大模型笔记8 文本数据清洗
帮其他组做了下数据清洗, 分享一些相关经验. (文中数据相关部分经过模糊/改写处理)
目录
格式改写
Jsonl格式
统计词条数目与长度分布
重复性检测
Topic去重
Content元素去重
句子去重
n-gram去重
去除content中空字符串
低质内容检测
多语言检测
content统计时先拼接
多换行标题检测
读取label图形展示
分层抽样
1. 转换成dataframe格式
2.分层抽样
content文字长度
中文比例
多语言分词
Magpie
格式改写
读取文件中数据, 并将其处理为目标结构.
每个topic的字符串末尾包含: 百度百科\n
据此区分topic与content.
处理结果目标格式:
| {"topic": 'xx', "content": ["", ""]} |
原始数据样例:
| {"text": "A_百度百科\n"} {"text": "A…今后若有类似问题或者升级补丁会提前在官网告知用户。\n"} {"text": "… 参考资料 1. iPhone陷闹钟失声门 苹果称不能保证未来没问题 2. 苹果吸金有术 用户体验点石成金\n"} {"text": "B_百度百科\n"} {"text": "B…今后若有类似问题或者升级补丁会提前在官网告知用户。\n"} {"text": "B… 参考资料 1. iPhone陷闹钟失声门 苹果称不能保证未来没问题 2. 苹果吸金有术 用户体验点石成金\n"} |
处理代码:
| import json with open('data/data.json', 'r', encoding='utf-8') as f: lines = [json.loads(line.strip())['text'].strip() for line in f if line.strip()] results = [] current_topic = None current_content = [] for line in lines: if line.endswith('_百度百科'): # 如果已经有前一个topic的内容,保存它 if current_topic: results.append({ "topic": current_topic.replace('_百度百科', ''), "content": current_content }) # 新的 topic current_topic = line.replace('_百度百科', '') current_content = [] else: current_content.append(line) # 处理最后一个 topic if current_topic: results.append({ "topic": current_topic.replace('_百度百科', ''), "content": current_content }) # 保存到文件 # print(json.dumps(results, ensure_ascii=False, indent=2)) with open('data/processed_data.json', 'w', encoding='utf-8') as f: json.dump(results, f, ensure_ascii=False, indent=2) |
其中strip 去除头尾字符、空白符(包括\n、\r、\t、' ',即:换行、回车、制表符、空格)因此判断_百度百科的时候不需要再次考虑\n
原始数据是逐行json, 而不是标准的json文件格式, 因此不能直接通过json.load(f)读取文件
改写后样例:
| [ { "topic": "A", "content": [ "A…今后若有类似问题或者升级补丁会提前在官网告知用户。", "A… 参考资料 1. iPhone陷闹钟失声门 苹果称不能保证未来没问题 2. 苹果吸金有术 用户体验点石成金" ] }, { "topic": "A", "content": [ "A…今后若有类似问题或者升级补丁会提前在官网告知用户。", "A… 参考资料 1. iPhone陷闹钟失声门 苹果称不能保证未来没问题 2. 苹果吸金有术 用户体验点石成金" ] } ] |
Jsonl格式
JSONL 文件格式在处理大量数据、写入文本文件或日志文件以及实时处理数据流等场景中具有优势,因为它可以逐行读取和处理数据,而不需要一次性加载整个数据集合。
直接写入代码:
| # 写入 JSONL 文件 with open('processed.jsonl', 'w', encoding='utf-8') as f: for entry in data: f.write(json.dumps(entry, ensure_ascii=False) + '\n') |
调用jsonlines库, 每个条目添加一个uuid:
| import json import jsonlines import uuid read_file_path='data/quality_check.json' save_repeat_path='data/jsonlines.jsonl' # 读取 JSON 格式文件(上次保存的) with open(read_file_path, 'r', encoding='utf-8') as f: data = json.load(f) # 写入为 JSON Lines 格式 with jsonlines.open(save_repeat_path, mode='w') as writer: for item in data: writer.write(item) |
Jsonl文件内容的读取:
| data = [] with jsonlines.open(save_repeat_path, mode='r') as reader: for obj in reader: data.append(obj) print(data[0]) |
统计词条数目与长度分布
- 统计词条数
统计刚刚保存的文件中topic的数量
| import json read_file_path='data/processed_data.json' with open(read_file_path, 'r', encoding='utf-8') as f: data = json.load(f) # 统计 topic 数量(每个 topic 对应一个对象) topic_count = len(data) print(f"共包含 {topic_count} 个 topic") |
2.content长度分布
在处理完的文件统计每个 content 的总字符串长度
| from collections import Counter # 统计每个 content 的总字符串长度 lengths = [sum(len(item) for item in entry["content"]) for entry in results] # 打印一些基本统计信息 print(f"样本总数: {len(lengths)}") print(f"最小长度: {min(lengths)}") print(f"最大长度: {max(lengths)}") print(f"平均长度: {sum(lengths) / len(lengths):.2f}") # 获取长度分布(以10为一个分组区间,例如 0-9, 10-19,...) bin_size = 10 bins = [((l // bin_size) * bin_size) for l in lengths] length_distribution = Counter(bins) # 打印分布(按长度区间升序排序) for length_bin in sorted(length_distribution.keys()): print(f"{length_bin:>3} - {length_bin + bin_size - 1:>3} : {length_distribution[length_bin]}") |
输出样例:
| 共包含 2 个 topic 样本总数: 2 最小长度: 163 最大长度: 163 平均长度: 163.00 160 - 169 : 2 |
画图:
| import matplotlib.pyplot as plt plt.hist(lengths, bins=range(0, max(lengths)+10, 10), edgecolor='black') plt.title("Content 长度分布") plt.xlabel("总长度") plt.ylabel("频数") plt.grid(True) plt.show() |
结果样例:
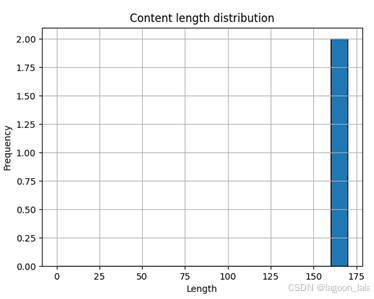
保存图片:
| plt.savefig('length_distribution.png') |
将统计信息保存到文件中:
| with open(save_stat_path, "w", encoding="utf-8") as f: f.write(f"topic总数: {len(lengths)}\n") f.write(f"最小长度: {min(lengths)}\n") f.write(f"最大长度: {max(lengths)}\n") f.write(f"平均长度: {sum(lengths) / len(lengths):.2f}\n") f.write("\n长度分布:\n") for length_bin in sorted(length_distribution.keys()): f.write(f"{length_bin:>3} - {length_bin + bin_size - 1:>3} : {length_distribution[length_bin]}\n") |
重复性检测
Topic去重
读取刚刚保存的文件. 去除重复topic及其对应content.
