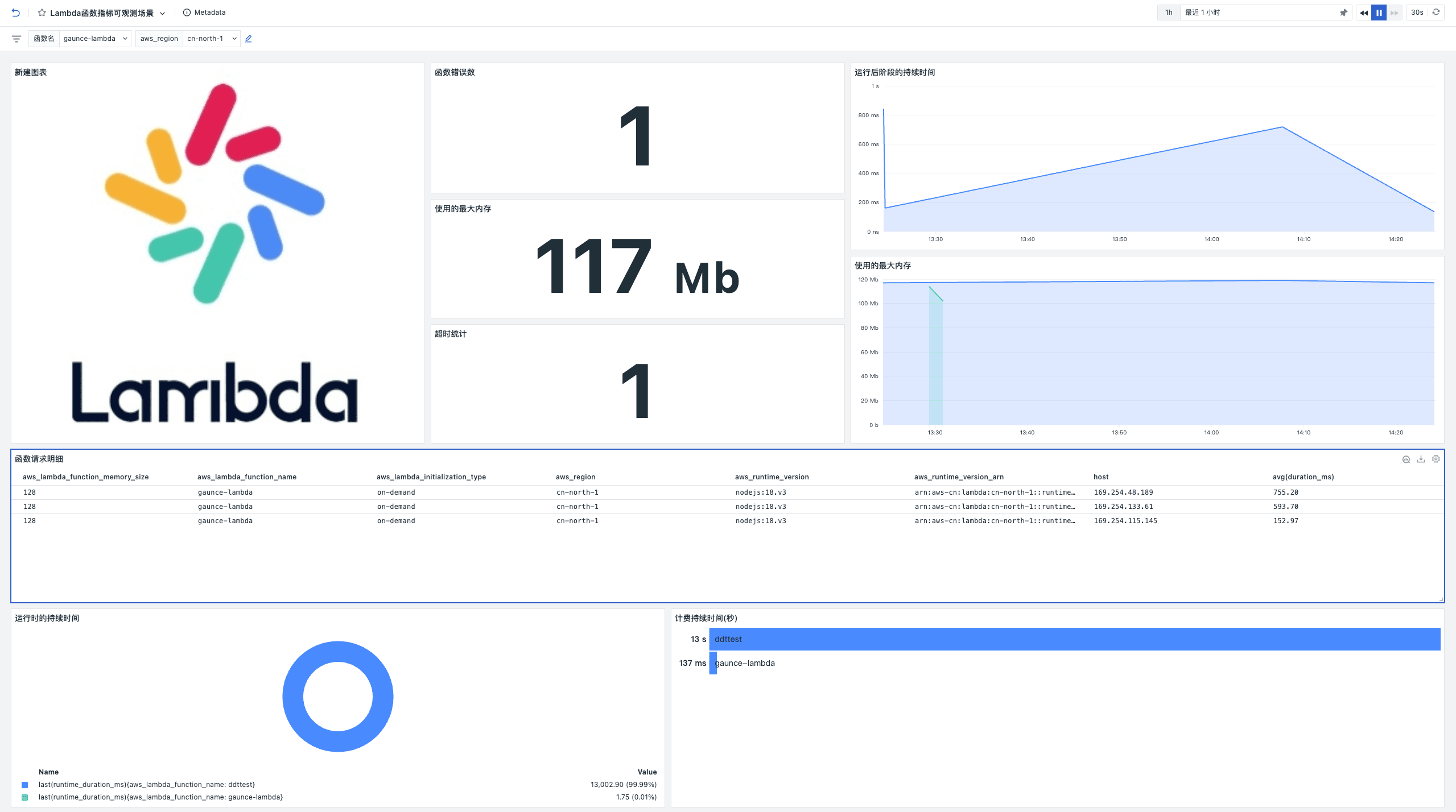
BinarySearchTree模拟实现
- 1 什么是二叉搜索树
- 2 二叉搜索树的插入
- 2.1 插入的流程
- 2.2 插入的代码
- 3 二叉搜索树的查找
- 3.1 查找的流程
- 3.2 查找的代码
- 4 二叉搜索树的中序遍历
- 4.1 中序遍历流程
- 4.2 中序遍历代码
- 5 二叉搜索树的删除
- 5.1 没有孩子 | 有右孩子
- 5.2 没有右孩子
- 5.3 有两个孩子
- 5.4 删除的全部代码
- 6 拷贝构造
- 6.1 函数头
- 6.2 copy(Node* root)
- 7 赋值运算符重载
- 8 全部代码
1 什么是二叉搜索树
- 若它的左子树不空,则 左子树上所有结点的值均 小于它 根结点的值。
- 若它的右子树不空,则 右子树上所有结点的值均 大于它 根结点的值。
- 它的左、右树又分为⼆叉搜索树
例如下面这一颗树:

