论文/报告地址:NTIRE 2024 Restore Any Image Model (RAIM) in the Wild Challenge
0、写在前面
马上CVPR2024就要开幕,各大挑战赛的排名和详细报告也都出炉。近期留意到这个名字很屌的赛道,修复一切图像的模型,小米的团队的拿了第1, 第2小红书,排在后面的都是高校队伍。
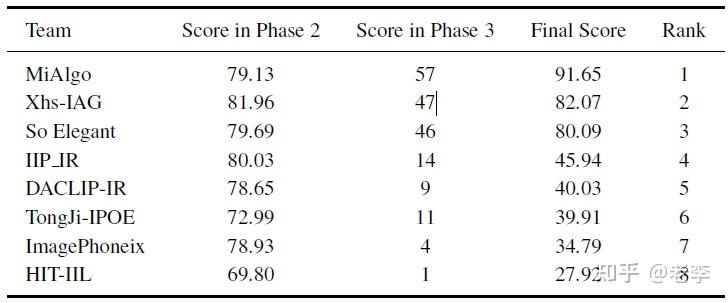
比赛挑战排名
整个赛道的设置和参赛团队的报告信息量比较大,笔者也是抽时间阅读后选取一些有意思的trick或者tech进行记录,以期后续算法研究中能够予己助益。更期待读者中各位巨巨能够分享和反馈有效的信息。
1、赛事设置详情
挑战详情页:CodaLab - Competition
数据集链接:https://drive.google.com/file/d/1DqbxUoiUqkAIkExu3jZAqoElr_nu1IXb/view
1.1、数据集安排
一共3套数据集,分别对应比赛进程的3个阶段:
- 模型设计与调试:提供100对paired的HQ(High-quality)-LQ(Low-quality)图像对和100个unpaired的LQ图像,model的效果由参赛队伍自行评判;
- 线上反馈:参赛阶段只给出了额外100对HQ-LQ数据对中的LQ样本,参赛队伍提交其修复的结果后有服务器与HQ进行比对,输出量化结果;官方接受队伍提交阶段1中unpaired的案例,这部分由人工打分给出结果;
- 最终角逐:10个在阶段2量化打分结果最高的队伍,可以参与,官方给出额外50张unpaired的LQ图像由参赛队伍修复后提交,由专家评价图像质量。
下载下来查看后总结数据集有以下三个特征:
- 数据来源:数据采集主要来自单反、部分疑似来自手机(有较重图像处理后的涂抹感),从全分辨率上抠出来1024x1024的分辨率patch。
- 劣化特征:主要是虚焦模糊、少量运动模糊,没有看到降噪需求。数据对能看到镜头的对焦切换:HR是绝大部分像素正确对焦的高清图像、LR则是镜头焦点往后退一截后的虚焦图像。同时,也留意到长焦特写的镜头素质有不同,虚焦后图像出现不同的散斑特征,这种劣化是主流图像修复赛道中鲜被提及。也有一两对图像,表现出手工degradation处理的特点。
- 像素对齐:HR和LR两图之间的采集时间跨度不小,室外场景能看到明显的亮度光影变化;有少量paired的图像出现了像素的偏移。
- 图像元素:较多规律性纹理和皮毛、草地等非规律纹理,较少高频小纹理,有一些文字字符,没有人形、人脸。
- 亮度分布:在paired数据中比较少见连片的高光过曝,但在unpaired数据中却又较多夜间拍摄的灯牌。
【笔者看法】
数据集的这些特征,明确对应了challenge标题中的“all image”和“in the wild”两个要求:数据对之间像素都对不齐,而且劣化特征差别很大。因此对于算法研究者,如果alignment的数据集并不容易touch、且参数量又有限制,则算法将很难取得比较理想的效果。
另外,这些图像未见亮度、对比度和色彩的调整,这意味着比赛主办方将这类处理归类到restoration之外,属于enhancement的范畴。笔者查看主办方信息,是OPPO研究院和港理工,张磊老师位列其中,也基本可以坐实这个猜想。
1.2、图像质量的衡量
paired数据的衡量方案: 20×����50+15×����−0.50.5+20×1−�����0.4+40×1−�����0.3+30×1−����10
官方脚本:https://drive.google.com/file/d/1Q1CvlbGo-WOgqya5GulS5eYIi2Rgcj5l/view
unpaired数据对衡量,邀请18个老司机参与主观打分,评价维度参考如下几点:
