神经网络优化 - 小批量梯度下降
本文我们来学习神经网络优化常用的方法,小批量梯度下降。
目前,深度神经网络的参数学习主要是通过梯度下降法来寻找一组可以最小化结构风险的参数。在具体实现中,梯度下降法可以分:批量梯度下降、随机梯度下降以及小批量梯度下降三种形式。关于梯度下降,大家可以参考之前的博文:
机器学习-常用的三种梯度下降法_梯度下降算法有哪些-CSDN博客
在训练深度神经网络时,训练数据的规模通常都比较大。如果在梯度下降 时,每次迭代都要计算整个训练数据上的梯度,这就需要比较多的计算资源。另外大规模训练集中的数据通常会非常冗余,也没有必要在整个训练集上计算梯度。因此,在训练深度神经网络时,经常使用小批量梯度下降法(Mini-Batch Gradient Descent)。
一、小批量梯度下降在深度神经网络如何应用
令 𝑓(𝒙; 𝜃) 表示一个深度神经网络,𝜃 为网络参数,在使用小批量梯度下降进行优化时,每次选取 𝐾 个训练样本:
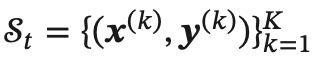
第 𝑡 次迭代(Iteration) 时损失函数关于参数 𝜃 的偏导数为:
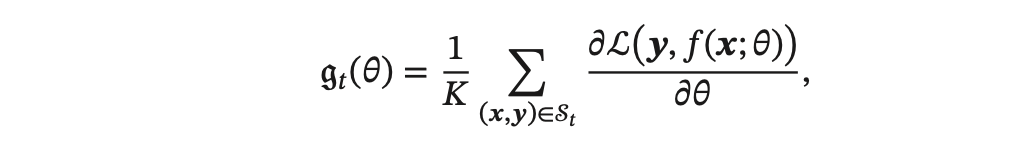
(这里的损失函数忽略 了 正则化项)
其中 L(⋅) 为可微分的损失函数,𝐾 称为批量大小(Batch Size)。
第 𝑡 次更新的梯度 g𝑡 定义为:

使用梯度下降来更新参数,
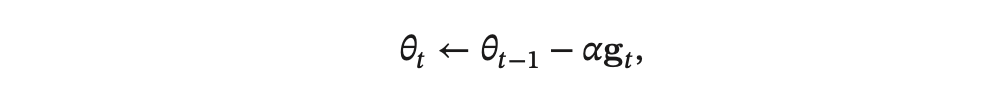
其中𝛼 > 0为学习率。
每次迭代时参数更新的差值 Δ𝜃𝑡 定义为:
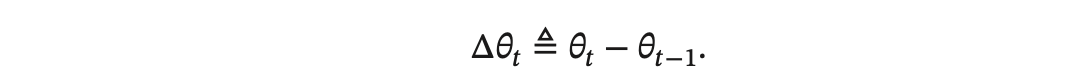
Δ𝜃𝑡 和梯度 𝒈𝑡 并不需要完全一致。Δ𝜃𝑡 为每次迭代时参数的实际更新方向,即
![]()
在标准的小批量梯度下降中,Δ𝜃𝑡 = −𝛼g𝑡.
从上面可以看出,影响小批量梯度下降法的主要因素有:
(1)批量大小𝐾
(2)学习率𝛼
(3)梯度估计
为了更有效地训练深度神经网络,在标准的小批量梯度下降法的基础上,也经常使用一些改进方法以加快优化速度,比如如何选择批量大小、如何调整学习率以及如何修正梯度估计。
接下来,在后面的博文中,会从这三个方面来介绍在神经网络优化中常用的算法。这些改进的优化算法也同样可以应用在批量或随机梯度下降法上。
结合上面的分析和数学表达式,有几个点,我们来一起解读一下。
二、为什么训练深度神经网络时,训练数据的规模通常都比较大?