先判断 topic 是否重复,使用一个 dict 来记录;
如果 topic 相同,检查其 content 列表中的文本是否重复,合并并去重;
| import json # import re read_file_path='data/processed_data.json' save_repeat_path='data/topic_deduplicate.json' # 读取保存的文件 with open(read_file_path, 'r', encoding='utf-8') as f: data = json.load(f) # 用 dict 去重 topic unique_topics = {} for entry in data: topic = entry['topic'] contents = entry['content']
if topic in unique_topics: # 合并内容并去重 existing_contents = unique_topics[topic] combined_contents = list(set(existing_contents + contents)) unique_topics[topic] = combined_contents else: unique_topics[topic] = contents # 重新组织为原始格式 results = [{"topic": topic, "content": contents} for topic, contents in unique_topics.items()] # 保存去重后的结果 with open(save_repeat_path, 'w', encoding='utf-8') as f: json.dump(results, f, ensure_ascii=False, indent=2) print("去重完成,共保留 topic 数量:", len(results)) |
Content元素去重
读取上次保存的文件, 检查同一个topic中的所有字符串元素, 如果content中一个字符串元素被另一个字符串元素包含(是其“子串”), 则去除这个被包含的元素.
遍历每个 topic 的 content 列表;
两两比较其中的字符串(例如 s1 in s2),如果 s1 是 s2 的子串且 s1 != s2,就标记 s1 为要删除的;
删除所有被包含的字符串,保留信息量更多的那个。
| import json # import re read_file_path='data/topic_deduplicate.json' save_repeat_path='data/content_deduplicate.json' # 读取 deduplicated 文件 with open(read_file_path, 'r', encoding='utf-8') as f: data = json.load(f) def remove_contained_contents(contents): unique_contents = [] for i, s1 in enumerate(contents): contained = False for j, s2 in enumerate(contents): if i != j and s1 in s2: contained = True break if not contained: unique_contents.append(s1) else:#找到需要去除的字符串打印其前10个字符 print("重复:",s1[0:10]) return unique_contents # 对每个 topic 的 content 进行处理 for entry in data: entry['content'] = remove_contained_contents(entry['content']) # 保存最终结果 with open(save_repeat_path, 'w', encoding='utf-8') as f: json.dump(data, f, ensure_ascii=False, indent=2) print("content中重复字符串元素去除完成") |
输出结果例子:
| 清洗前 { "topic": "A", "content": [ "A", "A\n… 参考资料 1. iPhone陷闹钟失声门 苹果称不能保证未来没问题 2. 苹果吸金有术 用户体验点石成金", "B。\n…今后若有类似问题或者升级补丁会提前在官网告知用户。" ] } |
| 清洗后 { "topic": "A", "content": [ "A\n… 参考资料 1. iPhone陷闹钟失声门 苹果称不能保证未来没问题 2. 苹果吸金有术 用户体验点石成金", "B。\n…今后若有类似问题或者升级补丁会提前在官网告知用户。" ] } |
句子去重
读取上次保存的文件, 对同一条 content 字符串元素内的句子进行去重
| import json import re read_file_path='data/processed_data.json' save_repeat_path='data/repeat_stats.json' def deduplicate_sentences(text): # 按标点切句(保留标点) sentences = re.split(r'(?<=[。!?\?])\s*', text.strip()) seen = set() deduped = [] for s in sentences: s = s.strip() if s and s not in seen: seen.add(s) deduped.append(s) return ''.join(deduped) # 读取已保存的文件 with open(read_file_path, 'r', encoding='utf-8') as f: data = json.load(f) # 去重处理每条 content 中的句子 for item in data: item['content'] = [deduplicate_sentences(text) for text in item['content']] # 保存新文件 with open(save_repeat_path, 'w', encoding='utf-8') as f: json.dump(data, f, ensure_ascii=False, indent=2) print("句子去重完成") |
其中句子分割的re.split(r'(?<=[。!?\?])\s*', text.strip()):通过正向肯定前瞻保留标点符号
|
读取上次保存的文件, 对同一个topic内所有content字符串元素之间的句子进行去重. 保留该句子在其第一次出现的字符串元素中.
跨content句子去重:
| import json import re def split_sentences(text): # 中文及英文常见句子结束符,分割时保留标点 sentences = re.split(r'(?<=[。!?\?])\s*', text.strip()) return [s.strip() for s in sentences if s.strip()] # 读取上次保存的文件 with open('processed_deduplicated.json', 'r', encoding='utf-8') as f: data = json.load(f) # 跨content去重句子 for item in data: seen_sentences = set() new_content = [] for content_text in item['content']: sentences = split_sentences(content_text) deduped_sentences = [] for s in sentences: if s not in seen_sentences: seen_sentences.add(s) deduped_sentences.append(s) # 合并回文本 new_content.append(''.join(deduped_sentences)) item['content'] = new_content # 保存处理后的文件 with open('processed_cross_deduplicated.json', 'w', encoding='utf-8') as f: json.dump(data, f, ensure_ascii=False, indent=2) print("跨content句子去重完成") |
句子重复判定方式改成ngram相似度判断
| import json import re def split_sentences(text): sentences = re.split(r'(?<=[。!?\?])\s*', text.strip()) return [s.strip() for s in sentences if s.strip()] def ngrams(sentence, n=3): return set([sentence[i:i+n] for i in range(len(sentence) - n + 1)]) def jaccard_sim(s1, s2, n=3): ngrams1 = ngrams(s1, n) ngrams2 = ngrams(s2, n) if not ngrams1 or not ngrams2: return 0.0 return len(ngrams1 & ngrams2) / len(ngrams1 | ngrams2) def is_duplicate(s, seen_sentences, threshold=0.8): for prev in seen_sentences: if jaccard_sim(s, prev) >= threshold: return True return False # 读取文件 with open('processed_deduplicated.json', 'r', encoding='utf-8') as f: data = json.load(f) # 对每个 topic 进行去重 for item in data: seen_sentences = [] new_content = [] for content_text in item['content']: sentences = split_sentences(content_text) deduped_sentences = [] for s in sentences: if not is_duplicate(s, seen_sentences): seen_sentences.append(s) deduped_sentences.append(s) new_content.append(''.join(deduped_sentences)) item['content'] = new_content # 保存结果 with open('processed_ngram_deduplicated.json', 'w', encoding='utf-8') as f: json.dump(data, f, ensure_ascii=False, indent=2) print("n-gram 相似度去重完成") |