左孩子严格小于根,右孩子严格大于根
不会有相同的值
1.二叉搜索树有什么特别的优势?
当使用 中序遍历的时候,遍历的结果是 从小到大排好序的。
速度很快,因为是特殊的树状结构,和二分查找类似,因此时间复杂度为 O(log N)
2 二叉搜索树的插入
2.1 插入的流程
2.上面这棵树的插入过程是怎样的?

- 当插入的值小于当前值,就往左边遍历
- 当插入的值大于当前值,就往右边遍历
- 直到找到一个合适的位置,将值插入进去
2.2 插入的代码
bool Insert(const T& key)
{if (_root == nullptr){_root = new Node(key);return true;}//不为空,要找到能插入的位置Node* parent = nullptr;Node* cur = _root;while (cur){//当前节点比key小,key往右边走if (cur->_data < key){parent = cur;cur = cur->_right;}else if (cur->_data > key){parent = cur;cur = cur->_left;}else{//走到这里说明有一个相同的的数了return false;}}//走到这里,说明找到合适的插入位置了//要判断插入到当前cur的左边还是右边cur = new Node(key);if (parent->_data < key){parent->_right = cur;}else{parent->_left = cur;}return true;
}
3.为什么要添加一个parent结点?
因为如果不添加parent结点,不知道插入的值是父节点的左孩子还是右孩子
3 二叉搜索树的查找
3.1 查找的流程
根据二叉搜索树的性质, 如果要查找4,查找的流程如下:

从这个查找的路线来看,也能发现, 查找的方式类似二分查找,比线性查找快很多。
3.2 查找的代码
bool Find(const T& key) const
{if (_root == nullptr)return false;Node* cur = _root;while (cur){//key大,往右边找if (cur->_data < key){cur = cur->_right;}else if (cur->_data > key){cur = cur->_left;}else{return true;}}return false;
}
4 二叉搜索树的中序遍历
这里只讲中序遍历,是因为,只有中序遍历是有意义的。中序遍历的结果是从小到大排好序的。
4.1 中序遍历流程
- 树的遍历是有深度优先和宽度优先。
- 这里采用宽度优先,也就是递归的方式。
- 中序遍历顺序:左子树,根,右子树。
4.2 中序遍历代码
void _Inorder(Node* root){if (root == nullptr)return;_Inorder(root->_left);cout << root->_data << " ";_Inorder(root->_right);}
4.中序遍历需要传一个参数为Node* root,但是在类中这个成员变量一般是private,如果直接访问会报错,需要怎么解决这个问题?
第一种方法:直接将成员变量的访问权限改为public
第二种方法:像下面这样。
将中序遍历的代码在public中做一个封装,这样就不需要传递参数了。

5 二叉搜索树的删除
二叉搜索树的删除较为复杂,分为三种情况:
- 没有孩子
- 有一个孩子:只有左孩子 | 只有右孩子
- 有两个孩子
根据这三种情况,写代码的时候可以分情况讨论:
if (没有左孩子) //没有左孩子可以表示:一个孩子都没有 | 没有左孩子(有右孩子)
...
else if (没有右孩子) //没有左孩子不满足,但是满足没有右孩子的条件 --> 只有左孩子
...
else //有两个孩子
...
总结:
第一种情况表示:没有孩子或者有右孩子
第二种情况表示:只有左孩子
第三种情况:有两个孩子
5.为什么要这样分情况?
不用特意的去写没有孩子的情况了。第一种情况包含了没有孩子的情况。
接下来根据分的情况进行叙述。
5.1 没有孩子 | 有右孩子
可以表示为删除下图中的4或者10.

删除4:让父节点6指向4的右孩子(虽然4的孩子为空)
删除14:让父节点8指向10的右孩子
这里有两个关键点:
- 需要保留父节点
- 父节点指向要删除结点的右孩子
6.为什么一定是指向删除结点的右孩子?左孩子不行吗?
不行, 因为这里分情况讨论的是没有孩子或者只有右孩子的情况。这种情况里面,要删除的结点没有左孩子。
还需要判断是不是根节点,如果是根结点,删除的逻辑不一样。
如果要删除的结点是下图中的10.

