引言
今天带来一篇优化函数调用的论文笔记——An LLM Compiler for Parallel Function Calling。
为了简单,下文中以翻译的口吻记录,比如替换"作者"为"我们"。

当前的函数(工具)调用方法通常需要对每个函数进行顺序推理和操作,比如,ReAct模式。这会导致高延迟、高成本有时还会出现不准确的行为。为此,我们引入LLMCompiler,它并行执行函数以有效地协调多个函数调用。
通过三个组件实现并行函数调用:
- 函数调用规划器,制定函数调用的执行计划;
- 任务获取单元,调度函数调用任务;
- 执行器,并行执行这些任务;
代码开源在: https://github.com/SqueezeAILab/LLMCompiler
1. 总体介绍
LLM具有整合各种工具和函数调用能力的潜力,但也带来了一个挑战,如何有效地整合多个函数调用?ReAct通过LLM调用一个函数,并分析其结果,然后推断下一个动作,该动作可能涉及后续的函数调用。
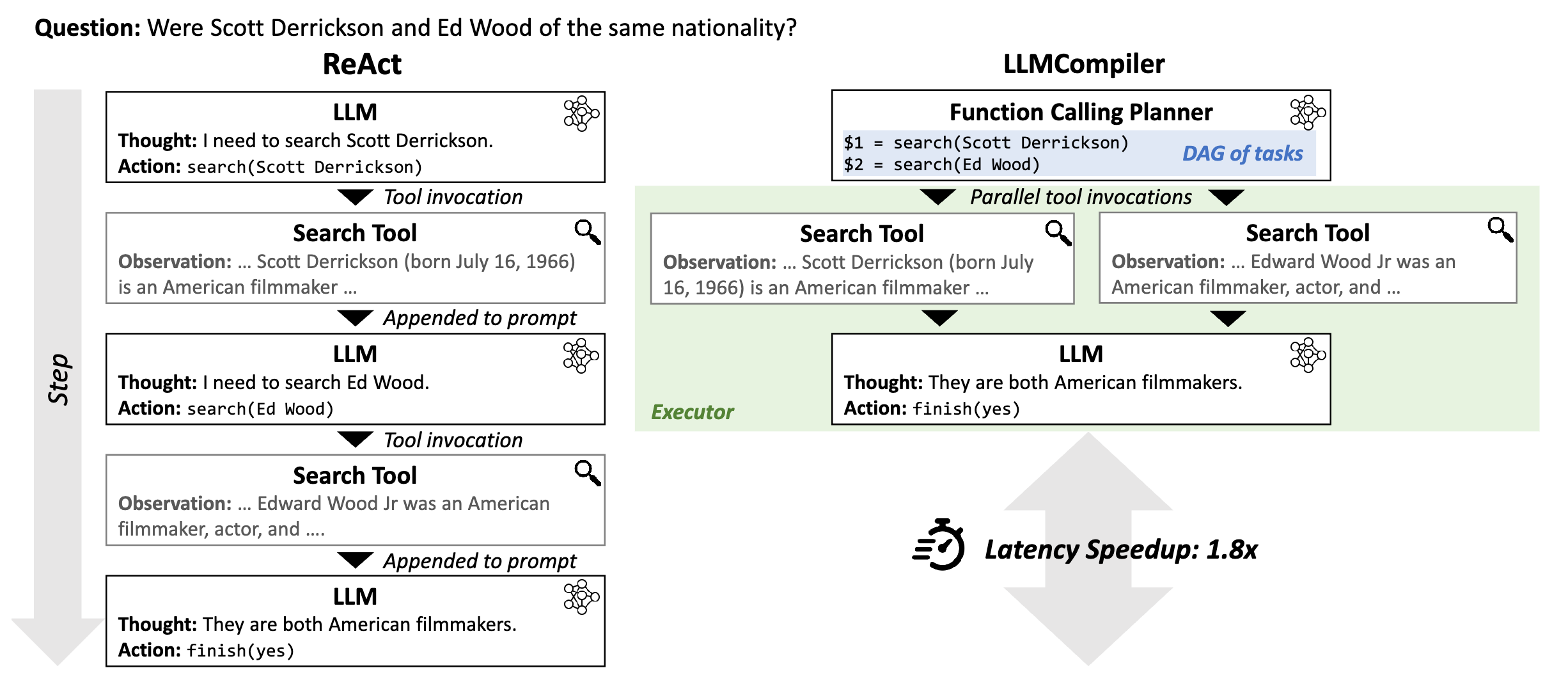
图 1. LLMCompiler 的运行时动态与 ReAct的对比,以 HotpotQA 基准测试中的一个示例问题为例。在 LLMCompiler (右) 中,规划器首先将查询分解为多个具有相互依赖关系的任务。执行器然后并行执行多个任务,尊重它们的依赖关系。最后,LLMCompiler 将来自工具执行的所有观察结果合并起来,以生成最终的响应。相比之下,现有框架如 ReAct (左)的顺序工具执行会导致更长的执行延迟。在这个例子中,LLMCompiler 在 HotpotQA 基准测试上实现了 1.8× 的延迟加速。虽然这里为了简单的视觉说明而展示了一个来自 HotpotQA 的可并行执行的 2 路问题,但 LLMCompiler 能够管理具有更复杂依赖模式的任务。
如图1左所示,当要求LLM判断Scott Derrickson 和 Ed Wood 是否拥有相同的国籍时,ReAct 首先分析查询并决定使用搜索工具来搜索 Scott Derrickson。然后将搜索(即观察)的结果与原始提示串联起来,供 LLM 推理下一个动作,从而调用另一个搜索工具来收集有关 Ed Wood的信息。
但是这种顺序直线函数并推理其观察结果的做法,可能会导致延迟和成本方法的问题,因为每个推理和动作步骤都需要进行顺序函数调用和重复的LLM调用。此外,将中间函数调用的结果连接起来可能会破坏LLM的执行流程,从而降低准确性。常见的失败案例包括重复调用相同的函数。
