大数据分析设计方案
1.数据集来源:https://search.jd.com
2.实现思路:
(1)数据爬取
首先,我们需要从京东平台上采集手机品牌的相关数据。可以通过网络爬虫或API接口等方式获取数据。为了保证数据的完整性和准确性,需要设置合理的爬虫策略,并处理可能出现的反爬机制。
(2)数据清洗与整合
采集到的原始数据可能存在格式不统一、缺失值、异常值等问题,需要进行数据清洗和整合。清洗过程中需要处理缺失值、异常值,并对数据进行标准化处理。此外,还需要将不同来源的数据进行整合,形成一个统一的数据集。
(3)数据分析
在数据清洗和整合的基础上,我们进行深入的数据分析。首先,可以通过描述性统计方法对手机品牌的基本情况进行统计分析,如品牌数量、市场份额等。其次,利用关联规则挖掘、聚类分析等数据挖掘方法对品牌之间的关联和分类进行分析。此外,还可以结合时间序列分析方法,对市场趋势进行预测。为了更加直观地展示数据分析结果,我们可以借助数据可视化技术将结果进行可视化展示。可以使用Python中的Matplotlib、Seaborn等可视化库进行图表绘制,如饼图、柱状图、散点图等。同时,可以利用数据可视化工具进行交互式的数据展示,提高可视化效果的可读性和易用性。
3.技术难点:
(1)数据获取
在数据获取阶段,需要从京东平台爬取手机品牌的相关数据。由于京东的反爬机制较为严格,可能会遇到诸如IP被封、需要登录等挑战。此外,如何有效地从网页中提取所需的数据也是一大难点。
(2)数据清洗与整合
原始数据可能存在缺失值、异常值等问题,需要进行数据清洗和整合。对于缺失值,需要根据业务实际情况进行处理,如填充缺失值、删除含有缺失值的记录等。对于异常值,需要结合业务逻辑和数据分布情况进行分析和处理。此外,如何将不同来源的数据进行有效整合也是一大难点。
(3)数据分析与可视化
在数据分析阶段,需要利用合适的分析方法对数据进行深入挖掘。这需要具备一定的数据挖掘和统计学知识,选择合适的方法对数据进行处理和分析。在可视化阶段,如何将数据分析结果以直观、易懂的方式展示出来是一大难点。此外,如何选择合适的可视化工具和图表类型也是需要考虑的问题。
三、数据分析步骤
(1)数据api接口获取
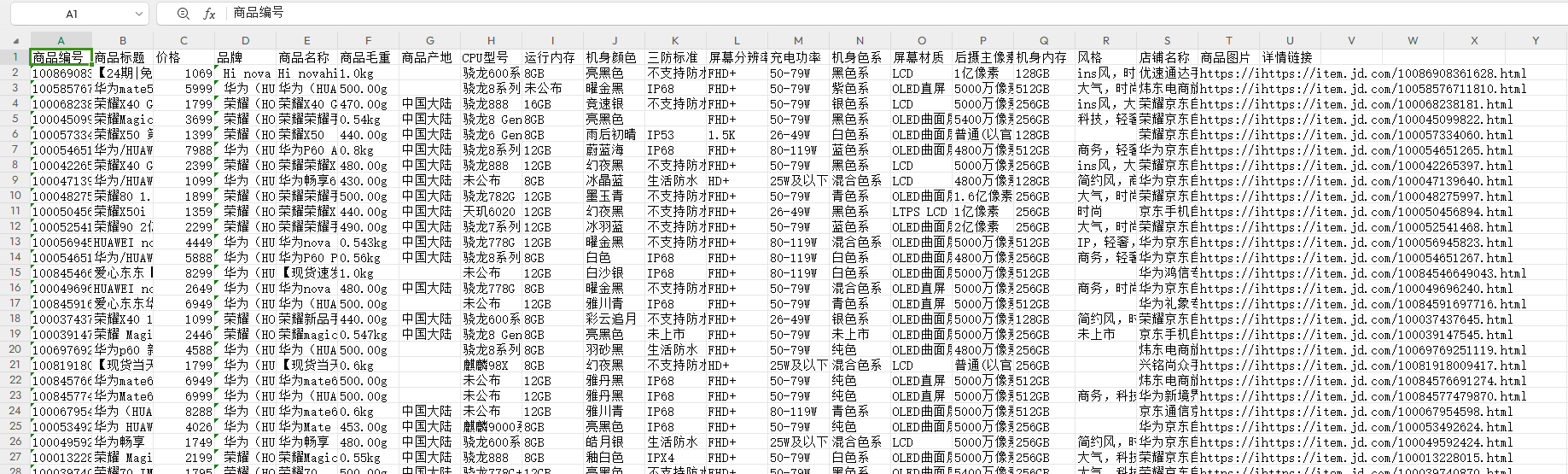
获取京东手机品牌信息数据api接口并保存为“京东手机.csv”文件
def save\_data(data\_list): global lock lock.acquire() try: with open("京东手机.csv", "a+", encoding='utf-8-sig', newline='') as csvfile: writer = csv.writer(csvfile) # 以读的方式打开csv 用csv.reader方式判断是否存在标题。 with open("京东手机.csv", "r", encoding='utf8', newline='') as f: reader = csv.reader(f) if not \[row for row in reader\]: # 先写入每一列的标题 writer.writerow( \["商品编号", "商品标题", "价格", "品牌", "商品名称", "商品毛重", "商品产地", "CPU型号", "运行内存", "机身颜色", "三防标准", "屏幕分辨率", "充电功率", "机身色系", "屏幕材质", "后摄主像素", '机身内存',"风格", "店铺名称",'商品图片', "详情链接"\]) # 再写入每一列的内容 writer.writerows(\[data\_list\]) csvfile.flush() else: writer.writerows(\[data\_list\]) csvfile.flush() finally: lock.release() def get\_index(url): print(f'抓取 {url}') response = requests.get(url,headers).text # 调用请求数据方法 soup = BeautifulSoup(response, 'lxml') # 实例化BeautifulSoup对象 J\_goodsList = soup.find('div', id='J\_goodsList').find\_all('li') # 匹配商品信息 for j\_good in J\_goodsList: # 循环遍历 try: sku\_id = j\_good\['data-sku'\] + '\\t' # 商品编号 ad\_title = j\_good.find('div', class\_='p-name').find('em').text.replace('<font class="skcolor\_ljg">', '').replace('</font>', '').replace( '\\n', '') # 商品标题 pc\_price = j\_good.find('div', class\_='p-price').find('i').text # 商品价格 shop\_name = j\_good.find('div', class\_='p-shop').find('a')\['title'\] # 商家名称 p\_img = 