编者按:想要部署大语言模型(LLMs),却不知该如何估算所需的 GPU 内存?在项目预算有限的情况下,是否曾因为 GPU 内存估算不准而导致资源浪费或性能不足?这些问题不仅影响项目进度,还可能直接导致成本超支或服务质量下降。
本文作者凭借丰富的 LLM 部署经验,深入剖析了 GPU 内存需求的计算方法。从模型参数到 KV 缓存,从激活值到系统开销,文章全面而详细地讲解了各个组成部分的内存占用。文章还讨论了内存管理面临的挑战,如内存碎片、过度分配和高级解码算法带来的额外需求。为解决这些问题,作者介绍了 PagedAttention 和 vLLM 等优化技术,当 GPU 内存不足时,还可以采用 Swapping 和 Recomputation 等优化策略。
作者 | Muhammad Saad Uddin
编译 | 岳扬
将 LLMs 投入生产环境使用,会遇到诸多挑战,尤其是想要为 LLMs 高效提供所需的计算资源时。有过此类经验的人可能深有体会,GPU 内存是支持 LLMs 运行的一项关键资源。由于这些模型体积巨大,且推理过程具有动态性质,因此对 GPU 内存使用的规划和优化提出了更高的要求。

Image by Author via DallE
出于以下几个原因,准确估算 GPU 内存的需求至关重要:
- 成本效益:GPU资源成本高昂。高估内存需求会导致不必要的硬件支出,而低估内存需求则会导致系统故障或性能下降。
- 性能优化:合理的内存管理能够保障模型的高效运行,从而快速响应用户需求,并提高并发处理能力。
- 可扩展性:随着业务需求的增长,准确掌握内存需求对于在不影响性能和不产生过高成本的情况下扩展服务至关重要。
然而,计算 LLMs 服务所需的 GPU 内存并非一件简单的事。模型的大小(model size)、序列长度(sequence lengths)、批处理数量(batch sizes)以及解码算法(decoding algorithms)等多种因素,都会以复杂的方式影响内存使用。而且,传统的内存分配方法常因内存碎片和键值(KV)缓存等动态内存组件的低效管理而造成大量浪费。
在本文中,我将尽可能详细地解释如何计算 LLMs 服务所需的 GPU 内存。我将分析影响内存使用的各部分,并根据模型参数和工作负载特征(workload characteristics),逐步介绍如何估算内存占用大小。同时,我还会探讨 Paged Attention 和 vLLM 等先进的优化技术,这些技术能显著降低内存消耗并提升处理能力。通过阅读本文,你将能够全面了解如何规划和优化 LLMs 的 GPU 内存使用,从而在实际应用中实现高效且低成本的 LLMs 部署。
01 了解 LLM 推理过程中,主要消耗 GPU 内存的几部分
要想掌握 GPU 内存的计算方法,最关键的是了解各部分如何占用 GPU 内存的。了解内存的使用去向有助于我们更好地规划与优化资源。在 LLMs 推理过程中,主要消耗 GPU 内存的几部分包括权重(模型参数)、键值缓存内存(Key-Value Cache Memory)、激活值(Activations)与临时缓冲区(Temporary Buffers),以及系统开销(Overheads)(如果你对并行处理或分布式计算有所研究,可能对这个概念已有一定的认识)。
1.1 模型参数(权重)
模型参数是神经网络在训练过程中学到的数值(权重(weights)和偏置(biases))。这些参数定义了模型如何处理输入数据生成输出。
模型大小对 GPU 内存的影响
- 直接关系:模型越大(参数越多),存储这些权重所需的 GPU 内存就越多。
- 内存计算:在使用半精度(FP16)格式时,每个参数通常需要 2 个字节,这在推理过程中很常见,可以节省内存而不会明显损失精度。
让我们看看这些模型:
- 拥有 34.5 亿参数的小型 LLM:
- 所需内存:34.5 亿 × 2 字节 = 69 MB。单 GPU 即可轻松支持。
- 现在如果使用 llama2-13b 模型:
- 拥有 130 亿参数,所需内存将是:130 亿 × 2 字节 = 26 GB。这种情况下,需要一个拥有 40 GB内存的 A100 GPU。
- 如果我们看看据说拥有 1750 亿参数的 GPT-3 模型:
- 所需内存:1750 亿 × 2 字节 = 350 GB,我们至少需要 9 个 GPU 来仅存放模型权重。
请记住,对于 GPT-3 及其之后的模型,使用模型并行化(model parallelism)将模型参数分布到多个 GPU 上是十分必要的。
1.2 键值(KV)缓存内存
KV缓存存储生成序列中每个 token 所需的中间表示。简单来说,当模型每次生成一个 token 时,它需要记住之前的 tokens 以保持上下文。KV缓存存储了目前为止生成的每个 token 的键(key)和值(value)向量,使模型能够高效地处理过去的 tokens ,而无需重新计算。
工作原理:
- Key 和 Values:在注意力机制中,模型为每个 token 计算一个键向量和一个值向量。
- Storage:这些向量存储在 KV 缓存中,并在后续步骤中用于生成新 tokens 。
序列长度(Sequence Length)和并发请求(Concurrent Requests)的影响:
- Longer Sequences:tokens 越多,KV缓存中的条目就越多,内存使用量增加。
- Multiple Users:同时服务多个请求会成倍增加所需的KV缓存内存。
计算每个 token 的 KV 缓存大小
让我们来分析一下如何得出每个 token 的 KV 缓存大小:
- 每个 token 的 KV 缓存组件:
键向量(每层一个键向量)和值向量(每层一个值向量)
- 每个 token 的向量总数:
模型层数(L)× 隐藏层大小(H):模型的深度 × 每个向量的维度。
再次以 llama-13b 模型为例,假设模型具有以下特征:
- 模型层数(L):40层
- 隐藏层大小(H):5120维度(这种大小的模型中的常见维度)
- 计算每个 token 占用的内存:
i. 键向量:
- 总数量:L层 × H维度 = 40 × 5120 = 204,800 个
- 内存大小:204,800 个 × 2字节(FP16)= 409,600字节(或400 KB)
ii. 值向量:
- 与键向量相同:也是400 KB
iii. 每个 token 的总KV缓存:
- 键向量 + 值向量:400 KB + 400 KB = 800 KB
现在考虑输出内容为2000个 tokens 的情况:
800 KB/token × 2000 tokens = 每个输出序列 1.6 GB
假如有 10 个并发请求(模型同时为 10 个用户服务):1.6 GB/输出序列 × 10 输出序列 = 16 GB 的 KV 缓存内存
KV缓存随着序列长度和并发请求数量的增加而线性增长。我从一篇论文[1]中了解到,KV缓存可以消耗多达 30% 甚至更多的GPU内存。
1.3 激活值和临时缓冲区
激活值(Activations)是指推理过程中神经网络层的输出,而临时缓冲区(temporary buffers)用于中间计算。激活值和缓冲区通常消耗的内存比模型权重和 KV 缓存要少。
它们可能使用大约 5-10% 的总 GPU 内存。
尽管它们的容量较小,但激活值对于模型计算每一层的输出是十分必要的。它们在前向传递过程(forward pass)中被创建和丢弃,但仍需要足够的内存分配。
1.4 内存开销
额外的内存使用开销来自于内存分配和使用的低效率。下面是对其的简要介绍:
内存碎片:
- Internal Fragmentation:当分配的内存块没有被完全利用时产生。
- External Fragmentation:随着时间的推移,空闲内存被分割成小块,使得在需要时难以分配较大的连续内存块。
计算过程中产生的中间步骤:
- 临时数据:像矩阵乘法这样的操作可能会创建消耗内存的临时张量。
低效内存管理的影响:
- 性能降低:浪费的内存可能会限制系统可以处理的并发请求数量。
- 吞吐量降低:低效的内存管理可能会导致延迟并降低向用户提供服务响应的整体速度。
示例:如果内存碎片在 40 GB GPU 上浪费了 20 %的内存,那么就有 8 GB 的内存本可以用来处理更多请求,但是现在被浪费了。
02 计算 GPU 内存需求
既然我们已经对关键内容有了足够的了解,那么就不再拖延,直接计算完整的 GPU 内存需求!
