隐马尔可夫模型在股市预测中的应用
原创 QuantML QuantML 2024年09月29日 21:44
Content
摘要
股市因其复杂多变的特性,预测未来股价一直是一个挑战。然而,运用高级方法可以显著提高股价预测的准确性。隐马尔可夫模型(Hidden Markov Models,HMMs)是一种统计模型,能够模拟部分可观测系统的行为,因此非常适合基于历史数据建模股价。本文训练并测试了一个隐马尔可夫模型,目的是基于开盘价和前一天的价格预测股票收盘价。模型的性能通过两个指标进行评估:平均绝对百分比误差(Mean Average Prediction Error,MAPE)和方向预测精度(Directional Prediction Accuracy,DPA),后者是新引入的指标,考虑了分数变化预测正确符号的数量。
引言
股市预测因其内在的波动性和潜在的巨额金融收益,长期以来一直吸引着机构投资者、对冲基金和自营交易公司的注意。这些复杂的市场参与者渴望对股价未来走势和趋势做出准确预测,以获得竞争优势并最大化投资回报。机构投资者,如养老基金和保险公司,代表其客户或受益人管理大量资本。这些投资者的主要目标是在长期内产生一致的回报以履行其财务义务。准确的股市预测使他们能够识别机会并降低风险,从而提高投资组合表现并履行其受托责任。对冲基金则是从认可的投资者那里汇集资本的私人投资合伙企业。对冲基金经理寻求通过采用多样化的投资策略来产生显著的绝对回报,通常与市场条件无关。准确的预测使对冲基金能够识别定价错误的证券,利用市场效率低下,并构建有利可图的交易策略,最终吸引投资者并获得可观的利润。