用现成的 Python 库 difflib来实现这个代码中句子相似度的判定部分
| import difflib def is_duplicate(s, seen_sentences, threshold=0.85): # 你可以微调这个阈值 for prev in seen_sentences: similarity = difflib.SequenceMatcher(None, s, prev).ratio() if similarity >= threshold: return True return False |
正则划分句子时候收到警告:
| FutureWarning: split() requires a non-empty pattern match. return _compile(pattern, flags).split(string, maxsplit) |
这个警告的根源是来自这句代码:
re.split(r'(?<=[。!?\?])\s*', text.strip())
当传入的 text.strip() 是 空字符串 "" 时,re.split() 会尝试匹配一个空字符串,然后抛出 FutureWarning,因为这样可能在将来的 Python 版本中会变成错误行为。
n-gram去重
对每个 content 内的句子进行 n-gram 重复性检测。检测思路如下:
- 切句子: 根据标点符号(比如 “。!?”)将每个 content 文本拆分为句子。
- 生成 n-gram: 对每个句子生成指定长度(例如3)的 n-gram 列表。
- 计算相似度: 采用 Jaccard 相似度来比较两个句子的 n-gram 重合程度,若超过设定阈值则认为它们重复。
参考:
利用N-Gram模型进行数据清洗的相关示例
利用N-Gram模型进行数据清洗_数据清洗ngram-CSDN博客
| import json import re read_file_path='data/processed_data.json' save_repeat_path='data/repeat_stats.json' def get_ngrams(text, n=3): """ 根据给定的 n 值生成文本的 n-gram 列表 """ return [text[i:i+n] for i in range(len(text)-n+1)] if len(text) >= n else [text] def jaccard_similarity(ngrams1, ngrams2): """ 计算两个 n-gram 集合的 Jaccard 相似度 """ set1 = set(ngrams1) set2 = set(ngrams2) union = set1.union(set2) if not union: return 0.0 intersection = set1.intersection(set2) return len(intersection) / len(union) def detect_duplicate_sentences(content_text, n=3, sim_threshold=0.8): """ 对给定的文本按照句子划分,利用 n-gram 方法检测重复句子。 返回: - sentences:分割后的句子列表 - duplicates:重复句子对的索引及相似度列表 """ # 简单根据中文句号、问号、感叹号切分句子 sentences = re.split(r'[。!?]', content_text) # 去掉空白以及冗余的空格 sentences = [s.strip() for s in sentences if s.strip()]
duplicates = [] # 分别计算每个句子的 n-gram ngrams_list = [get_ngrams(s, n) for s in sentences] num = len(sentences)
# 两两比较句子 for i in range(num): for j in range(i+1, num): sim = jaccard_similarity(ngrams_list[i], ngrams_list[j]) if sim >= sim_threshold: duplicates.append({ "sentence_index_pair": (i, j), "sentence_pair": (sentences[i], sentences[j]), "similarity": sim }) return sentences, duplicates #文件读取 with open(read_file_path, 'r', encoding='utf-8') as f: data = json.load(f) # 针对每个 topic 下的每个 content 做 n-gram 句子级重复性检测 # 检测参数:n=3, 阈值sim_threshold=0.8(可根据需要调整) detailed_results = [] for topic_item in data: topic_title = topic_item["topic"] # processed_contents = [] # 拼接同话题下content all_content="" for content in topic_item["content"]: all_content+=content # processed_contents.append({ # "original_content": content, # "sentences": sentences, # "duplicate_sentence_info": duplicates # }) # 针对同话题下所有内容调用检测函数,对内容进行句子分割和重复性检测 sentences, duplicates = detect_duplicate_sentences(all_content, n=3, sim_threshold=0.8)
detailed_results.append({ "topic": topic_title, "content": topic_item["content"], "sentences": sentences, "duplicate_sentence_info": duplicates }) #文件保存 # # 输出检测结果,格式化为 JSON # print(json.dumps(detailed_results, ensure_ascii=False, indent=2)) # 将处理结果写入文件 with open(save_repeat_path, 'w', encoding='utf-8') as f: json.dump(detailed_results, f, ensure_ascii=False, indent=2) |
实际运行时候调整参数:
检测粒度参数n
相似度阈值sim_threshold
去除content中空字符串
读取之前保存的文件, 去除content中为空的字符串元素
| import json read_file_path='data/sentence_deduplicate2.json' save_repeat_path='data/remove_empty.json' # 读取之前处理后的文件 with open(read_file_path, 'r', encoding='utf-8') as f: data = json.load(f) # 去除 content 中的空字符串 for topic in data: topic['content'] = [content for content in topic['content'] if content.strip()] # 保存清洗结果 with open(save_repeat_path, 'w', encoding='utf-8') as f: json.dump(data, f, ensure_ascii=False, indent=2) print("已清除 content 中的空字符串") |
低质内容检测
多语言检测
1.读取上次保存的文件, 检测content中的低质量字符串元素, 标记其低质类别标签, 及其在content列表中的元素序号.
当中文字符比例小于10%时候标记为多语言
结果保存格式例子:
| [ { "topic": "sniffer", "content": [ "…elseprintf(“protocolid:%d\\n”,iphead[9])…" ], "low_quality": [ { "multilingual":0 } ] } ] |
检测代码:
| import json import re # import re read_file_path='data/topic_deduplicate.json' save_repeat_path='data/quality_check.json' # 中文字符判断函数 def chinese_ratio(text): chinese_chars = re.findall(r'[\u4e00-\u9fff]', text) return len(chinese_chars) / len(text) if text else 0 # 读取处理后的 JSON 文件 with open(read_file_path, 'r', encoding='utf-8') as f: data = json.load(f) results = [] for item in data: topic = item['topic'] content = item['content'] low_quality = [] for idx, text in enumerate(content): ratio = chinese_ratio(text) if ratio < 0.1: low_quality.append({'multilingual': idx}) result = { "topic": topic, "content": content } # if low_quality: # result["low_quality"] = low_quality result["low_quality"] = low_quality results.append(result) # 保存结果到文件 with open(save_repeat_path, 'w', encoding='utf-8') as f: json.dump(results, f, ensure_ascii=False, indent=2) print("低质量内容分析完成") |
