论文标题:Unified Training of Universal Time Series Forecasting Transformers
GitHub链接:https://github. com/SalesforceAIResearch/uni2ts
论文链接:https://arxiv.org/pdf/2402.02592
前言
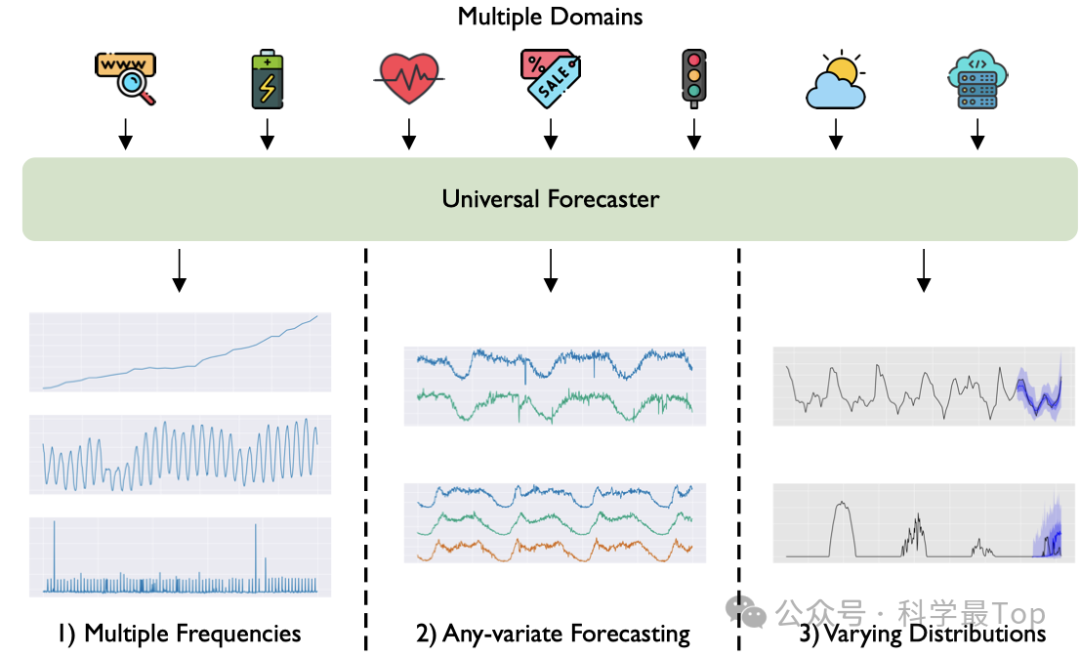
普适预测器是一个能够处理任何时间序列预测问题的大型预训练模型。它在跨多个领域的大规模时间序列数据集上进行训练。如图1,与现有范式相比,普适预测面临三个关键问题:i) 多频率,ii) 任意变量预测,iii) 分布变化。
为了解决这些挑战,本文对传统时间序列Transformer架构进行了新颖的增强,提出了——基于掩码编码器的普适时间序列预测Transformer(MOIRAI)。MOIRAI在新引入的大规模开放时间序列档案(LOTSA)上进行了训练,该档案包含了来自九个领域的超过270亿个观测值。作为零样本预测器,MOIRAI在性能上与全样本模型相比具有更优越的表现。
本文工作
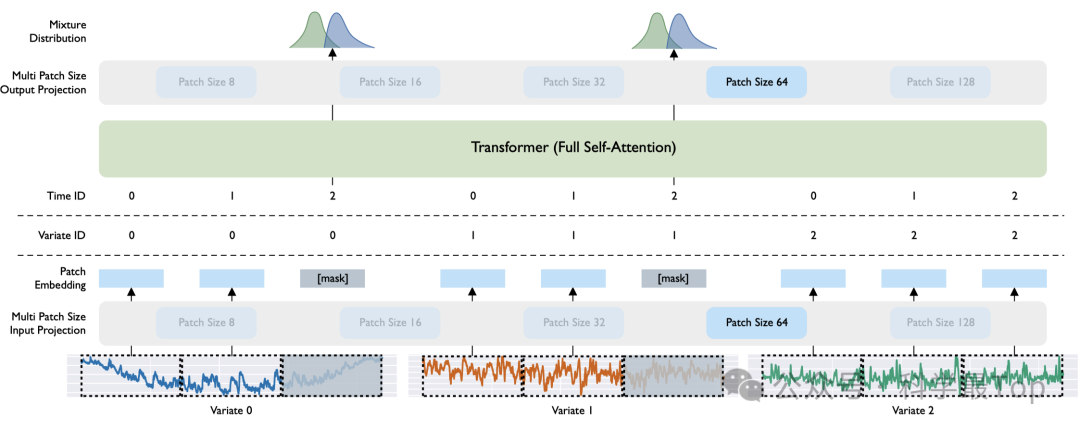
上图是本文MOIRAI框架图,
-
作者首先提出学习多个输入和输出投影层,以处理来自不同频率时间序列的不同模式。通过使用基于patch的投影,对于高频数据采用较大的patch大小,反之亦然,投影层专门学习该频率的模式。
-
其次,通过提出的任意变量注意力机制解决了维度变化的问题,该机制将时间和变量轴同时视为单个序列,利用旋转位置嵌入(RoPE)和学习的二元注意力偏差分别编码时间和变量轴。任意变量注意力机制允许模型输入任意数量的变量。
-
最后,通过混合参数分布解决了需要灵活预测分布的问题。此外,优化灵活分布的负对数似然具有与目标度量优化竞争的附加优势,这对于预训练普适预测器来说是一个强大的功能,因为它可以随后使用任何目标度量进行评估。