方法
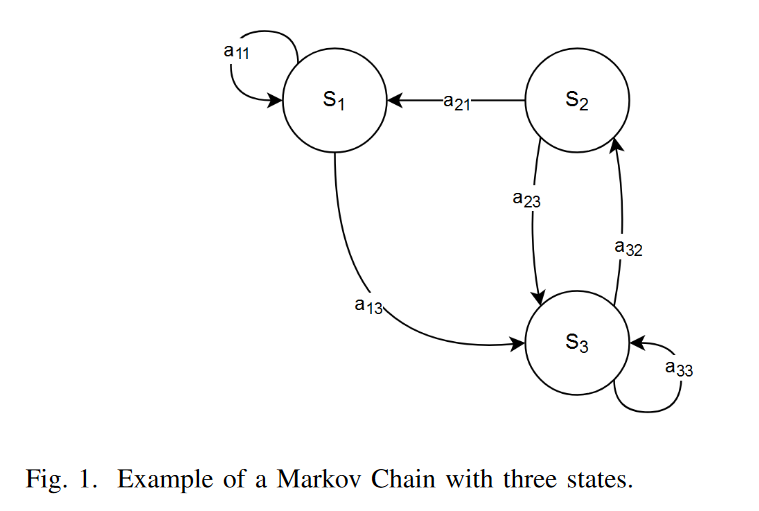
马尔可夫链
马尔可夫链是一种随机模型,代表一系列事件或状态的序列。在我们的分析中,我们将特别关注一阶马尔可夫链,它遵循马尔可夫性质。设 为所有可能状态的集合,为状态时间序列。马尔可夫性质表明,对于任何
为所有可能状态的集合,为状态时间序列。马尔可夫性质表明,对于任何 和状态
和状态 :
:

换句话说,转移到某个状态在时间步的概率仅取决于当前状态在时间步,而不依赖于任何先前的状态。这个性质允许我们基于其当前状态计算马尔可夫链在任何未来时间步的概率分布。形式上,一阶马尔可夫链由状态集合和转移概率矩阵定义,其中代表从状态转移到状态一步的概率。
隐马尔可夫模型
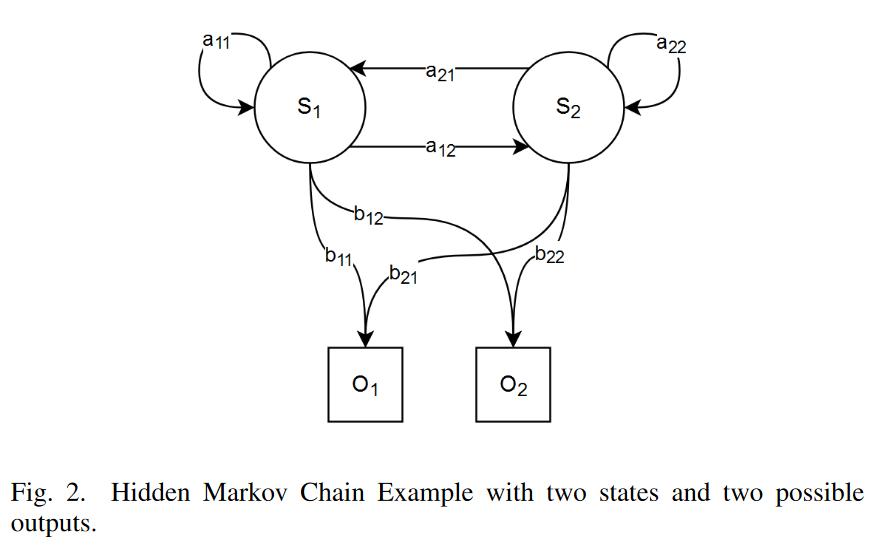
上述模型隐含地假设每个状态对应一个可观测(物理)事件。马尔可夫链已被证明是各种领域中建模序列数据的有价值工具。然而,许多现实世界场景涉及影响观测数据但不可直接观测的潜在状态。这种限制导致了隐马尔可夫模型的发展,它通过引入影响观测数据的隐藏或不可观测状态来扩展基本马尔可夫链模型。HMM的隐藏状态过程是一个马尔可夫链,每个状态生成具有特定概率分布的观测,该分布仅取决于状态本身。设为观测序列,其中是可能观测的集合。假设隐藏状态根据公式2演化。符号由状态发射的概率由发射概率函数描述。在当前和后续部分中,我们指的是发射概率矩阵。
HMM的应用:常见问题和解决方案