'https:' + j\_good.find('div', class\_='p-img').find('img')\['data-lazy-img'\] # 商品图片 link\_url = 'https:' + j\_good.find('a')\['href'\] # 商品链接 print(sku\_id, ad\_title, pc\_price, shop\_name, link\_url) pinpai, shangpinmincheng, shangpinmaozhong,shangpinchandi, CPUxinghao, yunxingneicun,jishenyanse, sanfangbiaozhun, pingmufenbianlv, chongdiangoglv, jishensexi, pingmucaizhi, houshezhuxiangsu, jisheneicun, fenge = get\_detail\_info(link\_url) data\_list = \[sku\_id, ad\_title, pc\_price,pinpai, shangpinmincheng, shangpinmaozhong,shangpinchandi, CPUxinghao, yunxingneicun,jishenyanse, sanfangbiaozhun, pingmufenbianlv, chongdiangoglv, jishensexi, pingmucaizhi, houshezhuxiangsu, jisheneicun, fenge, shop\_name,p\_img, link\_url\] #print(data\_list) save\_data(data\_list) time.sleep(random.random() + 5) except: continue
结果:


(2)数据清洗与整合
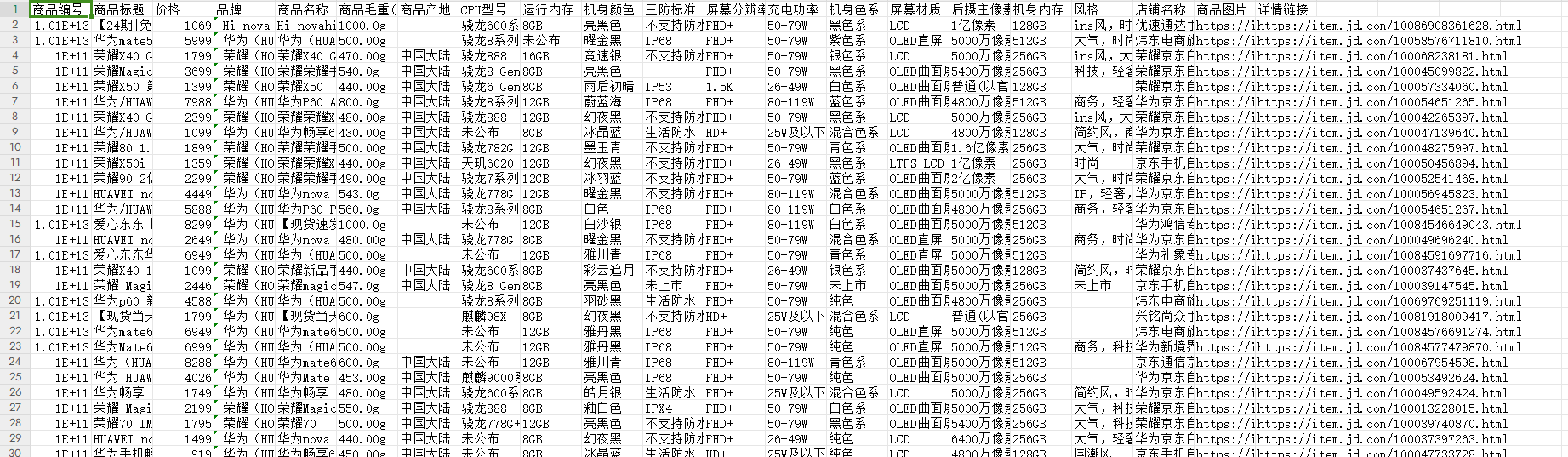
1、导入数据集
1 import pandas as pd
2 import os
3
4 # 读取csv文件
5 file\_path = r"京东手机.csv"
6 df = pd.read\_csv(file\_path)
2、删除重复行
1 pd.drop_duplicates(df.duplicated())
3、将编号改为字符类型
1 df[“商品编号”] = df[“商品编号”].astype(“str”)
4、填充缺失值
1 df[“机身内存”].fillna(“未知”, inplace = True)
5、将清洗后的数据整合并保存至“京东手机_清洗后.csv”文件

(3)数据可视化分析
**1、折线图 - 京东售卖手机屏幕材质分布**
1 # 1、折线图 - 京东售卖手机屏幕材质分布2 df = data\['屏幕材质'\].value\_counts()3 x = df.index 4 y = df.values 5 # 设置画布的尺寸6 plt.figure(figsize=(12, 10))7 # 创建折线图8 plt.plot(x, y)9 # 添加标题
10 plt.title('京东售卖手机屏幕材质分布')
11 # 设置横坐标字体倾斜
12 plt.xticks(rotation=-80)
13 # 图上显示数字
14 for i in range(len(x)):
15 plt.text(x\[i\], y\[i\], y\[i\], ha='center', va='bottom')
16 plt.ylabel('数量')
17 plt.show()
结果:

由此折线图可以看出,大多数手机都采取直屏的材质分布。
**2、条形图 - 出售手机排名前十的店铺分布**
1 # 2、条形图 - 出售手机排名前十的店铺分布2 df = data\['店铺名称'\].value\_counts().sort\_values(ascending=False)\[:10\]3 x = df.index 4 y = df.values 5 plt.figure(figsize=(12, 10)) # 设置画布的尺寸6 # 创建条形图7 plt.bar(x, y)8 # 添加标题9 plt.title('出售手机排名前十的店铺')
10 # 设置横坐标字体倾斜
11 plt.xticks(rotation=-80)
12 # 图上显示数字
13 for i in range(len(x)):
14 plt.text(x\[i\], y\[i\], y\[i\], ha='center', va='bottom')
15 plt.ylabel('数量')
16 plt.show()
结果:
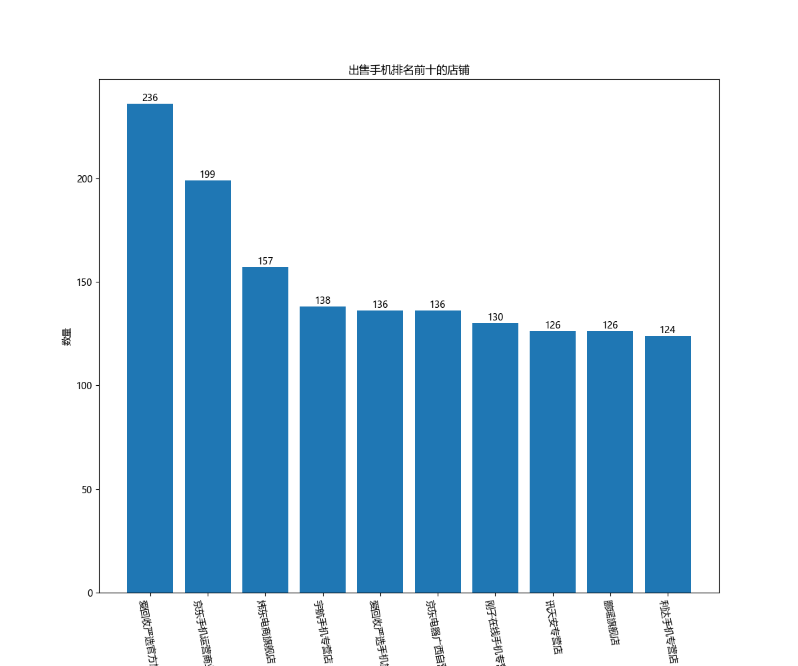
由此条形图可以通过对销量较好的店铺作为参考,发现哪些商品最受消费者欢迎,从而为手机品牌和商家提供有价值的参考信息,帮助他们更好地制定产品策略。
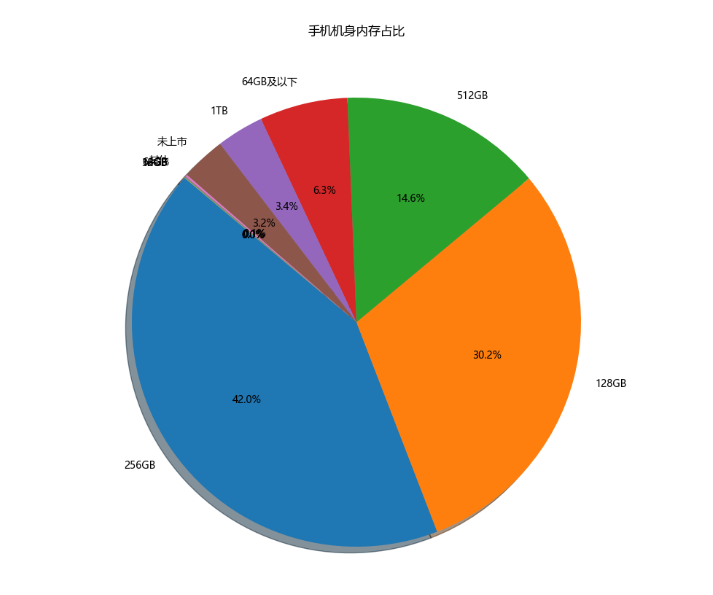
**3、饼图 - 手机机身内存占比
**
1 # 3、饼图 - 手机机身内存占比
2 memory = data\['机身内存'\].value\_counts()
3 plt.figure(figsize=(12, 10)) # 设置画布的尺寸
