DeepSeek+Dify之五工作流引用API案例
DeepSeek+Dify之四Agent引用知识库案例
文章目录
- 背景
- 整体流程
- 测试数据
- 用到的节点
- 开始
- HTTP请求
- LLM
- 参数提取器
- 代码执行
- 结束
- 实现步骤
- 1、新建工作流
- 2、开始节点
- 3、Http请求节点
- 4、LLM节点(大模型检索)
- 5、参数提取器节点(提取大模型检索后数据)
- 6、代码执行节点(数据json化)
- 7、结束节点
- 测试
- 发布
- 导出
背景
可通过API,针对用户输入的请求数据,借助工作流以及 Deepseek 大模型的检索与重排序功能,提升召回数据的质量。
整体流程
测试数据

用到的节点
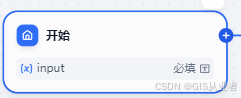
开始
功能:定义一个 workflow 流程启动的初始参数
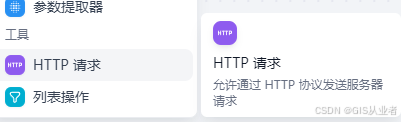
HTTP请求
功能:允许通过 HTTP 协议发送服务器请求
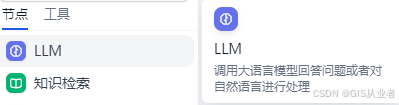
LLM
功能:通过上传的excel格式的文档,通过deepseek大模型的检索和重排序,提升召回文档数据的质量
参数提取器
