ClickHouse 是一个开源的面向列的数据库管理系统。它在实时数据处理方面的出色性能显着增强了数据分析和业务洞察力。将数据从 Oracle 迁移到 ClickHouse 可以释放数据在决策中的力量,这是单独使用 Oracle 无法实现的。
本教程介绍如何使用 BladePipe 将数据从 Oracle 移动到 ClickHouse。默认情况下,它使用 ReplacingMergeTree 作为 ClickHouse 表引擎。该连接的主要功能包括:
在 ReplacingMergeTree 表中添加 and 字段。
_sign_version支持 DDL 同步。
关于 BladePipe
BladePipe 是一种实时端到端数据复制工具,可简化不同数据源(包括数据库、消息队列、实时数据仓库等)之间的数据移动。
通过使用变更数据捕获 (CDC) 技术,BladePipe 可以自动准确地跟踪、捕获和交付数据更改,并且具有超低延迟,大大提高了数据集成效率。它为需要实时数据复制的使用案例提供了可靠的解决方案,从而推动了数据驱动的决策和业务敏捷性。
突出
替换 MergeTree 优化
在早期版本的 BladePipe 中,在将数据同步到 ClickHouse 的 ReplacingMergeTree 表时,遵循了以下策略:
Insert 和 Update 语句被转换为 Insert 语句。
Delete 语句使用 ALTER TABLE DELETE 语句单独处理。
虽然效果很好,但当 Delete 语句数量较多时,可能会影响性能,导致高延迟。
在最新版本中,BladePipe 优化了 ReplacingMergeTree 表引擎中的同步逻辑、支持和字段。所有 Insert、Update 和 Delete 语句都转换为带有版本信息的 Insert 语句。_sign_version
Schema 迁移
当 Oracle 迁移 schema 到 ClickHouse 时,BladePipe 默认使用 ReplacingMergeTree 作为表引擎,并自动向表中添加 and 字段:_sign_version
CREATE TABLE console.worker_stats (`id` Int64,`gmt_create` DateTime,`worker_id` Int64,`cpu_stat` String,`mem_stat` String,`disk_stat` String,`_sign` UInt8 DEFAULT 0,`_version` UInt64 DEFAULT 0,INDEX `_version_minmax_idx` (`_version`) TYPE minmax GRANULARITY 1
) ENGINE = ReplacingMergeTree(`_version`, `_sign`) ORDER BY `id`数据写入
DML 转换
在数据写入过程中,BladePipe 采用以下 DML 转换策略:
在 Source 中插入语句:
-- Insert new data, _sign value is set to 0 INSERT INTO <schema>.<table> (columns, _sign, _version) VALUES (..., 0, <new_version>);Update Source 中的语句(转换为两个 Insert 语句):
-- Logically delete old data, _sign value is set to 1 INSERT INTO <schema>.<table> (columns, _sign, _version) VALUES (..., 1, <new_version>);-- Insert new data, _sign value is set to 0 INSERT INTO <schema>.<table> (columns, _sign, _version) VALUES (..., 0, <new_version>);删除 Source 中的语句:
-- Logically delete old data, _sign value is set to 1 INSERT INTO <schema>.<table> (columns, _sign, _version) VALUES (..., 1, <new_version>);
数据版本
在写入数据时,BladePipe 会维护每个表的版本信息:
版本初始化:在第一次写入期间,BladePipe 通过运行以下命令检索当前表的最新版本号:
SELECT MAX(`_version`) FROM `console`.`worker_stats`;版本增量:每次写入新数据时,BladePipe 都会根据之前检索到的最大版本号递增版本号,确保每个写入操作都有一个唯一且递增的版本号。
为确保查询中的数据准确性,请添加 final 关键字以过滤掉未删除的行:
SELECT `id`, `gmt_create`, `worker_id`, `cpu_stat`, `mem_stat`, `disk_stat`
FROM `console`.`worker_stats` final;程序
第 1 步:安装 BladePipe
按照 安装 Worker (Docker) 或 Install Worker (Binary) 中的说明下载并安装 BladePipe Worker。
步骤 2:添加数据源
登录 BladePipe 云。
单击 DataSource > Add DataSource(添加数据源)。
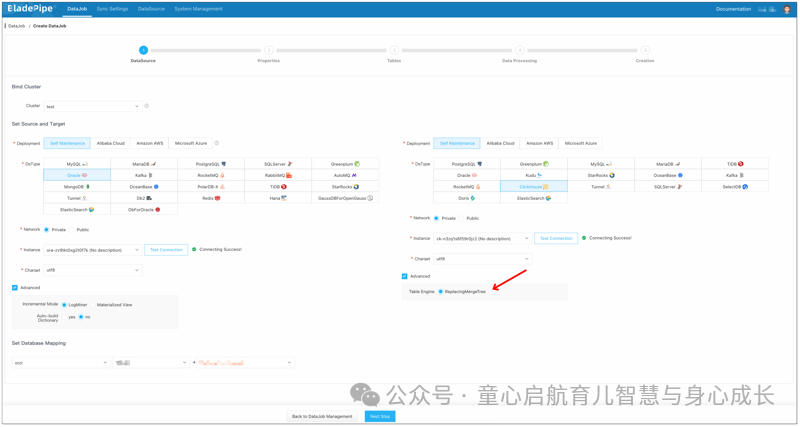
选择源和目标 DataSource 类型,并分别填写设置表单。