4 plt.pie(memory.values.tolist(), labels=memory.index.tolist(), autopct='%1.1f%%', shadow=True, startangle=140)
5 # 添加标题
6 plt.title('手机机身内存占比')
7 plt.show()
结果:
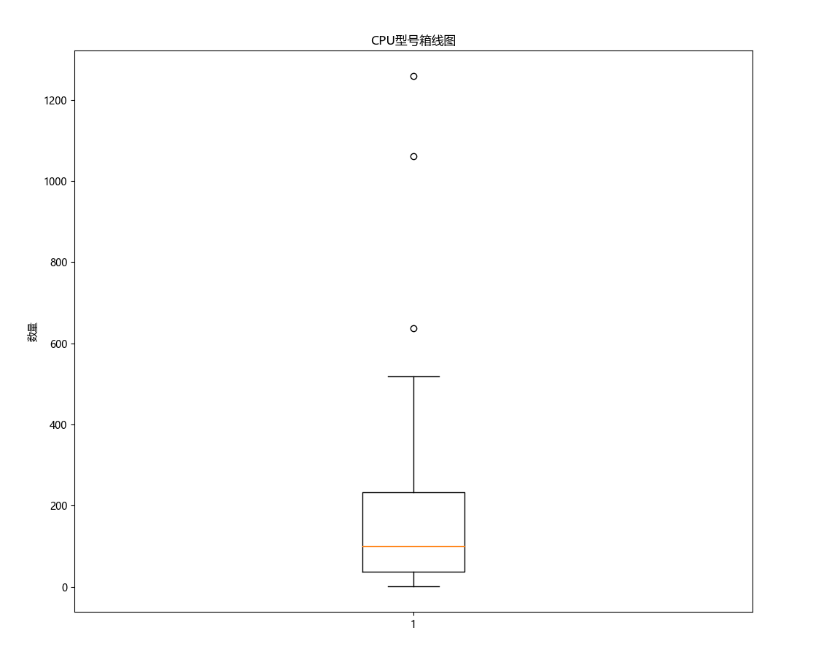
**4、箱线图 - CPU型号箱线图**
1 # 4、箱线图 - CPU型号箱线图
2 memory = data\['CPU型号'\].value\_counts()
3 plt.figure(figsize=(12, 10)) # 设置画布的尺寸
4 plt.boxplot(memory.values.tolist())
5 # 添加标题
6 plt.title('CPU型号箱线图')
7 plt.ylabel('数量')
8 plt.show()
结果:
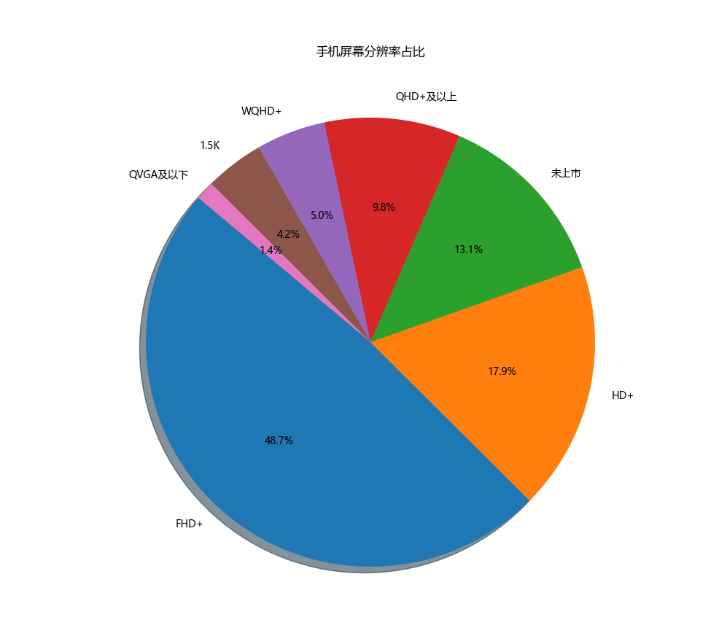
**5、饼图 - 手机屏幕分辨率占比
**
1 # 5、饼图 - 手机屏幕分辨率占比
2 memory = data\['屏幕分辨率'\].value\_counts()
3 plt.figure(figsize=(12, 10)) # 设置画布的尺寸
4 plt.pie(memory.values.tolist(), labels=memory.index.tolist(), autopct='%1.1f%%', shadow=True, startangle=140)
5 # 添加标题
6 plt.title('手机屏幕分辨率占比')
7 plt.show()
结果:
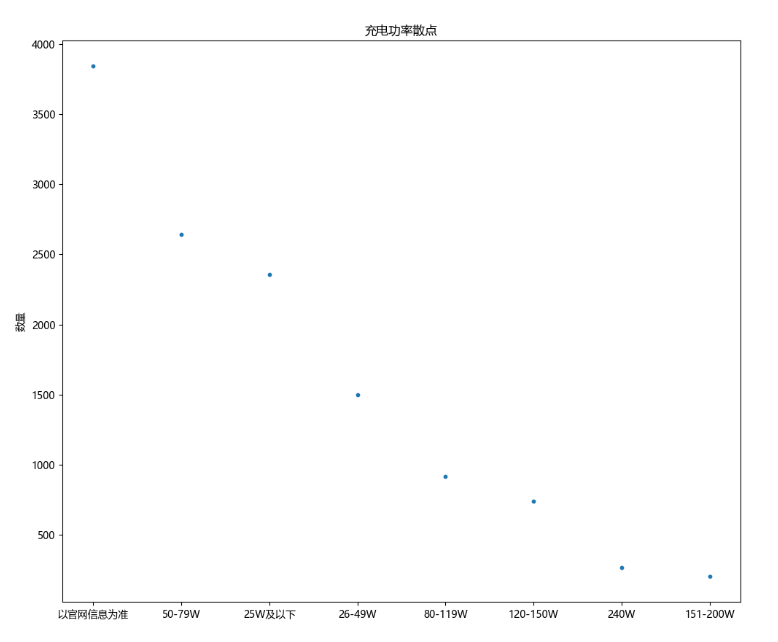
**6、散点图-充电功率散点**
1 # 6、散点图-充电功率散点
2 df = data\['充电功率'\].value\_counts()
3 plt.figure(figsize=(12, 10)) # 设置画布的尺寸
4 plt.scatter(df.index, df.values, s=10)
5 plt.title('充电功率散点')
6 plt.ylabel('数量')
7 plt.show()
结果:
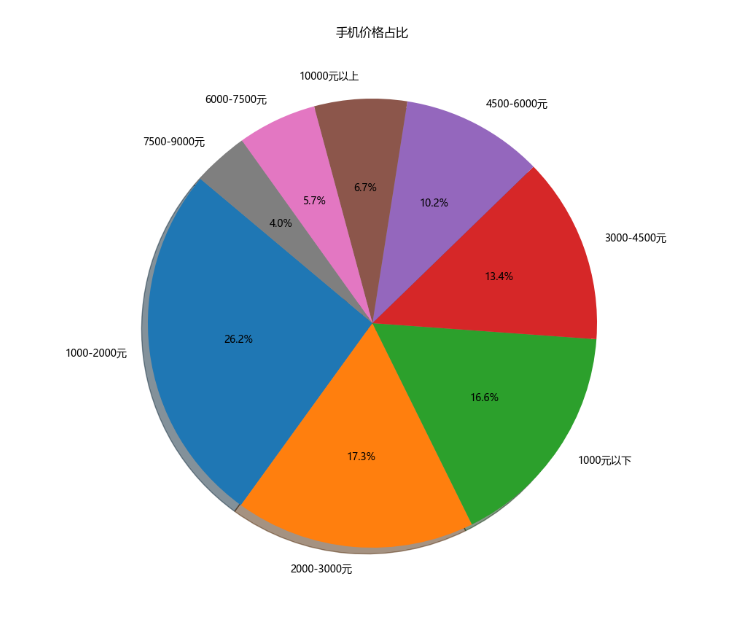
**7、饼图 - 手机价格占比**
1 # 7、饼图 - 手机价格占比2 money\_list = data\['价格'\]3 current\_list = \[\] 4 for money in money\_list: 5 money = int(money) 6 if money < 1000:7 current\_list.append('1000元以下')8 elif money >= 1000 and money < 2000:9 current\_list.append('1000-2000元')
10 elif money >= 2000 and money < 3000:
11 current\_list.append('2000-3000元')
12 elif money >= 3000 and money < 4500:
13 current\_list.append('3000-4500元')
14 elif money >= 4500 and money < 6000:
15 current\_list.append('4500-6000元')
16 elif money >= 6000 and money < 7500:
17 current\_list.append('6000-7500元')
18 elif money >= 7500 and money < 9000:
19 current\_list.append('7500-9000元')
20 else:
21 current\_list.append('10000元以上')
22
23 money\_list = pd.DataFrame(current\_list, columns=\['价格'\])
24 money\_list = money\_list\['价格'\].value\_counts()
25 l1 = money\_list.index.tolist()
26 l2 = money\_list.values.tolist()
27 plt.figure(figsize=(12, 10)) # 设置画布的尺寸
28 plt.pie(l2, labels=l1, autopct='%1.1f%%', shadow=True, startangle=140)
29 # 添加标题
30 plt.title('手机价格占比')
31 plt.show()
结果:
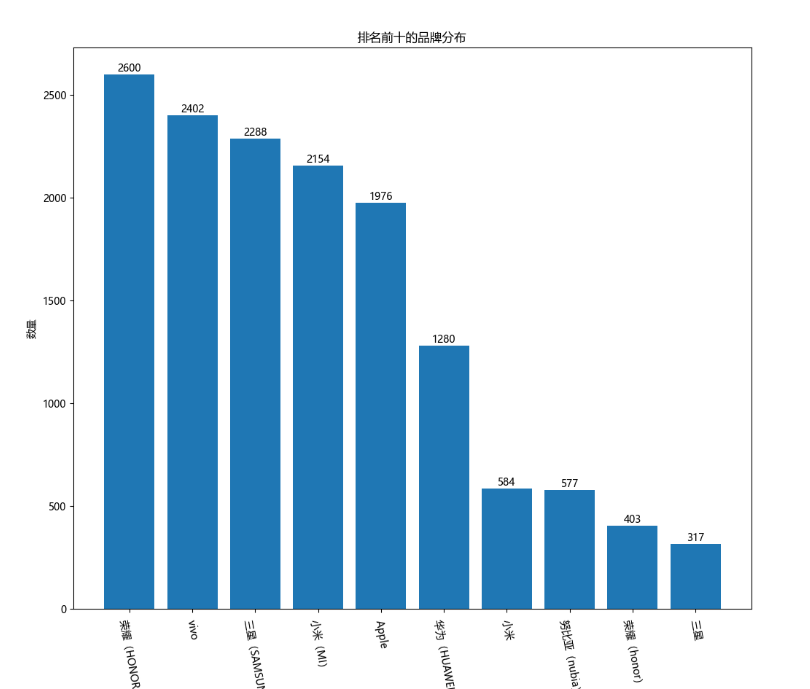
**8、条形图 - 排名前十的品牌分布**
1 df = data\['品牌'\].value\_counts().sort\_values(ascending=False)\[:10\]2 x = df.index 3 y = df.values 4 plt.figure(figsize=(12, 10)) # 设置画布的尺寸5 # 创建条形图6 plt.bar(x, y)7 # 添加标题8 plt.title('排名前十的品牌分布')9 # 设置横坐标字体倾斜
