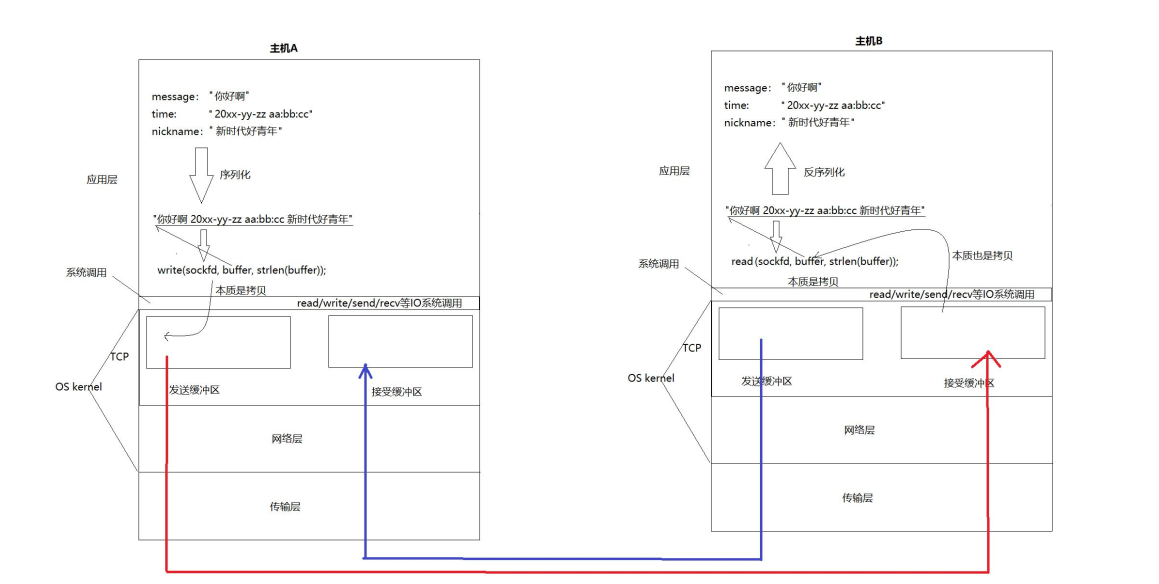
测试要求:
面向对象数据分析案例主程序代码 帮我完成并实现步骤:
1.设计一个类,完成数据的分装
2.设计一个抽象类,定义文件读取的相关功能,并使用子类实现具体功能
3.读取文件,生产数据对象
4.进行数据需求的逻辑计算
5.通过 PyEcharts进行绘图
如下答案:
下面是一个完整的面向对象数据分析案例,包含所有你提到的步骤。我们将以一个简单的销售数据分析为例,假设我们有一个包含销售记录的CSV文件,并且需要读取这个文件,计算总销售额和每个产品的销售数量,最终用PyEcharts绘制柱状图展示每个产品的销售数量。
1. 设计一个类,完成数据的封装
首先,我们设计一个 SaleRecord 类来封装每一条销售记录。
2. 设计一个抽象类,定义文件读取的相关功能,并使用子类实现具体功能
接下来,我们定义一个抽象类 FileReader,并在子类中实现读取CSV文件的功能。
3. 读取文件,生成数据对象
使用上面定义的 CSVFileReader 类来读取文件并生成 SaleRecord 对象列表。
4. 进行数据需求的逻辑计算
计算总销售额和每个产品的销售数量。
5. 通过 PyEcharts 进行绘图
使用 PyEcharts 绘制柱状图展示每个产品的销售数量。
完整代码
import json
from data_define_file import Record class Filereader: def __init__(self, path): self.path = path def read_data(self) -> list[Record]: pass class Text_file_reader(Filereader): def read_data(self) -> list[Record]: record_list = [] try: with open(self.path, "r", encoding="UTF-8") as f: for line in f: line = line.strip() if line: # 确保不是空行 data_list = line.split(",") record = Record(data_list[0], data_list[1], int(data_list[2]), data_list[3]) record_list.append(record) except Exception as e: print(f"Error reading text file: {e}") return record_list class Json_file_reader(Filereader): def read_data(self) -> list[Record]: record_list = [] try: with open(self.path, "r", encoding="UTF-8") as f: for line in f: data_dict = json.loads(line) record = Record(data_dict["date"], data_dict["order_id"], int(data_dict["money"]), data_dict["province"]) record_list.append(record) except Exception as e: print(f"Error reading JSON file: {e}") return record_list if __name__ == '__main__': text_file_reader = Text_file_reader(r"C:\Users\w\Desktop\python\课件\课件\13面向对象\2011年1月销售数据.txt") list1 = text_file_reader.read_data() for l1 in list1: print(l1) json_file_reader = Json_file_reader(r"C:\Users\w\Desktop\python\课件\课件\13面向对象\2011年2月销售数据JSON.txt") list2 = json_file_reader.read_data() for l2 in list2: print(l2)来吧,慧文同学,交钱吧~!
如果JSON文件能正确读取出来,而TXT文件读不出来,可能存在以下几个原因:
- 文件格式问题:
- TXT文件可能不是纯文本格式,或者包含了无法识别的字符编码。
- TXT文件的行格式可能与预期不符,比如使用了不同的换行符(如
\r\n、\n或\r),或者行尾有额外的空格或不可见字符。- 数据格式问题:
- TXT文件中的数据可能没有按照预期的格式(如逗号分隔)进行组织。
- 可能存在缺失值、错误的数据类型(如数字被当作字符串处理),或者数据字段的数量与
Record类构造函数所需的参数数量不匹配。- 代码问题:
- 在处理TXT文件时,代码可能没有正确处理行尾字符,导致数据被错误地解析或分割。
- 可能存在异常处理不当的情况,导致在读取或解析TXT文件时出现的错误没有被捕获或正确报告。
- 文件路径或权限问题:
- 虽然这不太可能是问题的原因(因为JSON文件能读出来),但仍然值得检查TXT文件的路径是否正确,以及程序是否有足够的权限读取该文件。
- 环境问题:
- 不同的文件可能在不同的环境下被处理(比如不同的操作系统、Python版本或依赖库版本),这可能会影响文件的读取和解析。
为了诊断问题,你可以尝试以下步骤:
- 检查TXT文件的内容:打开TXT文件,检查数据的格式和完整性。确保每行数据都是按照预期的格式进行组织的,并且没有额外的字符或错误的换行符。
- 添加调试输出:在读取和解析TXT文件的代码中添加打印语句,输出读取到的每一行数据以及解析后的结果。这可以帮助你定位问题所在的具体位置。
- 处理异常:确保你的代码中有适当的异常处理逻辑,能够捕获并报告读取或解析文件时出现的错误。
- 检查
Record类的定义:确保Record类的构造函数能够正确接收和处理从TXT文件中读取的数据。 - 使用绝对路径:尝试使用文件的绝对路径来排除路径问题。
- 检查Python和库的版本:确保你使用的Python版本和任何相关的库都是最新的,或者至少是与你的代码兼容的版本。