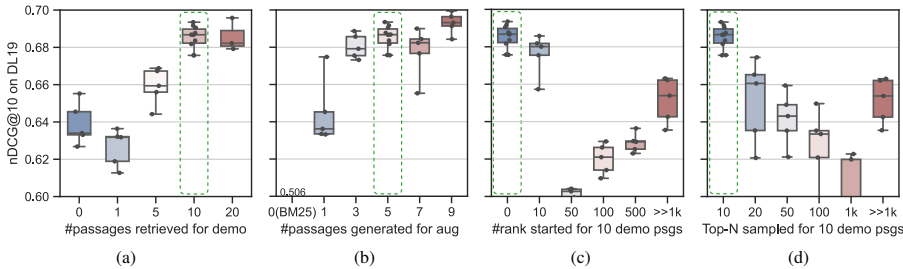
Python 列表推导式是什么
列表推导式是 Python 语言特有的一种语法结构,也可以看成是 Python 中一种独特的数据处理方式,
它在 Python 中用于 转换 和 过滤 数据。
其语法格式如下所示,其中 [if 条件表达式] 可省略。
[表达式 for 迭代变量 in 可迭代对象 [if 条件表达式]]
注意:学习列表推导式的前提是掌握 Python for 循环。
列表推导式中存在两个名词,一个是 列表,另一个是 推导式 ,列表我们很清楚,就是 Python 的一种数据类型,
而推导式只是一个普通的语法定义词,有的教程里,会将其叫做 解析式,二者是一样的概念。
列表推导式会返回一个列表,因此它适用于所有需要列表的场景。
怎么用
基础使用
列表推导式最常见的场景就是优化简单循环。
for 循环写法
my_list = [1,2,3]
new_list = []
for i in my_list:new_list.append(i*2)print(new_list)
列表推导式写法
nn_list = [i*2 for i in my_list]
print(nn_list)
是不是对比看就是将 for 循环语句做了变形之后,增加了一个 [],不过需要注意的是,列表推导式最终会将得到的各个结果组成一个新的列表。
再看一下列表推导式语法构成 nn_list = [i*2 for i in my_list] ,for 关键字后面就是一个普通的循环,前面的表达式 i*2 其中的 i 就是 for 循环中的变量,也就是说表达式可以用后面 for 循环迭代产生的变量,理解这个内容列表推导式就已经掌握 9 成内容了,剩下的是熟练度的问题。
在将 if 语句包含进代码中,运行之后,你也能掌握基本技巧,if 语句是一个判断,其中 i 也是前面循环产生的迭代变量。
nn_list = [i*2 for i in my_list if i>1]
print(nn_list)优化两层 for 循环
这些都是一般技能,列表推导式能支持两层 for 循环,例如下述代码:
nn_list = [(x,y) for x in range(3) for y in range(3) ]
print(nn_list)
当然如果你想**加密(谁都看不懂你的代码)**你的代码,你可以无限套娃下去,列表推导式并没有限制循环层数,多层循环就是一层一层的嵌套,你可以展开一个三层的列表推导式,就都明白了
nn_list = [(x,y,z,m) for x in range(3) for y in range(3) for z in range(3) for m in range(3)]
print(nn_list)
当然在多层列表推导式里面,依旧支持 if 语句,并且 if 后面可以用前面所有迭代产生的变量,不过不建议超过 2 成,超过之后会大幅度降低你代码的可阅读性。
当然如果你希望你代码更加难读,下面的写法都是正确的。
nn_list = [(x, y, z, m) for x in range(3) if x > 1 for y in range(3) if y > 1 for z in range(3) for m in range(3)]
print(nn_list)
nn_list = [(x, y, z, m) for x in range(3) for y in range(3) for z in range(3) for m in range(3) if x > 1 and y > 1]
print(nn_list)
nn_list = [(x, y, z, m) for x in range(3) for y in range(3) for z in range(3) for m in range(3) if x > 1 if y > 1]
print(nn_list)现在你已经对列表推导式有比较直观的概念了,列表推导式对应的英文是 list comprehension,有的地方写作列表解析式,基于它最后的结果,它是一种创建列表的语法,并且是很简洁的语法。
有了两种不同的写法,那咱们必须要对比一下效率,经测试小数据范围影响不大,当循环次数到千万级时候,出现了一些差异。
import time
def demo1():new_list = []for i in range(10000000):new_list.append(i*2)def demo2():new_list = [i*2 for i in range(10000000)]