10 plt.xticks(rotation=-80)
11 # 图上显示数字
12 for i in range(len(x)):
13 plt.text(x\[i\], y\[i\], y\[i\], ha='center', va='bottom')
14 plt.ylabel('数量')
15 plt.show()
结果:
**9、折线图 - 三防标准分布**
1 # 9、折线图 - 三防标准分布2 df = data\['三防标准'\].value\_counts()3 x = df.index 4 y = df.values 5 # 设置画布的尺寸6 plt.figure(figsize=(12, 10))7 # 创建折线图8 plt.plot(x, y)9 # 添加标题
10 plt.title('三防标准分布')
11 # 设置横坐标字体倾斜
12 plt.xticks(rotation=-80)
13 # 图上显示数字
14 for i in range(len(x)):
15 plt.text(x\[i\], y\[i\], y\[i\], ha='center', va='bottom')
16 plt.ylabel('数量')
17 plt.show()
结果:

**10、词云-手机风格词云**
1 #10、词云-手机风格词云2 words\_= \[\] #创建列表,用来装风格列数据3 for word in data\['风格'\].values.tolist():4 for w in str(word).split(','):5 if w!='nan':6 if '未上市' not in w: 7 words\_.append(w)8 9 df = pd.DataFrame(words\_).value\_counts() #统计
10 # 创建词频字典
11 word\_list = \[\]
12 for x in df.index.tolist():
13 word\_list.append(x\[0\])
14 word\_freq = dict(zip(word\_list,df.values.tolist()))
15 wordcloud = WordCloud(font\_path="simfang.ttf",background\_color='white', height=400, width=800, scale=20, prefer\_horizontal=0.9999).generate\_from\_frequencies(word\_freq)
16 plt.imshow(wordcloud, interpolation="bilinear")
17 plt.title('京东售卖手机风格词云图')
18 plt.axis("off")
19 plt.show()
结果:

(4)完整代码
1 #获取商品手机api2 import csv 3 import random 4 import threading 5 import time 6 import requests 7 from bs4 import BeautifulSoup 8 from concurrent.futures import ThreadPoolExecutor 9 10 #需要添加cookie11 headers = { 12 'Origin': 'https://search.jd.com',13 'Referer': 'https://search.jd.com/',14 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36',15 'X-Referer-Page': 'https://search.jd.com/Search',16 'Cookie':''17 }18 19 lock = threading.Lock() 20 def save\_data(data\_list): 21 global lock 22 lock.acquire()23 try:24 with open("京东手机.csv", "a+", encoding='utf-8-sig', newline='') as csvfile:25 writer = csv.writer(csvfile) 26 # 以读的方式打开csv 用csv.reader方式判断是否存在标题。27 with open("京东手机.csv", "r", encoding='utf8', newline='') as f:28 reader = csv.reader(f) 29 if not \[row for row in reader\]: 30 # 先写入每一列的标题31 writer.writerow(32 \["商品编号", "商品标题", "价格", "品牌", "商品名称", "商品毛重",33 "商品产地", "CPU型号", "运行内存", "机身颜色", "三防标准", "屏幕分辨率", "充电功率",34 "机身色系", "屏幕材质", "后摄主像素", '机身内存',"风格", "店铺名称",'商品图片',35 "详情链接"\])36 # 再写入每一列的内容37 writer.writerows(\[data\_list\])38 