- 纹理和细节:修复图像需要有良好和自然的纹理和细节。
- 噪声:不能保留噪声、尤其是对色彩噪声,但是一些亮度噪声可以保留以避免平坦区域过分平滑、看起来涂抹。
- 伪纹:蠕虫、色块、粘连、黑白边等伪纹需要尽量抑制。
- 保真度:修复结果需要忠实于输入(作者指出,保真度评价的细则针对具体案例在赛程中与参赛者都同步到)
最终裁量的结果,以40%的客观分数阶段2得分+60%的主观分数阶段3得分决出。
【笔者看法】
IQA(Image Quality Assessment)图像质量评价也是笔者团队的研究领域,长期以来都是一个尚处open的命题。尽管如此,open的是计算方法而不是概念,在AI-ISP处理盛行其道的今天,对图像高频细节效果的评价维度也基本与赛事官方给出的这4个方面相近。
对于亮度、对比度和色彩,这些维度一来不在本次restoration的赛道范畴,二来作为enhancement的处理环节、更受个人主观的影响,在缺乏GT的情况下相对容易陷入争议。
2、参赛队伍技术报告
2.1、MiAlgo(小米):万级自筹UHD数据集,“三年陈”技术照打天下
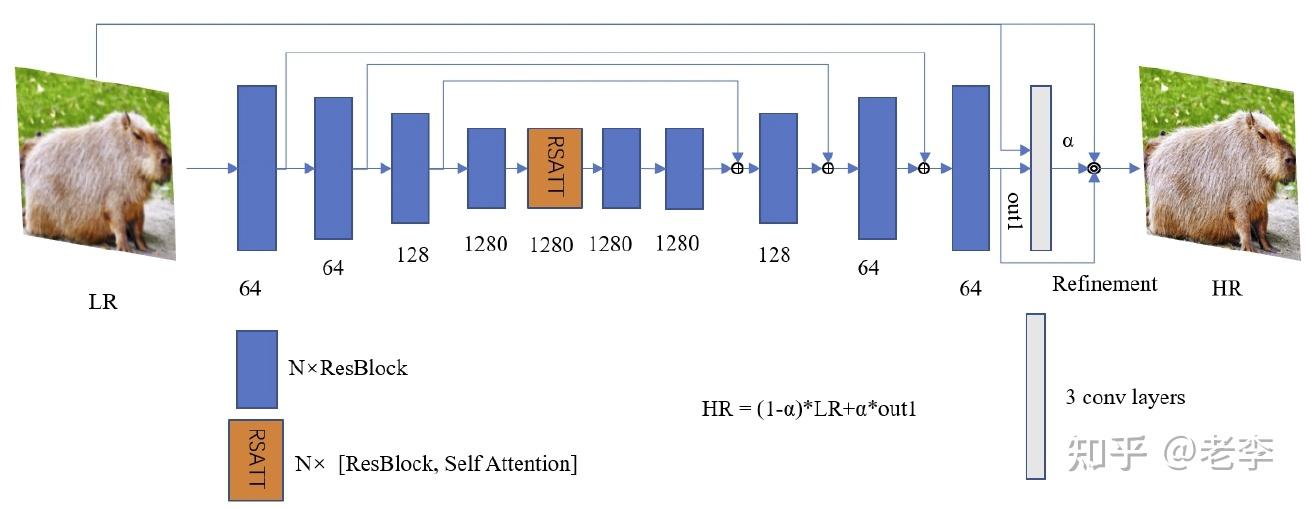
MiAlgo模型:上下采样处使用Harr小波,主要conv、高层有一个自注意力,最后加一个refinement
2.1.1、模型结构
【backbone:MW-Unet】
模型的架构源自MWRCAN,团队引用文献是AIM2020学习型ISP处理赛道,那年的赛会报告总结中说RCAN大行其道,而MW则来自于那年的冠军得主团队的网络MW-ISPNet,作者是哈工大左旺孟老师团队的张志路博士。
AIM2020:AIM 2020 Challenge on Learned Image Signal Processing Pipeline
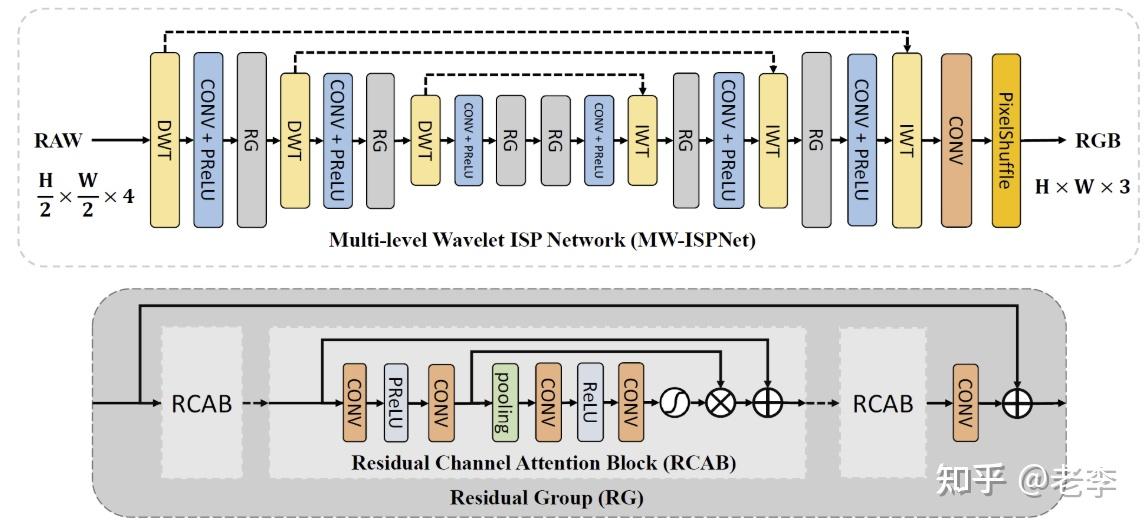
MW-ISPNet:主要采用小波变换和通道注意力机制提升图像处理能力
【self-attention:RSATT】
在主体ResConv Block的结构中的最深层,还插入了一个RSATT。团队提到想借助transformer强大的自注意力机制来定位整图感受野中的自相似特征,但是算例开销是非常大的,因此选择了在分辨率最小的深层level。团队训练的输入分辨率512x512,到这一层已经3次下采样至64x64,且只用了一个block,也算是tradeoff里向性能的方向偏移到极限了。具体的RESATT是什么结构,笔者倒是不太熟、简单检索后尽在ICCV2021找到2篇做high-level任务的文献,欢迎指教。
关于为什么自注意力对底层视觉任务有帮助,笔者5月初正好在重庆参加了VALSE2024,其中一个workshop上南理工的潘金山老师的报告很深入潜入,推荐大家观看:【VALSE2024】0506《Workshop :面向移动端的AI图像增强》_哔哩哔哩_bilibili。

潘金山:自注意力可以实现nonlocal的信号修复
【最后提拉:refinement】
网络的末尾采用了论文EMVD(Efficient Multi-Stage Video Denoising with Recurrent Spatio-Temporal Fusion)的refinement:接受input和前序处理的out再用conv卷几轮,这步操作可进一步提升细节的表现。
【笔者看法】
当时EMVD这篇论文出来时,笔者团队还和伦敦研究所有过交流。结合本次的任务,笔者认为在MiAlgo的模型中,这个refinement不能提供它被设计时所赋予的能力:这里模型中,inputLQ的形式主要为虚焦,因此并不存在原作中“降噪损失了纹理细节而需要refine的诉求”,无法提供out中所“损失”的细节;同时,input仅有单张,彼时EMVD的场景是video,多帧合并后的中间feature可以提供优于input的信号质量。
