数据库操作
1.查看当前的数据库版本
select version();

2.显示所有数据库
show databases;

3.创建数据库
create [if not exists] database 数据库名
character set 字符编码集
collate 排序规则;
我们这里提前说一下 被方括号括起来的代码 表示可写可不写
示例:

当然我们可以将第二、第三行也省略不写 如果不给予特定的字符编码集和排序规则
示例如下:

4.选择数据库
use 数据库名;
当想对某一数据库的表进行操作时 我们要先选择数据库 进而取操作表
5.查看当前选择了哪个数据库
select database();
示例:

6.删除数据库
drop [if exists] database 数据库名; //这是非常危险的操作
7.查看警告信息
show warnings;
8.退出
quit/exit;
表操作
在进行表操作之前 需要选择某一数据库
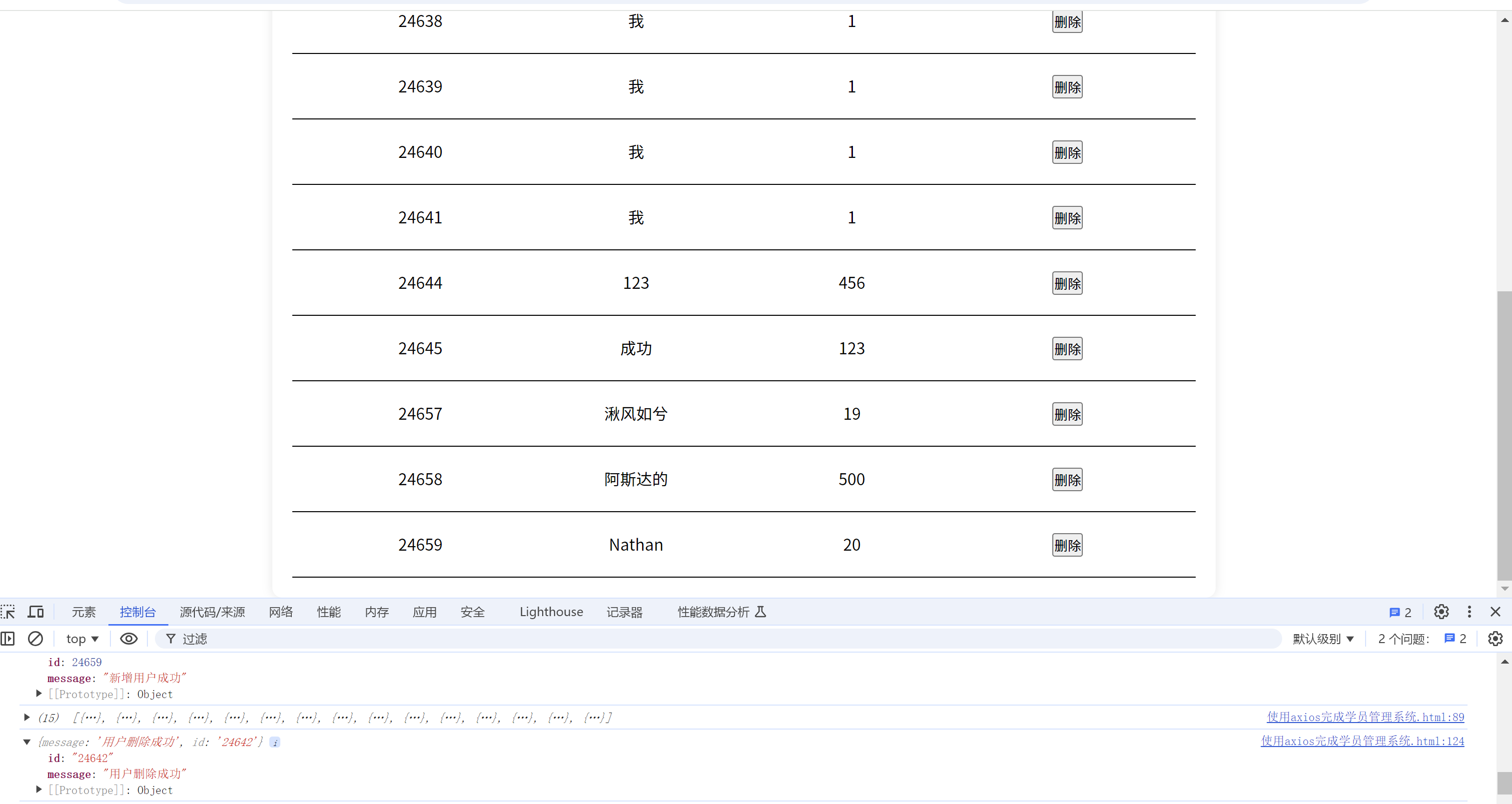
1.查看当前数据库中有哪些表
show tables;
示例如下:

2.创建一张新表
create table 表名(
字段名 数据类型,
字段名 数据类型,
....
);
示例如下:

3.查看表结构
desc 表名;
示例如下:

4.删除表
drop 表名; //非常危险的操作
数据库约束
约束类型
·NOT NULL:指定某列不能存储NULL值
·UNIQUE(唯一约束):保证某列的每行必须有唯一的值(如学生的学号)
·DEFAULT(默认值约束):当没有给列赋值时的默认值
·PRIMARY KEY(主键约束):NOT NULL和UNIQUE的结合 确保某列(或多个列的结合)有唯一标识 有助于更容易更快速地找到表中的一个特定的记录
·FOREIGN KEY(外键约束):保证一个表中的数据匹配另一个表中的值 的参照完整性
·CHECK:保证列中的值符合指定的条件 对于MySQL数据库 对于CHECK子句进行
分析 但忽略CHECK子句
示例:


PRI--主键约束 主键是NOT NULL和UNIQUE的结合
在表中的NULL列中显示的NO则表示NOT NULL
UNI--唯一约束
我们这里将学生id设置为主键 我们可以看到在主键后加了auto_increment
这里解释一下:
对于整数类型的主键 常搭配自增长auto_increment来使用 如果插入的该字段不给值时 使用表中最大的值+1
关于外键 foreign key
外键的主要目的是用来维护两张表或多张表之间的数据一致性和完整性
外键通过引用另一个表(父表)的主键来实现这一目的 从而确保在一个表中存储的外部键值(在当前表中设置 当前表为子表)在另一个表中是有效的(即 当前表的外部键值存在于父表的主键中)
示例:
假设我们有一个简单的在线书店数据库 其中包含两个表:author(作者表)和books(书籍表)
author表存储了作者的信息 而books表存储了书籍的信息 包括每本书是由哪位作者编写的
表结构定义
author表

在这个表中 author_id是主键 用于唯一标识每个作者
Primary key的效果等于not null+unique
books表

在这个books表中 book_id是主键 而author_id是外键
外键约束确保了books表中的author_id(子表)只能包含authors表(父表)中已经存在的author_id值
现在我们向authors表和books表中插入一些数据

查询books和authors表中的数据

我们在上述books表中设置了外键author_id 确保books表中的author_id只能包含authors表中已经存在author_id值
我们在authors表中看到author_id的值只有1和2 由于外键约束 如果我们向子表books中插入author_id不等于1或2的数据 则不会成功

主要作用
1.数据完整性:
·引用完整性:外键确保了一个表中(当前表为子表)的外键列只能包含另一个表(通常称为父表或主表)主键列中已经存在的值 这防止了无效或孤立的记录被插入到子表中 从而维护了数据的引用完整性
·约束完整性:通过外键约束 可以自动维护数据的完整性和一致性 当父表中的记录被删除或更新时 外键约束可以确保子表中的相关记录得到适当的处理(如级联删除或更新)
2.数据关系表达:
·外键是表达两个表之间关系的一种方式 通过外键 可以清晰地表示出哪些表是相关的 以及它们是如何关联的 这有助于数据库设计者和其他用户理解数据模型和数据结构
3.查询优化
·虽然外键本身并不直接优化查询性能 但它们通过维护数据之间的关系 使得数据库查询优化器能够更有效地执行连接(JOIN)操作 例如 在查询涉及多个表时 数据库可以利用外键关系来优化查询计划 减少不必要的表扫描和连接操作
4.级联操作
·外键约束支持级联操作 如级联删除(CASCADE DELETE)和级联更新(CASCADE UPDATE) 这意味着当父表中的记录被删除或更新时 子表中相关的记录也会自动被删除或更新 这简化了数据库维护的复杂性 并确保了数据的一致性
5.数据迁移和同步
·在数据库迁移或数据同步的场景中 外键可以确保数据在不同数据库或不同表之间保持一致性和完整性
然而 使用外键也需要注意一些潜在的问题和限制 例如:
·性能影响:虽然外键可以提高数据完整性和一致性 但它们可能会对数据库性能产生一定的影响 因为数据库需要额外的工作来维护外键约束 并在插入、更新和删除记录时检查这些约束
·设计复杂性:外键增加了数据库设计的复杂性 在设计表结构时 需要仔细考虑哪些表应该包含外键 以及这些外键应该如何设置
·灵活性限制:外键约束可能会限制数据库操作的灵活性 例如 如果子表中有依赖于父表的外键记录 那么删除或更新父表中的相关记录可能会收到限制
当然外键不仅仅只能用于两张表或多张表中 一张表也可以使用外键 这叫做自引用外键
自引用外键
自引用外键:虽然这种情况不常见 但在某些特殊场景下 一张表可能会通过外键引用自己的主键 这通常用于表示表内的层次结构或树状结构或父子关系 如组织架构、分类目录、评论的回复链等
例如 一个员工表可能包含员工ID和经理ID 其中经理ID是该表的一个外键 指向同一个表中的另一个员工ID(即该员工的经理)
示例:

manager_id是一个外键,它引用了同一个表(employees)中的employee_id字段。这个字段用于表示每个员工的直接上级。如果一个员工没有上级(比如CEO),那么这个字段可以为NULL
其实也就是 外键manager_id的值 存在于 父表employees中的employee_id中
现在我们想查询出每个员工的老板是谁 该如何操作呢?
操作如下:

在这个查询中:
·e是employees表的别名 代表员工
·m也是employees表的别名 但在这里它代表员工的上级
·我们通过left join将员工(e)与上级(m)连接起来 连接条件是 e.manager_id=m.employee_id
即员工的manager_id等于上级的id
在这里我们说明一下 left join是左连接 即员工全部出现
但是不一定所有员工都有上级 而他们依然会出现在查询结果中 只是manager_name会是NULL
查询结果选择了员工id和name以及它们上级的name(如果存在的话)
CRUD 增删改查
1.新增--插入
insert into 表名 ( [列名,列名....] ) values(值,值...);
指定了多少列名 就需要指定多少值 值与列名一一对应
不指定列名 值的顺序与个数和表中所有列一一对应
示例:
我们先事先说一下 左图是全列查询操作 在下面查询操作有讲哦 大家可以先看一下

2.查询操作
a.全列查询
select * from 表名; //使用 * 则会把表中所有的数据都查出来
我们在上述的示例中就使用了全列查询
b.指定列查询
select 列名... from 表名;

c.列为表达式的查询
select 列名/表达式 from 表名;

d.别名查询
select 列名/表达式 [as] 别名 from 表名; //别名中如果包含空格 需要用单引号引出来

e.去重查询
select distinct 列名... from 表名; //如果列名有多个 去重时只有所有的列都相等 才会判定为重复 从而进行去重

f.排序
select 列名... from 表名 order by 列名 asc/desc; //asc:升序 desc:降序

为了解决上述图中的问题 我们接下来插入一条chinese成绩为负数的数据 虽然是不合理的 但为了知道在排序中 NULL是不是在所有数中是最小的 这是值得的

g.条件查询
select 列名... from 表名 where 列名|表达式 比较/逻辑运算符 order by 列名 asc|desc;

h.区间查询
select 列名... from 表名 where 列名 between 开始条件 and 结束条件;
//等价于 开始条件<=列的值<=结束条件

i.模糊查询
select * from 表名 where 列名 like '%值_'; //%:匹配任意个字符 _:匹配单个字符
我们举例说明:

j.分页查询
select * from 表名 where 条件 order by 列名 asc|desc limit num;//查询前num条记录
//从第start条开始 向后查询num条记录
select * from 表名 where 条件 order by 列名 asc|desc limit start,num;
select * from 表名 where 条件 order by 列名 asc|desc limit num offset start;

3.更新
update 表名 set 列名=值 where 条件 order by 子句 limit num; //将满足条件的 值修改
示例:

4.删除
delete from 表名 where 条件 order by 子句 limit num;
//如果不指定条件和limit的数量就会更新整个表
示例: