# predict.pyimport numpy as np
import torch
import torch.nn as nn
from sklearn.preprocessing import OneHotEncoder
from model import FCNet
import pickle
import os
import sklearn
from packaging import version# 自定义函数用于加载模型和编码器
def load_model(model_path):if not os.path.exists(model_path):raise FileNotFoundError(f"模型文件 '{model_path}' 不存在。")# 加载模型文件checkpoint = torch.load(model_path, map_location=torch.device('cpu'))encoder = checkpoint['encoder']amino_acids = checkpoint['amino_acids']# 定义模型feature_dim1 = 3 # 最多三个氨基酸feature_dim2 = len(amino_acids) + 1 # one-hot + 数值特征model = FCNet(feature_dim1, feature_dim2)model.load_state_dict(checkpoint['model_state_dict'])model.eval()return model, encoder, amino_acids# 自定义函数进行预测
def predict(model, encoder, amino_acids, single_dict, aa_input):# 检查输入类型和长度if not isinstance(aa_input, str):raise ValueError("输入的氨基酸组合必须是字符串,例如 'A', 'AC', 'ACD'。")aa_input = aa_input.upper()length = len(aa_input)if length == 0 or length > 3:raise ValueError("输入的氨基酸组合长度必须在1到3之间。")# 填充至三个氨基酸if length == 1:aa_triplet = aa_input + '--'elif length == 2:aa_triplet = aa_input + '-'else:aa_triplet = aa_input# 检查是否所有氨基酸都在编码器中for aa in aa_triplet:if aa not in amino_acids:raise ValueError(f"氨基酸 '{aa}' 不在编码器的氨基酸列表中。")# 独热编码try:one_hot1 = encoder.transform([[aa_triplet[0]]])[0]one_hot2 = encoder.transform([[aa_triplet[1]]])[0]one_hot3 = encoder.transform([[aa_triplet[2]]])[0]except Exception as e:raise ValueError(f"无法对氨基酸组合 '{aa_triplet}' 进行编码。错误信息:{e}")# 读取单个氨基酸的数值特征value1_aa1 = single_dict.get(aa_triplet[0], 0.0)value1_aa2 = single_dict.get(aa_triplet[1], 0.0)value1_aa3 = single_dict.get(aa_triplet[2], 0.0)# 构建特征向量feature_part1 = np.concatenate([one_hot1, [value1_aa1]])feature_part2 = np.concatenate([one_hot2, [value1_aa2]])feature_part3 = np.concatenate([one_hot3, [value1_aa3]])feature = np.stack([feature_part1, feature_part2, feature_part3]) # (3, N +1)# 转换为张量并添加 batch 维度feature_tensor = torch.tensor(feature, dtype=torch.float32).unsqueeze(0) # (1, 3, N +1)# 进行预测with torch.no_grad():output = model(feature_tensor)# 获取预测结果predicted_values = output.squeeze(0).numpy() # (3,)return predicted_valuesdef main():import pandas as pd # 确保 pandas 已导入# 模型文件路径model_path = '../models/model.pth'# 加载模型、编码器和氨基酸列表try:model, encoder, amino_acids = load_model(model_path)except Exception as e:print(f"加载模型失败:{e}")return# 加载单个氨基酸的数值字典single_dict_path = '../data/single_dict.pkl'if not os.path.exists(single_dict_path):# 如果未保存,读取 single.csv 并创建字典,然后保存single_csv = '../data/single.csv'if not os.path.exists(single_csv):raise FileNotFoundError(f"单个氨基酸数据文件 '{single_csv}' 不存在。")single_df = pd.read_csv(single_csv, header=None, names=['AminoAcid', 'Value'])single_dict = single_df.set_index('AminoAcid')['Value'].to_dict()# 保存字典with open(single_dict_path, 'wb') as f:pickle.dump(single_dict, f)else:with open(single_dict_path, 'rb') as f:single_dict = pickle.load(f)# 提示用户输入氨基酸组合while True:aa_input = input("请输入氨基酸组合(例如 'A'、'AC'、'ACD'),输入 'exit' 退出:").strip().upper()if aa_input.lower() == 'exit':print("退出预测程序。")breaktry:predicted = predict(model, encoder, amino_acids, single_dict, aa_input)# 根据输入长度,打印对应数量的值length = len(aa_input)if length == 1:print(f"预测结果 - Value1: {predicted[0]:.6f}")elif length == 2:print(f"预测结果 - Value1: {predicted[0]:.6f}, Value2: {predicted[1]:.6f}")else:print(f"预测结果 - Value1: {predicted[0]:.6f}, Value2: {predicted[1]:.6f}, Value3: {predicted[2]:.6f}")except Exception as e:print(f"错误:{e}")if __name__ == '__main__':main()predict3
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.xdnf.cn/news/19408.html
如若内容造成侵权/违法违规/事实不符,请联系一条长河网进行投诉反馈,一经查实,立即删除!相关文章