运行结果:
| [ { "topic": "iPhone闹钟门", "content": [ "A… 参考资料 1. iPhone陷闹钟失声门 苹果称不能保证未来没问题 2. 苹果吸金有术 用户体验点石成金", "A…今后若有类似问题或者升级补丁会提前在官网告知用户。" ], "low_quality": [] }, { "topic": "sniffer", "content": [ "…elseprintf(“protocolid:%d\\n”,iphead[9])…" ], "low_quality": [ { "multilingual": 0 } ] } ] |
content统计时先拼接
| import json import re import jsonlines read_file_path='data/jsonlines.jsonl' save_repeat_path='data/quality_check.jsonl' # 中文字符判断函数 def count_chinese_ratio(text): chinese_chars = re.findall(r'[\u4e00-\u9fff]', text) return len(chinese_chars) / len(text) if text else 0 # 未换行标题检测函数 def count_unstructured_titles(text): count = 0 patterns = [ r'\[[1-9]\d*\]', # [1], [2], etc. r'第[一二三四五六七八九十百千万零1234567890]+章', # 第一章, 第二章 r'\d+(?:\.\d+)+', # 1.1.1, 1.1.2 r'([一二三四五六七八九十]+)', # (一), (二) r'(\d+)', # (1), (2) r'([A-Z])', # (A), (B) r'([a-z])', # (a), (b) r'([ⅠⅡⅢⅣⅤⅥⅦⅧⅨⅩ]+)', # (Ⅰ), (Ⅱ) r'([ⅰⅱⅲⅳⅴⅵⅶⅷⅸⅹ]+)', # (i), (ii) r'[一二三四五六七八九十]+、', # 一、, 二、 r'\d+、', # 1、, 2、 r'\d+\.', # 1., 2. r'[A-Z]\.', # A., B. r'[a-z]\)', # a), b) r'[ⅠⅡⅢⅣⅤⅥⅦⅧⅨⅩ]+\)', # Ⅰ), Ⅱ) r'[ⅰⅱⅲⅳⅴⅵⅶⅷⅸⅹ]+\)' # i), ii) ] # 组合正则表达式(使用多行模式 ^ 匹配行首) combined_pattern = re.compile( r'|'.join(patterns), flags=re.MULTILINE # 关键:让 ^ 匹配每行的开头 )
# 统计匹配次数 # matches = combined_pattern.findall(text) matches = list(re.finditer(combined_pattern, text)) for m in matches: if not around_has_newline(text, m.start(), m.end()): count += 1 return count # 判断匹配内容前后是否有换行 def around_has_newline(text, start, end, window=10): before = text[max(0, start - 5):start] after = text[end:end + window] return '\n' in before or '\n' in after # 读取上一步处理后的 JSON 文件 data = [] with jsonlines.open(read_file_path, mode='r') as reader: for obj in reader: data.append(obj) # 统计 results = [] for item in data: topic = item['topic'] contents = item['content'] combined_content = "".join(item['content']) # print("content:",combined_content) # low_quality = [] # 检测中文比例 chinese_ratio = count_chinese_ratio(combined_content) # 检测未换行标题个数 title_num=count_unstructured_titles(combined_content) result = { "topic": topic, "content": contents, 'chinese_ratio': chinese_ratio, "title_num": title_num } results.append(result) # 写入为 JSON Lines 格式 with jsonlines.open(save_repeat_path, mode='w') as writer: for item in results: writer.write(item) |
输出结果:
| {"topic": "A", "content": ["A\n… 参考资料 1. iPhone陷闹钟失声门 苹果称不能保证未来没问题 2. 苹果吸金有术 用户体验点石成金", "A\n…今后若有类似问题或者升级补丁会提前在官网告知用户。"], "chinese_ratio": 0.6363636363636364, "title_num": 2} {"topic": "sniffer", "content": ["…elseprintf(“protocolid:%d\\n”,iphead[9])…"], "chinese_ratio": 0.0, "title_num": 1} {"topic": "sniffer", "content": ["第1章…第1章…第1章…第1章…"], "chinese_ratio": 0.5, "title_num": 4} |
多换行标题检测
增加一种低质标签检测:
针对未换行标题记录个数, 超过3个则记录标签为multiple_titles
未换行标题指出现以下序号的前后未出现换行符\n
| [1] ,[2] ..., 第一章、第二章, 3.1.4 |
检测代码:
| # 未换行标题检测函数 def count_unstructured_titles(text): count = 0 # 模式1: [1], [2]... matches1 = list(re.finditer(r'\[\d+\]', text)) for m in matches1: if not around_has_newline(text, m.start(), m.end()): count += 1 # 模式2: 第一章、第二章等 matches2 = list(re.finditer(r'(第[一二三四五六七八九十百千万零〇]+章)', text)) for m in matches2: if not around_has_newline(text, m.start(), m.end()): count += 1 # 模式3: 3.1 或 2.4.5 等小节编号 matches3 = list(re.finditer(r'(?<!\d)(\d+\.\d+(?:\.\d+)*)(?!\d)', text)) for m in matches3: if not around_has_newline(text, m.start(), m.end()): count += 1 return count # 判断匹配内容前后是否有换行 def around_has_newline(text, start, end, window=10): before = text[max(0, start - 5):start] after = text[end:end + window] return '\n' in before or '\n' in after |
完整代码:
| import json import re # import re read_file_path='data/topic_deduplicate.json' save_repeat_path='data/quality_check.json' # 中文字符判断函数 def chinese_ratio(text): chinese_chars = re.findall(r'[\u4e00-\u9fff]', text) return len(chinese_chars) / len(text) if text else 0 # 未换行标题检测函数 def count_unstructured_titles(text): count = 0 # 模式1: [1], [2]... matches1 = list(re.finditer(r'\[\d+\]', text)) for m in matches1: if not around_has_newline(text, m.start(), m.end()): count += 1 # 模式2: 第一章、第二章等 matches2 = list(re.finditer(r'(第[一二三四五六七八九十百千万零〇]+章)', text)) for m in matches2: if not around_has_newline(text, m.start(), m.end()): count += 1 # 模式3: 3.1 或 2.4.5 等小节编号 matches3 = list(re.finditer(r'(?<!\d)(\d+\.\d+(?:\.\d+)*)(?!