s_time = time.perf_counter()
demo2()
e_time = time.perf_counter()
print("代码运行时间:", e_time-s_time)
运行结果:
# for 循环
代码运行时间: 1.3431036140000001
# 列表推导式
代码运行时间: 0.9749278849999999在 Python3 中列表推导式具备局部作用域,表达式内部的变量和赋值只在局部起作用,表达式的上下文里的同名变量还可以被正常引用,局部变量并不会影响到它们。所以其不会有变量泄漏的问题。例如下述代码:
x = 6
my_var = [x*2 for x in range(3)]print(my_var)
print(x)列表推导式还支持嵌套
参考代码如下,只有想不到,没有做不到的。
my_var = [y*4 for y in [x*2 for x in range(3)]]
print(my_var)用于转换数据
可以将可迭代对象(一般是列表)中的数据,批量进行转换操作,例如将下述列表所有元素翻两倍。
my_list = [1,2,3]
代码如下所示:
my_list = [1, 2, 3]
new_list = [item * 2 for item in my_list]
print(new_list)结果可以自行编译运行。
掌握上述语法的关键点是 item ,请重点关注 item 从 my_list 遍历而来,并且 item*2 尾部与 for 循环存在一个空格。
用于过滤数据
列表表达式,可以将列表中满足条件表达式的值进行筛选过滤,获取目标数据。
my_list = [1, 2, 3]
new_list = [item for item in my_list if item > 1]
print(new_list)掌握上述语法的关键是 if ,其余要点是注意语法编写结构。
接下来你可以尝试将上述编程逻辑,修改为 for 循环语法,学习过程中要着重理解以上两种语法结构可以相互转换,
当你可以无缝将二者进行转换时,该技能你就掌握了。
有些人会将列表推导式当做 for 循环的简化版。
字典推导式
有了列表推导式的概念,字典推导式学起来就非常简单了,语法格式如下:
{键:值 for 迭代变量 in 可迭代对象 [if 条件表达式]}
直接看案例即可
my_dict = {key: value for key in range(3) for value in range(2)}
print(my_dict)
得到的结果如下:
{0: 1, 1: 1, 2: 1}
此时需要注意的是字典中不能出现同名的 key,第二次出现就把第一个值覆盖掉了,所以得到的 value 都是 1。
最常见的哪里还是下述的代码,遍历一个具有键值关系的可迭代对象。
my_tuple_list = [('name', '橡皮擦'), ('age', 18),('class', 'no1'), ('like', 'python')]
my_dict = {key: value for key, value in my_tuple_list}
print(my_dict)元组推导式与集合推导式
其实你应该能猜到,在 Python 中是具备这两种推导式的,而且语法相信你已经掌握了。不过语法虽然差不多,但是元组推导式运行结果却不同,具体如下。
my_tuple = (i for i in range(10))
print(my_tuple)
运行之后产生的结果:
<generator object <genexpr> at 0x0000000001DE45E8>
使用元组推导式生成的结果并不是一个元组,而是一个生成器对象,需要特别注意下,这种写法在有的地方会把它叫做生成器语法,不叫做元组推导式。
集合推导式也有一个需要注意的地方,先看代码:
my_set = {value for value in 'HelloWorld'}
print(my_set)
因为集合是无序且不重复的,所以会自动去掉重复的元素,并且每次运行显示的顺序不一样,使用的时候很容易晕掉。
提高场景
再次查看推导式语法结构中,涉及了一个关键字,叫做 可迭代对象,因为我们可以把自己目前掌握的所有可迭代对象,
都进行一下尝试,例如使用 range() 函数。
my_list = [1, 2, 3]
new_list = [item for item in range(1, 10) if item > 5]
print(new_list)
检验是否掌握,可以回答下述两个问题。
- 如果可迭代对象是一个字典,你该如何操作?
- 如果可迭代对象位置使用了
enumerate()函数,你该如何操作?