在训练深度神经网络时,常常需要海量的训练数据,主要原因包括网络参数众多、模型容量大、过拟合风险高以及分布刻画复杂等。
1. 参数规模与模型容量巨大
深度网络通常包含数百万至数十亿个参数(权重和偏置),它们共同决定了模型能表达的函数空间大小。
-
高维参数空间:参数多意味着模型有能力拟合非常复杂的函数,但也意味着需要更多数据来“填满”这个空间,才能让优化过程找到有意义的解,而不是轻易陷入噪声学习。
-
容量–数据量匹配:理论和实践都表明,模型容量(参数数量)与训练样本数量需要保持一定比例,否则容易出现欠拟合或过拟合的极端情况。
2. 防止过拟合
过拟合指模型在训练集上表现很好,但对新数据(验证集、测试集)泛化能力差。大规模数据有助于:
-
降低方差:更多样化的样本能减少模型对训练噪声和偶然性的敏感度,从偏差–方差平衡角度来看,等价于在不显著提升偏差的前提下显著降低方差,从而提高泛化性能。
-
覆盖真实分布:足够多的数据能更全面地覆盖真实数据分布,减少分布偏差(dataset shift)和类不平衡带来的影响。
3. 学习复杂特征与层次结构
深度网络能自动从数据中学习多层次、多尺度的表征特征。
-
低层到高层特征:真实世界数据(如图像、语音、文本)往往具有高度非线性、层次化的结构,需要大量样本来让网络在每一层都学到稳健的模式。
-
数据多样性:更多样本提供了多种变化(光照、角度、背景等),网络才能学会忽略无关变动,专注于核心特征。
4. 优化动态与稳定性
-
梯度噪声减少:小批量梯度下降(Mini‑Batch SGD)结合大数据量,可在梯度估计中获得更低的噪声,促进稳定收敛。
-
学习率与批量大小:大数据量通常也意味着可采用更大的批量,从而可以设定更合适的学习率和优化超参数,提高训练效率。
5. 实践经验与行业共识
在计算机视觉、自然语言处理等领域的大规模竞赛和应用中,如 ImageNet、COCO、BERT、GPT 等模型,均依赖于千万级甚至百亿级数据样本,才取得了卓越性能。
三、在大规模训练集中,为什么数据通常会非常冗余,也没有必要在整个训练集上计算梯度?
在大规模训练集中,数据往往存在高度冗余,并且在每次迭代都使用全量数据计算梯度既耗时又不必要。下面分几个方面来说明其原因以及使用小批量(mini‑batch)而非全量梯度的优势。
概要
大规模数据集通常包含重复或相似的信息,因此全量(batch)梯度下降不仅计算成本极高,而且在早期迭代中“多余”数据对梯度估计的贡献逐渐边际递减。相比之下,小批量梯度下降(mini‑batch SGD)通过在有限且随机抽样的小批量上计算梯度,既能获得足够准确的参数更新方向,又大幅降低了计算负担和内存需求,同时帮助算法跳出鞍点、加速收敛和提升泛化能力。
1. 训练数据的高度冗余
1.1 样本近似独立同分布
大规模数据集(如 ImageNet、COCO)往往通过网络抓取或人工标注收集,产生了大量相似样本(相似图像、近似语句),它们对模型学习的增益边际递减。
-
过度覆盖:当数据量远超模型所需的样本复杂度时,新增样本往往与已有样本信息重叠,对梯度方向影响甚微。
-
噪声平均化:冗余数据可以帮助平滑噪声,但一旦达到某个规模后,继续收集更多相同模式的数据,对噪声抑制的边际效用降低。
1.2 数据集构成与分布
-
类不平衡和稀缺样本:过多“普通”样本掩盖了对少数类或难例的关注,反而不利于模型学习多样性特征。
-
重复与近似重复:图像或文本的微小变形/重采样会产生大量近似样本,增加了存储与 I/O 成本,却并不显著改善训练效果。
2. 全量梯度计算的成本与局限
2.1 计算与内存开销
-
时间复杂度:每次迭代都需遍历 N 个样本,若 N 达到上亿,单步更新耗时过长,不利于快速迭代和探索超参数。
-
内存瓶颈:存储全量梯度和中间激活需要巨大的内存/显存,常常超出硬件承载能力。
2.2 学习效率与收敛
-
收敛速度:全量梯度下降每一步都精准,但步长受限、更新频率低,导致收敛速度不如小批量方法灵活和快速。
-
鞍点与平坦区:在高维非凸问题中,全量梯度容易在鞍点或平坦区域停滞,小批量的噪声反而可提供“跳出”动力。
3. 小批量梯度下降的优势
3.1 近似期望与噪声注入
-
梯度近似:用大小为 B(通常 B≪N)的小批量样本估计全量梯度,满足
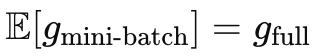
-
随机扰动:由于批量随机抽样带来的噪声,可帮助跳出鞍点、减少过拟合并改善泛化。
3.2 计算与并行效率
-
频繁更新:同样计算预算下,可进行更多次参数更新,加速初期收敛;
-
硬件友好:小批量可并行化计算(GPU、TPU),在加速器上比全量梯度更高效。
3.3 收敛与泛化
-
偏差–方差权衡:小批量引入噪声,略增更新偏差、显著降低方差,从而提高在未见数据上的稳定性和泛化能力。
-
动态学习率:常与自适应优化器(Adam、RMSprop)结合,通过小批量梯度的方差估计自适应调整学习率,提升收敛和鲁棒性。
4. 实践建议
-
选择合适批量大小:通常在 32∼512 之间做超参数搜索,平衡更新稳定性和硬件利用率。
-
数据去重与采样:对高冗余数据集做去重或加权采样,提升稀缺样本的训练比例。
-
在线数据增强:用数据增强(翻转、裁剪、噪声)替代简单复制,制造更多有效多样性样本。
四、上面提到:令 𝑓(𝒙; 𝜃) 表示一个深度神经网络,𝜃 为网络参数,对于神经网络使用小批量梯度下降进行优化时,第 𝑡 次更新的梯度 g𝑡 定义为g𝑡 ≜ 𝔤𝑡(𝜃𝑡−1)。为什么第t次更新的梯度,参数𝜃却是𝜃(𝑡−1)呢?而不是𝜃(t)呢?