\d)', text)) for m in matches3: if not around_has_newline(text, m.start(), m.end()): count += 1 return count # 判断匹配内容前后是否有换行 def around_has_newline(text, start, end, window=10): before = text[max(0, start - 5):start] after = text[end:end + window] return '\n' in before or '\n' in after # 读取上一步处理后的 JSON 文件 with open(read_file_path, 'r', encoding='utf-8') as f: data = json.load(f) results = [] for item in data: topic = item['topic'] content = item['content'] low_quality = [] for idx, text in enumerate(content): # 检测中文比例 ratio = chinese_ratio(text) if ratio < 0.1: low_quality.append({'multilingual': idx}) # 检测未换行标题个数 if count_unstructured_titles(text) > 5: low_quality.append({"multiple_titles": idx}) result = { "topic": topic, "content": content } # if low_quality: # result["low_quality"] = low_quality result["low_quality"] = low_quality results.append(result) # 保存结果到文件 with open(save_repeat_path, 'w', encoding='utf-8') as f: json.dump(results, f, ensure_ascii=False, indent=2) print("低质量内容分析完成") |
运行结果:
| { "topic": "sniffer", "content": [ "第一章…第一章…第一章…第一章…第一章…第一章…第一章…" ], "low_quality": [ { "multiple_titles": 0 } ] } |
读取label图形展示
读取上次保存的文件, 展示文件中各种 low_quality 标签(如 multilingual、multiple_titles)出现的 频率比例,即:
每种标签出现的次数 / 所有 content
| import json import matplotlib.pyplot as plt from collections import defaultdict read_file_path='data/quality_check.json' # 读取之前保存的标注文件 with open(read_file_path, 'r', encoding='utf-8') as f: data = json.load(f) # 初始化计数器 label_counts = defaultdict(int) total_contents = 0 # 统计所有内容字符串的数量 + 标签出现次数 for topic in data: total_contents += len(topic['content']) if 'low_quality' in topic: for tag in topic['low_quality']: for label in tag: label_counts[label] += 1 # 计算比例 labels = list(label_counts.keys()) ratios = [label_counts[label] / total_contents for label in labels] # 绘图 plt.figure(figsize=(8, 5)) bars = plt.bar(labels, ratios, color='skyblue') # 添加具体数值标注 for bar, ratio in zip(bars, ratios): plt.text(bar.get_x() + bar.get_width() / 2, bar.get_height(), f'{ratio:.2%}', ha='center', va='bottom', fontsize=10) plt.title('Low-quality content ratio') plt.ylabel('ratio') plt.ylim(0, 1) plt.grid(axis='y', linestyle='--', alpha=0.5) plt.tight_layout() plt.show() |
示例运行结果
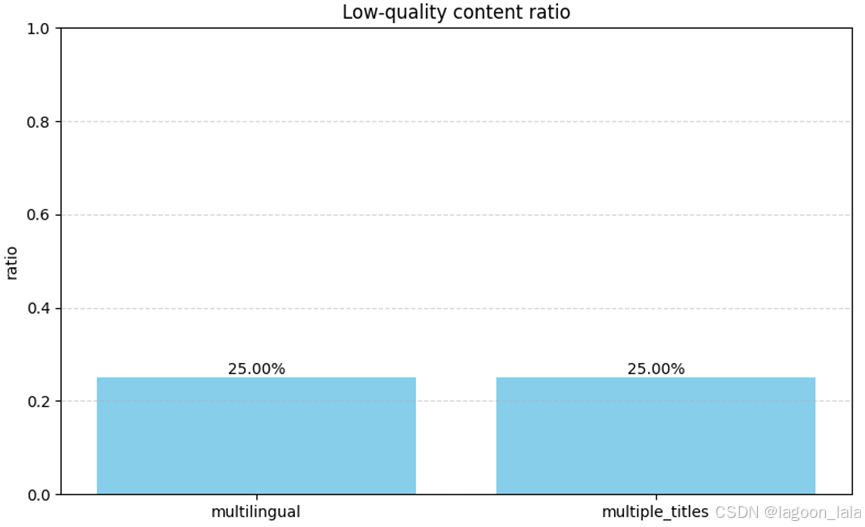
去重比例:
| import json import matplotlib.pyplot as plt from collections import defaultdict read_file_path='data/quality_check.json' format_file_path='data/processed_data.json' # 读取之前保存标注的文件 with open(read_file_path, 'r', encoding='utf-8') as f: data = json.load(f) with open(format_file_path, 'r', encoding='utf-8') as f: format_data = json.load(f) # 初始化计数器 label_counts = defaultdict(int) total_contents = 0 total_contents_before_deduplicate = 0 # 统计所有内容字符串的数量 + 标签出现次数 for topic in data: total_contents += len(topic['content']) if 'low_quality' in topic: for tag in topic['low_quality']: for label in tag: label_counts[label] += 1 # 统计去重前内容字符串的数量 + for topic in format_data: total_contents_before_deduplicate += len(topic['content']) print("total_contents:",total_contents) print("total_contents_before_deduplicate:",total_contents_before_deduplicate) # 计算比例 labels = list(label_counts.keys()) ratios = [label_counts[label] / total_contents for label in labels] # 去重比例 labels.append("Duplicate content ratio") ratios.append(total_contents / total_contents_before_deduplicate) # 绘图 plt.figure(figsize=(8, 5)) bars = plt.bar(labels, ratios, color='skyblue') # 添加具体数值标注 for bar, ratio in zip(bars, ratios): plt.text(bar.get_x() + bar.get_width() / 2, bar.get_height(), f'{ratio:.2%}', ha='center', va='bottom', fontsize=10) plt.title('Low-quality content ratio') plt.ylabel('ratio') plt.ylim(0, 1) plt.grid(axis='y', linestyle='--', alpha=0.5) plt.tight_layout() plt.show() |
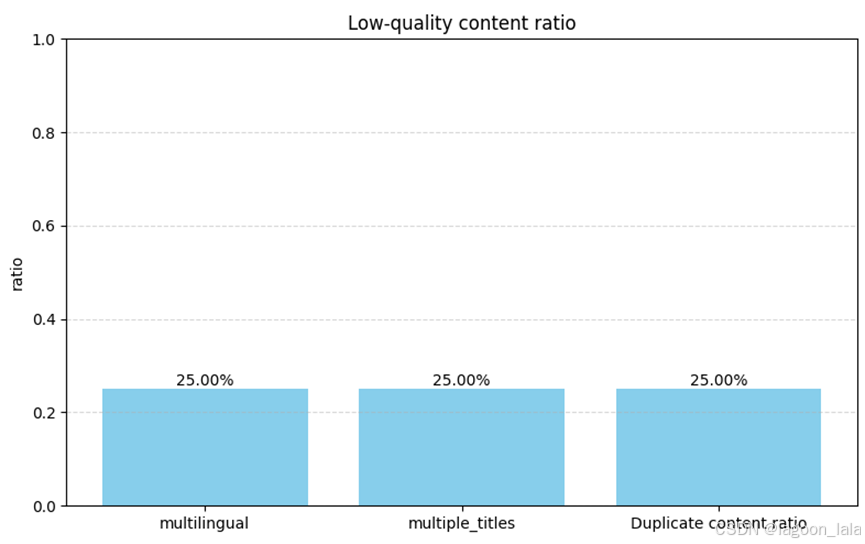
分层抽样
针对不同比例的多语言问题和标题个数抽样看具体情况
目标是寻找不同处理方式(抛弃, 重写, 原样保留)的合适阈值
分几个频次, 分别筛取所有落在这个范围内的样本, 最后从这些样本中抽样显示
参考分层抽样的库和代码:
https://zhuanlan.zhihu.com/p/384322508
| from sklearn.model_selection import train_test_split stratified_sample, _ = train_test_split(population, test_size=0.9, stratify=population[['label']]) print (stratified_sample) |
但是这些库是基于结构化数据的, 有两个思路, 一个是基于非结构化数据找库或者自己写, 一个是把非结构化数据转换为结构化的.
Dict数据转pandas参考:
Stratified Sampling in Pandas | GeeksforGeeks
不成比例的采样: 使用 pandas groupby,根据学生的成绩(即 A、B、C)将学生分成几组,并使用样本函数从每个年级组中随机抽样 2 名学生
| df.groupby('Grade', group_keys=False).apply(lambda x: x.sample(2)) |
每层个数统计(可以从test文件看)
之前重新保存的低质量统计结果格式样例为:
| {"topic": "A", "content": ["A\n… 参考资料 1. iPhone陷闹钟失声门 苹果称不能保证未来没问题 2. 苹果吸金有术 用户体验点石成金", "B\n…今后若有类似问题或者升级补丁会提前在官网告知用户。"], "chinese_ratio": 0.6363636363636364, "title_num": 2} {"topic": "sniffer", "content": ["…elseprintf(“protocolid:%d\\n”,iphead[9])…"], "chinese_ratio": 0.0, "title_num": 1} {"topic": "sniffer", "content": ["第1章…第1章…第1章…第1章…"], "chinese_ratio": 0.5, "title_num": 4} |
读取之前保存的文件, 并根据chinese_ratio进行分层采样.