除了可迭代对象部分可以扩展知识点, if 表达式 中的 条件表达式 也支持各种布尔运算,如果用中文进行翻译,
表示把满足条件的元素,放置到新的列表中。
扩展知识
由于列表推导式涉及了数据类型,所以可大胆推断,还存在其它推导式语法,Python 也确实是这样设计的。
你可以继续学习下述内容,而且知识结构基本一致。
- 字典推导式
- 集合推导式
- 生成器推导式
列表推导式的学习,不要过于在意细节,也无需要求学会即掌握,因为该知识点属于语法糖(编程小技巧),
所以在初学阶段,了解即可,随着编程学习的深入,你会自然而然的将可用推导式的地方,修改为推导式。
Python 三元表达式是什么
Python 中没有其它语言的三元表达式(三目运算符)相关说法,但是有类似的语法。
在 Python 中,三元表达式是一种语法结构,一般被 Python 开发者叫做条件表达式,它的结构如下所示:
表达式(1)为 True 执行语句 if 条件表达式(1) else 表达式(1)为 False 执行语句
怎么用
用于 if 语句简化
三元表达式可以将简单的 if 语句 缩减为一行代码。
age = 20cn = "成年" if age >= 18 else "未成年"
print(cn)
原 if 语句 如下所示:
age = 20
if age >= 18 :cn = "成年"
else:cn = "未成年"返回多个条语句
可以编写如下代码结构,在条件表达式中返回多条语句。
age = 20cn = "成年", "大于18" if age >= 18 else "未成年"
print(cn)
代码返回一个元组,内容为 ('成年', '大于18') ,这里一定注意不要使用分号 ; ,否则只返回第一个语句的结果。
age = 20cn = "成年"; "大于18" if age >= 18 else "未成年"
print(cn)
运行代码之后,输出 成年 。
在函数内部使用三元表达式
有些简单的判定逻辑,可以直接使用三元表达式简化,例如判断传入参数是否为偶数。
def even_num(num):return True if num % 2 == 0 else False三元表达式用于列表推导式
在列表推导式知识点中,也存在三元表达式的落地应用,例如下述代码。
li = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
# ret = [i for i in li if i % 2 == 0]
ret = [i if i % 2 == 0 else None for i in li]
print(ret)
上述代码重点注意列表生成器部分代码,三元表达式所在位置。
三元表达式与 lambda
有时候可以将三元表达式与 lambda 进行结合,让代码变得更加简洁。
声明一个函数,返回较大值
def max(a, b):if a > b:ret = aelse:ret = breturn retr = max(5, 6)
print(r)
由于上述代码非常简单,可以直接使用 lambda 匿名函数实现。
max = lambda a, b: a if a > b else b
r = max(10, 15)
print(r)提高场景
Python 条件表达式可以嵌套使用,但是建议最多嵌套两层,而且是在代码简单的情况下,具体编码如下所示,你需要重点学习下述问题。
在嵌套的时候,还需要注意 if 和 else 配对问题。
# 编写一个三元表达式,首先判断其值大于20,然后在判断是奇数(案例,无实际意义)
num = 19
ret = "小于20" if num < 20 else ("奇数" if num % 2 == 1 else "偶数")
print(ret)扩展知识
在很多地方会将 Python 的条件表达式进行扩展,出现下述两种用法,但都属于炫技能力,实战性不强。
例如下述内容:
元组条件表达式
age = 20cn = ("未成年", "成年")[age >= 18]
print(cn)
语法格式如下所示
(当后面的表达式为假时返回,当后面的表达式为真时返回)[条件表达式]
字典条件表达式
age = 20cn = {False: "未成年", True: "成年"}[age >= 18]
print(cn)
你会发现,上述两种写法都有一些故弄玄虚,而且代码 非常不易 阅读,所以不建议实战编码时使用。
Python 断言是什么
Python 断言,即 Python assert 语句,简单理解就是简易版的 if 语句,
用于判断某个表达式的值,结果为 True,程序运行,否则,程序停止运行,抛出 AssertionError 错误。
语法格式如下所示:
assert 表达式
类比 if 语句,如下所示:
if not 表达式:raise AssertionError在 assert 表达式之后,可以增加一个参数 [, arguments],等价的 if 语句如下所示:
if not 表达式:raise AssertionError(arguments)怎么用
模拟场景
在游戏里面设置一个未满 18 岁禁止访问的功能。
def overage18(age):assert age >= 18, "对不起未满18岁,无法进行游戏"print("享受欢乐游戏时光")if __name__ == '__main__':overage18(15)但是这个案例并不是一个完美的案例,因为断言是为了告知 开发人员 ,你写的程序发生异常了。
如果一个潜在错误在程序编写前就能考虑到,例如程序运行时网络中断,这个场景就不需要使用断言。
断言主要为调试辅助而生,为的是程序自检,并不是为了处理错误,程序 BUG 还是要依赖 try… except 解决。
由于断言是给 开发人员看的,所以下述案例的断言是有效的。
def something():"""该函数执行了很多操作"""my_list = [] # 声明了一个空列表# do somethingreturn my_listdef func():"""调用 something 函数,基于结果实现某些逻辑"""ret = something()assert len(ret) == 18, "列表元素数量不对"# 完成某些操作使用断言要注意:
不要用断言验证用户的输入,这是因为 python 通过命令行运行时,如果增加 -O 标识,断言就被全局禁止了,你的所有验证就都丢失了。
常用断言函数
- assertEqual(a,b,msg=msg):判断两个值是否相等;
- assertNotEqual(a,b,msg=msg):上一函数的反义;
- self.assertTrue(a,msg=none):判断变量是否为 True;
- assertFalse(a,msg=none):同上反义;
- assertIsNone(obj=‘’):判断 obj 是否为空;
- assertIsNotNone(obj=‘’):同上反义;
扩展知识
Python 断言的适用场景
进行防御性的编程
我们在使用断言的时候,应该捕捉不应该发生的非法情况。这里要注意非法情况与异常错误之间的区别,
后者是必然存在的并且是一定要作出处理的。而断言后的条件不一定发生。
对假定条件做验证
断言是对程序员的假定做验证,因此这些假定的异常不一定会触发。
with....as...