使用HMM分析的最常见问题包括评估问题、解码问题和参数估计问题。这些问题及其相应的解决方案已在文献中广泛研究和记录。在以下段落中,我们提供了这些问题及其解决方案的概述。
-
评估问题:HMM中的评估问题涉及计算给定模型的已知观测序列的概率。具体来说,给定具有参数和的HMM,以及观测序列,我们希望计算
 。
。 -
解码问题:解码问题涉及确定给定观测序列和模型的最有可能的隐藏状态序列。给定具有参数和的HMM,以及观测序列,我们希望找到隐藏状态序列,使得最大化。解码问题的解决方案通常使用Viterbi算法解决。该算法通过迭代计算每个时间步的每个状态的最有可能路径,考虑当前观测和先前状态的概率。
-
参数估计问题:HMM中的参数估计问题涉及调整模型参数以最大化观测序列的概率。给定观测序列,我们希望估计最优值的参数和,以最大化。这个问题的解决方案通常使用前向-后向算法解决,也称为Baum-Welch算法。Baum-Welch算法是特定于HMM的期望最大化(EM)算法的实现。它迭代执行三个主要步骤:前向、后向和更新步骤。
技术实现
在本研究中,我们使用了MATLAB中的统计和机器学习工具箱™提供的三个特定函数来训练和测试HMM:hmmtrain、hmmdecode和fitgmdist。模型在公开可用的苹果、IBM和戴尔股票的历史日价格上进行训练和测试。我们数据集中的每个观测值包括三个不同的值,分别代表每日的分数变化、分数最高价和分数最低价。
训练
