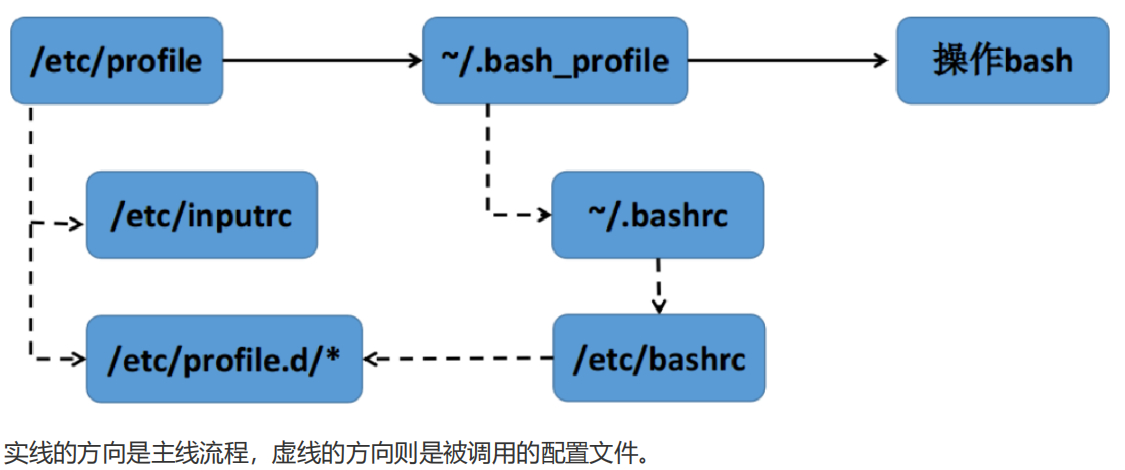
以下是如何将32位数据转化为 1bit valid, 1bit modified, 20bit tag, 2bit index, 8bit 数据 的代码实现和解释。
数据结构布局
我们希望将 32 位数据分成以下几部分:
- 1bit valid: 数据是否有效(0 或 1)。
- 1bit modified: 数据是否被修改(脏位,0 或 1)。
- 20bit tag: 缓存标记,用于标识不同的内存块。
- 2bit index: 索引,用于确定属于哪个缓存 set。
- 8bit 数据: 实际的数据。
32 位数据分布示意图:
[31] valid
[30] modified
[29:10] tag (20 bits)
[9:8] index (2 bits)
[7:0] data (8 bits)
转换代码
以下是 C 语言实现代码:
#include <stdint.h>
#include <stdio.h>// 模拟 32 位数据分解为字段
void decodeCacheLine(uint32_t cache_line) {// 提取各个字段uint8_t valid = (cache_line >> 31) & 0x1; // 提取第 31 位(valid bit)uint8_t modified = (cache_line >> 30) & 0x1; // 提取第 30 位(modified bit)uint32_t tag = (cache_line >> 10) & 0xFFFFF; // 提取第 29-10 位(20 bits tag)uint8_t index = (cache_line >> 8) & 0x3; // 提取第 9-8 位(2 bits index)uint8_t data = cache_line & 0xFF; // 提取第 7-0 位(8 bits 数据)// 输出解析结果printf("Valid: %u\n", valid);printf("Modified: %u\n", modified);printf("Tag: 0x%X\n", tag);printf("Index: %u\n", index);printf("Data: 0x%X\n", data);
}int main() {// 示例缓存行 32 位数据uint32_t cache_line = 0b10100000000000000001100000101010;// 解析缓存行decodeCacheLine(cache_line);return 0;
}
示例解析
假设 32 位缓存行数据为:
cache_line = 0b10100000000000000001100000101010
-
Valid:
- 位于最高位(31 位)。
- 提取:
(cache_line >> 31) & 0x1。 - 结果:
1(有效)。
-
Modified:
- 位于第 30 位。
- 提取:
(cache_line >> 30) & 0x1。 - 结果:
0(未修改)。
-
Tag:
- 位于第 29 到第 10 位(共 20 位)。
- 提取:
(cache_line >> 10) & 0xFFFFF。 - 结果:
0x00003。
-
Index:
- 位于第 9 到第 8 位(共 2 位)。
- 提取:
(cache_line >> 8) & 0x3。 - 结果:
0x2。
-
Data:
- 位于最低的 8 位(第 7 到第 0 位)。
- 提取:
cache_line & 0xFF。 - 结果:
0x5A。
输出
运行代码将输出:
Valid: 1
Modified: 0
Tag: 0x3
Index: 2
Data: 0x5A
总结
这段代码通过移位操作和按位与操作,将 32 位数据拆分为 1bit valid,1bit modified,20bit tag,2bit index 和 8bit 数据。你可以使用类似的方法解析其他的缓存行格式或设计更复杂的模拟器。