看到这里,EMVD的二作黄亦斌博士此前还有一个AIM的inverseISP的比赛中拿到了头名,似乎也是和伦敦研究所的这个Matteo合作的,之前有过两次技术交流,但刚才公司内查询发现已经离职了。拖到报告后面才看到原来小米这次参赛的一作就是黄博,那就难怪了。
【模型性能】
参数量341MB,显存占用7GB,一张4090GPU推理512x512x3图像耗时180ms。这个在我这个8年老本1060上跑不了。
2.1.2、数据退化和GAN训练
赛会提供的数据集并不足以支撑训练,团队训练了两个GAN来退化:
第一个模型,把论文(Learning Degradation Uncertainty for Unsupervised Real-world Image Super-resolution)的生成器倍增channel后,针对赛会提供的paired数据训练,输入HQ,LG做gt,训出来一个微弱blur的退化模型。
第二个模型,在第一个基础上增加赛会阶段2的高blur LQ数据作为GT,再选择同场景的100张HQ作为输入以unpaired的形式进行训练,训练方式同样参考第一个模型引用的论文。
【笔者看法:这个训练方式,笔者暂时没有深究,此前的算法中少有涉及unpaired训练;但感觉应该很有意思,后续研究后再更上来】
第二个模型相比第一个模型会引入更强的blur。在使用第二个模型的时候,团队在这里将HQ图像的人形、文字单独分割出来,用第一个模型退化出微弱blur的结果替换到LQ图像中。此举的目的是为了保证训练出来的restoration模型在推理的时候能够有更好的保真度/fidelity。
【笔者看法】
这里团队的操作无可非议,但能work有2个背景:1、其restoration模型参数量够大;2、赛道场景中并没有人形甚至人脸,fidelity的约束并不强。但从起数据退化的精心程度,也足见当LQ劣化到一定程度已经丢失对象的fidelity可能,例如人脸已经丢失ID特征后,会产生更强的uncertainty,restoration甚至enhancement大概率是无能为力的,因此团队才会力求避免把人形和文字部分劣化过度,造成对restoration模型的污染、产生偏向generate的能力。
团队采用上述两个退化模型,对团队既有的万级UHD数据库进行退化得到的20000训练数据对。
训练阶段分为5个,辨别器来自RealESRGAN:
- lr 1e-5, bs: 24,ps: 512, L2 loss -> ~10000 iter
- L2+1xPerceptual+0.1xGAN loss -> 140000 iter
- 在官方阶段2的100对数据上FT: lr 1e-6, L2+0.1xPerceptual+0.01xGAN loss+4xLPIPS -> 20000 iter
- 阶段3,在3的模型上,使用80%强退化+20%弱退化数据,继续FT:lr 1e-5, L2+0.1xPerceptual+0.01xGAN loss+4xLPIPS -> 100000 iter
- 从数据集中挑选NIQE指标最高的10个patch组成subset继续ST:lr 1e-6 -> ~50000 iter。
【笔者看法:从这繁复的训练策略可见下了狠功夫了,最后第5步是restoration任务、尤其是细节处理模型很有必要的一步,应当作为范式遵循。】
2.1.3、小结
- 没有什么高大上的或者讳莫如深的tech,主要都是3年前的工作成果,也多数和小米不搭边。
- 模型训练的关键还是在于数据,数据如何做好domain gap的跨越和易获取性,是衡量数据质量的重要指标。更何况小米自己的团队有万级的UHD数据库。
- 训练过程的雕琢不可或缺,从上面的5个阶段就可以比照,其他团队或者我们自己的算法研究中是否穷尽一切策略?