我们从经典的编译器(compiler)中获取灵感。编译器的关键优化技术是识别可以并行执行的指令,并有效地管理它们的依赖关系。为此,我们引入了LLMCompiler,它能够跨越不同小莫和工作负载并行执行多个LLM工具
2. 相关工作
2.1 大语言模型中的延迟优化
各种研究集中于优化模型设计和系统以实现高效的LLM推理,而应用程序级别的优化研究较少。
Skeleton-of-Thought 提出通过应用级并行解码来降低延迟,设计一个两步过程:首先是生成骨架,然后是并行执行骨架项目。它主要针对易并行的负载,不支持具有依赖关系任务的问题。而LLMCompiler通过将输入查询翻译成一系列具有相互依赖关系的任务来解决这个问题。
最近OpenAI在其1106版本中引入了并行函数调用功能,通过同时生成多个函数调用来增强用户查询处理,但它仅适用于OpenAI专有的模型。而LLMCompiler能够为开源模型实现高效地并行函数调用。
2.2 计划与解决策略
一些研究探索了将复杂查询分解成不同细节层次的提示方法,来提高LLM在推理任务中的性能。这种分解式提示通过将复杂任务分解为更简单的子任务来解决问题,使每个子任务都通过具有专用提示的LLM进行优化。
Decomposed Prompting使LLM能从细节中抽取高级概念,来增强各种任务的推理能力。Plan-and-Solve 提示将多步推理任务细分为子任务,以最大限度地减少错误并提高任务准确性,无需手动提示。
ReWOO使用规划器将推理过程与执行和观察阶段分离,与ReAct相比减少了标记使用量和成本。
2.3 工具增强LLM
LLM增强后的推理能力使其能够调用用户提供的函数并使用其输出有效地完成任务。
3. 方法
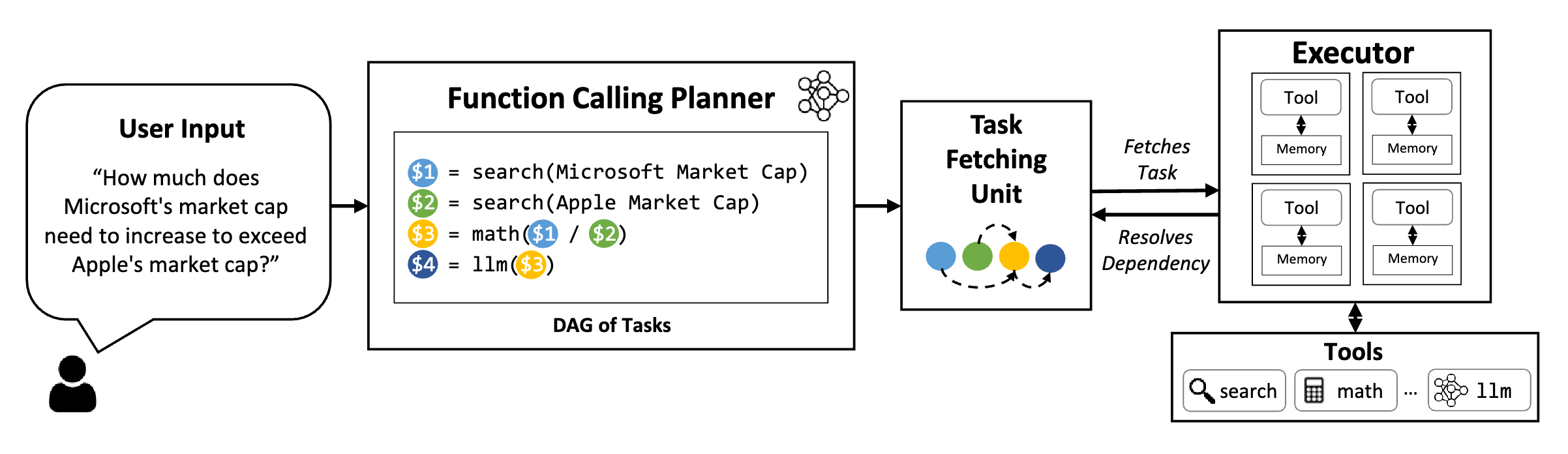
图 2. LLMCompiler 框架概述。函数调用规划器生成一个包含任务及其相互依赖关系的 DAG(有向无环图)。然后,任务获取单元根据任务的依赖关系将这些任务并行调度到执行器。在本例中,任务 $1 和 $2 被同时获取,以并行执行两个独立的搜索任务。每个任务执行完成后,结果将被转发回任务获取单元,以在用实际值替换其占位符变量(例如,任务 $3 中的变量 $1 和 $2)后,解除对依赖任务的阻塞。所有任务执行完成后,最终答案将被传递给用户。