概要
在小批量梯度下降中,参数迭代遵循
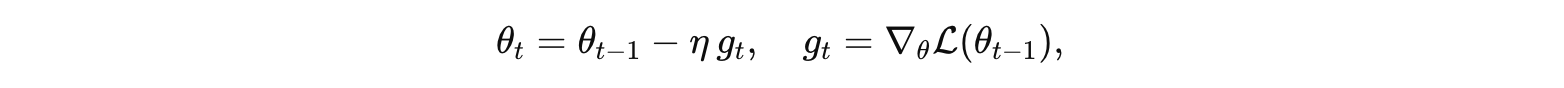
这里梯度 gt 必须在更新之前根据当前(亦即上一次迭代得到的)参数 θ_{t-1} 计算。若改用未来的 θt ,则产生循环依赖:更新本身就依赖于尚未计算的梯度,因而无法实现。这个“先算梯度再更新参数”的流程不仅是算法定义所需,也是保证每一步更新基于已知信息、并行计算与收敛分析得以实施的关键。
1. 算法流程的先后顺序
1.1 经典梯度下降伪码
初始化 θ₀
for t = 1, 2, … dog_t ← ∇_θ L(θ_{t−1}) # 在上次参数 θ_{t−1} 处计算梯度θ_t ← θ_{t−1} − η · g_t # 用该梯度更新参数
end for
-
梯度计算 必须基于已知参数 θ_{t-1},这样才能获得确定的导数值。
-
基于将要得到的 θt 来计算梯度是自相矛盾的,因为 θt 又依赖于同一梯度。
1.2 小批量版本
在小批量梯度下降中,仅用当前批次数据估计梯度,仍然是
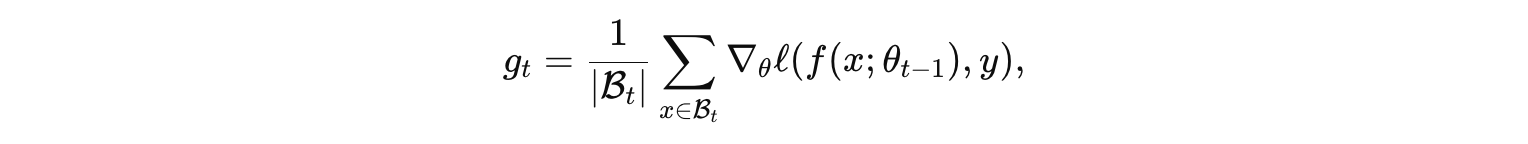
然后再执行更新。
2. 循环依赖与实现可行性
-
无循环依赖:先计算梯度再更新,保证每一步所需的数据(θ_{t-1}、当前批次样本)都是可用的。
-
避免未来依赖:如果梯度定义为 gt=∇L(θt),则在第 t 步就需要先知道 θt,但 θt 又需要 gt,形成矛盾。
3. 并行化与收敛分析
3.1 并行计算
大规模分布式或 GPU 并行训练时,Worker 节点读取当前参数版本 θ_{t-1},各自计算 gt,再集中更新。此时所有节点都使用同一“旧”参数,保证计算一致性。
3.2 收敛性
大多数收敛证明(如梯度下降的收敛率分析)都假设更新式

基于这个先梯度后更新参数的顺序,才能推导学习率范围与误差界。