概括一下:
MOIRAI采用基于patch的非重叠方法,通过掩码编码器架构对时间序列进行建模。提出的将架构扩展到任意变量设置的一项修改是“展平”多变量时间序列,将所有变量视为单个序列。随后通过多patch大小输入投影层投影为向量表示。[mask]表示一个可学习的嵌入,替换掉预测范围内的patch(感觉和语言模型思路类似)。然后,输出token通过多patch大小输出投影解码为混合分布的参数。
核心Transformer模块是一个仅包含编码器的Transformer架构,利用了当前的大型语言模型架构提出的各种改进trick,包括:1)使用预归一化并用RMSNorm替换所有LayerNorm;2)应用了查询-键归一化;3)FFN层中的非线性被SwiGLU替换,调整隐藏维度以使参数数量与原始FFN层相同。在Transformer模块的所有层中省略了偏置。
实验分析和结果
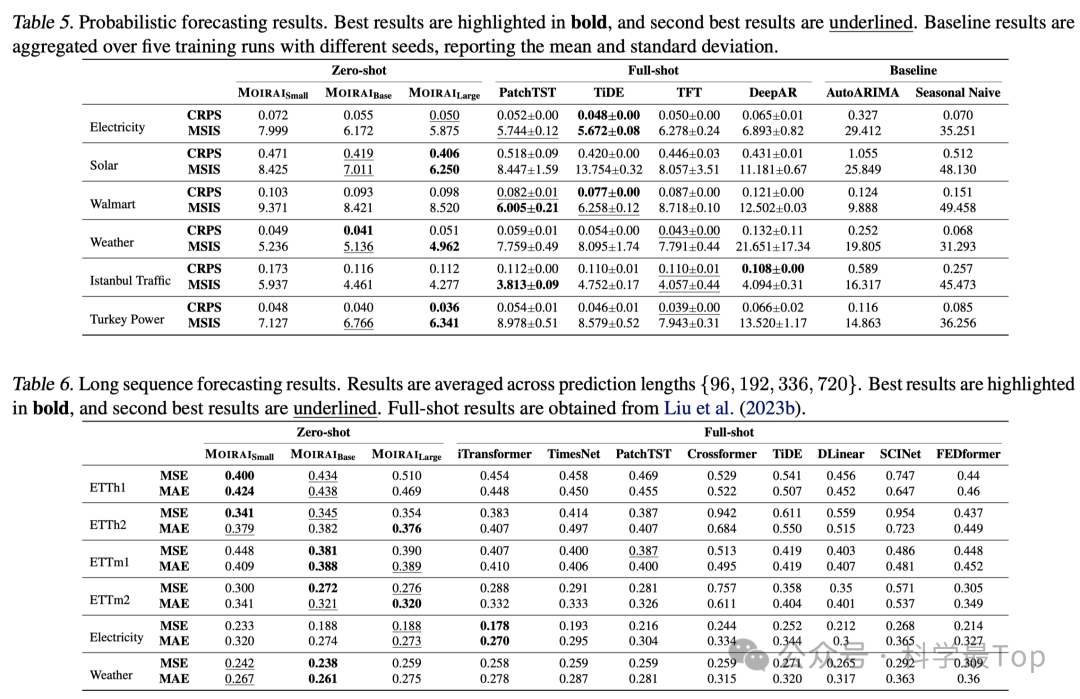
实验分析部分篇幅很大,这里只截取了部分结果。总结来说:MOIRAI在所有模型规模下都优于Monash基准中的所有基线,显示出统一训练方法带来的强大的分布内和跨领域能力。每个MOIRAI实例都是在多个数据集上评估的单一模型,而基线模型通常是每个数据集训练一个模型。
未来工作思考
参数和调优方面,几乎没有进行超参数调优。在架构方面,使用多patch大小映射来解决跨频率学习的问题,这种方法有些依赖经验性,灵活性不足。
对高维时间序列的支持有限,扩展Transformer输入长度的高效方法可以缓解这个问题。掩码编码器结构还使其适合探索潜在扩散架构。
在数据方面,LOTSA可以通过在领域和频率方面增加更多的多样性来进一步增强。最后,结合表格或文本输入等多模态普适预测也是一个新方向。
大家可以关注我【科学最top】,第一时间follow时序高水平论文解读!!!