为了回答“微软的市值需要增长多少才能超过苹果的市值?”,LLM首先需要对两家公司的市值进行网络搜索,然后进行除法操作。显然它们可以并行执行,关键问题是如何自动确定哪些任务是可并行的,哪些任务是相互依赖的,以便我们能相应地编排不同任务的执行。
LLMCompiler通过三个组件构成的系统来实现这一点:一个函数调用规划器,生成一系列任务及其依赖关系;一个任务获取单元,根据中间结果替换参数并获取任务;以及一个执行器,使用相关工具执行任务。
3.1 函数调用规划器
函数调用规划器(Function Calling Planner)负责生成要执行的任务序列以及它们之间的任何依赖关系。例如,图2中的任务$1和$2是两个可以并行执行的独立搜索。而任务S3依赖这两个搜索结果。因此,规划器的作用是利用LLM识别必要的任务、输入参数以及它们之间的相互依赖关系,形成一个任务依赖的有向无环图(directed acyclic graph, DAG)。如果一个任务依赖于前面的任务,它会包含一个占位符变量,如图2中任务3里的$1,该变量稍后将被替换为前面任务的实际输出。
核心是利用LLM的推理能力,将输入的任务分解。规划器LLM结合了一个预定义的提示词,指导它如何创建依赖图并确保语法正确。除此之外,用户还需要为规划器提供工具定义和可选的上下文示例。这些示例提供了针对特定问题的任务分解的详细演示,帮助规划器更好地理解规则。
3.2 任务获取单元
任务获取单元根据贪婪策略,在任务准备好(并行)执行时将任务传递给执行器。另一个关键功能是将变量替换为之前任务的实际输出,这些输出最初由规划器设置为占位符。比如图2中的实例,任务$3中的变量$1和$2将被替换为微软和苹果的实际市值。这可以通过简单的获取和排队机制实现,无需专门的LLM。
3.3 执行器
执行器异步执行从任务获取单元获取的任务。任务获取单元保证所有分派到执行器的任务都是独立的,因此它们可以简单地并发执行。执行器配备了用户提供的工具,并将任务委托给相关工具。每个任务都有专门的内存来存储其中间结果。任务完成后,最终结果将作为输入转发给依赖它们的后续任务。
3.4 动态重规划
在各种应用中,执行图可能需要根据先验未知的中间结果进行调整。类似于编程中的分支,对于简单的分支,可以静态编译执行流程,并根据中间结果动态选择正确的流程。然后,对于更复杂的分支,基于中间结果进行重新编译或重新规划可能更好。
重新规划时,中间结果从执行器发送回函数调用规划器,然后函数调用规划器生成一组新的任务及其关联的依赖关系。这些任务随后被发送到任务获取单元,然后发送到执行器。该循环持续进行,直到达到所需的最终结果并可以交付给用户。