在初始训练中,我们假设有四个潜在的隐藏状态,每个状态生成的输出由具有四个组件的GMM表示。然后我们重新训练模型,改变值。每个训练的特定参数可以在GitHub存储库中找到。这些GMM的参数使用MATLAB函数fitgmdist估计,该函数使用期望最大化(EM)算法优化模型。GMM的初始参数通过k-means聚类获得。
预测
在训练阶段之后,我们继续测试我们的模型,预测不同时间框架的股票每日收盘价。对于目标期间的每一天,预测过程包括以下步骤:
-
我们考虑可用的最后个观测。这些观测代表前9天。
-
接下来,我们附加当前天的每个可能的输出,创建一个10天的序列。这个序列现在包括9个历史观测和下一天的一个潜在观测。当前天有种可能性。
-
我们计算从我们训练的模型生成每个序列的概率。最后,我们选择具有最高发射概率的观测作为下一天的观测。
结果
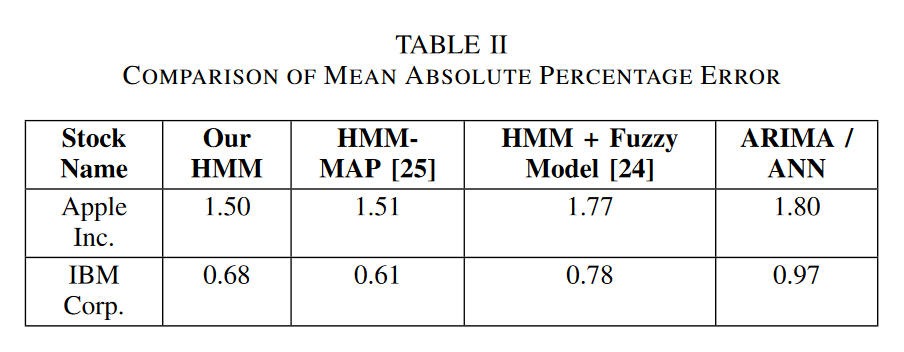
我们使用多个指标来评估模型的性能。平均绝对百分比误差(MAPE)计算实际和预测股票收盘价之间的误差。
在表II中,我们展示了我们在两种不同股票上的结果,并将其与其他论文的结果进行了比较。
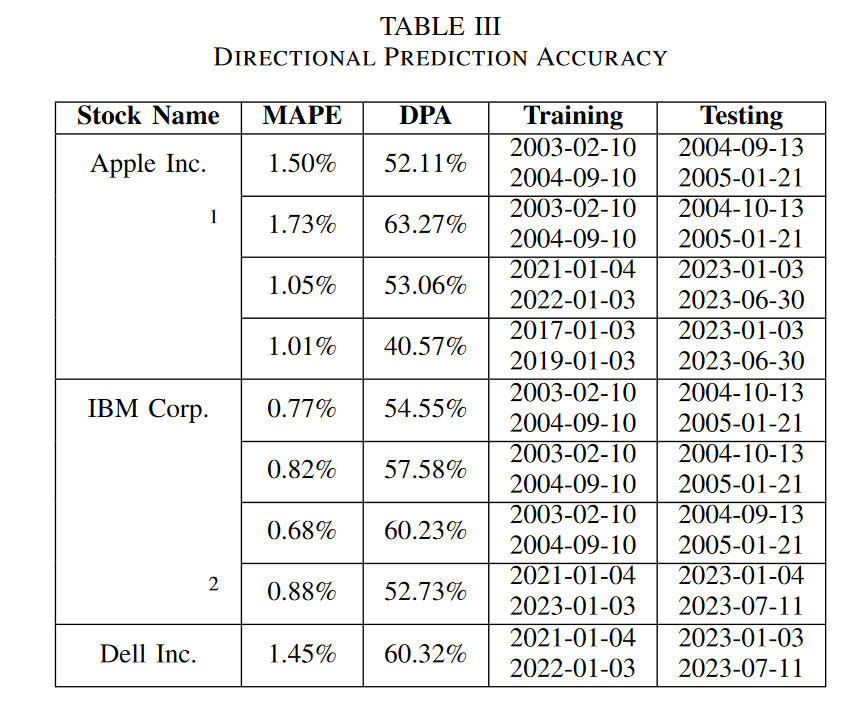
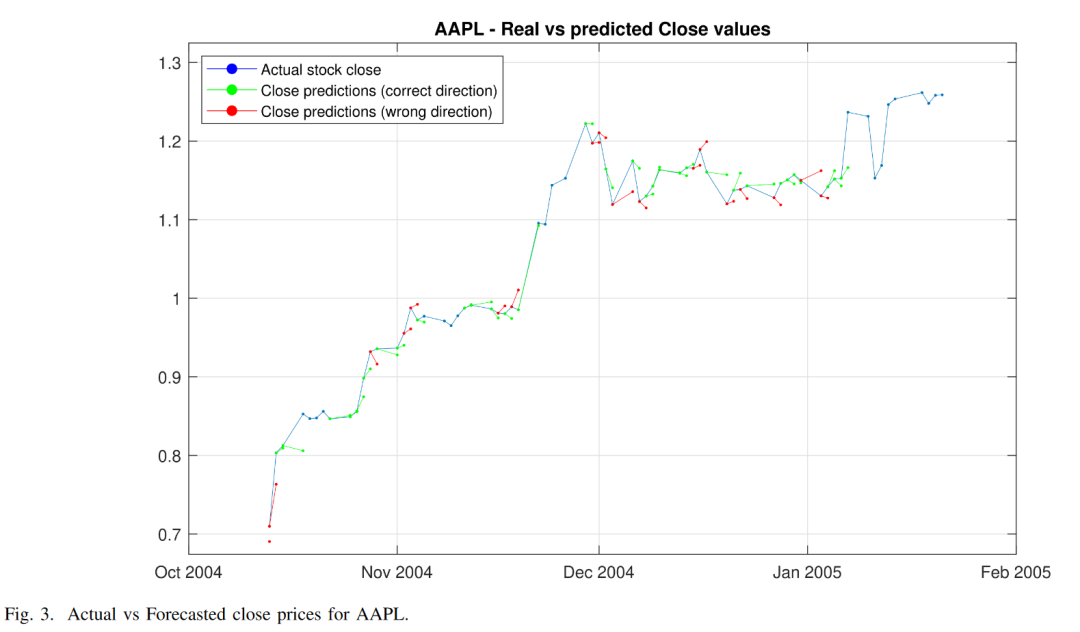
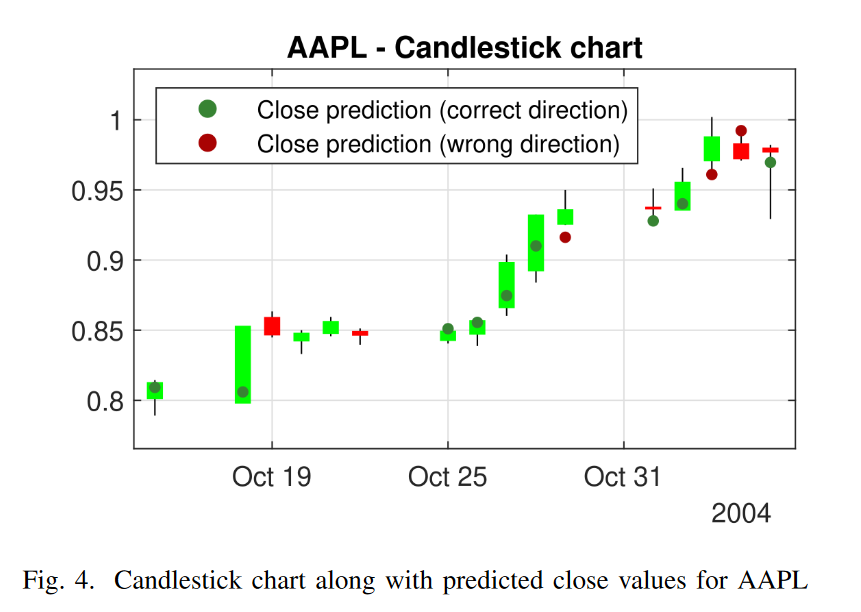
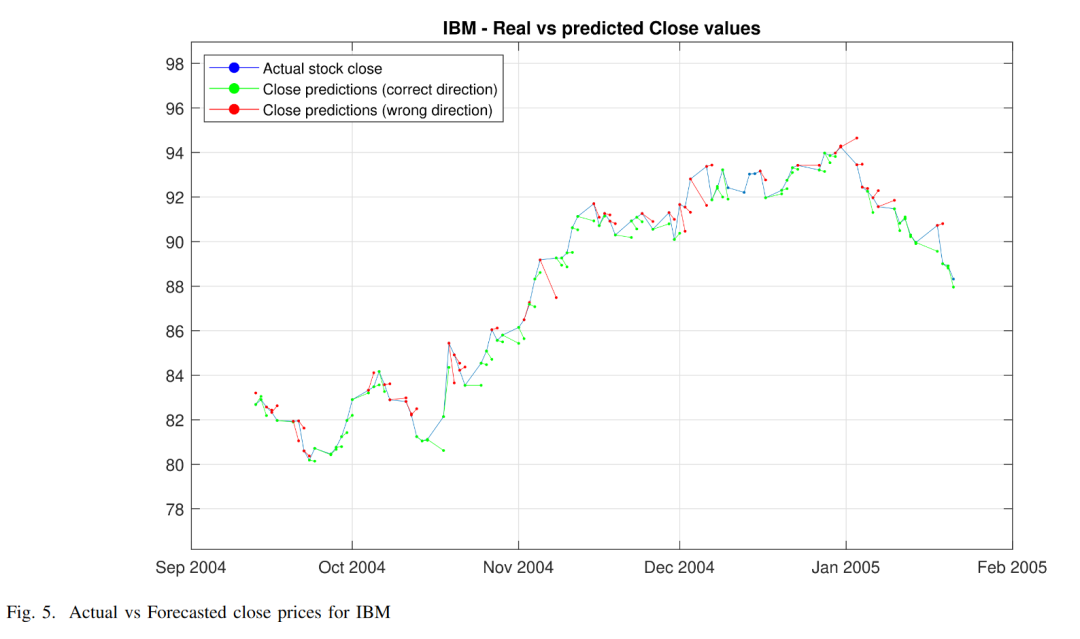
结论和进一步发展
