在云计算和生物信息学领域,执行大规模计算任务时的性能与成本效率至关重要。MemVerge推出的JuiceFlow通过JuiceFS和云端Memory Machine Cloud(简称“MMCloud”)平台,为Nextflow工作流(pipeline)提供了一种高效且经济的执行方案。

1. JuiceFlow简介
JuiceFlow是一种实时按需的,基于管控面的组合配置方案。该方案以JuiceFS作为主要的文件系统来执行NextFlow工作流。JuiceFS是一个开源的高性能分布式文件系统,专为云环境设计,具备以下特点:
-
数据与元数据分离:JuiceFS将文件数据以块的形式存储在对象存储平台(如Amazon S3)中,而元数据则存储在数据库(如Redis)中,这种设计提升了性能和可扩展性。
-
卓越性能:JuiceFS旨在实现毫秒级延迟和接近无限的吞吐量,非常适合需要高性能计算的Nextflow工作流。
-
与MMCloud的无缝集成:MMCloud通过提供预配置的Nextflow服务模板和JuiceFS典型配置,极大地简化了用户的部署过程。
JuiceFlow的按需特性意味着,一旦Nextflow运行完成,无论是成功还是失败,节点都会自动终止,从而避免了额外的费用。此外,JuiceFlow能够从对象存储Bucket重新加载先前的运行结果,只要Bucket中存在每个作业的元数据文件,这为数据管理和工作流执行提供了极大的便利。
JuiceFlow提供了直观的日志监控方式,用户可以在OpCenter图形用户界面中轻松查看Nextflow的标准输出和个别作业的详细日志。
2. JuiceFlow发展史
JuiceFS + Nextflow解决方案的开发经历了多次迭代,最终创建了JuiceFlow。
-
最初,JuiceFS文件系统和Nextflow被集成在同一个主机实例中,用户需要通过SSH登录实例来启动运行,并且在运行结束后手动处理虚拟机。
-
第二阶段,JuiceFS和Nextflow被分配到两个不同的实例中,JuiceFS保持持久性,而Nextflow组件则在运行结束后自动终止,减少了用户的干预。
-
最终,JuiceFlow将JuiceFS和Nextflow集成到一个节点中,同时保留了上一阶段的无干预特性,用户只需通过一个简单的CLI命令即可完成部署。
3. 实操指南:JuiceFlow的设置与运行
要设置JuiceFlow,您需要准备一个可用的MMC OpCenter、一个对象存储Bucket以及相应的访问密钥。用户只需提交一个包含所有必要信息的命令,以及两个主要脚本:
-
transient_JFS.sh:将对象存储Bucket的工作目录格式化为JuiceFS格式。
-
job-submit.sh:包含Nextflow的输入参数和MMC配置。
提交命令后,系统将启动一个虚拟机,该虚拟机负责在指定的对象存储Bucket内格式化一个目录为JuiceFS。如果Bucket中存在先前作业的元数据文件,JuiceFlow将加载相应的JuiceFS分区,使当前作业能够访问该目录。此外,JuiceFlow还会生成一个针对MMCloud优化的Nextflow配置文件,使用nf-float插件,并执行指定的Nextflow命令。
无论结果如何(失败或成功),工作流执行后,JuiceFlow将把JuiceFS文件系统的元数据归档到用户的工作目录中。如果使用相同的Bucket再次执行JuiceFlow,它将识别元数据文件并重新加载相同的JuiceFS文件系统。这个特性对于使用Nextflow执行中的-resume命令的实例特别有益。
4. JuiceFlow的价值
01 成本效益
JuiceFlow的按需节点在Nextflow工作流执行完毕后自动终止,避免了额外的资源浪费。以nf-core流程为例,JuiceFlow在AWS Spot实例上运行时,不仅执行时间缩短,而且成本也得到了有效控制。
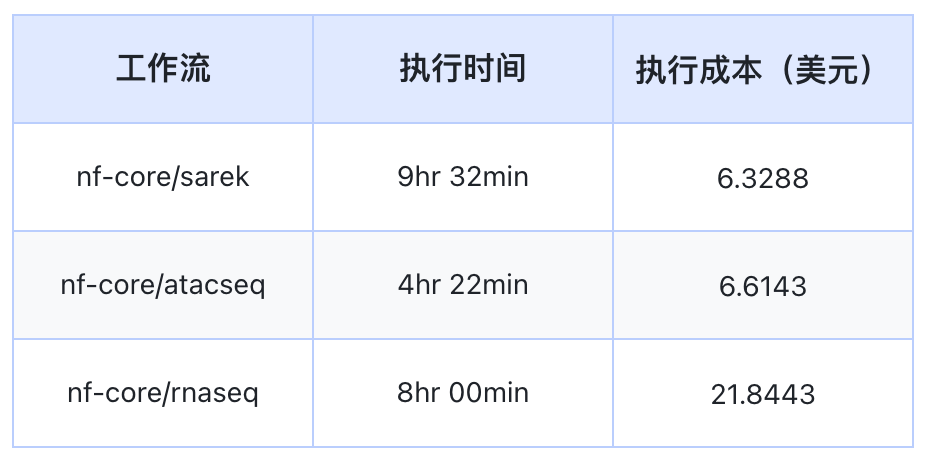
说明:JuiceFlow支持各主流云平台,当在Spot实例(又称抢占式实例或竞价实例)上运行时,利用MMCloud的Spot保护特性。该特性在Spot实例被抢占时自动保存作业进度,并在新Spot实例上恢复它,确保连续性。
02 简化操作
用户只需通过一个命令即可启动整个工作流,无需复杂的SSH登录和手动管理。
5. 结语
JuiceFlow以其高性能、低成本和用户友好的特性,为生物信息学和云计算领域提供了一种创新的解决方案。它不仅优化了Nextflow工作流的执行效率,还通过简化的操作流程,降低了用户的使用门槛,是执行复杂计算工作流的理想选择。
![【Linux】 shell 学习汇总[转载]](https://i-blog.csdnimg.cn/blog_migrate/e52248eb4552f1585ca5de9c0520fa69.png)














![[代码审计]宏*HCM最新文件上传漏洞分析复现](https://i-blog.csdnimg.cn/direct/9e67875c41dd44ff93a67191d8744acf.png)