4. LLMCompiler细节
4.1 用户提供的信息
LLMCompiler需要用户提供两个输入:
- 工具定义 用户需要指定LLM可以使用的工具;
- 规划器上下文示例 用户可以选择用LLMCompiler提供规划器应如何运行的示例。这些示例可以帮助规划器LLM理解如何使用各种工具并为传入的输入生成正确格式的依赖关系图。
4.2 流式规划器
规划器在处理涉及大量任务的用户查询时可能会产生不小的开销,因为它会阻塞任务获取单元和执行器,而它们必须等待规划器输出才能启动其进程。
类似与计算机系统中的指令流水线,可以通过允许规划器异步地流式传输依赖关系图来缓解这个问题,从而允许每个任务在所有依赖关系都解析后立即由执行器处理。
5. 结果
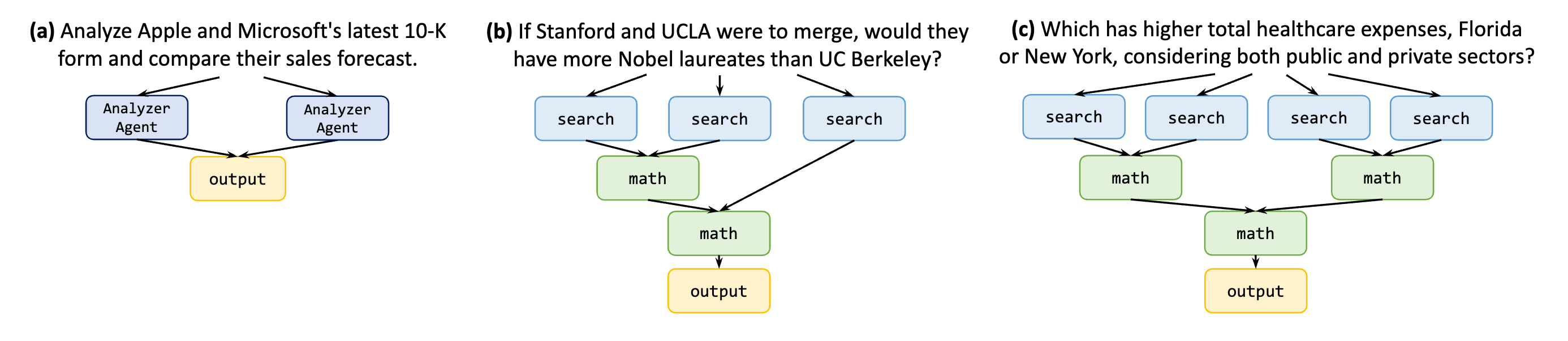
图 3. 不同函数调用模式的示例问题及其依赖图。HotpotQA 和电影推荐数据集表现出模式 (a),而 ParallelQA 数据集表现出模式 (b) 和 ©,以及其他模式。在 (a) 中,我们需要分析每家公司的最新 10-K 报告。在 (b) 中,我们需要对每所学校进行三次搜索,然后进行一次加法运算和一次比较运算。在 © 中,我们需要搜索每个州在每个领域的年度医疗保健支出,将每个州的支出相加,然后进行比较。
在并行函数调用场景。最简单的场景涉及一个 LLM 重复使用工具来完成独立的任务,例如进行平行搜索或分析以收集不同主题的信息,如 图3 (a) 中所示的模式。虽然这些任务彼此独立,可以并行执行,但 ReAct 以及其他 LLM 解决方案,在当前状态下,需要按顺序运行。这会导致由于每次工具使用都需要频繁调用 LLM 而导致延迟和Token消耗增加。

表 1. LLMCompiler 与基线在不同基准测试上的准确性和延迟比较,包括 HotpotQA、电影推荐、名为 ParallelQA 的自定义数据集以及 24 点游戏。对于 HotpotQA 和电影推荐,我们经常观察到循环和提前停止。为了尽可能减少这些行为,我们加入了 ReAct 特定的提示,我们将其表示为 ReAct†。ReAct(不带 †) 表示没有此提示的原始结果。
从表1可以看到,ReAct的准确性始终低于OpenAI并行函数调用和LLMCompiler。ReAct有两种主要失败模式: (1)重复生成先前函数调用的趋势;(2)基于不完整的中间结果过早停止。
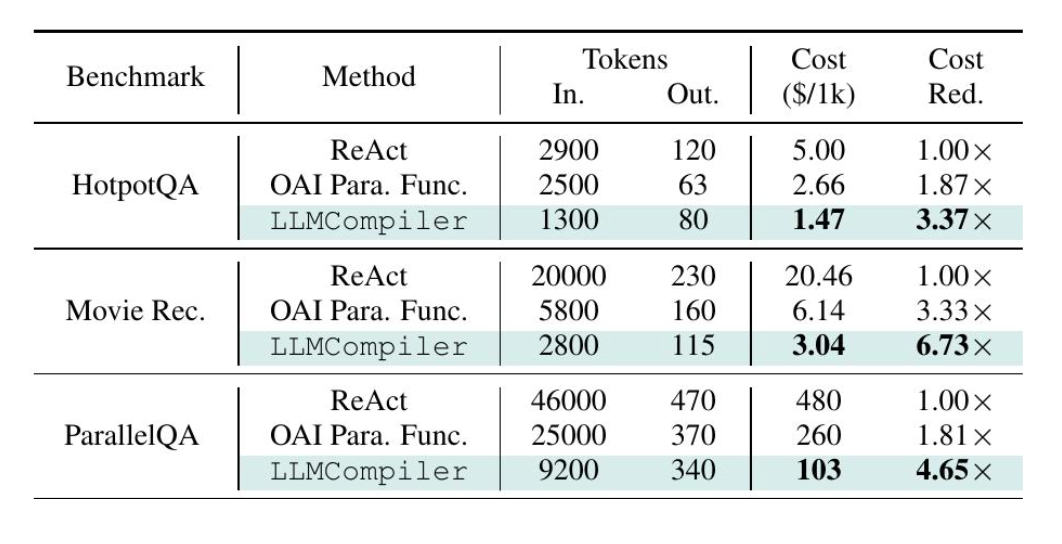