python操作文件时,需要打开文件,最后手动关闭文件。
通过使用with...as...不用手动关闭文件。当执行完内容后,自动关闭文件。
Python 异常捕获是什么
程序异常,就是程序出错了,程序员一般叫做 BUG(八哥),写程序不出错是不可能发生的事情,而程序员要做的事情就是及时的捕获错误,修改错误。
最常见的错误 - 除数为 0
在数学中也存在类似的问题,除数不可以为 0。相同的概念在编程中也是存在的。
num1 = 20
num2 = 0
num3 = num1 / num2
print(num3)Traceback (most recent call last):File "D:/gun/2/demo7.py", line 3, in <module>num3 = num1 / num2
ZeroDivisionError: division by zero
错误内容就是末尾的 ZeroDivisionError: division by zero ,当出现错误程序崩溃,终止运行。错误异常中也提示了错误出现的行数 line 3 在第三行,但查看行号排查错误在很多时候无法直接解决问题,因为出错的地方不在行号那一行,修改 BUG 的效率一般会随着你对 Python 学习的深入逐步增强改善。
try … except 语句
刚才的程序出现错误就终止运行了,如何避免程序被强迫终止,出现问题提示出问题,然后继续运行呢?这就是 try … except 语句使用的场景了。
语法格式:
try:可能会出错的代码
except 异常对象:处理异常代码
按照上述语法格式修改上文代码。
num1 = 20
num2 = 0
try:num3 = num1 / num2
except ZeroDivisionError:print("除数不可以为 0 ")
此时程序不会报错,当发现除数为 0 会进入异常处理,直接输出除数不能为 0。
try 表示测试代码部分是否存在异常,except 表示捕获异常,前提是出现异常。如果 try 语句中没有任何错误,except 中的代码不会执行。
还有一点需要注意,在 except 后面是异常对象,该异常对象我们设置为 ZeroDivisionError 这是因为已经知道是会出现这个异常,如果在编码过程中不知道会出现哪种异常,依旧会出现错误。
num1 = 20
num2 = "abc"
try:num3 = num1 / num2
except ZeroDivisionError:print("除数不可以为 0 ")
上述代码依旧会报错,报错的异常为:
Traceback (most recent call last):File "D:/gun/2/demo7.py", line 4, in <module>num3 = num1 / num2
TypeError: unsupported operand type(s) for /: 'int' and 'str'
如果想在 except 后面支持本异常,需要添加上 TypeError。
num1 = 20
num2 = "abc"
try:num3 = num1 / num2
except (ZeroDivisionError,TypeError):print("除数不可以为 0 ")
也可以分开编写:
num1 = 20
num2 = "abc"
try:num3 = num1 / num2
except ZeroDivisionError:print("除数不可以为 0 ")except TypeError:print("除数类型不对")
该种写法在书写的时候需要预先知道会提示哪种异常,如果异常不清楚那可以省略异常对象,直接使用下述代码即可。
num1 = 20 num2 = "abc" try: num3 = num1 / num2 except: print("除数不可以为 0 ")
try … except … else 语句
在 try … except 语句后面可以增加一个 else 语句,该语句表示的含义可以按照如下描述进行理解,当出现异常的时候执行 except 语句中的代码,当无异常执行 else 语句代码。
num1 = 20
num2 = 1
try:num3 = num1 / num2
except ZeroDivisionError:print("除数不可以为 0 ")except TypeError:print("除数类型不对")else:print("无异常,会被执行")
以上代码无错误,那 else 语句就会被执行到。
常见的异常类型
在编写代码的过程中,你需要掌握一些常见的异常类型,熟记它们可以帮助你快速进行错误排查。
- AttributeError 某个对象没有属性
- Exception 通用型异常对象
- FileNotFoundError 找不到文件
- IOError 输入输出异常
- IndexError 索引异常
- KeyError 键异常
- NameError 对象名称异常
- SyntaxError 语法错误
- TypeError 类型错误
- ValueError 值错误
以上错误都属于常见错误,其中重点以 Exception 通用异常对象与 SyntaxError 语法错误为主,它们两个是最常出现的。
很多时候其实直接使用通用异常对象 Exception 就可以了,不需要记住所有的异常类型的。
捕捉多个异常
在上文已经接触过捕捉多个异常的语法格式了,可以在学习一下。
try:可能出错的代码块
except 异常对象1:异常处理代码块
except 异常对象2:异常处理代码块一个 except 捕获多个异常
Python 也支持使用一个 except 捕获多个异常,具体语法格式如下:
try:可能出错的代码块
except (异常对象1,异常对象2...):异常处理代码块直接抛出异常