ubuntu下连接了192.168.1.x和192.168.2.x两个网络段,如何让这个两个网段互相通信?
在 Ubuntu 上连接两个网络段(如 个人终端A 192.168.1.10 和 个人终端B 192.168.2.10),需要配置路由和网络转发功能,使这两个网段能够相互通信。以下是实现方法:
步骤 1:确认网络配置
1. 确保 Ubuntu 机器…
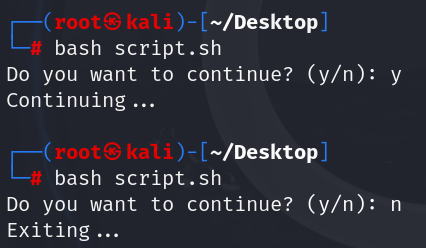
Shell脚本5 -- 脚本与用户交互read
声明: 本文的学习内容来源于B站up主“泷羽sec”视频【shell编程(4)脚本与用户交互以及if条件判断】的公开分享,所有内容仅限于网络安全技术的交流学习,不涉及任何侵犯版权或其他侵权意图。如有任何侵权问题,…

mysql5.7主从问题记录
项目运行一段时间后突然打印如下异常信息。 由于现场环境和数据库是客户提供,看异常提示一直以为是代码问题,导致锁表。
通过逐步排查之后发现,是binlog把磁盘占满了,让客户的DBA设置了一下就恢复。
当设置了主从同步之后&…

使用卷积自编码器进行图像重构
1. 自编码器简介
自编码器(Autoencoder)是一种无监督学习的神经网络模型,旨在学习数据的有效表示。自编码器的主要组成部分包括编码器和解码器,二者共同工作以实现数据的压缩和重构。以下是自编码器的详细介绍:
1.1 …

鸿蒙实战:页面跳转传参
文章目录 1. 实战概述2. 实现步骤2.1 创建鸿蒙项目2.2 编写首页代码2.3 新建第二个页面 3. 测试效果4. 实战总结 1. 实战概述
本次实战,学习如何在HarmonyOS应用中实现页面间参数传递。首先创建项目,编写首页代码,实现按钮跳转至第二个页面并…

恶意代码分析入门--静态分析(chapter1_Lab01-01)
恶意代码分析-工具收集 - 17bdw - 博客园 (cnblogs.com) 实验环境:Lab 1-1 这个实验使用Lab01-01.exe和Lab01-01.dll文件,使用本章描述的工具和技术来获取 关于这些文件的信息。 操作环境 操作场景: windows xp sp3 实验工具: PEi…

【操作系统不挂科】<信号量(9)>选择题(带答案与解析)
前言 大家好吖,欢迎来到 YY 滴操作系统不挂科 系列 ,热烈欢迎! 本章主要内容面向接触过C的老铁 本博客主要内容,收纳了一部门基本的操作系统题目,供yy应对期中考试复习。大家可以参考 本章为选择题题库,试卷…