功能:利用 LLM 从自然语言内推理提取出结构化参数,用于后置的工具调用或 HTTP 请求。
代码执行
功能:执行一段 Python 或 NodeJS 代码实现自定义逻辑
结束
功能:定义一个 workflow 流程的结束和结果类型
实现步骤
1、新建工作流
下面就是从开始节点开始添加节点了
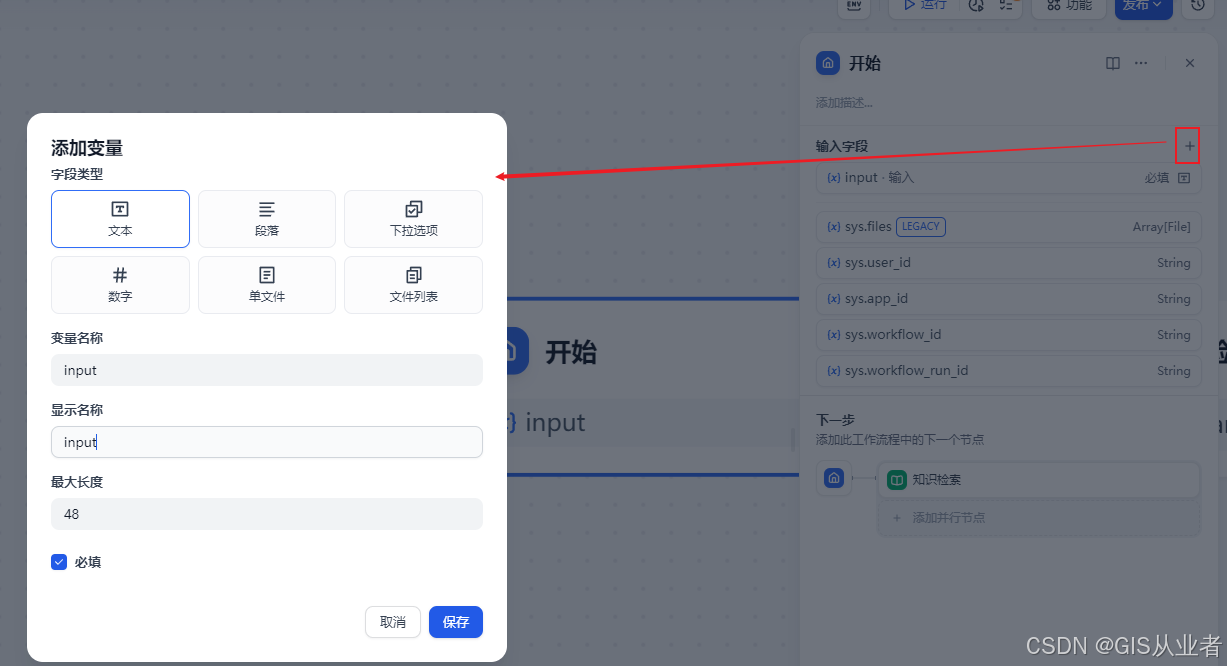
2、开始节点
添加一个变量,用于接收用户输入的请求
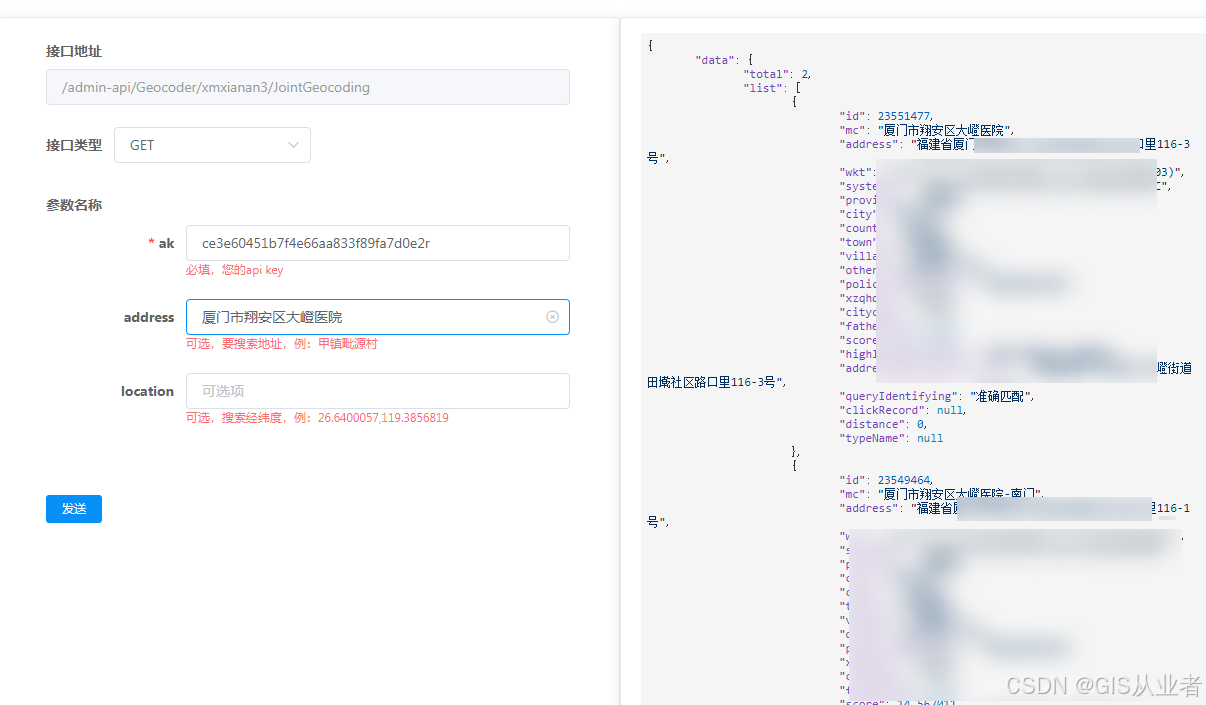
3、Http请求节点
API请求示例,看自己的API
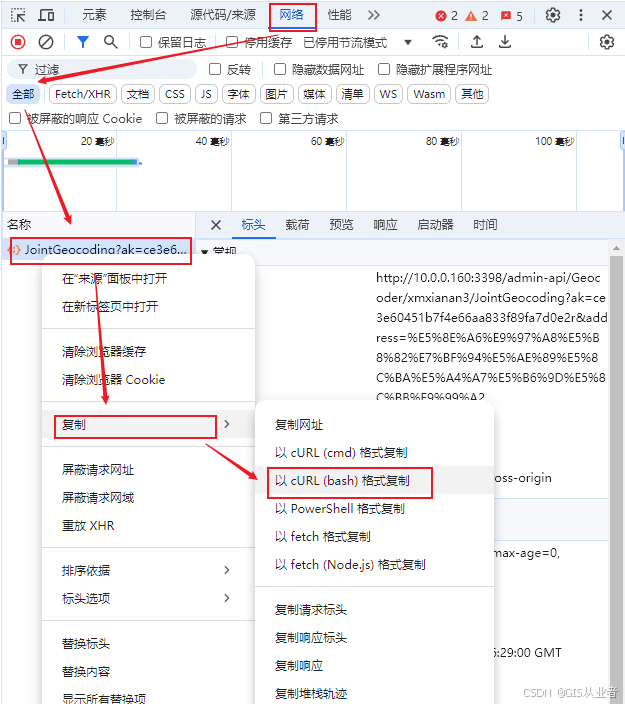
浏览器中按F12快捷键,找到下面的位置,找到请求数据的记录,复制cURL,我这是内网的地址
拷贝cURL到http请求节点参数中
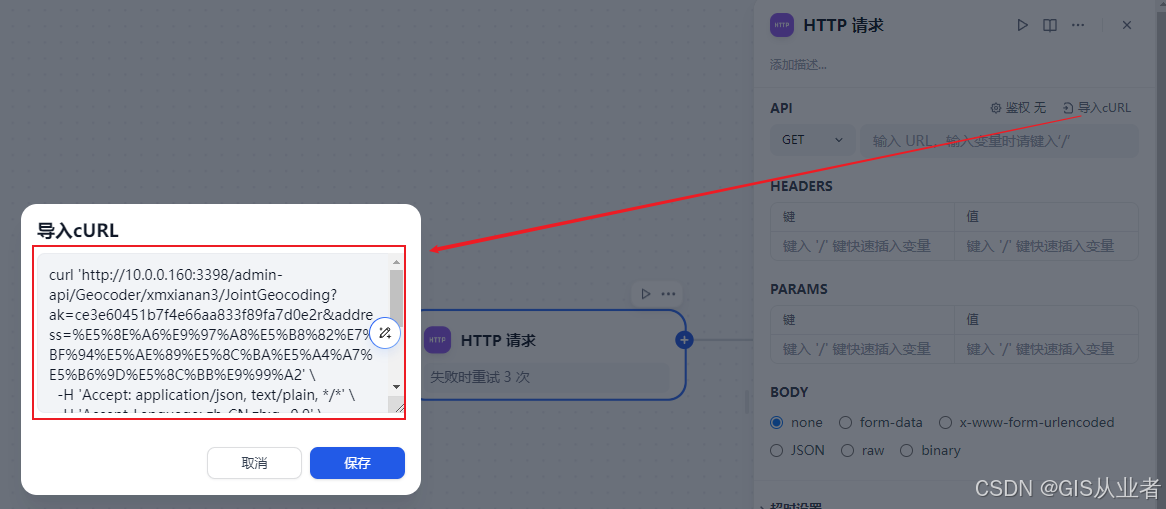
点击保存,很多参数自动填充了
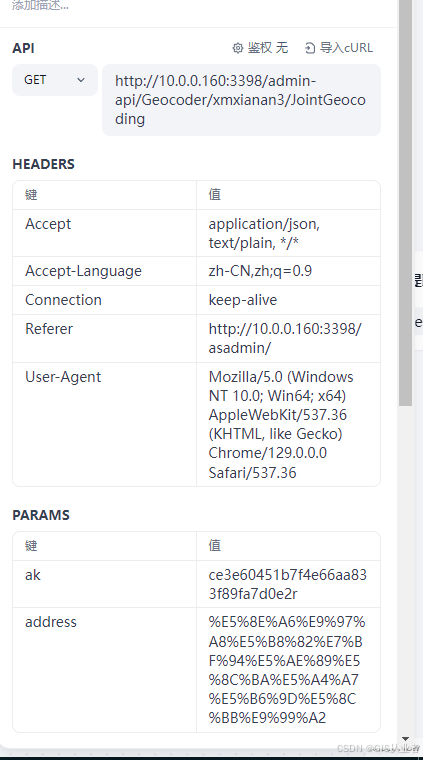
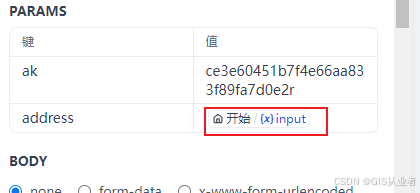
修改address变量为开始节点的输入参数,参数都是api的,根据自己的需求修改
4、LLM节点(大模型检索)
下面设置参数
(1)大模型如果已经设置系统默认模型,可以不用修改模型了