逐步计算:
要计算任何模型的内存需求,几乎以下内容都需要:了解模型权重、KV缓存、激活值和临时缓冲区以及系统内存开销。以 llama-2 13B 模型为例,公式为:
所需内存总量:模型权重 + KV缓存 + 激活值和系统内存开销
对于 13 B 模型来说:
模型权重 = 参数数量 × 每个参数的字节数
总 KV 缓存内存 = 每个 token 的 KV 缓存内存 × 输出序列长度 × 输出序列数量
激活值和系统内存开销 = GPU总内存的 5–10 %
激活值和系统内存开销通常消耗模型参数和 KV 缓存使用的 GPU 总内存的大约 5–10 %。你可以额外分配目前计算出的总内存的 10 %作为这部分的内存消耗预留量。
模型权重 = 130 亿 × 2 字节 = 26 GB
总 KV 缓存内存 = 800 KB × 8192* tokens × 10* 并发请求 = 66 GB
激活值和系统内存开销 = 0.1 × (26 GB + 66GB) = 9.2 GB
*假设模型的输出系列长度为 8192,有 10 个并行请求。
所需内存总量:26 GB + 66 GB + 9.2 GB = 101.2 GB
所以,运行 llama-2 7B 模型至少需要 3 个 A100 40GB GPU。
如果我想要托管一个 GPT-3 模型(我知道这很疯狂;D),计算方法与此类似,但这次我会假设每次只处理一个请求,并使用 OPT-175B[2] 模型的大小( 96 层和每层 12288 维度)作为参考。
模型权重 = 1750 亿 × 2 字节 = 350 GB
总 KV 缓存内存 = 4.5 MB × 8192 token × 1 并发请求 = 36 GB
激活值和系统内存开销 = 0.1 × (350 GB + 36GB) = 38.6 GB
所需总内存:350 GB + 36 GB + 38.6 GB = 424.6 GB 几乎需要 11 个 A100 😐。
如果假设 GPT-4 是一个拥有 1 万亿参数的模型,那么将需要 2.3 TB的内存。
根据有关模型大小和参数的公开信息,计算出的内存计算表如下所示:
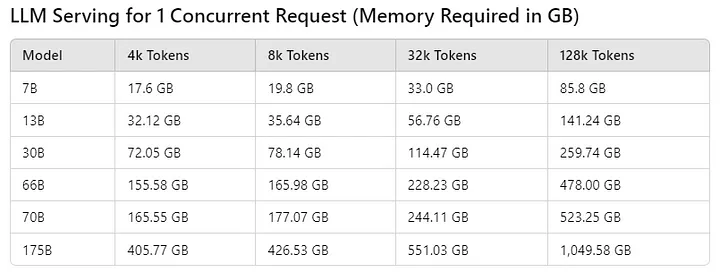
Table calculated by Author
同样,如果我将模型部署给许多用户(比如 10 个)同时使用,计算出的内存计算表如下所示:
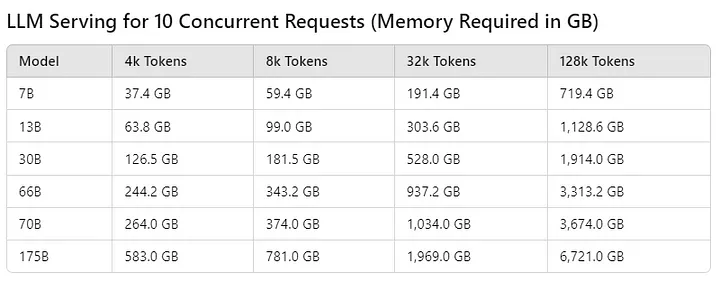
Table calculated by Author
在处理多个请求时,内存消耗明显增加。主要是KV缓存大量增加,因为模型权重和系统内存开销保持不变,KV 缓存会随着 tokens 数量和并发请求的增加而大幅增加,矩阵的行数就会越多,从而直接增加内存消耗。
现在想象一下 OpenAI[3] 或 Anthropic[4] 的大模型拥有数百万用户的情况吧!!
03 使用 GPU 内存过程中遇到的挑战及其优化策略
经过上述计算,我意识到如果不探讨在部署大语言模型(LLMs)时遇到的一些挑战,以及目前的研究是如何针对这些问题进行优化的,那么这篇文章将显得不够完整。对于我们许多人来说,了解、掌握高效的 GPU 内存管理技巧至关重要。下面我们简要分析一下。
3.1 挑战一:内存碎片与内存过度分配
在部署过程中,我们通常会静态地为 KV cache 分配内存,为每个请求预留尽可能大的内存空间。这样往往会导致内存过度分配,因为尽管实际的输出序列往往更短,系统会为可能的最长输出序列预留内存空间。
此外,内存碎片会降低有效的可用内存,从而限制系统同时处理的请求数量。内存碎片分为内部(Internal)和外部(External)两种。内部内存碎片是指分配的内存块未被充分利用,留下未使用的内存空间。而外部内存碎片则是指随着时间推移,空闲内存被分割成多个小的且不连续的内存块,这样就难以在需要时分配足够大的连续内存块。
内存使用效率低下意味着 GPU 的计算资源并未得到充分利用。结果,系统受内存限制而非计算能力的限制,浪费了处理器性能。(这也是我们在并行或分布式系统中力求避免的问题)
3.2 挑战二:解码算法
大量的 LLM 应用都倾向于采用先进的解码算法来优化输出质量或是产生多样化的输出结果。尽管这些方法效果显著,但它们也对内存管理提出了新的挑战。以束搜索(Beam Search)为例,该算法会生成多个备选输出序列(即“束(beams)”),并根据评分标准保留得分最高的输出序列。这意味着,每个“束(beams)”都需要专属的 KV 缓存空间,从而增加了内存使用量。同样,Parallel Sampling 通过从模型生成的概率分布(probability distribution)中抽取样本,一次性生成多个独立输出,每个输出同样需要独立的 KV 缓存,这无疑进一步增加了内存消耗。
在动态内存分配这种情况下,解码过程中“束(beams)”或样本的数量可能会发生变化,从而导致不可预测的内存需求。在不产生内存碎片和过度内存开销的情况下,动态地分配和释放内存,成为一项技术挑战。此外,这些解码方法可能会成倍增加内存需求,有时甚至超出了 GPU 的处理能力。如果 GPU 内存不足,系统可能不得不将数据转移到速度较慢的 CPU 内存或硬盘上,这无疑会延长处理时间。
面对这些问题,我们可能会思考:
我们该如何突破这些限制?