服务器数据恢复—raid5阵列故障导致上层系统分区无法识别的数据恢复案例
服务器数据恢复环境: 某品牌DL380服务器,服务器中三块SAS硬盘组建了一组raid5阵列。服务器安装Windows Server操作系统,划分了3个分区,D分区存放数据库,E分区存放数据库备份。
服务器故障: RAID5阵列中有一…

【ARM】MDK在debug模式下的Registers窗口包含哪些内容
【更多软件使用问题请点击亿道电子官方网站】
1、 文档目标
解决客户对于Debug模式下,对于Registers窗口包含的内容了解。 2、 问题场景
Registers窗口是在进入到debug模式下后,就会出现一个窗口。窗口中包含了很多寄存器信息。但是对于具体内容不了解…


高项 - 项目进度管理
个人总结,仅供参考,欢迎加好友一起讨论 博文更新参考时间点:2024-12
高项 - 章节与知识点汇总:点击跳转 文章目录 高项 - 项目进度管理进度管理ITO规划监控 管理基础项目进度计划的定义和总要求管理新实践用户故事(补…

【数据结构】【线性表】【练习】反转链表
申明 该题源自力扣题库19,文章内容(代码,图表等)均原创,侵删!
题目 给你单链表的头指针head以及两个整数left和right,其中left<right,请你反转从位置left到right的链表节点&…

鸿蒙原生应用开发元服务 元服务是什么?和App的关系?(保姆级步骤)
元服务是什么?和App的关系?
元服务是是一种HarmonyOS轻量应用形态,用户无需安装即可使用,具备随处可及、服务直达、自由流转的特征。
元服务是可以独立部署和运行的程序实体,独立于应用,不依赖应用可独立…

Redis中的String数据类型及相关命令
[经典面试题] redis虽然是单线程模型,为什么效率还这么高?速度这么快呢?
原因:1、redis主要访问内存,数据库则是主要访问硬盘。 2、redis的核心功能,比数据库的核心功能更简单。数据库对于数据的CRUD&…

远程管理不再难!树莓派5安装Raspberry Pi OS并实现使用VNC异地连接
前言:大家好!今天我要教你们如何在树莓派5上安装Raspberry Pi OS,并配置SSH和VNC权限。通过这些步骤,你将能够在Windows电脑上使用VNC Viewer,结合Cpolar内网穿透工具,实现长期的公网远程访问管理本地树莓派…

本地部署 Chat Nio
本地部署 Chat Nio 0. 引言1. 本地部署2. 访问 Chat Nio3. 渠道设置4. 聊天 0. 引言
Chat Nio 的功能:
🤖️ 丰富模型支持: 多模型服务商支持 (OpenAI / Anthropic / Gemini / Midjourney 等十余种格式兼容 & 私有化 LLM 支持)🤯 美观 …

C# OpenCV 通过高度图去筛选轮廓
//输入图像
threshCropMap.ImWrite("D:\\test\\threshCropMap_BeforeFilterByBlob.bmp");
//设定我们要筛选的高度
var ResultHeight 60;
//创建对应高度的图像,由于是高度信息图,所有要使用32位来存放数据
Mat mat new Mat(filter.Rows, fi…

23.UE5删除存档
2-25 删除存档制作_哔哩哔哩_bilibili
按照自己的风格制作删除按钮 这样该行的存档就被从存档列表中删除了,并且实际存档(我的存档蓝图)中也被删除了 但是存在一个问题,如果存档数据中存在索引为: 0 1 2 3的存档,当索…

【graphics】图形绘制 C++
众所周知,周知所众,图形绘制对于竞赛学僧毫无用处,所以这个文章,专门对相关人员教学(成长中的码农、高中僧、大学僧)。
他人经验教学参考https://blog.csdn.net/qq_46107892/article/details/133386358?o…