2.2、Xhs-IAG(小红书):站在SUPIR巨人肩上但没能看得更远
小红书团队在两个参赛阶段采用了全然不同的策略:
阶段2虽然没有写明,但从上下文推测应该使用了SrFormer作为backbone,先用LSDIR的数据集进行训练,然后只用赛事官方提供个paired数据精调,结果在分数上达到了rank1的水平,只用了1个小section就完成了介绍。
阶段3就复杂了,团队的报告花了很大的篇幅介绍他们的方案,在IR的任务上直接套用CVPR2024的SUPIR(这个工作笔者之前阅读了一点点,后续看完会补充报告链接在这里),为了平衡细节效果和fidelity,又用DeSRA来辅助分类,把SUPIR放飞自我的图像区域替替换到弱生成的内容,最后用一个SRformer的backbone训练一个fusion模块融合两者结果。但很可惜阶段3的提交分数稍微拉了胯,最终评分掉到了rank2。
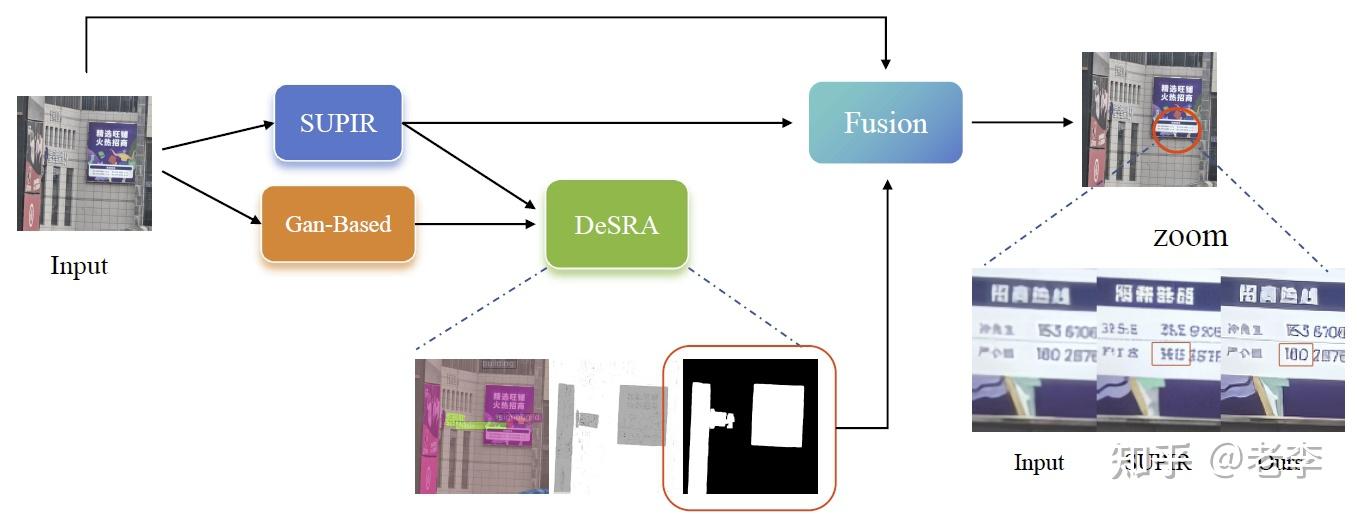
Xhs-IAG模型:利用SUPIR的强生成和DeSRA的伪纹分类,最终修复出细节保真的结果
2.2.1、模型结构
【扩散模型:SUPIR】
在还没有阅读到Xhs-IAG的报告前,笔者还在疑惑扩散模型现在已经导出屠榜的为啥rank1的团队居然没使用。结果一翻到这里就看到了熟悉的字眼SUPIR(Scaling Up to Excellence: Practicing Model Scaling for Photo-Realistic Image Restoration In the Wild)。
Xhs-IAG介绍到SUPIR使用了2千万级数据训练、输出结果自然度较好,但团队也坦言赛期紧张且SUPIR并未开源训练工程,因此就“拿来主义”了,最多在推理的时候调整了部分参数和prompt。
【笔者看法】
RAIM的挑战并未约束开销, 就SUPIR基于StableDiffusion-XL的体量,断然就不是一个对部署条件很友好的方案。同时,目前 扩散模型在对文字的处理上还欠缺稳定,对于real-world场景中广泛存在的文本图像场景,甚至要对已经经过拍摄设备SR处理过的劣化文字进行处理,可能会起到反作用(可以从本文上方图的zoom效果和下方效果看到效果,字符笔画碎裂)。
这一反差从Xhs-IAG团队阶段2只用SrFormer的分数相对优于阶段3的分数也看得出草蛇灰线。

SUPIR论文展示素材中唯一的文字样本,LQ中的车牌已看不清是啥文字,但出来的结果并不是一个很规整的字符序列
【fidelity保姆:DeSRA】
针对扩散模型在细节纹理和结构表现上视觉效果好但不一定保真的情况,团队借鉴了DeSRA(DeSRA: Detect and Delete the Artifacts of GAN-based Real-World Super-Resolution Models)的模型。

DeSRA:辨别SR中出手过重的区域并给出mask,引导模型采用更加保真的策略
这篇工作来自腾讯优图,发表在ICML2023。这篇工作针对GAN生成纹理容易出现过度生成的artifacts训练了一个像素辨别器,进一步地,该模型还具备一定的语义分割能力,可借助semantic的信息对纹理进行更加精细的判别。
团队借助DeSRA的方法论对SUPIR的结果进行判定,把判定为fidelity有问题的像素区域替换为LQ的内容。这一步操作,团队报告中的流程图有一定误导性,并不是用在了GAN-based的输出,而是回贴了LQ内容后的结果,混合mask、LQ整图输入到fusion部分,完成了的GAN-based的操作。但实际上,团队并没有完全照搬DeSRA的backbone,而是使用了Mask2Former替换了源文档SegFormer,这里替换的动机并未解释,笔者对这两份工作不太熟悉,欢迎了解的大佬补充。