csvfile.flush()39 else:40 writer.writerows(\[data\_list\])41 csvfile.flush()42 finally:43 lock.release()44 45 def get\_index(url): 46 print(f'抓取 {url}')47 response = requests.get(url,headers).text # 调用请求数据方法48 soup = BeautifulSoup(response, 'lxml') # 实例化BeautifulSoup对象49 J\_goodsList = soup.find('div', id='J\_goodsList').find\_all('li') # 匹配商品信息50 for j\_good in J\_goodsList: # 循环遍历51 try:52 sku\_id = j\_good\['data-sku'\] + '\\t' # 商品编号53 ad\_title = j\_good.find('div', class\_='p-name').find('em').text.replace('<font class="skcolor\_ljg">',54 '').replace('</font>', '').replace(55 '\\n', '') # 商品标题56 pc\_price = j\_good.find('div', class\_='p-price').find('i').text # 商品价格57 shop\_name = j\_good.find('div', class\_='p-shop').find('a')\['title'\] # 商家名称58 p\_img = 'https:' + j\_good.find('div', class\_='p-img').find('img')\['data-lazy-img'\] # 商品图片59 link\_url = 'https:' + j\_good.find('a')\['href'\] # 商品链接60 61 print(sku\_id, ad\_title, pc\_price, shop\_name, link\_url)62 pinpai, shangpinmincheng, shangpinmaozhong,shangpinchandi, CPUxinghao, yunxingneicun,jishenyanse, sanfangbiaozhun, pingmufenbianlv, chongdiangoglv, jishensexi, pingmucaizhi, houshezhuxiangsu, jisheneicun, fenge = get\_detail\_info(link\_url) 63 data\_list = \[sku\_id, ad\_title, pc\_price,pinpai, shangpinmincheng, shangpinmaozhong,shangpinchandi, CPUxinghao, yunxingneicun,jishenyanse, sanfangbiaozhun, pingmufenbianlv, chongdiangoglv, jishensexi, pingmucaizhi, houshezhuxiangsu, jisheneicun, fenge, shop\_name,p\_img, link\_url\] 64 #print(data\_list)65 save\_data(data\_list)66 time.sleep(random.random() + 5)67 except:68 continue69 70 def get\_detail\_info(url): 71 detail\_html = requests.get(url, headers=headers).text # 通过链接向服务器发送请求72 soup = BeautifulSoup(detail\_html, 'lxml') # 实例化BeautifulSoup对象73 p\_parameter = soup.find('div', class\_='p-parameter').find\_all(74 'li') # 查找标签为div,class为p-parameter的节点,并查找该节点下所有标签为li的节点75 pinpai, shangpinmincheng, shangpinmaozhong,shangpinchandi, CPUxinghao, yunxingneicun,jishenyanse, sanfangbiaozhun, pingmufenbianlv, chongdiangoglv, jishensexi, pingmucaizhi, houshezhuxiangsu, jisheneicun, fenge = '', '', '', '', '', '', '', '', '', '', '', '', '', '', ''76 for parameter in p\_parameter: # 循环遍历获取节点信息77 item = parameter.text.split(':') # 获取文本内容78 #print(item)79 if '品牌' == item\[0\]: 