了MRL技术,如果我们更看重节省内存和提高处理速度,从而减少成本,可能只取前64个维度来用。如果追求最佳的性能,那就用上所有的维度,当然也可以选择一个折中的维度数。
总的来说,MRL技术让LLM用户能够在嵌入向量的存储成本和性能之间找到一个平衡点。
4.Nomic AI的MRL应用
Nomic的套娃文本嵌入模型nomic-embed-text-v1.5是使用 matryoshka_dims = [768,512,256,128,64] 训练的。该模型在Hugging Face上公开可用。
这个编码器模型还支持多种前缀,比如[search_query, search_document, classification, clustering],这意味着它能针对搜索查询、搜索文档、文本分类和聚类等特定任务,提供更为精准的嵌入结果。
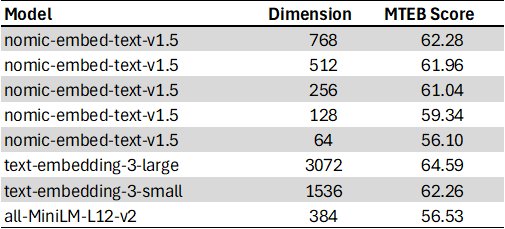
以下是nomic-embed-text-v1.5在大规模文本嵌入基准(MTEB)上的表现:
使用PyTorch和Sentence Transformers库在Python中实现该模型:
!pip install torch sentence_transformers einopsimport torch
from sentence_transformers import SentenceTransformermodel = SentenceTransformer("nomic-ai/nomic-embed-text-v1.5",device=device,trust_remote_code=True,prompts={"search_query": "search_query: ","search_document": "search_document: ","classification": "classification: ","clustering": "clustering: ",},
)def embed_sentences(model: SentenceTransformer,sentences: list[str],prompt_name: str,matryoshka_dim: int,device: str,
):assert matryoshka_dim <= 768, "maximum dimension for nomic-embed-text-v1.5 is 768"embeddings = model.encode(sentences, prompt_name=prompt_name, device=device, convert_to_tensor=True)embeddings = torch.nn.functional.layer_norm(embeddings, normalized_shape=(embeddings.shape[1],))embeddings = embeddings[:, :matryoshka_dim]embeddings = torch.nn.functional.normalize(embeddings, p=2, dim=1)return embeddings.cpu()
使用 matryoshka_dim 参数,可以将原本768维的嵌入向量进行截断,然后归一化新的嵌入向量。
现在,可以设置期望的维度,对维基百科上的一些文本内容以及相关问题进行编码,以供检索增强生成(RAG)的应用场景使用:
matryoshka_dim = 64wikipedia_texts = ["The dog (Canis familiaris or Canis lupus familiaris) is a domesticated descendant of the wolf.","Albert Einstein was born in Ulm in the Kingdom of Württemberg in the German Empire, on 14 March 1879.","Einstein excelled at physics and mathematics from an early age, and soon acquired the mathematical expertise normally only found in a child several years his senior.","Werner Karl Heisenberg was a German theoretical physicist, one of the main pioneers of the theory of quantum mechanics, and a principal scientist in the Nazi nuclear weapons program during World War II.","Steven Paul Jobs (February 24, 1955 - October 5, 2011) was an American businessman, inventor, and investor best known for co-founding the technology giant Apple Inc.","The cat (Felis catus), commonly referred to as the domestic cat or house cat, is the only domesticated species in the family Felidae.",
]question = ["Where was Albert Einstein born?"]question_embedding = embed_sentences(model,sentences=question,prompt_name="search_query",matryoshka_dim=matryoshka_dim,device=device,
)document_embeddings = embed_sentences(model,sentences=wikipedia_texts,prompt_name="search_document",matryoshka_dim=matryoshka_dim,device=device,
)
print(f"document_embeddings.shape: {document_embeddings.shape}")
print(f"question_embedding.shape: {question_embedding.shape}")
>> document_embeddings.shape: torch.Size([6, 64])
>> question_embedding.shape: torch.Size([1, 64])
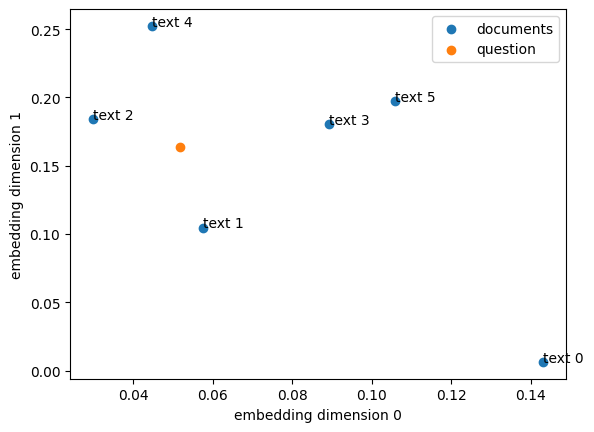
可以用散点图可视化套娃文本嵌入的前两个维度,不过需要注意的是,这个嵌入模型并没有专门针对二维展示进行优化。
将文档嵌入存储在向量数据库中,这里使用的是Faiss。Faiss是Meta Research的开源库,用于高效相似性搜索和密集向量的聚类。
!pip install faiss-cpu
import faiss
index = faiss.IndexFlatIP(matryoshka_dim)
index.add(document_embeddings)
通过“精确搜索内积”的方法,构建一个名为IndexFlatIP的向量数据库,它使用的是点积相似性度量。因为使用的嵌入向量已经过归一化处理,所以点积和余弦相似性在这种情况下是等价的。
index 现在是一个包含六个文本嵌入的向量数据库:
print(index.ntotal)
>> 6
搜索与我们的问题最相似的嵌入,并检索前k个结果:
distances, indices = index.search(question_embedding, k=6)
print(indices)
print(distances)
>> [[1 2 3 4 0 5]]
>> [[0.9633528 0.729192 0.63353264 0.62068397 0.512541 0.43155164]]
最相似的文本在数据库中的索引是1,相似性得分为0.96(最高是1.0)。
# results with d=64
print(question)
print(wikipedia_texts[1])
>> ['Where was Albert Einstein born?']
>> 'Albert Einstein was born in Ulm in the Kingdom of Württemberg in the German Empire, on 14 March 1879.'
这里也用matryoshka_dim=768重新运行了代码,得到了类似的结果,然而更高的维度需要更多的内存和更多的计算。
# results with d=768
print(indices)
print(distances)
>> [[1 2 4 3 0 5]]
>> [[0.92466116 0.645744 0.54405797 0.54004824 0.39331824 0.37972206]]
5.MRL&量化
如果想要进一步压缩我们的嵌入,可以使用MRL和二进制向量量化。二进制量化将嵌入向量中所有大于零的数字转换为一,其余的转换为零。

使用二进制量化,一个维度为 d 的嵌入向量只需要 d / 8 字节的内存,这比32位浮点数的 d * 4 字节减少了32倍,然而这种减少是以性能为代价的。
在训练过程中,嵌入模型采用了套娃损失函数,以优化多个嵌入维度。通过套娃表示学习,LLM用户可以在减少文本嵌入大小和接受轻微性能损失之间进行权衡。
较小的嵌入向量占用的内存更少,计算量也更小,长期来看有助于节省成本。同时,它们的计算速度也更快,因此具有更高的检索速度,这对于像RAG这样的应用程序来说尤其重要。