捕获到异常之后,可以直接抛出 Python 给内置好的异常信息,例如:
num1 = 20
num2 = 0
try:num3 = num1 / num2
except ZeroDivisionError as e:print(e)except TypeError as e:print(e)else:print("无异常,会被执行")
注意 except 后面异常对象使用 as 关键字起了一个别名叫做 e,然后直接输出 e 就是 Python 内置好的错误信息了。这里的 e 可以为任意名称,遵循变量命名规则即可。
finally 语句
try … except 语句还可以和 finally 语句配合,形成下述语法格式:
try:可能出错的代码块
except:代码出错执行的代码块
else:代码正常执行的代码块
finally:无论代码是否有异常出现都会执行的的代码块
finally 语法需要与 try 语句配合使用,无论是否有异常出现都会执行该语句内容,具体代码大家可以自行测试即可。
Python 异常捕获扩展部分
本篇博客主要写的是异常相关知识,在 Python 代码的编写过程中经常会出现异常,一般情况下程序员都叫做 出 BUG 了,这个 BUG 就是臭虫的意思,表示程序出臭虫了。当然很多时候我们也戏称“无 BUG,不编程”。
发现 BUG,解决 BUG,程序员不是在写 BUG 的路上,就是在改 BUG 的路上,好友哲理。
关于异常部分,还有如下内容可以扩展。
- 使用 raise 抛出异常
- 使用 traceback 模块记录异常信息到文件中
- 程序断言 assert
Python 字符串方法是什么
Python 字符串是 Python 内置的一种数据类型,本篇博客要学习的内容就是字符串对象的方法。
先来学习第一个知识点,Python 字符串,字符串是一个编程名词,翻译过来就是字符组成的串(跟没说一样)
在 Python 中,用引号来表示字符串,例如 双引号 ",单引号 ',还有一个奇葩的三引号 """,对应的三单引号 '''。
所以下述代码都是在 声明 一个字符串。
name = "橡皮擦"
name = '橡皮擦'
name = """橡皮擦"""
name = '''橡皮擦'''此时你应该尝试输入一下上述代码,找找编程的感觉,如果你能得到如下几个结论,证明水平还不错。
- 引号都是成对出现的,前面一个后面一个;
- 单引号对应单引号,双引号对应双引号,三引号对应三引号;
- 所有引号都是在英文模式下输入的,不能用中文的引号。
字符串会伴随我们的整个编程生涯,几乎每段代码都会碰到,因此咱们将其放在一开始就进行讲解。
怎么用
截止目前,你只接触到了 Python 字符串的概念,那你来看一下 '1' 是字符串吗?
答案肯定是,因为 1 被单引号包裹起来了。
既然字符串是一个字符的串,那你就可以把它当成糖葫芦串,你可以对糖葫芦做什么,就能对字符串做什么,
例如吃第一个,吃最后一个,吃中间的 2 个,在头上插入一个山楂,在尾部插入一个山楂,数数山楂的数量……
这些对应到 Python 字符串中,就是各种编程语法,编程概念,咱们一起翻译翻译。
我有一个字符串(糖葫芦),我要吃第一个
tang_hu_lu = "都说冰糖葫芦儿酸" # 声明字符串
print(tang_hu_lu) # 打印输出字符串
print(tang_hu_lu[0]) # 打印字符串的第一个字符
注意代码都是在
jupyter中进行编写,然后点击运行实现效果,运行的快捷键是shift+enter。
又是一段代码,里面又涉及了很多编程概念,例如 tang_hu_lu 你已经知道它是一个变量了,
但是 Python 变量是有命名规范的,例如 1_a 就是错误的,命名规范是啥呢?
学习建议是直接搜索,只有一个原则需要告诉你,就是命名尽量有含义,哪怕你用拼音。
# 表示注释,相当于备注的意思,写在 # 后面的内容不会被 Python 软件 执行。
tang_hu_lu[0] 这里就有趣了,在变量名称后面跟了一个中括号[],并且在里面写了一个数字 0,
它表示取这个串里面的第一个字符,在编程语言中,报数一般从 0 开始,也就是 0 表示第一位,
知道二进制不?二进制用 0,1 表示,所以从 0 开始数。
取第一个字符咱们已经会了,那最后一个呢
tang_hu_lu = "都说冰糖葫芦儿酸" # 声明字符串
print(tang_hu_lu) # 打印输出字符串
print(tang_hu_lu[-1]) # 打印字符串的最后一个字符
print(tang_hu_lu[7]) # 打印字符串的最后一个字符
上述代码就实现了,注意中括号里面的数字 [-1] 就是倒着数最后一个,当然你可以顺着数,
数到 7 就是第八个山楂了,这里尝试把 7 修改成 8 ,看一下会报什么错误吧。
到这里就不得不抛出一个新的名词了,索引,刚才中括号中的数字就是 索引值,又是一个新概念,这就是编程。
字符串的第一个和最后一个你都能获取到了,吃中间的怎么办。
tang_hu_lu = "都说冰糖葫芦儿酸" # 声明字符串
print(tang_hu_lu) # 打印输出字符串
print(tang_hu_lu[2:4]) # 输出冰糖
print(tang_hu_lu[3:5]) # 输出糖葫
注意中括号扩展了,变成了 2 个数字,中间还有一个英文的冒号,此时一定要对比着原字符串进行学习。
- 都说冰糖葫芦儿酸
- 0 1 2 3 4 5 6 7
看好各个的位置
[2:4]输出冰糖,分别对应索引 2,索引 3 位置的字符;[3:5]输出糖葫,分别对应索引 3,索引 4 位置的字符;
那 [0:6] 你知道输出什么了吗?能说出来,恭喜你,Python 字符串切片你已经掌握 90%了,想不到吧,又是一个新概念,
切片,多么形象!