步骤 3:创建 DataJob
单击 DataJob >创建 DataJob。
选择源数据源和目标数据源,然后单击 Test Connection 以确保与源数据源和目标 DataSources 的连接都成功。
在目标 DataSource 的 Advanced 配置中,选择表引擎作为 ReplacingMergeTree(或 ReplicatedReplacingMergeTree)。
为 DataJob Type (DataJob 类型) 选择 Incremental (增量) 以及 Full Data (完整数据) 选项。
在 Specification settings (规范设置) 中,确保选择至少 1 GB 的规范。分配过少的内存可能会导致 DataJob 执行期间出现内存不足 (OOM) 错误。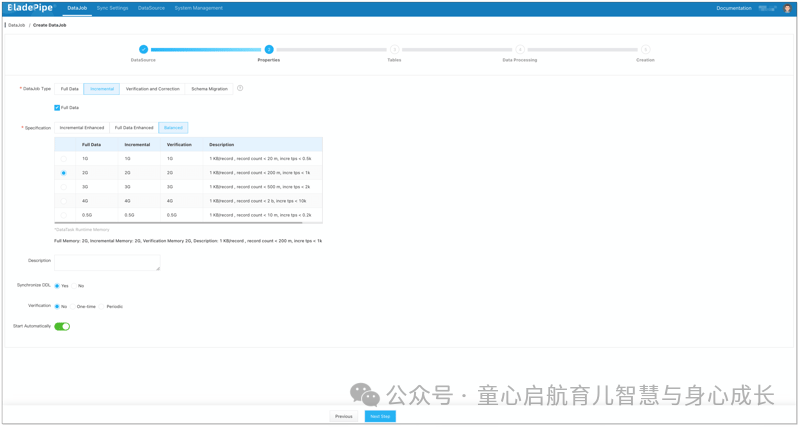
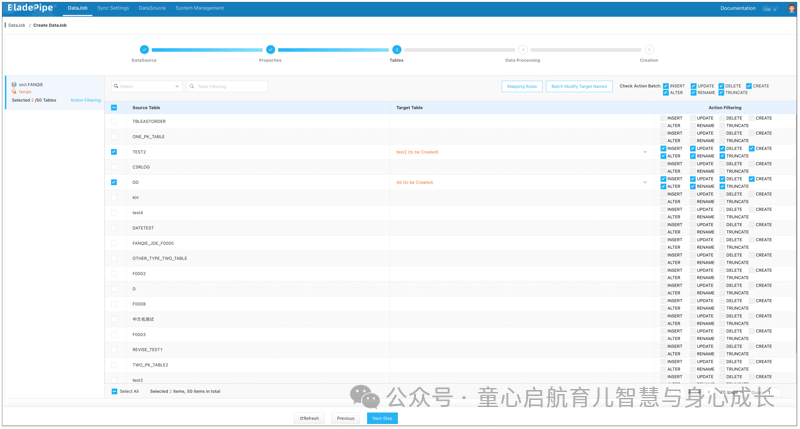
选择要复制的表。
选择要复制的列。
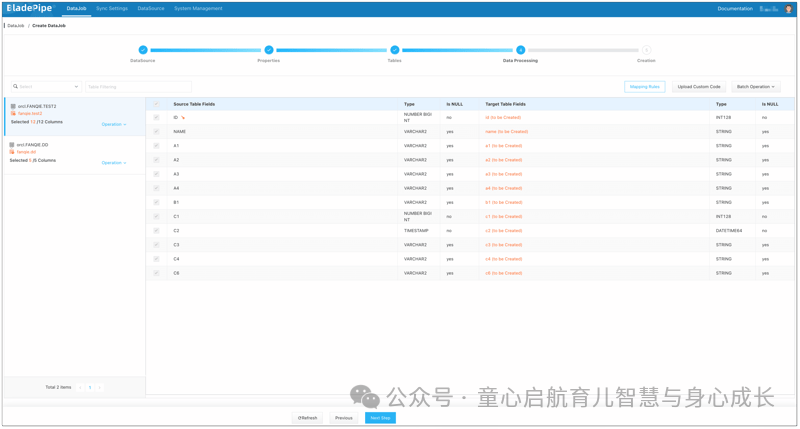
确认 DataJob 创建。
现在 DataJob 已创建并启动。BladePipe 会自动运行以下 DataTask:
Schema 迁移:源表的 Schema 将迁移到 ClickHouse。
全量数据迁移:源表的所有现有数据都将完全迁移到 ClickHouse。
增量同步:正在进行的数据更改将持续同步到目标数据库。

第 4 步:验证数据
停止 Source 数据库的数据写入,并等待 ClickHouse 合并数据。
很难知道 ClickHouse 何时自动合并数据,因此您可以通过运行命令来手动触发合并。请注意,此手动合并可能并不总是成功。
或者,您可以运行命令创建视图并对视图执行查询,以确保数据完全合并。optimize table xxx finalcreate view xxx_v as select * from xxx final创建 Verification DataJob。验证 DataJob 完成后,查看结果以确认 ClickHouse 中的数据与 Oracle 中的数据相同。

在本教程中,使用 BladePipe 在 3 个步骤中在几分钟内创建从 Oracle 到 ClickHouse 的数据管道。此外,您还可以在复制后验证数据,确保数据的准确性。



