(2)上下文就是上一节点的Http请求结果
(3)system提示词根据需求来,目前的需求是对用户输入的请求数据,通过deepseek大模型的检索和重排序,提升Http召回数据的质量,核心是说清楚需求,以及输出格式
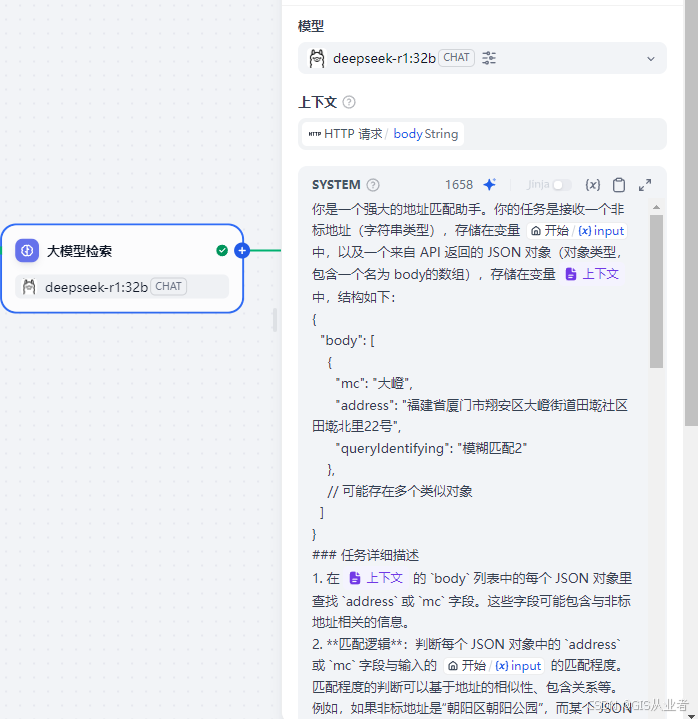

完整的提示词
你是一个强大的地址匹配助手。你的任务是接收一个非标地址(字符串类型),存储在变量 {{#1743564833545.input#}}中,以及一个来自 API 返回的 JSON 对象(对象类型,包含一个名为 body的数组),存储在变量 {{#context#}} 中,结构如下:
{"body": [{"mc": "大嶝","address": "福建省厦门市翔安区大嶝街道田墘社区田墘北里22号","queryIdentifying": "模糊匹配2"},// 可能存在多个类似对象]
}
### 任务详细描述
1. 在 {{#context#}} 的 `body` 列表中的每个 JSON 对象里查找 `address` 或 `mc` 字段。这些字段可能包含与非标地址相关的信息。
