调用接口拿到的数据rows,有很多行,每一行又有很多key-value pair,一开始代码是遍历第一行,每一对key-value,key作为建表时的列名,value的类型决定了该列在mysql中的类型
之后出现问题,表能建,但是插入数据时列的个数和value的个数对不上,比如,rows的第一行可以正常插入,但是第二行就插入不了,因为rows[1]里多出来一个key,所以在建表时不能只根据rows的第一行去建表。
于是遍历rows的所有行,并把过程中生成的建表的query放到set里去重,再去执行sql语句,又报错,重复列名"remark"。
怎么回事呢?不是已经去重了吗?经过排查发现,因为同样一个key remark,它对应的value可能类型不一样,这就导致同样都是remark,生成的建表query是不一样的,而set里存放的是建表query而不是单单key,所以不会被去重
目前能想到的解决方法只有遇到重复的key就去掉,只保留一个了
或者搞一个hashmap,key就是列名,value是一个list,里面存放这个列名可能的类型,比如INTEGER,VARCHAR(255)。Hashmap在python中就是字段,dict。




去重后又遇到了问题,还是这个remark的key,现在是value太长了,推测是因为remark本来对应了两种数据类型,但因为去重只保留了第一次遇到的数据类型,结果插入数据时遇到的是第二种数据类型,于是出现了长度冲突,最后决定不要remark这个字段了,直接跳过

Mysql建表遇到重复的列名
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.xdnf.cn/news/1548401.html
如若内容造成侵权/违法违规/事实不符,请联系一条长河网进行投诉反馈,一经查实,立即删除!相关文章

cve 漏洞排查流程
1、打开CVE连接 确认漏洞jar包以及版本信息 https://gitee.com/opengauss/security/issues/IASNOA?fromproject-issue 2、通过命令导出对应jar包的依赖树 并导出到目标结果文件中 mvn dependency:tree -Dincludes:gson > gson.result.txt 3、过滤test引用…
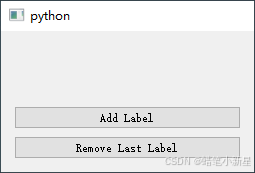
Python PyQt5 在frame中生成多个QLabel控件和彻底销毁QLabel控件
文章目录 步骤 1: 创建主窗口和布局步骤 2: 添加QLabel到QFrame步骤 3: 销毁QLabel示例代码 在PyQt5中,在QFrame或任何其他容器控件中生成多个QLabel控件并通过一个标志位或方法来彻底销毁这些QLabel控件是相对直接的操作。以下是一个简单的示例,展示了如…

【Midjourney中文版:AI绘画新纪元,赋能创意设计与开发】
在数字艺术与设计领域,创新与效率并重。Midjourney中文版,作为一款强大的AI绘画工具,正引领我们步入一个全新的创意时代。它不仅简化了复杂的绘画流程,更以智能算法为驱动力,为开发者、设计师及所有创意工作者带来了前…

如何在postman中传入文件参数
如何在postman中传入文件参数 打开Body中的form-data,将请求所需的参数写到Key中,点击右侧的按钮选择File,在Value列中即可上传本地文件。

并发编程---线程与进程
业务场景:小明去理发店理发。
小明去理发店理发,完成理发需要吹,剪,洗、理的过程。由这个场景我们引用进程和线程这两个
概念。 一.进程
1.什么是进程 进程是具有独立功能的程序关于某个数据集合上的一次运行活动,是…

js删除emoji表情问题
emoji标签占位两个 ,直接删除后一位会出现乱码符; 判断是否是emoji
function isEmoji(char) {let code char.charCodeAt(0);return code>55296&&code<57343
}
// 使用方法,传入单字符
console.log(isEmoji(1)); // false
con…

算法复杂度之时间复杂度
一 . 数据结构前言
1.1 数据结构
数据结构(Data structure) 是计算机存储,组织数据的方式,指互相之间存在一种或多种特定关系的数据元素的集合。没有一种单一的数据结构对所有用途都有用,所以要学习各式各样的数据结构,如&#…
pilz皮尔兹PSSuniversal分散控制平台 Dezentrale Steuerungsplattform 手测
pilz皮尔兹PSSuniversal分散控制平台 Dezentrale Steuerungsplattform 手测

【科研小小白】理解图片容量、像素、尺寸、分辨率各自含义、 像素、分辨率与实际尺寸之间的转换关系
理解图片容量、像素、尺寸、分辨率各自含义:
通过之前的学习,我们知道了图片有这4个参数,下面给大家总结一这下4个参数的具体含义。
1、容量(占内存):是指图像文件的存贮空间,也就是文件的大小…