80 pinpai = str(item\[1\]).replace('\\n', '')81 elif '商品名称' == item\[0\]: 82 shangpinmincheng = item\[1\]83 elif '商品毛重' == item\[0\]: 84 shangpinmaozhong = item\[1\]85 elif '商品产地' == item\[0\]: 86 shangpinchandi = item\[1\]87 elif 'CPU型号' == item\[0\]: 88 CPUxinghao = item\[1\]89 elif '运行内存' == item\[0\]: 90 yunxingneicun = item\[1\]91 elif '机身颜色' == item\[0\]: 92 jishenyanse = item\[1\]93 elif '三防标准' == item\[0\]: 94 sanfangbiaozhun = item\[1\]95 elif '屏幕分辨率' == item\[0\]: 96 pingmufenbianlv = item\[1\]97 elif '充电功率' == item\[0\]: 98 chongdiangoglv = item\[1\]99 elif '机身色系' == item\[0\]:
100 jishensexi = item\[1\]
101 elif '屏幕材质' == item\[0\]:
102 pingmucaizhi = item\[1\]
103 elif '后摄主像素' == item\[0\]:
104 houshezhuxiangsu = item\[1\]
105 elif '机身内存' == item\[0\] :
106 jisheneicun = item\[1\]
107 elif '风格' == item\[0\]:
108 fenge = item\[1\]
109
110 return pinpai, shangpinmincheng, shangpinmaozhong,shangpinchandi, CPUxinghao, yunxingneicun,jishenyanse, sanfangbiaozhun, pingmufenbianlv, chongdiangoglv, jishensexi, pingmucaizhi, houshezhuxiangsu, jisheneicun, fenge
111
112
113 if \_\_name\_\_ == '\_\_main\_\_':
114 phone\_keyword\_list = \['华为手机','荣耀手机','小米手机','vivo手机','三星手机','苹果手机','努比亚手机','中兴手机','联想手机','红米手机','诺基亚手机','索尼手机','菲利普手机'\]
115 '''for keyword in phone\_keyword\_list:
116 for pn in range(1,101):
117 try:
118 get\_index(keyword,pn)
119 time.sleep(random.random()+5)
120 except:
121 break'''
122 url\_list = \[\]
123 for keyword in phone\_keyword\_list:
124 for pn in range(1, 101):
125 url = f'https://search.jd.com/Search?keyword={keyword}&page={pn}'
126 url\_list.append(url)
127
128 with ThreadPoolExecutor(max\_workers=3) as executor:
129 for url in url\_list:
130 executor.submit(get\_index, url)
131 #数据清洗
132 import pandas as pd
133 import os
134
135 # 读取csv文件
136 file\_path = r"京东手机.csv"
137 df = pd.read\_csv(file\_path)
138
139 # 删除重复行
140 pd.drop\_duplicates(df.duplicated())
141 # 将编号改为字符类型
142 df\["商品编号"\] = df\["商品编号"\].astype("str")
143 # 填充缺失值
144 df\["机身内存"\].fillna("未知", inplace = True)
145 #数据可视化分析
146 import os
147 import pandas as pd
148 import matplotlib.pyplot as plt
149 from wordcloud import WordCloud
150 plt.rcParams\['font.family'\] = 'Microsoft YaHei' #设置字体
151
152 def visual\_analytics():
153 file = f'京东手机\_清洗后.csv'
154 if not os.path.exists(file): #判断文件是否存在