表 2. HotpotQA、电影推荐和名为ParallelQA 的自定义数据集的输入和输出标记消耗以及估计成本。成本是根据用于每个基准的 GPT 模型的定价表计算的。
LLMCompiler在成本方面比ReAct更具成本效益,因为它涉及更少的LLM调用。LLMCompiler 在成本效率方面也优于最近的 OpenAI 并行函数调用。因为 LLMCompiler 的规划阶段比 OpenAI 并行函数调用的规划阶段更有效率,因为我们的规划器的上下文示例比较短,只包含计划,不包含观察结果。
6. 结论
作者引入了LLMCompiler,这是一个受编译器启发的框架,它能够在各种LLM之间高效地并行调用函数。通过将用户输入分解为具有定义的相互依赖关系的任务,并通过其规划器、任务获取单元和执行器组件并发执行这些任务。
G. 用户提供的LLMCompiler配置示例
LLMCompiler提供了一个简单的接口,允许通过提供工具定义以及可选的上下文示例来为规划器定制框架,以应用不同的用例。
下面提供用于在电影推荐和24点游戏中设置框架的规划器示例提示。
Question: Find a movie similar to Mission Impossible, The Silence of the
Lambs, American Beauty, Star Wars Episode IV - A New Hope
Options:
Austin Powers International Man of Mystery
Alesha Popvich and Tugarin the Dragon
In Cold Blood
Rosetta
1. search("Mission Impossible")
2. search("The Silence of the Lambs")
3. search("American Beauty")
4. search("Star Wars Episode IV - A New Hope")
5. search("Austin Powers International Man of Mystery")
6. search("Alesha Popvich and Tugarin the Dragon")
7. search("In Cold Blood")
8. search("Rosetta")
Thought: I can answer the question now.