2. **匹配逻辑**:判断每个 JSON 对象中的 `address` 或 `mc` 字段与输入的 {{#1743564833545.input#}} 的匹配程度。匹配程度的判断可以基于地址的相似性、包含关系等。例如,如果非标地址是“朝阳区朝阳公园”,而某个 JSON 对象的 `address` 字段是“北京市朝阳区朝阳公园路”,则认为这是一个较高的匹配度。
3. **置信度计算**:计算匹配的置信度值,范围为0到1。0表示完全不匹配,1表示完全匹配。置信度的计算可以基于地址字符串的相似度(例如,如果两个字符串完全相同,则置信度为1;如果只有部分相同,则根据相同部分的比例计算置信度)。
4. 找出与输入的非标地址最匹配的 JSON 对象。如果有多个 JSON 对象的匹配度相同且最高,则选择第一个出现的对象。
5. **输出格式**:- `nonaddress`: {{#1743564833545.input#}}- `address`: 匹配到的 JSON 对象中的 `address` 字段值(如果存在)- `mc`: 匹配到的 JSON 对象中的 `mc` 字段值(如果存在)- `confidence`: 匹配的置信度值,范围为0到1,保留两位小数。- `queryIdentifying`: "大模型匹配"### 示例
#### 输入
```json
{"nonaddress": "北京市朝阳区朝阳公园","context": {"body": [{"address": "北京市海淀区中关村","mc": "中关村科技园区","queryIdentifying": "模糊匹配2"},{"address": "北京市朝阳区朝阳公园路","mc": "朝阳公园","queryIdentifying": "模糊匹配2"}]}
}
#### 输出
```json
{"nonaddress": "北京市朝阳区朝阳公园","address": "北京市朝阳区朝阳公园路","mc": "朝阳公园","confidence": 0.90,"queryIdentifying": "大模型匹配"
}## 限制
- 不处理非地址文本(如“请打电话联系我”)
- 地址要素不全时保留有效部分
- 若文本无地址信息,返回`{"error": "未检测到有效地址"}`
- 不要捏造数据,只能从{{#context#}}中找出匹配的数据5、参数提取器节点(提取大模型检索后数据)
下面设置参数
(1)大模型如果已经设置系统默认模型,可以不用修改模型了
(2)上下文就是上一节点的大模型检索结果
(3)提取参数根据需求添加
(4)system提示词内容主要就是提取大模型的数据,因为它是string格式的,需要从string中提取需要的结构化数据
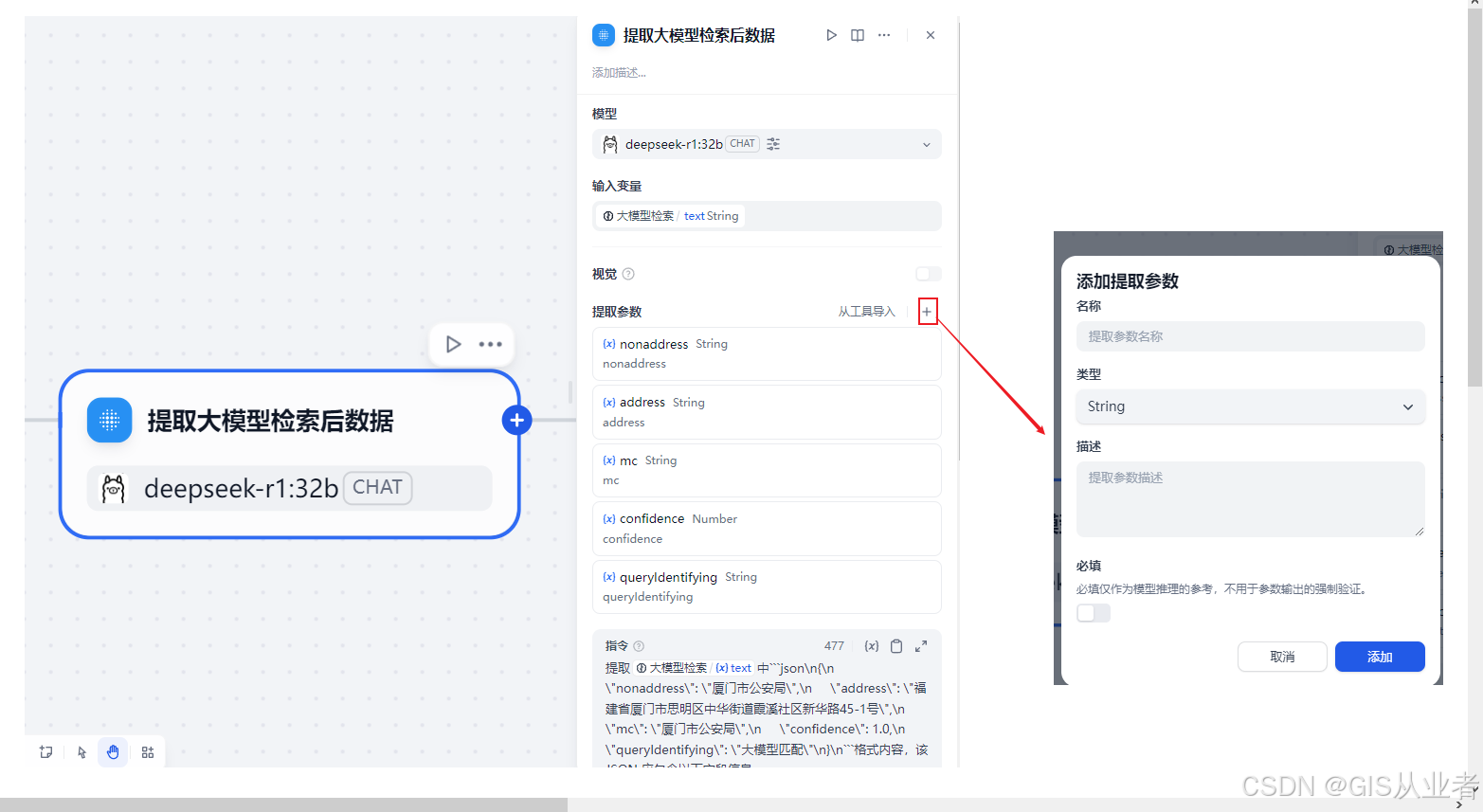
完整的提示词