可以发现一个问题:根节点没有父节点。
所以,如果删除的是根节点,直接让根节点指向根节点的右子树就行了。
5.2 没有右孩子
没有右孩子的处理方式和前面没有左孩子的处理方式是一样的。

如果要删除上图中的值为4的结点,方法就是将4的父节点指向4的左孩子。(因为4没有右孩子)
当然这里还有一个细节:需要判断4是父亲的左孩子还是右孩子。这涉及到是父节点的左指向4的左孩子还是父节点的右指向4的左孩子。
如果删除的是根节点,也需要像上面一样特殊处理。
5.3 有两个孩子
假设要删除的节点是8,它有左孩子还有右孩子

有两个孩子的情况,需要在树中找到一个符合当前位置的节点,然后将这两个节点交换。
7.哪种节点符合条件?
要满足既比左子树大,右比右子树小。因此只能找左子树中最大的节点或者右子树中最小的节点。
8.找到符合条件的节点并且交换节点之后,该如何操作?
交换完之后树的结构如下图:

接下来只需要让左子树中最大节点的父节点指向该节点的左孩子即可。
9.为什么只需要指向该节点的左孩子?为什么不指向右孩子?
因为符合条件的节点为左子树中最大的值。根据二叉搜索树的性质,就是从左子树开始一直往右走,最右的那个节点满足条件。因此, 满足条件的节点一定是最右边的,只可能有左孩子(也可能没有孩子),不可能有右孩子。
5.4 删除的全部代码
bool Erase(const T& key){if (_root == nullptr)return false;//分三种情况,没有孩子 | 有一个孩子 | 有两个孩子Node* parent = nullptr;Node* cur = _root;while (cur){//1.找到keyif (cur->_data < key) //往右找{parent = cur;cur = cur->_right;}else if (cur->_data > key){parent = cur;cur = cur->_left;}else{//走到这里说明找到值为key的结点了if (cur->_left == nullptr){//判断是不是根节点if (cur == _root){_root = cur->_right;}else{//判断cur是parent的左孩子还是右孩子if (parent->_left == cur){//让parent接管cur的右节点->因为左为空parent->_left = cur->_right;}else{parent->_right = cur->_right;}}}else if (cur->_right == nullptr){if (cur == _root){_root = cur->_left;}else{//判断cur是parent的左孩子还是右孩子if (parent->_left == cur){//让parent接管cur的左节点->因为右为空parent->_left = cur->_left;}else{parent->_right = cur->_left;}}}else{//左右都不为空//找替换结点,左边的最大的元素或者右边的最小的元素Node* parent = cur;Node* leftMax = cur->_left;while (leftMax->_right){parent = leftMax;leftMax = leftMax->_right;}//走到这里,说明已经走到左边的最大元素了std::swap(leftMax->_data, cur->_data); //交换leftMax和cur//判断是parent的左孩子还是右孩子if (parent->_left == leftMax){parent->_left = leftMax->_left; //这是因为leftMax是左边的最大元素,不可能有右孩子了}else{parent->_right = leftMax->_left;}cur = leftMax;}delete cur;return true;}}return false;}
6 拷贝构造
6.1 函数头
BSTree(const BSTree<T>& t){}
拷贝构造就是用新的类对象构造成传入的类对象的样子。
二叉搜索树是树形结构,因此可以使用递归的形式进行拷贝构造。
创建一个copy()函数,直接调用即可。
6.2 copy(Node* root)
Node* copy(Node* root){if (root == nullptr)return nullptr;Node* copyroot = new Node(root->_data);copyroot->_left = copy(root->_left);copyroot->_right = copy(root->_right);return copyroot;}
7 赋值运算符重载
BSTree<T>& operator=(BSTree<T> t){std::swap(_root, t._root);return *this;}
这里有一个比较巧妙的地方:
10. 为什么不传引用?
因为如果不传引用而传值,就会 产生临时对象,临时对象是拷贝产生的,而这个拷贝产生的临时对象出了作用域就会销毁。因此只需要 将自己类中根节点和拷贝产生的根节点进行交换,就达成了赋值的目的。出了作用域临时对象还会自动销毁。
这里的具体原理,我在这篇文章:list的模拟实现中画图讲解过。点击链接即可跳转。
8 全部代码
BinarySearchTree.h
#pragma once
#include<iostream>using std::cout;
using std::cin;
using std::istream;
using std::ostream;
using std::endl;namespace zyy
{template<class T>struct BSTreeNode{BSTreeNode<T>* _left;BSTreeNode<T>* _right;T _data;//构造函数BSTreeNode(const T& x):_left(nullptr),_right(nullptr),_data(x){}};template <class T>class BSTree{public:typedef BSTreeNode<T> Node;//默认构造BSTree():_root(nullptr){}//拷贝构造BSTree(const BSTree<T>& t){_root = copy(t._root);}BSTree<T>& operator=(BSTree<T> t){std::swap(_root, t._root);return *this;}~BSTree(){Destory(_root);}bool Insert(const T& key){if (_root == nullptr){_root = new Node(key);return true;}//不为空,要找到能插入的位置Node* parent = nullptr;Node* cur = _root;while (cur){//当前节点比key小,key往右边走if (cur->_data < key){parent = cur;cur = cur->_right;}else if (cur->_data > key){parent = cur;cur = cur->_left;}else{//走到这里说明有一个相同的的数了return false;}}//走到这里,说明找到合适的插入位置了//要判断插入到当前cur的左边还是右边cur = new Node(key);if (parent->_data < key){parent->_right = cur;}else{parent->_left = cur;}return true;}bool Find(const T& key) const{if (_root == nullptr)return false;Node* cur = _root;while (cur){//key大,往右边找if (cur->_data < key){cur = cur->_right;}else if (cur->_data > key){cur = cur->_left;}else{return true;}}return false;}bool Erase(const T& key){if (_root == nullptr)return false;//分三种情况,没有孩子 | 有一个孩子 | 有两个孩子Node* parent = nullptr;Node* cur = _root;while (cur){//1.找到keyif (cur->_data < key) //往右找{parent = cur;cur = cur->_right;}else if (cur->_data > key){parent = cur;cur = cur->_left;}else{//走到这里说明找到值为key的结点了if (cur->_left == nullptr){//判断是不是根节点if (cur == _root){_root = cur->_right;}else{//判断cur是parent的左孩子还是右孩子if (parent->_left == cur){//让parent接管cur的右节点->因为左为空parent->_left = cur->_right;}else{parent->_right = cur->_right;}}}else if (cur->_right == nullptr){if (cur == _root){_root = cur->_left;}else{//判断cur是parent的左孩子还是右孩子if (parent->_left == cur){//让parent接管cur的左节点->因为右为空parent->_left = cur->_left;}else{parent->_right = cur->_left;}}}else{//左右都不为空//找替换结点,左边的最大的元素或者右边的最小的元素Node* parent = cur;Node* leftMax = cur->_left;while (leftMax->_right){parent = leftMax;leftMax = leftMax->_right;}//走到这里,说明已经走到左边的最大元素了std::swap(leftMax->_data, cur->_data); //交换leftMax和cur//判断是parent的左孩子还是右孩子if (parent->_left == leftMax){parent->_left = leftMax->_left; //这是因为leftMax是左边的最大元素,不可能有右孩子了}else{parent->_right = leftMax->_left;}cur = leftMax;}delete cur;return true;}}return false;}void Inorder(){return _Inorder(_root);}private://中序遍历void _Inorder(Node* root){if (root == nullptr)return;_Inorder(root->_left);cout << root->_data << " ";_Inorder(root->_right);}Node* copy(Node* root){if (root == nullptr)return nullptr;Node* copyroot = new Node(root->_data);copyroot->_left = copy(root->_left);copyroot->_right = copy(root->_right);return copyroot;}void Destory(Node*& root){if (root == nullptr)return;Destory(root->_left);Destory(root->_right);delete root;root == nullptr;}Node* _root;};
};
TestBSTree.cpp
#include "BinarySearchTree.h"using namespace zyy;void test1()
{BSTree<int> bst;bst.Insert(1);bst.Insert(3);bst.Insert(4);bst.Insert(6);bst.Insert(0);bst.Insert(2);if (bst.Find(3)){cout << "找到了" << endl;}else{cout << "没找到" << endl;}bst.Inorder();
}void test2()
{BSTree<int> bst;bst.Insert(8);bst.Insert(1);bst.Insert(3);bst.Insert(6);bst.Insert(4);bst.Insert(7);bst.Insert(10);bst.Insert(14);bst.Insert(13);cout << "before: ";bst.Inorder();//1.测试没有孩子//bst.Erase(7);//2.测试有一个孩子//bst.Erase(10);//3.测试有两个孩子bst.Erase(6);cout << "after: ";bst.Inorder();
}
int main()
{test2();return 0;
}