【笔者看法】
DeSRA的思路挺好,但其模型不过精调直接使用,笔者估计并不能在SUPIR的结果中实现很好的判定。从DeSRA论文给出的素材中,模型旨在判定GAN产生的伪纹理,对于diffusion能够产生语义不同但纹理自然的结果、则应该是无能为力的。
笔者团队在IQA技术体系中也针对fidelity的评价展开过研究,仅用无参考的技术手段是非常难以从纹理自然的图像中判定其fidelity的。与其说这种任务有难度,倒不如说此前的判定和评价所针对的都是人工刻意制作的synthesis的样本,这类样本在信号层面上容易出现高频泄露。
【打完补丁:fusion】
团队使用SRFormer作为backbone来做最终的fusion和图像修复,原作为单图SR任务,团队这里输入有三项内容:LQ输入、DeSRA判定的mask、套上mask之后回贴了LQ和SUPIR之后的结果。
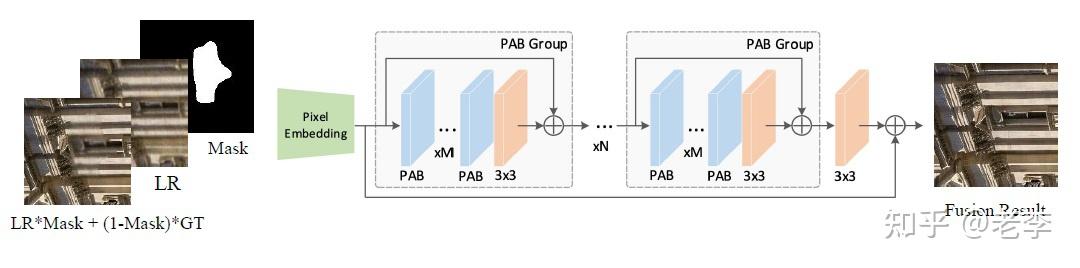
Fusion部分:3个输入最终输出修复的结果
这一步模型的训练,团队采用了inpainting任务的思路,随机生成mask区域并把GT的区域贴回,并采用了任务针对性的loss:valid_loss、hole_loss、perceptual_loss和gan_loss;在推理的时候GT的角色由SUPIR的输出替代,这样训练的fusion模块实则与阶段2的模型相近,区别在于GAN的大刀只挥向LQ的区域,SUPIR的结果予以保留。
2.2.2、数据、训练和模型开销
团队报告并未在此内容上着墨太多,笔者推测应是没有太多好说的,毕竟首先开销绝对不小(相比于目前已经分析过的MiAlgo的方案),且模型中的SUPIR并没有训练过。
倒是阶段2的训练,团队介绍了其训练过程:
- 第一步采用LSDIR(LSDIR: A Large Scale Dataset for Image Restoration)的数据集训练,patch size 128x128,iter=92k,lr=1e-4。
- 第二步只使用赛事官方提供的paired数据集进行训练,iter=140k,lr=5d-5,loss设置补充了对抗loss和感知loss,权重配置 1.0×�1_����+1.0×����������_����+0.05×���_����
【笔者看法】
LSDIR的数据domain和本次赛事给出的图像之间的gap还挺大的,因此第二步的ft应该可以做得更细一些;另外毕竟backbone基于transformer,所以patch size如果放大一些应该收益更佳、但算力的开销应该也会指数增长,相比MiAlgo的patch size 512,还是小了。也许团队当时看到阶段2的分数已经rank1了,所以也就作罢。
2.2.3、小结
- 小红书在阶段3倒是想了不少法子,也用上了最新成果SUPIR,最后形成了一个大型组装怪。然而图像质量,尤其在带文字部分的处理上,相比朴素的拉对比效果还是有逊色的。也许未来diffusion在字符超分问题上有了比较好的表现,那么其团队的思路可以有更好的突破,但目前来看、最牛的方法并不一定是最适合的,SUPIR的引入并没有达成其最理想的效果。
- 之所以称其为大型组装怪,在于其方案基本无视落地的轻量的实际落地诉求,sota的diffusion方案再加2个堆叠是transformer网络,推理一个图要个十几到几十秒那也没有太大意义。
- 报告放入了较多的代码块,有凑字数篇幅之嫌,实则两行公式就能说得清楚。
2.3、So Elegant(石油大学):DiffIR开路,首步输出约束后续扩散过程的保真度