字符串扩展方法
字符串除了切片用法以外,还可以使用一个新的概念,叫做 对象的方法,在 Python 中有一个说法,叫做万物皆对象(对象的概念我们在后文展开学习,现在知道这么回事即可),例如现在有一个字符串,内容是 "都说冰糖葫芦儿酸"。
先看代码
my_str = "都说冰糖葫芦儿酸"
a = my_str.find("糖")
print(a) # 输出内容为 3find() 方法
上述代码中,在字符串变量 my_str 的后面增加一段代码 .find("糖"),其中 .find() 就是一个字符串对象的方法,它的用途你顺着刚才的代码在细琢磨,就能知道,是查找 "糖" 这个小字符串在大字符串中的索引值。
同理,还有哪些需要掌握的字符串对象方法呢?
my_str = "AaBbCcDd"
new_my_str = my_str.title()
print(new_my_str) # Aabbccddtitle() 方法
.title() 方法表示将字符串首字母大写
my_str = "AaBbCcDd"
new_my_str = my_str.upper()
print(new_my_str) # AABBCCDD
**upper() 方法和 lower() 方法 **
.upper() 方法表示将字符串全部大写,全部小写是 .lower()
字符串去除左右两端的空格。
my_str = " AaBbCcDd "
new_my_str = my_str.strip()
print(new_my_str)
除了这些,字符串对象的方法还有很多,但是不需要记忆,你需要去搜索一些相关的博客进行阅读,
搜索关键字为 Python 字符串方法,然后看上几篇博客,最终得到下面这个结论:
“哦~字符串对象有这些方法,可以大小写转换,可以去除空格,可以检索字符串,可以统计字符出现次数,
还能判断字符串中字符内容……”
子串搜索相关方法
count() 方法
语法格式如下所示:
my_str.count(sub_str[, start[, end]])
返回字符串 my_str 中子串 sub_str 出现的次数,可以指定从开始(start)计算到结束(end)。
print('abcaaabbbcccdddd'.count('a'))endswith()和 startswith()
方法原型如下
my_str.endswith(suffix[, start[, end]])
my_str.startswith(prefix[, start[, end]])
endswith() 检查字符串 my_str 是否以 suffix(可以是一个元组) 结尾,返回布尔值的 True 和 False。startswith() 用来判断字符串 my_str 是否是以 prefix 开头。
find(),rfind()和 index(),rindex()
函数原型如下所示:
my_str.find(sub[, start[, end]])
my_str.rfind(sub[, start[, end]])
my_str.index(sub[, start[, end]])
my_str.rindex(sub[, start[, end]])
find() 搜索字符串 my_str 中是否包含子串 sub,包含返回 sub 的索引位置,否则返回"-1"。
index() 和 find() 不同点在于当找不到子串时,抛出ValueError错误。
替换相关方法
replace()
my_str.replace(old, new[, count])
将字符串中的 old 替换为 new 字符串,如果给定 count,则表示只替换前 count 个 old 子串。
分割和合并
split()、rsplit()和 splitlines()
my_str.split(sep=None, maxsplit=-1)
my_str.rsplit(sep=None, maxsplit=-1)
my_str.splitlines([keepends=True])
split() 根据 sep 对 my_str 进行分割,maxsplit用于指定分割次数。
splitlines() 用来分割换行符。
join()
my_str.join(iterable)
将可迭代对象中的元素使用字符 my_str 连接起来。
修剪
strip()、lstrip()和 rstrip()
my_str.strip([chars])
my_str.lstrip([chars])
my_str.rstrip([chars])
分别是移除左右两边、左边、右边的字符 char。默认移除空白(空格、制表符、换行符)。
上述代码中的 len() 就是一个 Python 内置函数,它表示统计长度,
注意看内置函数和刚才学到的方法之间的差异,len() 函数,前面并没有对象去调用它,
调用 其实也是一个编程概念,就是那个 . 符号。
统计过程,你也会注意到 " AaBbCcDd " 算上空格,恰好是 10 个 字符,所以得出空格也是字符,这个基本认知。
后续我们还会学习更多的内置函数,接下来在学习 2 个,这两个有助于提高编程效率。
第一个是 help(),该函数用来查看编程对象的帮助手册,例如下述代码
my_str = " AaBbCcDd "
help(my_str )不过该代码无法在 jupyter 中运行,会得到如下结果