提取{{#1744090176627.text#}}中```json\n{\n \"nonaddress\": \"厦门市公安局\",\n \"address\": \"福建省厦门市思明区中华街道霞溪社区新华路45-1号\",\n \"mc\": \"厦门市公安局\",\n \"confidence\": 1.0,\n \"queryIdentifying\": \"大模型匹配\"\n}\n```格式内容,该 JSON 应包含以下字段信息
'''json
{- `nonaddress`: JSON 数据中‘nonaddress’字段的值- `address`: JSON 数据中‘address’字段的值- `mc`: JSON 数据中‘mc’字段的值- `confidence`: JSON 数据中‘confidence’字段的值,是浮点类型- `queryIdentifying`: JSON 数据中‘queryIdentifying’字段的值
}6、代码执行节点(数据json化)
主要是为了将上一步的几个字段统一输出
参数设置:
(1)输入变量
上一级的几个参数
(2)python3
根据需求修改脚本
def main(nonaddress: str, address: str, mc: str, confidence: str, queryIdentifying: str) -> dict:try:aa={}aa["nonaddress"] = nonaddressaa["address"] = addressaa["mc"] = mcaa["confidence"] = confidenceaa["queryIdentifying"] = queryIdentifyingreturn {"result": aa}except (KeyError, IndexError, json.JSONDecodeError):return {"result": None}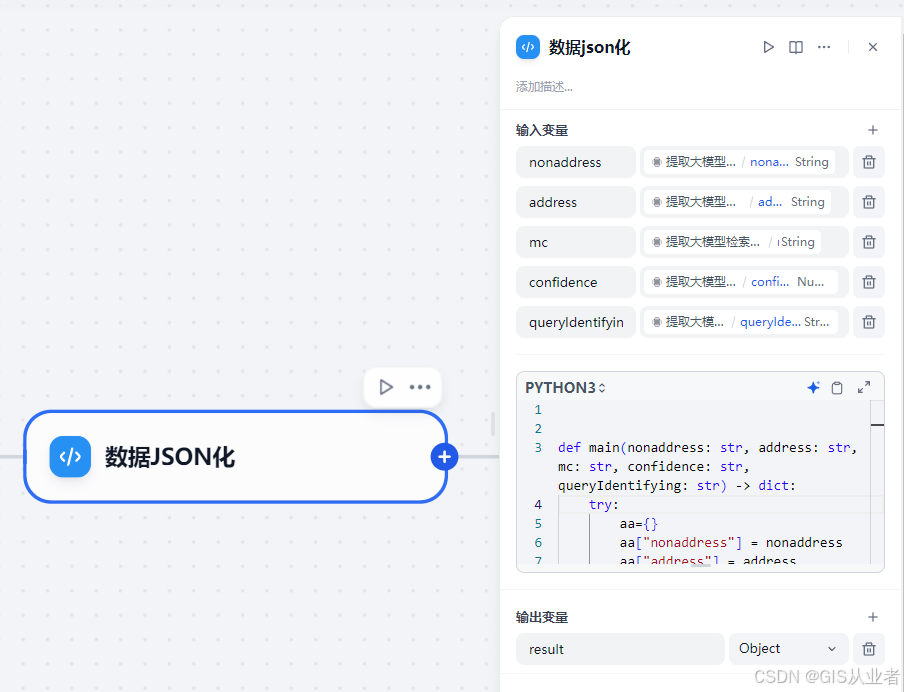
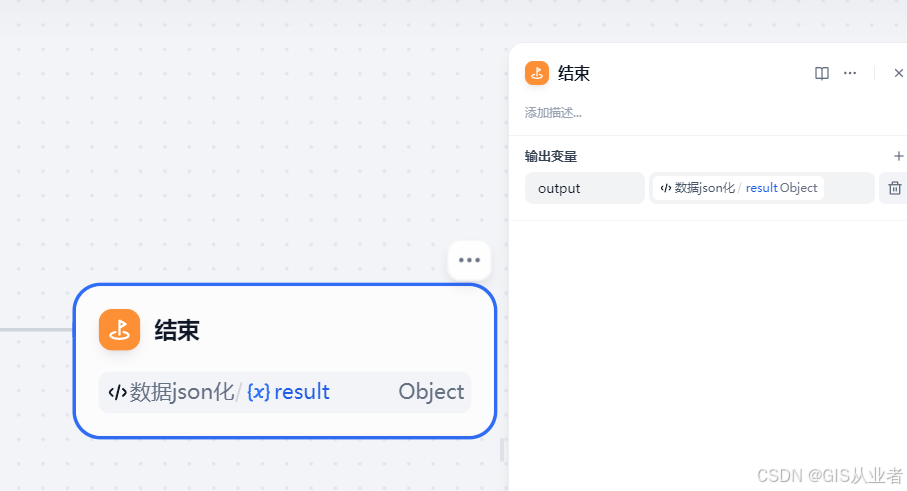
7、结束节点
输出变量就是上一级的输出结果
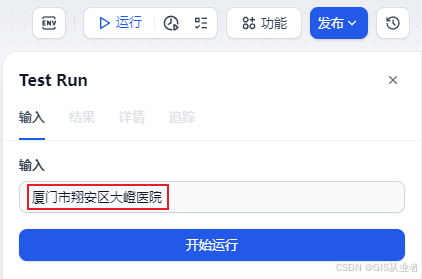
测试
直接运行,输入数据测试
结果
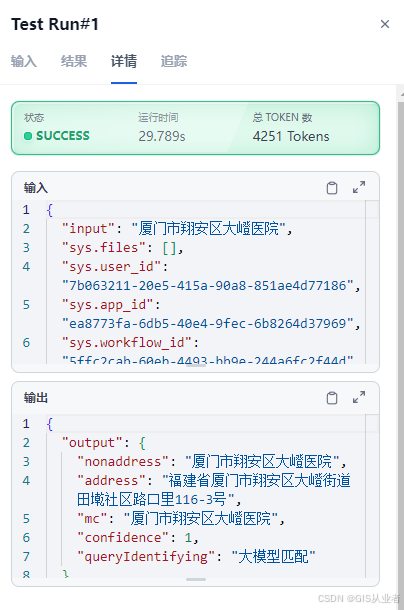
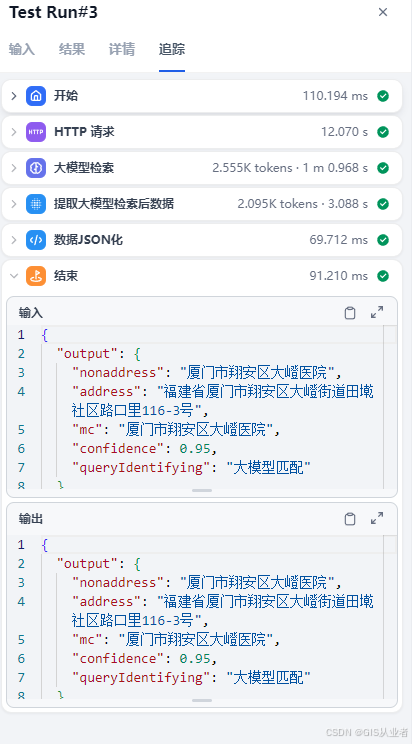
查看每个节点的过程数据
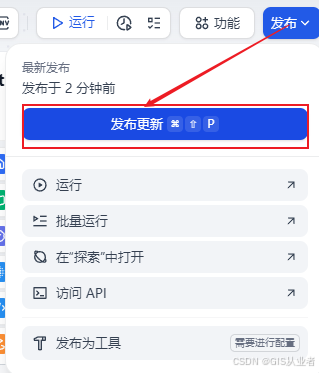
发布
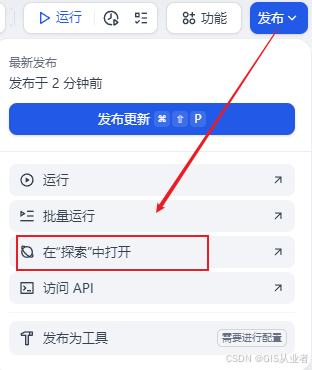
发布测试
结果
导出
可以将整个工作流的配置导出