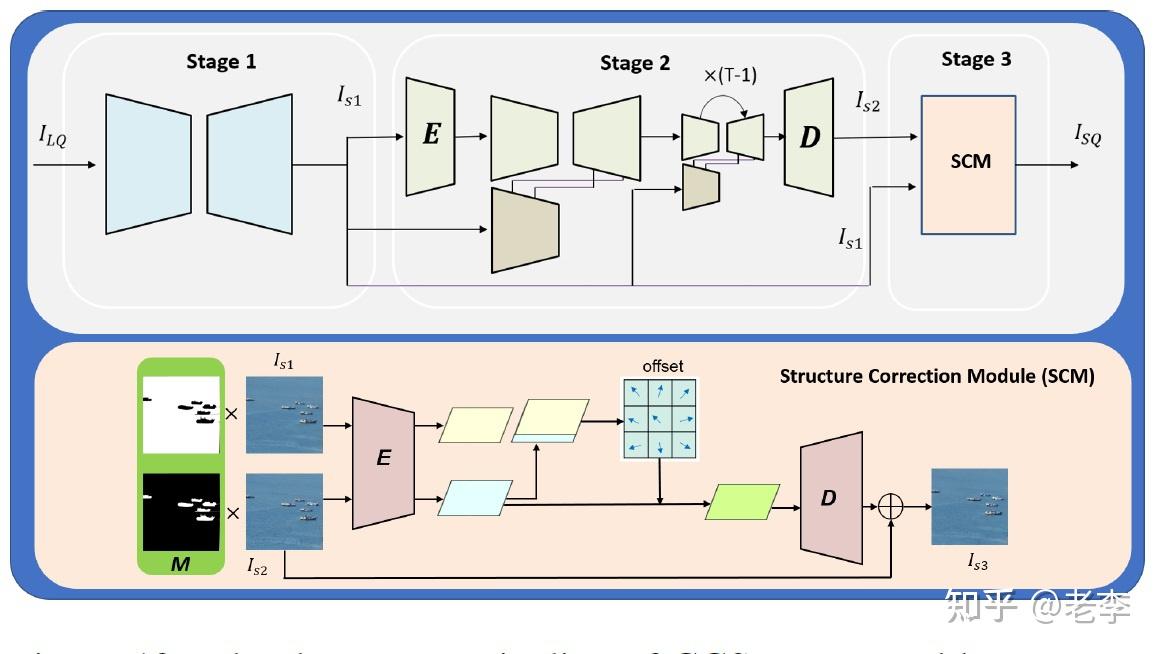
So Elegant模型:三段式,DiffIR开路,输出持续约束后续扩散,并在末段用DeSRA各取所长
2.3.1、模型结构与训练
【Stage 1:DiffIR】
团队使用DiffIR去除LQ中多样化的劣化,以此获取到基础修复的图像输出 ��1 ,而后这个输出作为guidance分多路持续作用于后续处理。
训练:先按照DiffIR的训练方式,后调整到ps=512x512,lr=5e-5,bs=2,iter=10k。
【Stage 2:Stable Diffusion】
在纹理和细节的增强上,SD无疑是很优秀的。但是fidelity问题需要改善,团队采用Stage 1输出的 ��1 作为保真引导、约束diffusion的结果不要放飞自我。
训练:lr=1e-4,bs=64,steps=50k。
【Stage 3:结构矫正】
这一步先利用DeSRA对图像的判别出一个mask,然后应用到前序两个stage的输出上,送入模型“矫正”。模型内部使用了可变卷积来把 ��2 的纹理往 ��1 warp。
训练:ps=1024x1024,bs=2,lr=1e-4,iter=20k。
2.3.2、模型结构与训练
团队的数据主要采用BSRGAN(Designing a Practical Degradation Model for Deep Blind Image Super-Resolution)的方式自筹训练集,同时考虑到赛事提供的数据domain,又在BSRGAN已有的退化基础上补充了离焦模糊。
同时,论文为了弥合与赛事任务数据的domain gap,还采用了论文Crafting Training Degradation Distribution for the Accuracy-Generalization Trade-off in Real-World Super-Resolution的方法,这篇论文提出的问题正是real-world图像超分、修复和增强的关键问题。
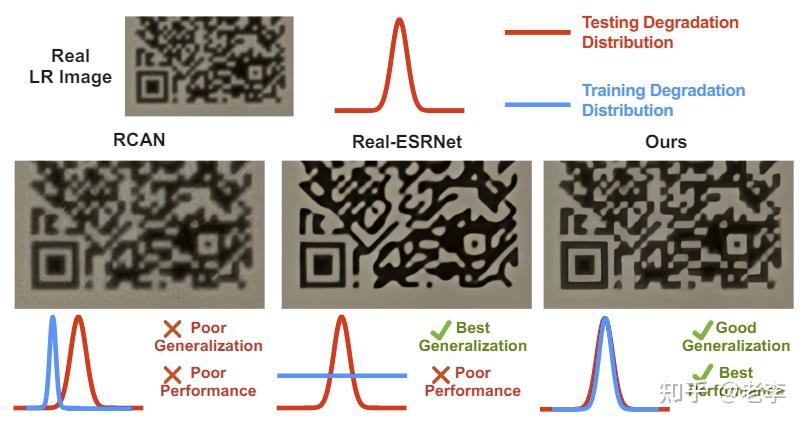
real-world的图像修复问题的关键挑战,就是兼顾好的泛化性与好的效果。
【笔者看法】上图是real-world问题的核心追求,但同时也是巨大挑战,如何模拟真实劣化进来也有不少工作崭露头角。过去常见的方法是采用自监督学习,而这篇论文笔者此前未touch到,会择机翻阅研究。
2.3.3、小结
- 高校团队自筹数据集,还是正视了domain gap这一核心关键,在degradation中补充加入了离焦模糊,进一步采用了其他方法来弥合训练数据与赛事数据的domain gap,这很关键。
- 首阶段DiffIR的结果持续为后续扩散过程和修复过程提供引导,可见哪怕扩散模型给够了引导还是不够,不然也不会有stage 3,但囿于没有说明训练过程,也不太好判断是因为信息引导力度欠佳还是真的做不好。
- DiffIR主要采用conv运算,笔者还未仔细研究过,可以抓紧学习下。
2.4、IIP IR(武汉大学):以deblur任务执行基础修复,x2上采样后SD再降采样输出
2.4.1、模型结构
【Stage 1:模糊核估计与SPADE注入】
团队采用了潘金山老师团队的工作FFTformer(Efficient frequency domain-based transformers for high-quality image deblurring),这里团队应该是分析过数据特征找到主要的劣化来自于blur,并且这种blur并不是单纯的虚焦模糊,而是有很多光学成像素质引入的模糊,因此特别需要不设限的模糊核估计。