文件格式:
| {"topic": "A", "content": ["A。\n… 参考资料 1. iPhone陷闹钟失声门 苹果称不能保证未来没问题 2. 苹果吸金有术 用户体验点石成金", "2011年1月1日,炙手可热的iPhone遭遇“闹钟门”,导致很多上班族迟到。\n…今后若有类似问题或者升级补丁会提前在官网告知用户。"], "chinese_ratio": 0.6363636363636364, "title_num": 2} {"topic": "sniffer", "content": ["…elseprintf(“protocolid:%d\\n”,iphead[9])…"], "chinese_ratio": 0.0, "title_num": 1} {"topic": "sniffer", "content": ["第1章…第1章…第1章…第1章…"], "chinese_ratio": 0.5, "title_num": 4} |
改结构化可以先遍历所有json对象, 用list把它们分别存起来.
参考test:
| total_num = 1 uniq_set = [] rule_res = [] seq_len = [] chinese_ratio = [] possible_igline_num = [] for ljson in data[:2000]: topic = ljson['topic']
total_num += 1
if topic not in uniq_set: uniq_set.append(topic) text = '\n'.join(ljson['content']) seq_len.append(len(text))
crat = filter_text_based_on_chinese_ratio(text) num = count_qing_lines(text) chinese_ratio.append(crat) possible_igline_num.append(num) else: print("重复topic:",topic) |
手动分层中文比例采样:
| import jsonlines import numpy as np import random # 参数设置 filename = 'processed_with_ratio.jsonl' # 你的 jsonl 文件名 n_bins = 5 # 分成几层(bins) sample_ratio = 0.5 # 每层采样的比例(0~1 之间) random.seed(42) # 保证可复现 # Step 1: 读取数据 data = [] with jsonlines.open(filename, mode='r') as reader: for item in reader: data.append(item) # Step 2: 分层采样 # 将chinese_ratio按等距分bin(如0~0.2,0.2~0.4等) bin_edges = np.linspace(0, 1, n_bins + 1) # eg: [0. , 0.2, 0.4, ..., 1.0] binned_data = [[] for _ in range(n_bins)] # 分配每个item到对应bin for item in data: ratio = item.get('chinese_ratio', 0.0) # 确保最大值归到最后一组 for i in range(n_bins): if bin_edges[i] <= ratio < bin_edges[i + 1] or (i == n_bins - 1 and ratio == 1.0): binned_data[i].append(item) break # Step 3: 每层采样 sampled_data = [] for bin_items in binned_data: n = int(len(bin_items) * sample_ratio) sampled = random.sample(bin_items, min(n, len(bin_items))) sampled_data.extend(sampled) # Step 4: 打印或保存结果 print(f"原始数量: {len(data)}, 采样后数量: {len(sampled_data)}") # 保存采样结果(可选) with jsonlines.open('sampled_by_chinese_ratio.jsonl', mode='w') as writer: writer.write_all(sampled_data) |
对比决定还是换格式比较靠谱
1. 转换成dataframe格式
读取之前保存的文件, 转换成dataframe格式. 其中content列表中的元素拼接为一个字符串:
| import jsonlines import pandas as pd read_file_path='data/quality_check.jsonl' save_repeat_path='data/df_data.csv'
# 读取 JSONL 格式文件(上次保存的) data = [] with jsonlines.open(read_file_path, mode='r') as reader: for obj in reader: # 拼接 content 中的所有段落为一个字符串 obj['content'] = ''.join(obj['content']) data.append(obj) # print(data[0]) #转换为 DataFrame df = pd.DataFrame(data) # print(df.head()) #保存为 CSV df.to_csv(save_repeat_path, index=False) # 读取 CSV 文件检查 df = pd.read_csv(save_repeat_path, dtype={'chinese_ratio': 'float32'})#节省内存 # 显示前几行数据 print(df.head()) |
2.分层抽样
content文字长度
content文字长度, chinese_ratio, 以及title_num分别做分布图
读取刚刚保存的csv文件, 针对content字符串长度做分布图
| import pandas as pd import matplotlib.pyplot as plt import seaborn as sns read_file_path='data/df_data.csv' # save_repeat_path='data/df_data.csv' # 读取 CSV 文件 df = pd.read_csv(read_file_path) # 计算 content 字符串长度 df['content_length'] = df['content'].astype(str).apply(len) # 横轴范围( 0 到 25000) x_min = 0 x_max = 200 # 绘制分布图 plt.figure(figsize=(10, 6)) # sns.histplot(df['content_length'], bins=30, kde=True, color='skyblue', edgecolor='black') sns.histplot( df['content_length'], bins=30, binrange=(x_min, x_max), kde=True, color='skyblue', edgecolor='black' ) plt.title('Content Length Distribution') plt.xlabel('Content Length (characters)') plt.ylabel('Frequency') plt.xlim(x_min, x_max) plt.grid(True) plt.tight_layout() plt.show() |
分布图例子:
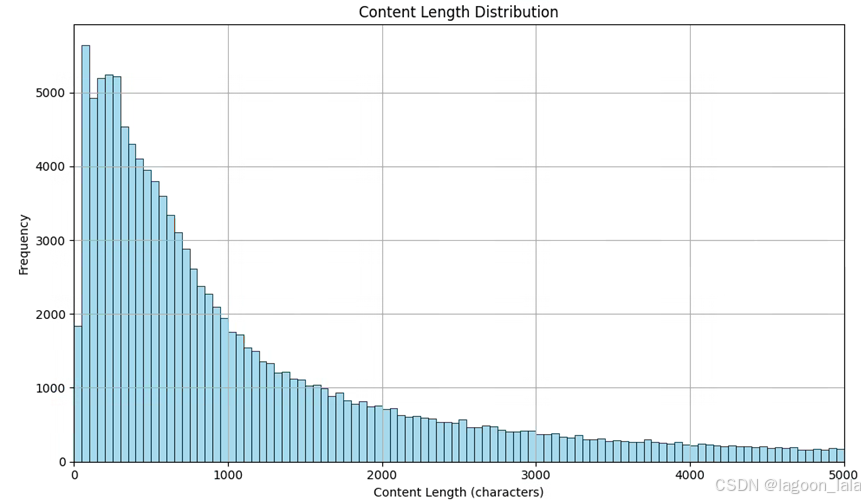
content_length的最大值:
| df['content_length'].max() |
层内样本数量, 上界以上的样本占比
1. 统计content_length 为0-50样本数量, 50以上的样本占比
| def count_sample_num(lb,ub): # 统计 0-50 范围内的样本数 sample_num = df[(df['content_length'] > lb) & (df['content_length'] <= ub)].shape[0] # 统计 >50 的占比 total = df.shape[0] count_above_ub = df[df['content_length'] > ub].shape[0] ratio_above_ub = count_above_ub / total * 100 # 输出结果 print(f"content_length 在 {lb} 到 {ub} 之间的样本数量: {sample_num}") print(f"content_length 大于 {ub} 的样本占比: {ratio_above_ub:.2f}%") count_sample_num(0,50) |
| 输出结果 content_length 在 0 到 50 之间的样本数量: 2 content_length 大于 50 的样本占比: 33.33% |
2.在该区间内抽取3个样本, 注意处理样本比欲抽样个数小的情况