155 print(f'{file}文件不存在')
156 else:
157 file = f'京东手机\_清洗后.csv'
158 data = pd.read\_csv(file, encoding='utf-8') # 读取csv文件
159
160 # 1、折线图 - 京东售卖手机屏幕材质分布
161 df = data\['屏幕材质'\].value\_counts()
162 x = df.index
163 y = df.values
164 # 设置画布的尺寸
165 plt.figure(figsize=(12, 10))
166 # 创建折线图
167 plt.plot(x, y)
168 # 添加标题
169 plt.title('京东售卖手机屏幕材质分布')
170 # 设置横坐标字体倾斜
171 plt.xticks(rotation=-80)
172 # 图上显示数字
173 for i in range(len(x)):
174 plt.text(x\[i\], y\[i\], y\[i\], ha='center', va='bottom')
175 plt.ylabel('数量')
176 plt.show()
177
178 # 2、条形图 - 出售手机排名前十的店铺分布
179 df = data\['店铺名称'\].value\_counts().sort\_values(ascending=False)\[:10\]
180 x = df.index
181 y = df.values
182 plt.figure(figsize=(12, 10)) # 设置画布的尺寸
183 # 创建条形图
184 plt.bar(x, y)
185 # 添加标题
186 plt.title('出售手机排名前十的店铺')
187 # 设置横坐标字体倾斜
188 plt.xticks(rotation=-80)
189 # 图上显示数字
190 for i in range(len(x)):
191 plt.text(x\[i\], y\[i\], y\[i\], ha='center', va='bottom')
192 plt.ylabel('数量')
193 plt.show()
194
195 # 3、饼图 - 手机机身内存占比
196 memory = data\['机身内存'\].value\_counts()
197 plt.figure(figsize=(12, 10)) # 设置画布的尺寸
198 plt.pie(memory.values.tolist(), labels=memory.index.tolist(), autopct='%1.1f%%', shadow=True, startangle=140)
199 # 添加标题
200 plt.title('手机机身内存占比')
201 plt.show()
202
203 # 4、箱线图 - CPU型号箱线图
204 memory = data\['CPU型号'\].value\_counts()
205 plt.figure(figsize=(12, 10)) # 设置画布的尺寸
206 plt.boxplot(memory.values.tolist())
207 # 添加标题
208 plt.title('CPU型号箱线图')
209 plt.ylabel('数量')
210 plt.show()
211
212 # 5、饼图 - 手机屏幕分辨率占比
213 memory = data\['屏幕分辨率'\].value\_counts()
214 plt.figure(figsize=(12, 10)) # 设置画布的尺寸
215 plt.pie(memory.values.tolist(), labels=memory.index.tolist(), autopct='%1.1f%%', shadow=True, startangle=140)
216 # 添加标题
217 plt.title('手机屏幕分辨率占比')
218 plt.show()
219
220 # 6、散点图-充电功率散点
221 df = data\['充电功率'\].value\_counts()
222 plt.figure(figsize=(12, 10)) # 设置画布的尺寸
223 plt.scatter(df.index, df.values, s=10)
224 plt.title('充电功率散点')
225 plt.ylabel('数量')
226 plt.show()
227
228 # 7、饼图 - 手机价格占比
229 money\_list = data\['价格'\]
230 current\_list = \[\]
231 for money in money\_list:
232 money = int(money)
233 if money < 1000:
234 current\_list.append('1000元以下')
235 elif money >= 1000 and money < 2000:
236 current\_list.append('1000-2000元')
237 elif money >= 2000 and money < 3000:
238 current\_list.append('2000-3000元')