这里可以直接输入 help(),进入手册模式,在进行查询即可。
在文本框输入 str,就可以获取到帮助手册中的相关内容,也就是获取到了字符串对象的相关方法。
第 3 个要学习的内置函数是 dir(),使用该函数可以直接把对象支持的方法全部输出。
my_str = " AaBbCcDd " print(dir(my_str))
字符串格式化
在 Python 中,字符串格式化有三种方式,分别为 % 占位符格式化,format() 方法格式化,以及 f-string,
重点学习的是第二种和第三种方式进行格式化,例如下述代码:
my_str = "小爱同学,今天天气"
answer_str = "今天的天气是: {}".format("晴")
print(answer_str)
第二个字符串中出现了一个大括号 {},然后通过 format() 函数对其进行了填充,
同理,大括号可以出现多个,也可以有名称,例如下述代码:
# 多个大括号,format() 方法中需要多个值进行填充
my_str = "小爱同学,今天天气"
answer_str = "今天上午的天气是: {},下午的天气是:{}".format("晴","多云")
print(answer_str)
# 大括号中有占位符
my_str = "小爱同学,今天天气"
answer_str = "今天上午的天气是: {shangwu},下午的天气是:{xiawu}".format(shangwu="晴",xiawu="多云")
print(answer_str)
在使用占位符的时候注意下,前后要一致,否则会出错的。
上述代码其实用到了函数相关支持,这些随着我们的学习,都将逐步展开,当下最有效的学习方式,就是临摹一遍代码啦。
在使用占位符的时候注意下,前后要一致,否则会出错的。
上述代码其实用到了函数相关支持,这些随着我们的学习,都将逐步展开,当下最有效的学习方式,就是临摹一遍代码啦。
Python lambda 表达式是什么
lambda 表达式也叫做匿名函数,在定义它的时候,没有具体的名称,一般用来快速定义单行函数,直接看一下基本的使用:
fun = lambda x:x+1
print(fun(1))查看上面的代码就会发现,使用 lambda 表达式定义了一行函数,没有函数名,后面是是函数的功能,对 x 进行 +1 操作。
稍微整理一下语法格式:
lambda [参数列表]:表达式 # 英文语法格式 lambda [arg1[,arg2,arg3....argN]]:expression
语法格式中有一些注意事项:
- lambda 表达式必须使用 lambda 关键字定义;
- lambda 关键字后面,冒号前面是参数列表,参数数量可以从 0 到任意个数。多个参数用逗号分隔,冒号右边是 lambda 表达式的返回值。
本文开始的代码,如果你希望进行改写成一般函数形式,对应如下:
fun = lambda x:x+1
# 改写为函数形式如下:
def fun(x):return x+1当然,如果你决定上述 fun() 也多余,匿名函数就不该出现这些多余的内容,你也可以写成下面这个样子,
不过代码的可读性就变低了。
print((lambda x:x+1)(1))lambda 表达式一般用于无需多次使用的函数,并且该函数使用完毕就释放了所占用的空间。
怎么用
lambda 表达式与 def 定义函数的区别
第一点:一个有函数名,一个没有函数名
第二点:lambda 表达式 : 后面
只能有一个表达式,多个会出现错误,也就是下面的代码是不会出现的。
# 都是错误的
lambda x:x+1 x+2
由于这个原因的存在,很多人也会把 lambda 表达式称为单表达式函数。
第三点:for 语句不能用在 lambda 中
有的地方写成了 if 语句和 print 语句不能应用在 lambda 表达式中,该描述不准确,例如 下述代码就是正确的。
lambda a: 1 if a > 10 else 0
基本结论就是:lambda 表达式只允许包含一个表达式,不能包含复杂语句,该表达式的运算结果就是函数的返回值。
第四点:lambda 表达式不能共享给别的程序调用
第五点:lambda 表达式能作为其它数据类型的值
例如下述代码,用 lambda 表达式是没有问题的。
my_list = [lambda a: a**2, lambda b: b**2]
fun = my_list[0]
print(fun(2))lambda 表达式应用场景
在具体的编码场景中,lambda 表达式常见的应用如下:
1. 将 lambda 表达式赋值给一个变量,然后调用这个变量
上文涉及的写法多是该用法。
fun = lambda a: a**2
print(fun(2))2. 将 lambda 表达赋值给其它函数,从而替换其它函数功能
一般这种情况是为了屏蔽某些功能,例如,可以屏蔽内置 sorted 函数。
sorted = lambda *args:None
x = sorted([3,2,1])
print(x)3. 将 lambda 表达式作为参数传递给其它函数
在某些函数中,函数设置中是可以接受匿名函数的,例如下述排序代码:
my_list = [(1, 2), (3, 1), (4, 0), (11, 4)]
my_list.sort(key=lambda x: x[1])
print(my_list)my_list 变量调用 sort 函数,参数 key 赋值了一个 lambda 表达式,