| #避免文字过早截断 pd.set_option('display.max_colwidth', 1000) def content_length_samples(lb,ub,sample_n): # 过滤出 content_length 在 (0, 50] 的样本 subset = df[(df['content_length'] > lb) & (df['content_length'] <= ub)] # 检查子集大小,确保样本数大于等于 3 sample_size = min(sample_n, subset.shape[0]) # 随机抽取 3 个样本 sampled = subset.sample(n=sample_size, random_state=42) # 显示结果 print(f"---content长度 在 {lb} 到 {ub} 之间的样本---") print("抽取样本:") print(sampled[['topic', 'content']]) # 统计 0-50 范围内的样本数 sample_num = subset.shape[0] # 统计 >50 的占比 total = df.shape[0] count_above_ub = df[df['content_length'] > ub].shape[0] ratio_above_ub = count_above_ub / total * 100 # 输出结果 print(f"样本数量: {sample_num}") print(f"样本占比: {ratio_above_ub:.2f}%") content_length_samples(0,50,3) |
中文比例
content文字长度, chinese_ratio, 以及title_num分别做分布图
读取刚刚保存的csv文件, 针对content字符串长度做分布图
| x_min = 0 x_max = 1 # 绘制分布图 plt.figure(figsize=(10, 6)) sns.histplot( # (df['chinese_ratio'] * 100).map(lambda x: f"{x:.2f}%"), df['chinese_ratio'], bins=30, binrange=(x_min, x_max), color='skyblue', edgecolor='black' ) plt.title('Chinese Ratio Distribution') plt.xlabel('Chinese Ratio') plt.ylabel('Frequency') plt.xlim(x_min, x_max) plt.grid(True) plt.tight_layout() plt.show() |
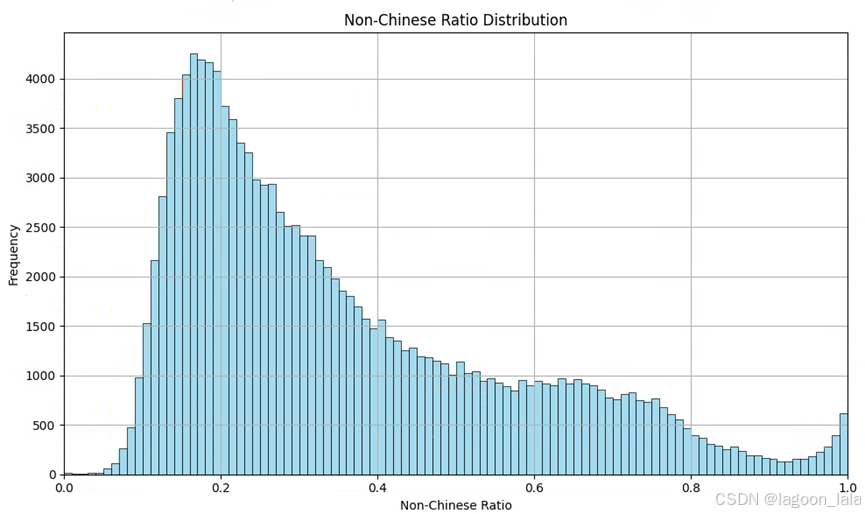
抽样:
| def nonchinese_ratio_samples(lb,ub,sample_n): label='nonchinese_ratio' df[label]=1-df['chinese_ratio'] # 过滤出 content_length 在 (0, 50] 的样本 subset = df[(df[label] > lb) & (df[label] <= ub)] # 检查子集大小,确保样本数大于等于 3 sample_size = min(sample_n, subset.shape[0]) # 随机抽取 n 个样本 sampled = subset.sample(n=sample_size, random_state=42) # 显示结果 print(f"---content长度 在 {lb} 到 {ub} 之间的样本---") print("抽取样本:") print(sampled[['topic', 'content']]) # 统计 范围内的样本数 sample_num = subset.shape[0] # 统计上界外的占比 total = df.shape[0] count_above_ub = df[df[label] > ub].shape[0] ratio_above_ub = count_above_ub / total * 100 # 输出结果 print(f"区间内样本数量: {sample_num}") print(f"区间内样本占比: {sample_num/total* 100:.2f}%") print(f"大于{ub}样本占比: {ratio_above_ub:.2f}%") nonchinese_ratio_samples(0,1,3) |
保存抽样样本中的主要几列
| columns_to_save = ['uuid', 'topic', 'content', 'chinese_ratio'] df[columns_to_save].to_csv('selected_columns.csv', index=False) |
多语言分词
统计语言占比时, 词统计比字符统计更精确, 但是数据包含多语言, 因此需要考虑多语言分词
LangSegment可以看看Stanza库
统计一个字符串的words数量, 其中包含多种语言(中英日韩)和代码
将分词, 从而每种语言包含的:
对一个字符串进行word segmentation, 从而统计其包含的words数量, 字符串中包含多种语言(中英日韩)和代码
| pip install LangSegment |
| from LangSegment import getTexts from collections import Counter # 示例文本,包含中文、日文、韩文和英文 text = "你的名字叫<ja>佐々木?</ja>吗?韩语中的오빠读什么呢?あなたの体育の先生は誰ですか? 此次发布会带来了四款iPhone 15系列机型和三款Apple Watch等一系列新品,这次的iPad Air采用了LCD屏幕" # 获取分词结果 segments = getTexts(text) # 统计每种语言的词数 lang_counts = Counter() for seg in segments: lang = seg['lang'] words = seg['text'].split() lang_counts[lang] += len(words) # 输出每种语言的词数 for lang, count in lang_counts.items(): print(f"{lang}: {count} words") |
Nltk版本:
| import re import jieba import nltk from nltk.tokenize import word_tokenize nltk.download('punkt') def count_multilingual_words(text): # Segment Chinese text chinese_words = jieba.lcut(text) # Tokenize English and other languages other_words = word_tokenize(text) # Combine and deduplicate words combined_words = set(chinese_words + other_words) return len(combined_words) # Example usage text = "我爱Python编程。Hello, world!" print("Word count:", count_multilingual_words(text)) |
split-lang的功能是将不同语言进行分割, 没有split_by_lang这个库与单词分割的功能, 其代码如下
| pip install split-lang |
| from split_lang import LangSplitter lang_splitter = LangSplitter() text = "你喜欢看アニメ吗" substr = lang_splitter.split_by_lang( text=text, ) for index, item in enumerate(substr): print(f"{index}|{item.lang}:{item.text}") |
区分不同语言后分割单词:
| pip install jieba kiwipiepy |
| pip install sudachipy sudachidict_core |
除了中英日韩, 其他文字用字符数统计词数
Kiwipiepy是Kiwi(韩国智能单词标识符)的Python版本
MeCab, Nagisa, konoha环境配置存在问题, 换成sudachipy
| from split_lang import LangSplitter import jieba from kiwipiepy import Kiwi from konoha import WordTokenizer # 初始化分词器 lang_splitter = LangSplitter() kiwi = Kiwi() ja_tokenizer = WordTokenizer("nagisa") # 使用 Nagisa 作为日语分词器 text = "你喜欢看アニメ吗?Hello, world! 안녕하세요. مرحبا بالعالم" segments = lang_splitter.split_by_lang(text=text) word_count = 0 for segment in segments: lang = segment.lang content = segment.text.strip() if not content or lang == 'pun': continue # 跳过空字符串和标点 if lang == 'zh': tokens = list(jieba.cut(content)) elif lang == 'ja': tokens = [token.surface for token in ja_tokenizer.tokenize(content)] elif lang == 'ko': tokens = [token.form for token in kiwi.tokenize(content)] elif lang == 'en': tokens = content.split() else: # 对于其他语言,按字符数统计词数 tokens = list(content) word_count += len(tokens) print(f"总词数:{word_count}") |