9. finish()
###
问题:找到一部类似于《碟中谍》,《沉默的羔羊》,《美国美人》,《星球大战第四集:新希望》的电影
选项:
《奥斯汀·鲍尔斯:国际间谍》
《阿列沙·波普维奇与龙图加林》
《冷血》
《罗塞塔》
1. search("碟中谍")
2. search("沉默的羔羊")
3. search("美国美人")
4. search("星球大战第四集:新希望")
5. search("奥斯汀·鲍尔斯:国际间谍")
6. search("阿列沙·波普维奇与龙图加林")
7. search("冷血")
8. search("罗塞塔")
Thought:我现在可以回答这个问题。
9. finish()和
Question: "1 2 3 4", state list: [""]
$1 = thought proposer("1 2 3 4", "")
$2 = state evaluator("1 2 3 4", "$1")
$3 = top k select("1 2 3 4", ["$1"], ["$2"])
$4 = finish()
###
Question: "1 2 3 4", state list: ["1+2=3(left:3 3 4)","2-1=1(left:1 3
4)","3-1=2(left:2 2 4)","4-1=3(left:2 3 3)","2*1=2(left:2 3 4)"]
$1 = thought proposer("1 2 3 4", "1+2=3(left:3 3 4)")
$2 = thought proposer("1 2 3 4", "2-1=1(left:1 3 4)")
$3 = thought proposer("1 2 3 4", "3-1=2(left:2 2 4)")
$4 = thought proposer("1 2 3 4", "4-1=3(left:2 3 3)")
$5 = thought proposer("1 2 3 4", "2*1=2(left:2 3 4)")
$6 = state evaluator("1 2 3 4", "$1")
$7 = state evaluator("1 2 3 4", "$2")
$8 = state evaluator("1 2 3 4", "$3")
$9 = state evaluator("1 2 3 4", "$4")
$10 = state evaluator("1 2 3 4", "$5")
$11 = top k select("1 2 3 4", ["$1", "$2", "$3", "$4", "$5"], ["$6", "$7",
"$8", "$9", "$10"])
$12 = finish()
###
H. 预定义的LLMCompiler规划器提示
预定义的LLMCompiler规划器提示为其提供了关于如何分解任务和生成依赖图的具体说明,同时确保相关语法格式正确。此提示包含特定规则,例如将每个任务分配到新行,每个任务以数字标识符开头,并使用$符号来表示中间变量。
- Each action described above contains input/output types and descriptions.
- You must strictly adhere to the input and output types for each action.
- The action descriptions contain the guidelines. You MUST strictly follow
those guidelines when you use the actions.
- Each action in the plan should strictly be one of the above types. Follow
the Python conventions for each action.
- Each action MUST have a unique ID, which is strictly increasing.
- Inputs for actions can either be constants or outputs from preceding
actions. In the latter case, use the format $id to denote the ID of the
previous action whose output will be the input.
- Ensure the plan maximizes parallelizability.
- Only use the provided action types. If a query cannot be addressed using
these, invoke the finish action for the next steps.
- Never explain the plan with comments (e.g. #).
- Never introduce new actions other than the ones provided.
- 上面描述的每个动作都包含输入/输出类型和描述。
- 你必须严格遵守每个动作的输入和输出类型。
- 动作描述包含指导方针。你在使用动作时必须严格遵守这些指导方针。在你使用这些操作时,请遵循这些指南。
- 每个动作必须具有唯一的 ID,该 ID 严格递增。
- 动作的输入可以是常量或来自先前动作的输出。在后一种情况下,使用格式 $id 来表示先前动作的 ID,其输出将作为输入。
- 确保计划最大程度地并行化。
- 仅使用提供的动作类型。如果查询无法使用这些动作类型解决,则调用 finish 动作以进行下一步。
- 永远不要用注释(例如 #)来解释计划。
- 除提供的动作外,不要引入新的动作。
除了用户提供的函数外,规划器还包含一个特殊的硬编码完成函数(finish())。规划器在计划足以解决用户查询或无法在执行当前计划之前继续规划时(即,当它认为需要重新规划时)使用此函数。当规划器输出完成函数时,其计划生成停止。完成函数的定义如下,并作为提示与其他用户提供的函数定义一起提供给规划器。
finish():
- Collects and combines results from prior actions.
- A LLM agent is called upon invoking join to either finalize the user
query or wait until the plans are executed.
- join should always be the last action in the plan, and will be called in
two scenarios:
(a) if the answer can be determined by gathering the outputs from tasks to
generate the final response.
(b) if the answer cannot be determined in the planning phase before you
execute the plans.
finish():
- 收集并整合先前行动的结果。
- 调用 join 时,LLM agent要么完成用户查询,要么等待计划执行。
- join 应该始终是计划中的最后一个操作,并且将在两种情况下被调用:
(a) 如果答案可以通过收集任务的输出以生成最终响应来确定。
(b) 如果在执行计划之前,无法在计划阶段确定答案。
总结
⭐ 这是一篇很厉害的工作,作者受计算机中编译器的启发,设计了LLMCompiler这一框架。首先利用函数调用规划器指定函数调用的执行计划;然后通过任务获取单元来调度函数调用任务,找出其中的依赖和独立任务;最后通过执行器(并行)执行这些任务。