3.3 PagedAttention
受操作系统内存管理方式的启发,PagedAttention 技术将虚拟内存的分页原理应用于 KV 缓存的管理。这种方法使得 KV 缓存数据不必占据一大块连续的内存空间,而是可以分散存储于多个不连续的内存页面上。PagedAttention 采用动态内存分配策略,即根据实际需求为 KV 缓存分配内存,无需提前预留出最大输出序列长度所需的内存。这样的注意力机制能够顺畅地从不同内存地址中检索 KV 缓存数据。
PagedAttention 的优势在于,通过使用较小的内存块,有效减少了内存碎片,降低了因内存碎片导致的内存浪费,从而提升了内存的整体使用率。
3.4 vLLM
简单来说,vLLM 是一个基于 PagedAttention 构建的高吞吐量 LLM 服务系统。其核心目的是在推理过程中高效管理 GPU 内存,尤其是 KV 缓存。从理论上看,vLLM 几乎实现了零内存浪费的解决方案。通过内存的动态分配和非连续存储,它几乎消除了内存浪费。理论上,它还支持在单个请求内部和跨请求之间共享 KV 缓存数据,这对于高级解码方法尤其有用。在此基础上,vLLM 能够处理更大的批处理数量和更多的并发请求,从而提升整体性能。
即使进行了优化,有时也可能出现 GPU 内存不足的情况。vLLM 可通过 swapping 和 recomputation 来应对这个问题。让我们进一步了解这一机制。
3.5 Swapping KV Cache to CPU Memory
- Swapping:当 GPU 内存满载时,系统会将 KV 缓存数据从 GPU 内存临时转移到 CPU 内存中。
- 优点:
- 内存释放(Memory Relief):通过将数据移出 GPU 内存,可以为新的请求腾出空间,确保 GPU 内存不会因为资源不足而阻碍新任务的执行。
- 代价:
- 延迟增加:由于 CPU 内存的访问速度通常低于 GPU 内存,因此从 CPU 内存读取数据会比从 GPU 内存读取数据更加耗时。
- 数据传输开销:在 GPU 内存和 CPU 内存之间转移数据需要消耗带宽和处理器时间。
3.6 Recomputation
不存储所有 KV 缓存数据,而是在需要时按需重新计算。
- 优点:
- 减少内存使用:在内存中需要存储的数据量减少。
- 代价:
- 增加计算量:重新计算数据需要额外的处理能力。
- 延迟影响:由于增加的额外计算量,可能会导致响应时间变长。
Swapping 和 Recomputation 两种方法比较表

Table by Author
单独使用 Swapping 或 Recomputation 可能各有优缺点,但是将两者结合起来使用,可以相互弥补对方的不足,从而在节省内存、减少计算量、降低延迟等方面达到一个较为理想的平衡状态。
Thanks for reading!
Hope you have enjoyed and learned new things from this blog!
About the authors
Muhammad Saad Uddin
Data Science is poetry of math where data is your love and its on you how you write your verses to show world your poetic expressions with utmost clarity®.
END
本期互动内容 🍻
❓你是否遇到过因为模型过大而导致的 GPU 内存不足问题?
🔗文中链接🔗
[1]https://arxiv.org/pdf/2309.06180
[2]https://medium.com/@plienhar/llm-inference-series-4-kv-caching-a-deeper-look-4ba9a77746c8
[3]https://openai.com/
[4]https://www.anthropic.com/
原文链接:
https://ai.gopubby.com/stop-guessing-heres-how-much-gpu-memory-you-really-need-for-llms-8e9b02bcdb62