| from split_lang import LangSplitter import jieba from kiwipiepy import Kiwi from sudachipy import dictionary, tokenizer # 初始化语言分段器和分词器 lang_splitter = LangSplitter() kiwi = Kiwi() sudachi_tokenizer = dictionary.Dictionary().create() sudachi_mode = tokenizer.Tokenizer.SplitMode.C # 使用最细粒度的分词模式 # 示例多语言文本 text = "你喜欢看アニメ吗?Hello, world! 안녕하세요. مرحبا بالعالم" # 进行语言分段 segments = lang_splitter.split_by_lang(text=text) # 初始化词数统计 word_count = 0 # 遍历每个语言段落 for segment in segments: lang = segment.lang content = segment.text.strip() if not content or lang == 'pun': continue # 跳过空字符串和标点 if lang == 'zh': tokens = list(jieba.cut(content)) elif lang == 'ja': tokens = [m.surface() for m in sudachi_tokenizer.tokenize(content, sudachi_mode)] elif lang == 'ko': tokens = [token.form for token in kiwi.tokenize(content)] elif lang == 'en': tokens = content.split() else: # 对于其他语言,按字符数统计词数 tokens = list(content) word_count += len(tokens) print(f"总词数:{word_count}") |
split() 保留了标点符号,可能导致单词统计不准确。因为字符串中包含代码片段, 因此使用正则r'\b\w+\b'分割
其中\b:表示单词边界(word boundary),用于匹配单词的开始或结束位置。
\w+:匹配一个或多个字母、数字或下划线,等价于 [A-Za-z0-9_]。
tokens = re.findall(r'\b\w+\b', content)
english_words = re.findall(r'\b[a-zA-Z]+\b', content)
lang == 'pun'代表为字符, x代表无法被识别
lang== 'x'时, 抽取其中英文字符, 正则r'\b\w+\b'分割单词, 抽取后剩余的部分计算字符数
lang== 'x'时, 抽取其中英文字符, 正则r'\b\w+\b'分割单词后计算单词数, 抽取后剩余的部分计算字符数
| import re from split_lang import LangSplitter import jieba from kiwipiepy import Kiwi from sudachipy import dictionary, tokenizer # 初始化分词器 lang_splitter = LangSplitter() kiwi = Kiwi() sudachi_tokenizer = dictionary.Dictionary().create() sudachi_mode = tokenizer.Tokenizer.SplitMode.C # 最细粒度 # 示例文本 text = "你喜欢看アニメ吗?Hello, world! 안녕하세요. مرحبا بالعالم" # 进行语言分段 segments = lang_splitter.split_by_lang(text=text) # 初始化词数统计 word_count = 0 # 遍历每个语言段落 for segment in segments: lang = segment.lang content = segment.text.strip() if not content or lang == 'pun': continue # 跳过空字符串和标点 if lang == 'zh': tokens = list(jieba.cut(content)) elif lang == 'ja': tokens = [m.surface() for m in sudachi_tokenizer.tokenize(content, sudachi_mode)] elif lang == 'ko': tokens = [token.form for token in kiwi.tokenize(content)] elif lang == 'en': tokens = content.split() elif lang == 'x': # 判断是否为英文字符 if re.search(r'[A-Za-z]', content): tokens = re.findall(r'\b\w+\b', content) else: tokens = list(content) else: tokens = list(content) word_count += len(tokens) print(f"总词数:{word_count}") |
| # 提取英文单词 english_words = re.findall(r'\b\w+\b', text) # 统计英文单词数 english_word_count = len(english_words) # 移除英文单词后的剩余部分 remaining_text = text for word in english_words: remaining_text = remaining_text.replace(word, '') # 移除空格后的剩余部分 remaining_text = remaining_text.replace(' ', '') # 统计剩余字符数 remaining_char_count = len(remaining_text) |
Magpie
Magpie:
https://arxiv.org/html/2406.08464v2
https://zhuanlan.zhihu.com/p/717562402
直接从对齐的LLM中提取高质量指令数据来大规模合成高质量的指令数据
Our key observation is that aligned LLMs like Llama-3-Instruct can generate a user query when we input only the pre-query templates up to the position reserved for user messages, thanks to their auto-regressive nature.
We use this method to prompt Llama-3-Instruct and generate 4 million instructions along with their corresponding responses.
仅将pre-query模板输入到为用户消息保留的位置时,诸如Llama-3-Instruction之类的aligned LLM可以生成用户查询,这要归功于其auto-regressive性质。
仅输入左侧模板直到用户消息预留位置时,能够生成用户查询。
对齐LLM的典型输入包含三个关键组成部分:预查询模板、查询和后查询模板。例如,对Llama-2-chat的输入可以是“[INST] Hi! [/INST]”,其中[INST]是预查询模板,[/INST]是后查询模板。
我们使用这种方法来提示Llama-3-Instruct模型,并生成400万个说明及其相应的响应。
We further introduce extensions of Magpie for filtering, generating multi-turn, preference optimization, domain-specific and multilingual datasets.
我们进一步介绍了Magpie的扩展,用于过滤,生成多转,偏好优化,域特异性和多语言数据集。
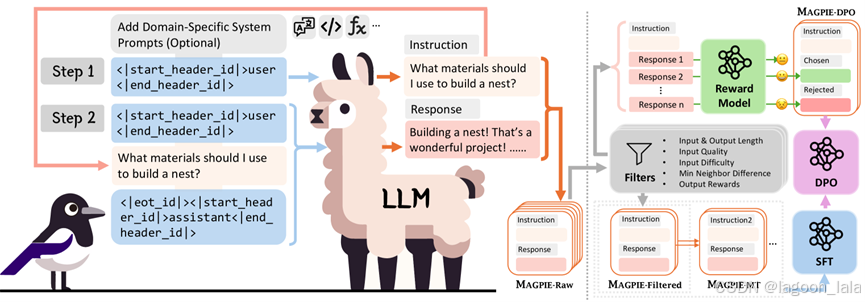

该图说明了如何使用系统提示来控制生成数学和中文指令。
用户prompt部分到end_head, 没有后续文字和eot_id, llm就会自动生成了
该系统提示为中文转换为:“您是AI助手,旨在为用户的中文问题提供准确,简洁的答案。”用户在中文中的回答翻译为:“我想了解AI的一些基本概念和历史发展趋势。”