在本研究中,我们全面实施了最初由Gupta等人提出的股市预测隐马尔可夫模型。在他们的基础工作之上,我们旨在评估模型在不同数据集上的性能,并探索其在预测股市走势方面的有效性。通过仔细复制和扩展他们的方法,我们进行了严格的评估,将结果与基准模型进行了比较,以获得有关模型能力和局限性的宝贵见解。
我们的模型在一个一到两年的时间段内进行训练,并用于预测不同的时间段,展示了其灵活性和可重用性。完整的源代码,以及预训练模型及其特性的摘要,可在GitHub上获得。我们在各种股票上对我们的实现进行了严格的测试,并将结果与HMM-MAP、HMM-Fuzzy、ARIMA和ANN模型的结果进行了比较。我们对不同的超参数进行了彻底的探索,测量了它们的影响,以寻找最优值。结果表明,与HMM-Fuzzy、ARIMA和ANN模型相比,当在[25]和[24]中相同的年份进行训练时,平均绝对百分比误差显著降低。此外,为了获得对我们模型效率的额外见解,我们开发了一种名为方向预测精度(DPA)的新评估指标。DPA允许我们评估我们的预测在捕捉股票价格走势方面的准确性,为模型性能评估提供了宝贵的信息。
为了进一步改进,我们建议在每天的最后一个时间窗口之前对发射和传输矩阵进行微调,然后再进行预测。这种方法涉及在历史数据上训练主模型,然后在进行每次预测之前使用更近期的数据更新矩阵。例如,我们可以从2021-01-01到2023-01-01训练主模型,并在2022-06-01到2023-06-01的数据上微调矩阵,然后再对2023-06-02进行预测。这个过程可能会捕捉到更近期的市场趋势,并提高预测的准确性。