该式子表示依据列表中每个元素的第二项进行排序。
4. 将 lambda 表达式应用在 filter、map、reduce 高阶函数中
这个地方先挖下一个小坑,你可以自行扩展学习。
5. 将 lambda 表达式应用在函数的返回值里面
这种技巧导致的结论就是函数的返回值也是一个函数,具体测试代码如下:
def fun(n): return lambda x:x+n new_fun = fun(2) print(new_fun) # 输出内容:<function fun.<locals>.<lambda> at 0x00000000028A42F0>
上述代码中,lambda 表达式实际是定义在某个函数内部的函数,称之为嵌套函数,或者内部函数。
对应的将包含嵌套函数的函数称之为外部函数。
内部函数能够访问外部函数的局部变量,这个特性是闭包(Closure)编程的基础
闭包(Closure)是指在一个函数内部定义另一个函数,并且这个内部函数可以访问外部函数的局部变量,即使外部函数执行完毕后,这些局部变量依然会被“记住”并保存下来,供内部函数使用。这种特性在编程中非常有用。
闭包的定义
闭包是一个函数对象,这个对象能够记住定义它的环境中的变量值(即外部函数的局部变量),即使在环境已经不存在的情况下,仍然能够访问这些变量。
闭包的三要素
要形成闭包,需要以下三要素:
- 外部函数:外层函数中定义了一个变量或参数。
- 内部函数:在外层函数中定义的函数(称为嵌套函数)。
- 返回内部函数:外部函数返回内部函数,使内部函数可以在外部调用时继续访问外部函数的变量。
闭包的作用
闭包主要用于在一个函数的内部定义并返回一个内部函数,使这个内部函数“记住”并可以访问外部函数的变量。这样可以用于创建带有持久状态的函数,常用于工厂函数、定制化函数、数据封装等场景。
闭包的示例
以下代码演示了闭包的概念:
def make_multiplier(n): def multiplier(x): return x * n return multiplier
在这里,make_multiplier 是外部函数,multiplier 是内部函数。即使 make_multiplier 执行完并退出,它的参数 n 仍然会被 multiplier 函数“记住”。
times_3 = make_multiplier(3) # 创建一个闭包,n = 3 times_5 = make_multiplier(5) # 创建另一个闭包,n = 5 print(times_3(10)) # 输出 30,因为 10 * 3 = 30 print(times_5(10)) # 输出 50,因为 10 * 5 = 50
在这段代码中:
times_3是一个闭包,记住了n = 3的状态。times_5是另一个闭包,记住了n = 5的状态。
闭包的关键点
- 持久化状态:闭包会“记住”外部函数的变量,因此在多次调用时可以保持一致的行为。
- 数据封装:闭包将数据(外部变量)封装在函数内部,使得在调用时无需外部提供这些变量值。
闭包的实际应用
闭包在许多场景中非常有用,例如创建特定的数学运算函数、定制化回调函数、创建工厂函数等。
扩展知识
lambda 表达式虽然有优点,但不应过度使用 lambda,最新的官方 Python 风格指南 PEP8 建议永远不要编写下述代码:
normalize_case = lambda s: s.casefold()
因此你想创建一个函数并存储到变量中, 请使用 def 来定义。
不必要的封装
我们实现一个列表排序,按照绝对值大小进行。
my_list = [-1,2,0,-3,1,1,2,5]
sorted_list = sorted(my_list, key=lambda n: abs(n))
print(sorted_list)
上述貌似用到了 lambda 表达式,但是确忘记了,在 Python 中所有的函数都可以当做参数传递。
my_list = [-1,2,0,-3,1,1,2,5]
sorted_list = sorted(my_list, key=abs)
print(sorted_list)
也就是当我们有一个满足要求的函数的时候,没有必要在额外的去使用 lambda 表达式了。
扩展知识
lambda 表达式虽然有优点,但不应过度使用 lambda,最新的官方 Python 风格指南 PEP8 建议永远不要编写下述代码:
normalize_case = lambda s: s.casefold()
因此你想创建一个函数并存储到变量中, 请使用 def 来定义。
不必要的封装
我们实现一个列表排序,按照绝对值大小进行。
my_list = [-1,2,0,-3,1,1,2,5]
sorted_list = sorted(my_list, key=lambda n: abs(n))
print(sorted_list)
上述貌似用到了 lambda 表达式,但是确忘记了,在 Python 中所有的函数都可以当做参数传递。
my_list = [-1,2,0,-3,1,1,2,5]
sorted_list = sorted(my_list, key=abs)
print(sorted_list)
也就是当我们有一个满足要求的函数的时候,没有必要在额外的去使用 lambda 表达式了。
参考教程:
列表推导式-进阶语法-CSDNPython入门技能树