团队放开了以往去模糊/超分工作中核权重为正且和为1的先验限制,以使得模型能够学习到更丰富的劣化表征。而为了尽可能保留在修复过程中劣化表征的信息,团队利用SPADE结构把表征注入到每一层Unet的bridge上。
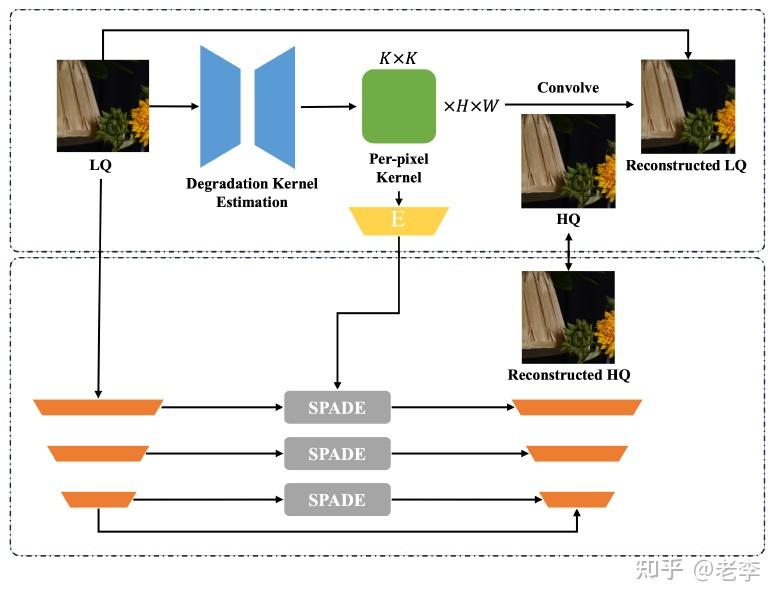
IIP IR阶段1模型:FFTformer执行deblur任务,估计不设限模糊核导入SPADE输出重建LQ
【Stage 2:x2Up过SD然后Down回来】
stage1的处理相对只是把图像的模糊劣化给解决了,但图像缺失而有显著改善人眼主观感受的细节纹理仍有缺失。因此团队把图像经过HAT(Activating More Pixels in Image Super-Resolution Transformer)进行2倍超分,再送入StableSR@SD-Turbo。这样做是为了让模型利用预训练的扩散模型时,能够更好的解决原本很细小的字符纹理。最后再用LANCZOS插值把图像下采样后输出。
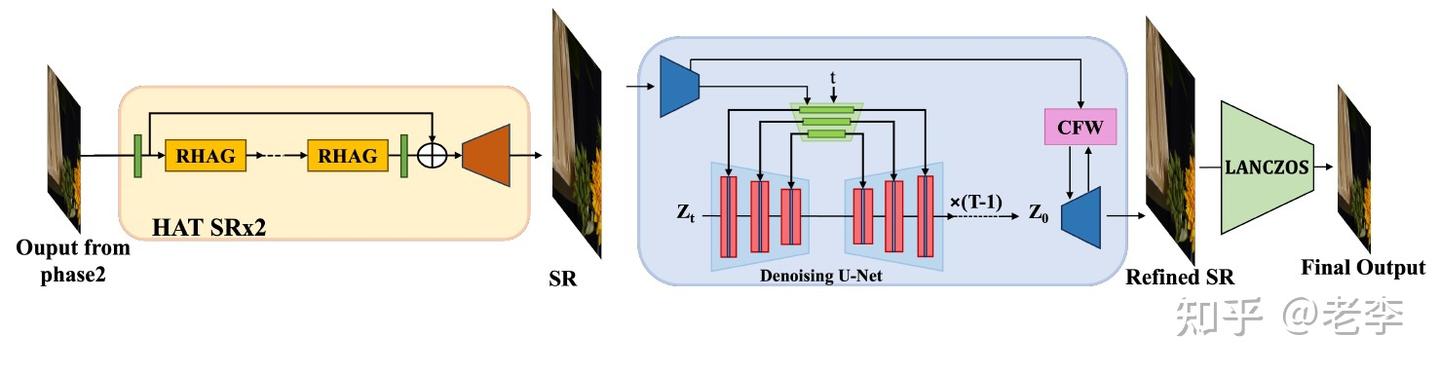
IIP IR阶段2模型:stableSR超分后送入预训练的StableSR,输出再下采样回来。
【笔者看法】
武大团队思路是比较清晰的,针对赛事数据的特点明确采用了放开限制的模糊核估计,这种模型设计更好的应对赛会数据的模糊劣化特点。并且也在起用扩散模型的时候知道其在字符纹理处理上的短板,因此先上采样扩展字符笔画间距、将其送入扩散模型相对擅长的信号频率范围。
尽管他们团队在阶段2的得分上rank2,但 从最终的人眼主观感受来看,输出图像在高频纹理上的表现不够理想,而且大边缘比较重,整体画面偏涂抹,这些特征都是人言相对容易不接受的点。
2.4.2、训练数据
团队采用论文Non-uniform Blur Kernel Estimation via Adaptive Basis Decomposition的方法进行数据退化,也重点是针对deblur问题设计的数据工程。
2.4.3、小结
- 虽然重新定位了问题,但怀疑数据劣化提供的结果并不是很match目标域,因此输出结果偏涂抹,更容易影响人眼主观感受。
- 通过SPADE将劣化先验注入到Unet的每一层,这种操作可能在端侧实现会有些限制,但SPADE的技巧确有功效。
- 对于去模糊问题研究得比较透彻,对于其中引用的一些工作,笔者也未曾涉猎、已经加入心愿单。
2.5、DACLIP-IR(乌普萨拉大学):自带军火参赛,backbone全为作者名下网络
作者罗梓巍(个人主页:https://algolzw.github.io/)目前在乌普萨拉大学攻读博士学位,本次参赛的算法方案建立在其此前发表工作之上:
IR-SDE:Image Restoration with Mean-Reverting Stochastic Differential Equations
DA-CLIP(Degradation-aware CLIP):Controlling Vision-Language Models for Multi-Task Image Restoration
作者的IR-SDE,采用stochastic differential equation(SDE)描述图像的劣化和修复过程,旨在让模型能力不限制在某种具体的劣化空间下修复问题。但在本次挑战中,作者提到仿照DA-CLIP,把LQ的embedding是注入了IR-SDE的过程以提升修复的结果。
对于赛事并未提供训练数据集的现实,作者先基于Real-ESRGAN的数据劣化策略,修改了一个随机劣化顺序的流程。然后借助自己以前的工作DA-CLIP来提升所劣化出来的LQ图像的质量,具体的方法是最小化LQ和HQ样本embeddings之间的L1距离。
为了改善泛化性能,作者先用LSDIR的数据集训练,然后用上文提到的数据劣化出的synthesis数据与赛事提供的数据精调。作者提到,引入赛事提供的paired数据后,效果提升很显著。
【作者看法】
这个参赛队主要IP都来自其本人的论文工作,首先respect。笔者会在后续进一步研究其publication。
但是回过头来也能看到, 作者不管是数据劣化、还是其IR-SDE、DA-CLIP的工作,都没有很好的解决domain gap的问题,才会出现其提到引入赛会数据精调后效果有显著的提升,并且 主观效果并没有很理想,对比下来其模型输出还是高频信息偏弱、且对比度是最弱的。
2.6、剩余4支队伍:主要都采用了扩散模型的DiffSR和StableSR
剩余4支队伍:TongJi-IPOE来自同济、ImagePhoneix和MARSHAL都来自港理工、HIT-IIL来自哈工大。介绍的篇幅不多,且在前几个队伍的技术框架下并没有太多的别样点,所以笔者就不再赘述,只挑选2个比较有意思的内容着以记录。
2.6.1、ImagePhoneix团队采用了感知loss的替代方案
本次参赛队伍的提交方案中普遍采用了感知loss来提升图像细节表现,但ImagePhoneix团队使用了Misalignment-Robust Frequency Distribution Loss for Image Transformation论文的方法,把图像FFT到频域,使用频域分布的Wasserstein距离来约束两个样本在感知层的loss。笔者评估,这样空域转频域的特征,在一定程度上应该能实现论文标题说指的misalignment-robust。该工作新鲜出炉,后续指的跟踪其他场景的应用情况。
2.6.2、MARSHAL团队复验了字符纹理上采样后有利于预训练扩散模型的表现
MARSHAL团队对赛事阶段2和3的图像倾向性进行了分析,并分别使用了遵照fidelity和人眼主观诉求的两阶段策略,后者采用扩散模型。考虑到扩散模型在字符细节上的短板,在最终推理环节,团队先把图像resize到2048输入到扩散模型,以此实现了稳定的字符纹理。

resize再送入扩散模型,处理结果的字符纹理完整且稳定
3、报告总结
- 笔者第一次将论文报告成文,一共1万1千余字,感慨于自身收获颇丰的同时,又难免包含不少遗憾,时间太少而卷帙浩繁,值得借鉴和研究的经验实在太多。而针对同一种策略,不同背景的视野也会有不同的解读,以上全部观点仅代表个人,挂一漏万、不无偏颇,非常恳请各位大佬指正。
- 全部团队的报告看毕,深感real-world图像处理问题训练集质量的关键性。小米团队自筹的万级UHD是在各支队伍中独领风骚的存在,并在此基础上精雕细琢其劣化策略与训练策略,笔者推测正因此、其模型复杂度不高但却能实现最好的图像效果;并且只有他明确在高层采用了全局注意力,在报告呈现的效果案例上,唯有小米团队的结果、草业的纹理相对保真且边缘顺滑不破碎。
- 对于预训练大模型的使用,刷榜自然可以大张旗鼓,但最终算法要产生价值,更多还是要受到算力的约束。而在面向real-world任务重,扩散模型仍然还有gap。若用针对domain gap的数据工程来精调,对算力资源又提出了挑战。因此,这条路依然任重道远。
- 一方面模型要尽量拟合到target domain,另一方面把数据通过一定预处理调整至模型的domain也不失为一种更好的trade-off,比如队伍中采用上采样来抑制扩散模型对字符纹理处理的瑕疵。
- 心愿单拉长了很多,一些笔者认为有意思的工作,后续都会逐步剖析解读,欢迎催更!
转自:
https://zhuanlan.zhihu.com/p/701048076