239 elif money >= 3000 and money < 4500:
240 current\_list.append('3000-4500元')
241 elif money >= 4500 and money < 6000:
242 current\_list.append('4500-6000元')
243 elif money >= 6000 and money < 7500:
244 current\_list.append('6000-7500元')
245 elif money >= 7500 and money < 9000:
246 current\_list.append('7500-9000元')
247 else:
248 current\_list.append('10000元以上')
249
250 money\_list = pd.DataFrame(current\_list, columns=\['价格'\])
251 money\_list = money\_list\['价格'\].value\_counts()
252 l1 = money\_list.index.tolist()
253 l2 = money\_list.values.tolist()
254 plt.figure(figsize=(12, 10)) # 设置画布的尺寸
255 plt.pie(l2, labels=l1, autopct='%1.1f%%', shadow=True, startangle=140)
256 # 添加标题
257 plt.title('手机价格占比')
258 plt.show()
259
260 # 8、条形图 - 排名前十的品牌分布
261 df = data\['品牌'\].value\_counts().sort\_values(ascending=False)\[:10\]
262 x = df.index
263 y = df.values
264 plt.figure(figsize=(12, 10)) # 设置画布的尺寸
265 # 创建条形图
266 plt.bar(x, y)
267 # 添加标题
268 plt.title('排名前十的品牌分布')
269 # 设置横坐标字体倾斜
270 plt.xticks(rotation=-80)
271 # 图上显示数字
272 for i in range(len(x)):
273 plt.text(x\[i\], y\[i\], y\[i\], ha='center', va='bottom')
274 plt.ylabel('数量')
275 plt.show()
276
277 # 9、折线图 - 三防标准分布
278 df = data\['三防标准'\].value\_counts()
279 x = df.index
280 y = df.values
281 # 设置画布的尺寸
282 plt.figure(figsize=(12, 10))
283 # 创建折线图
284 plt.plot(x, y)
285 # 添加标题
286 plt.title('三防标准分布')
287 # 设置横坐标字体倾斜
288 plt.xticks(rotation=-80)
289 # 图上显示数字
290 for i in range(len(x)):
291 plt.text(x\[i\], y\[i\], y\[i\], ha='center', va='bottom')
292 plt.ylabel('数量')
293 plt.show()
294
295 #10、词云-手机风格词云
296 words\_= \[\] #创建列表,用来装风格列数据
297 for word in data\['风格'\].values.tolist():
298 for w in str(word).split(','):
299 if w!='nan':
300 if '未上市' not in w:
301 words\_.append(w)
302
303 df = pd.DataFrame(words\_).value\_counts() #统计
304 # 创建词频字典
305 word\_list = \[\]
306 for x in df.index.tolist():
307 word\_list.append(x\[0\])
308 word\_freq = dict(zip(word\_list,df.values.tolist()))
309 wordcloud = WordCloud(font\_path="simfang.ttf",background\_color='white', height=400, width=800, scale=20, prefer\_horizontal=0.9999).generate\_from\_frequencies(word\_freq)
310 plt.imshow(wordcloud, interpolation="bilinear")
311 plt.title('京东售卖手机风格词云图')
312 plt.axis("off")
313 plt.show()
314
315 if \_\_name\_\_ == '\_\_main\_\_':
316 visual\_analytics()
如有侵权,请联系删除。