华为OD机试 - 获取最多食物 - 拓扑排序、动态规划(Python/JS/C/C++ 2024 E卷 200分)
华为OD机试 2024E卷题库疯狂收录中,刷题点这里 专栏导读
本专栏收录于《华为OD机试真题(Python/JS/C/C)》。
刷的越多,抽中的概率越大,私信哪吒,备注华为OD,加入华为OD刷题交流群,…

计算机毕业设计 基于Python的广东旅游数据分析系统的设计与实现 Python+Django+Vue Python爬虫 附源码 讲解 文档
🍊作者:计算机编程-吉哥 🍊简介:专业从事JavaWeb程序开发,微信小程序开发,定制化项目、 源码、代码讲解、文档撰写、ppt制作。做自己喜欢的事,生活就是快乐的。 🍊心愿:点…

职场基本功:情绪管理的行动指南(前置情绪管理)
文章目录 引言情绪管理的目标情绪产生的阶段前置情绪管理避免情绪失控的技巧案例分析引言
成熟的职场人,必备的五项技能: 管理自己的情绪:职场需要你的行为是可控的,只有情绪是稳定的,其他人才能顺利地跟你展开协作。称赞他人:赞赏能让你获得一个友好的交流环境求助他人…

为什么这款智能在线派单软件成为行业首选?
智能在线派单软件通过自动化任务分配等提升效率,ZohoDesk因其全方位服务管理、智能分配、定制性强、数据分析等功能,成为企业优选。实例涵盖物流、家政、维修、医疗等行业,提高效率和客户满意度。 一、智能在线派单软件有什么功能
在深入探讨…


C++入门day5-面向对象编程(终)
C入门day4-面向对象编程(下)-CSDN博客 本节是我们面向对象内容的最终篇章,不是说我们的C就学到这里。如果有一些面向对象的基础知识没有讲到,后面会发布在知识点补充专栏,全都是干货满满的。
https://blog.csdn.net/u…

阿博图书馆管理:SpringBoot实战指南
第二章 开发技术介绍此次B/S结构、Java技术以及mysql数据库是该阿博图书馆管理系统的主要开发技术,然后对系统的整体设计、数据库设计、功能模块设计、系统页面设计以及系统程序设计进行了详细的研究与规划。 2.1 系统开发平台 在该阿博图书馆管理系统中,…

OJ在线评测系统 代码沙箱优化模版方法模式 使用与有规范的流程 并且执行流程可以复用
代码沙箱优化模版方法模式
上次我们代码沙箱的docker实现和原生实现
我们可以使用模版方法设计模式去优化我们的代码 我们原生的java实现代码沙箱和docker实现代码沙箱是有更多重复点的
比如说把文件 收集文件 进行校验
我们要用模版方法设计模式 定义一套通用的执行流程 让…

2024年合肥市职业院校技能大赛(中职组)赛 网络安全理论题
竞赛内容 模块A: 理论技能与职业素养
培训、环境、资料、考证
公众号:Geek极安云科
网络安全群:624032112
网络系统管理群:223627079
网络建设与运维群:870959784 极安云科专注于技能提升,赋能
2024年广东省高校的技…

cubemx配置ADC
参考博客:https://blog.csdn.net/qq_29031103/article/details/119894077 生成代码;
接着编写代码: 1)在main函数bsp初始化部分; 添加:HAL_ADCEx_Calibration_Start(&hadc1);
2)在…

C++之STL—常用拷贝和替换算法
copy(iterator beg, iterator end, iterator dest); // 按值查找元素,找到返回指定位置迭代器,找不到返回结束迭代器位置 // beg 开始迭代器 // end 结束迭代器 // dest 目标起始迭代器 replace(iterator beg, iterator end, oldvalue, newvalue); …
最新文章
- 安装aloha硬件环境
- Golang generate 指南:自动化代码生成的艺术
- 51单片机汇编学习例程(13)——DC-Motor篇
- 电机分类_控制方式
- FP-Growth算法
- 记一个FPGrowth的简单例子
- 网站服务架构:LAMP vs LNMP
- 【Elasticsearch】-实现图片向量相似检索
- Docker torchserve workflow部署流程
- Serverless and Go
- C/C++语言基础--C++运算符重载以及其重载限制
- 在Linux实时监控某个应用是否运行,未运行,执行运行命令
- Spring Boot 调用外部接口的常用方式!
- IDEA 系列产品 下载
- 虚幻引擎UE5如何云渲染,教程来了
- 【LeetCode】每日一题 2024_9_27 每种字符至少取 K 个(双指针)
- 腾讯一面-LRU缓存
- excel统计分析(3): 一元线性回归分析