论文链接:https://arxiv.org/pdf/2409.02108
Github链接:https://github.com/xw-hu/Unveiling-Deep-Shadows
亮点直击
深度学习时代阴影分析的全面综述。本文对阴影分析进行了深入的综述,涵盖了任务、监督级别和学习范式等各个方面。本文的分类旨在增强研究人员对阴影分析及其在深度学习领域应用中的关键特征的理解。
现有方法的公平比较。目前,现有方法之间的比较存在输入大小、评估指标、不同数据集和实现平台的不一致性。本文标准化了实验设置,并在同一平台上对各种方法进行了实验,以确保公平比较。此外,实验将在新修正的数据集上进行,其中的噪声标签或真实图像已被纠正。
模型大小、速度与性能关系的探索。与以往仅关注最终性能指标的阴影分析研究不同,本文还考察了模型大小和推理速度,强调了这些特征与性能之间的复杂相互作用。
跨数据集泛化研究。认识到阴影数据集中的固有偏差,本文对现有数据集进行了跨数据集泛化研究,以评估深度模型在不同数据集上的泛化能力,为这些模型的鲁棒性提供了宝贵的见解。
开放问题和未来方向的概述,涉及AIGC和大型模型。本文探讨了阴影分析中的开放问题,重点关注图像和视频感知、编辑以及对AIGC和大型视觉/语言模型的影响。本文的见解建议了未来的研究方向,为阴影分析及其应用的进展提供了路线图。
公开可用的结果、训练模型和评估指标。本文提供了在公平比较设置下的结果、训练模型和评估指标,以及新的数据集,以促进未来的研究和该领域的进步。结合这些贡献,本文提供了全面的综述,使其与早期的评审论文有所区别。
阴影是在光线遇到障碍物时形成的,导致照明区域减弱。在计算机视觉中,阴影检测、去除和生成对于增强场景理解、改善图像质量、确保视频编辑中的视觉一致性以及提升虚拟环境至关重要。本文对过去十年中深度学习领域内图像和视频的阴影检测、去除和生成进行了全面的综述,涵盖了任务、深度模型、数据集和评估指标。本文的主要贡献包括对阴影分析的全面综述、实验比较的标准化、模型大小、速度与性能之间关系的探索、跨数据集的泛化研究、未解决问题和未来方向的识别,以及提供公开资源以支持进一步研究。
阴影检测
阴影检测预测二进制 mask,指示输入图像或视频中的阴影区域。定位阴影使得阴影编辑成为可能,并促进阴影区域分析,这对于对象检测和跟踪等高级计算机视觉任务至关重要。本小节提供了针对图像和视频的阴影检测深度模型的全面概述。此外,它还总结了用于评估阴影检测方法的常用数据集和指标。为了评估不同模型在各个方面的有效性,本文进行了实验并呈现了比较结果。
用于图像阴影检测的深度模型
下表1展示了不同方法的基本属性,为理解深度学习领域中图像阴影检测的全貌提供了便利的参考。最初,早期的深度学习方法使用深度卷积神经网络根据输入图像预测阴影特征,包括阴影边界和局部阴影块。随后,研究重点转向专门设计的端到端深度神经网络,这些网络能够直接从阴影图像生成阴影 mask。另一种方法是采用多任务学习,其中模型被训练以同时执行阴影检测和阴影去除。之后,提出了基于半监督、自监督和大型视觉模型的方法,以进一步提高在各种场景下的性能。在接下来的小节中,本文将详细描述每个类别中的方法。
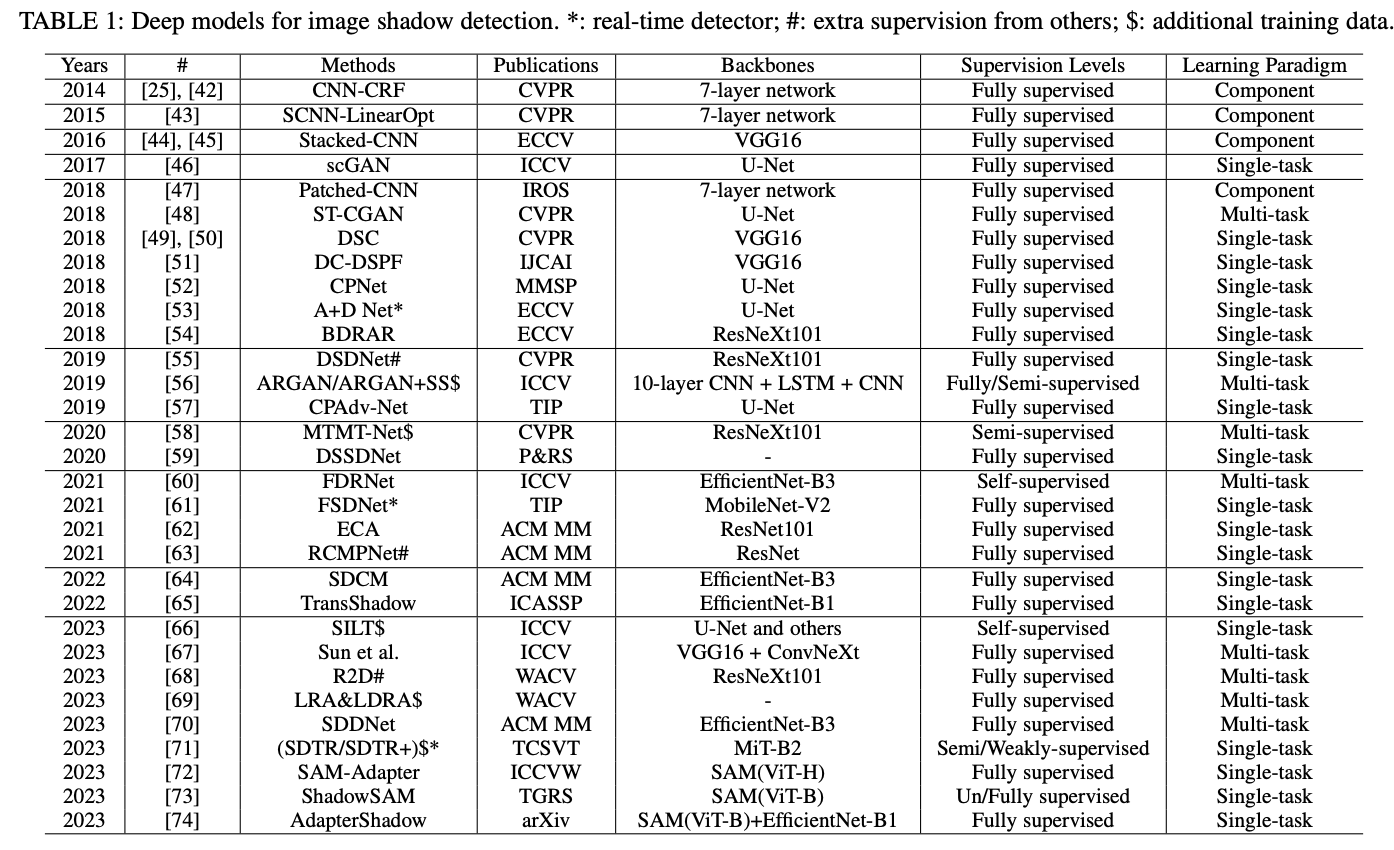
组件学习
早期的方法主要采用卷积神经网络(CNN)来生成阴影特征,然后使用统计建模方法(例如,条件随机场(CRF))来获得最终的阴影 mask。
-
CNN-CRF 采用多个CNN在超像素级别和物体边界上学习特征,然后使用CRF模型生成平滑的阴影轮廓。
-
SCNN-LinearOpt 使用CNN捕捉阴影边缘的局部结构及相关特征,然后制定最小二乘优化来预测阴影mask。
-
Stacked-CNN 使用全卷积神经网络(FCN)输出图像级阴影先验图,随后使用补丁CNN生成局部阴影mask。然后,使用加权平均融合多个预测结果。
-
Patched-CNN 首先采用支持向量机与统计特征来获取阴影先验图,然后使用CNN预测补丁的阴影概率图。
使用深度卷积神经网络学习阴影特征仅在早期方法中采用。以下类别中的深度模型均为端到端训练。
单任务学习
随着深度神经网络的发展,方法采用端到端的深度模型进行阴影检测,通过直接从输入的阴影图像预测输出的阴影 mask。
-
scGAN 是一种条件生成对抗网络,具有可调的敏感性参数,用于调节预测阴影 mask 中阴影像素的数量。
-
DSC 构建了一个方向感知空间上下文(DSC)模块,以方向感知的方式分析图像上下文。该模块在卷积神经网络(CNN)中使用,生成多尺度阴影 mask ,并将其合并为最终的阴影 mask 。
-
DC-DSPF 堆叠多个并行融合分支以构建网络,该网络以深度监督的方式进行训练,然后使用密集级联学习方案对预测结果进行递归精炼。
-
CPNet 在 U-Net中添加了残差连接来识别阴影区域。
-
A+D Net 使用一个衰减器(A-Net)生成具有衰减阴影的真实图像,作为额外的困难训练样本,这些样本与原始训练数据一起用于训练检测器(D-Net)以预测阴影 mask 。值得注意的是,这是一个快速阴影检测器,能够实现实时性能。
-
BDRAR 引入了递归注意残差模块,以结合来自相邻 CNN 层的特征,并学习一个注意力图以递归选择和精炼残差上下文特征。此外,它开发了一个双向特征金字塔网络,以聚合来自不同 CNN 层的阴影特征。
-
DSDNet 设计了分心感知阴影(DS)模块,通过明确预测假阳性和假阴性来学习分心感知和区分特征。值得注意的是,预测的假阳性和假阴性来自其基础模型和其他阴影检测器。
-
CPAdv-Net 在 U-Net 的编码器层和解码器层之间设计了一个跳跃连接中的映射方案。此外,它引入了两个对抗样本生成器,从原始图像生成用于训练的数据。
-
DSSDNet 采用编码器-解码器残差结构和深度监督渐进融合模块,以预测航空图像上的阴影 mask 。
-
FSDNet 是一个快速阴影检测网络,采用 DSC 模块来聚合全局特征,并构建一个细节增强模块,以在低级特征图中提取阴影细节。它使用 MobileNet V2 作为骨干网络,以实现实时性能。
-
ECA 采用多种并行卷积,使用不同的卷积核来增强在适当尺度下的有效物体上下文。
-
RCMPNet 提出了相对置信度图回归的方法,利用一个预测网络来评估阴影检测方法的可靠性,并结合基于注意力的长短期记忆(LSTM)子模块以增强置信度图的预测。
-
SDCM 采用两个并行分支,分别生成阴影和非阴影 mask ,利用它们的互补特性。在训练过程中,通过使用负激活、身份重建损失和区分性损失来提升阴影检测结果的准确性。
-
TransShadow 使用多级特征感知模块,利用 Transformer 来区分阴影和非阴影区域,并结合渐进上采样和跳跃连接以增强特征提取效果。
多任务学习
一些方法采用端到端的深度神经网络,不仅执行 mask 预测任务,还执行其他任务,例如预测无阴影图像以进行阴影去除。这些多任务方法受益于相互之间的改进或对阴影图像的更好理解。
-
ST-CGAN 使用两个顺序的条件 GAN,其中第一个网络预测阴影 mask ,第二个网络通过将阴影图像和阴影 mask 作为输入来预测无阴影图像。
-
ARGAN 开发了注意力递归生成对抗网络,用于阴影检测和去除。生成器生成阴影注意力图,并通过多个逐步的粗到细的步骤恢复无阴影图像。此外,ARGAN 可以使用未标记的数据以半监督的方式进行训练,利用 GAN 中的对抗损失。
-
R2D 通过利用在阴影去除过程中学习到的阴影特征来增强阴影检测性能。所提出的 FCSD-Net 架构集成到 R2D 框架中,重点通过特别设计的检测器模块提取细致的上下文特征。它使用假阳性和假阴性以及 DSDNet中的 DS 模块。
-
LRA 和 LDRA 在堆叠范式中优化残差,以同时解决阴影检测和去除的挑战,指导优先重建阴影区域,并对最终的混合/颜色校正做出贡献,同时减少开销并提高各种主干架构的准确性。它生成一个配对数据集,其中包含阴影图像、无阴影图像和阴影 mask ,以进行预训练。
-
SDDNet 引入了样式引导的双层解耦网络用于阴影检测,利用特征分离和重组模块通过差异化监督来分离阴影和背景层。同步联合训练确保了分离的可靠性,而阴影样式过滤模块引入了样式约束(由 Gram 矩阵 表示),增强了特征解耦的质量。
-
Sun 等人 提出了自适应照明映射 (AIM) 模块,该模块将原始图像转换为具有不同强度的 sRGB 图像,并配合利用多尺度对比信息的阴影检测模块。反馈机制指导 AIM 以阴影感知的方式渲染具有不同照明的 sRGB 图像。
半监督学习
训练深度模型进行阴影检测需要标记的阴影 mask,因此有限的训练数据量会影响深度模型在复杂情况下的性能。因此,提出了半监督阴影检测器,以便在标记和未标记的阴影图像上训练模型。
-
ARGAN+SS 如前文所述。
-
MTMT-Net 是一种成功的半监督阴影检测方法,它基于教师-学生(mean teacher)架构构建了一个多任务平均教师网络进行半监督学习。教师和学生网络以多任务学习的方式检测阴影区域、阴影边缘和阴影数量。
-
SDTR 和 SDTR+ 分别表示半监督和弱监督阴影检测器。新阴影图像的处理过程涉及通过可靠样本选择方案识别不可靠样本。随后,可以选择重新训练可靠样本、重新推断不可靠样本以获得精确的伪 mask,或采用灵活的注释(例如,框、点、涂鸦),并获得见解以提高深度模型的泛化能力。利用 MiT-B2 主干,SDTR 和 SDTR+ 都能实时运行。
自我监督学习
自监督学习利用数据本身作为监督信号来学习深度特征。这个理念可以在现有的训练数据集上实现,也可以使用额外的数据。
-
FDRNet 设计了一种特征分解和重加权方案,以减轻深度阴影检测器对强度线索的偏见。它首先采用两个自监督任务,通过使用调整亮度的图像作为监督来学习强度变化和强度不变的特征。然后,它使用累积学习对特征进行重加权。
-
SILT 构建了一个阴影感知迭代标签调整框架,具有阴影感知的数据增强、用于 mask 预测的全局-局部融合、阴影感知的过滤,以及整合零标记的无阴影图像以提高非阴影区域的识别能力。它收集了一些互联网图像(暗物体和无阴影图像),进一步帮助训练网络以区分阴影和暗物体。该框架使用了多种基础网络作为主干,包括 U-Net、ResNeXt101、EfficientNet 和 PVT v2。
大型视觉模型
现代大型视觉模型在一般视觉任务中表现出色。例如,“任意分割”模型(SAM)在多种物体类别的图像分割中展现了令人印象深刻的零样本性能。然而,在复杂背景和复杂场景中处理阴影仍然很困难。为了提高SAM在阴影检测方面的性能,许多方法旨在仅微调新添加的或部分结构。
-
SAM-Adapter 将SAM作为其骨干网络,通过整合定制信息来增强性能。这涉及在SAM编码器的每一层中集成两个多层感知机(MLP)作为适配器,同时微调适配器和SAM mask 解码器。
-
ShadowSAM 在多个SAM编码器层中集成两个MLP和一个GELU激活函数作为提示器。它使用非深度学习方法生成伪 mask ,并通过照明和纹理引导的更新策略来改善这些伪 mask。该方法包括用于增量课程学习的 mask 多样性指标。ShadowSAM支持无监督(使用伪 mask)和监督模式的训练。
-
AdapterShadow 将可训练的适配器插入到SAM的冻结图像编码器中进行微调。此外,引入了一种网格采样方法,以自动从预测的粗略阴影 mask 生成密集点提示。请注意,SAM的骨干网络是ViT-H,辅助网络的骨干是EfficientNet-B1。
用于视频阴影检测的深度模型
视频阴影检测处理动态场景,并在视频帧中生成一致的阴影 mask 。学习导向的数据集和视频阴影检测方法由 TVSD-Net 制定。下表 2 总结了所调查论文的基本属性。

-
TVSD-Net 作为基于深度学习的视频阴影检测的先驱,TVSD-Net 采用三重并行网络协同工作,以在视频内部和视频间层面获得区分性表示。该网络包括一个双门协同注意模块,用于约束同一视频中相邻帧的特征,并引入辅助相似性损失,以捕捉不同视频之间的语义信息。
-
Hu et al. 该方法采用基于光流的扭曲模块对帧之间的特征进行对齐和组合,应用于多个深度网络层,以提取相邻帧的信息,涵盖局部细节和高级语义信息。
-
STICT 该方法使用均值教师学习,结合标记图像和未标记视频帧,实现实时阴影检测。它引入时空插值一致性训练,以提高泛化能力和时间一致性。
-
SC-Cor 该方法采用对应学习以提高细粒度的像素级相似性,采用像素到集合的方式,精细化帧间阴影区域内的像素对齐。它增强了时间一致性,并无缝地作为现有阴影检测器中的即插即用模块,且没有计算成本。
-
STF-Net 该方法使用 Res2Net50 作为骨干网络,在实时视频中高效检测阴影,引入一个简单而有效的时空融合模块,以利用时间和空间信息。
-
SCOTCH 和 SODA 这两个框架形成了一个视频阴影检测体系。SCOTCH 使用监督对比损失来增强阴影特征的区分能力,而 SODA 应用时空聚合机制来管理阴影变形。这种组合改善了特征学习和时空动态。
-
ShadowSAM 该方法对 SAM进行微调,以使用边界框作为提示检测第一帧中的阴影,并采用以 MobileNetV2 为骨干的长短期网络在视频中传播 mask,利用长短期注意力提升性能。
-
RSM-Net 该方法引入了参考视频阴影检测任务,提出了一种参考阴影跟踪记忆网络,利用双轨协同记忆和混合先验阴影注意力,根据描述性自然语言提示在视频中分割特定阴影。
-
TBGDiff 这是第一个用于视频阴影检测的扩散模型,通过提取时间引导和边界信息,使用双尺度聚合来处理时间信号,并通过时空编码embedding进行边界上下文提取和时间线时间引导。
-
Duan et al. 该方法使用两阶段训练范式,首先使用预训练的图像域模型,并通过时间适应模块和空间适应模块将其调整为视频域,以实现时间一致性,并整合高分辨率局部补丁与全局上下文特征。这两个模块采用类似 ControlNet的结构。
阴影检测数据集
接下来,本文专门讨论用于模型训练和评估的广泛使用的数据集,省略其他用于额外半监督/弱监督训练的数据。
用于阴影检测的图像数据集
早期的数据集,例如UCF和UIUC,是为了使用手工特征训练传统机器学习方法而准备的。UCF包含245张图像,其中117张是在多样的户外环境中拍摄的,包括校园和市区区域。剩余的图像来自现有的数据集。每张图像中的阴影都经过精细的像素级手动标注,并由两个人进行了验证。UIUC有108张阴影图像,带有标记的阴影 mask 和无阴影图像,这是首次能够在几十张图像上进行阴影去除的定量评估。
后来,收集了包含数千张阴影图像的数据集,以训练深度学习模型。
-
SBU 和 SBU-Refine: SBU是一个大规模的阴影数据集,包含4,087张训练图像和638张测试图像,使用了一种懒惰标注方法,用户最初粗略地标记阴影和非阴影区域,然后通过优化算法对这些标签进行细化。SBU-Refine手动重新标记测试集,并通过算法细化训练集中的噪声标签。
-
ISTD: 提供阴影图像、无阴影图像和阴影 mask,适用于阴影检测和去除任务。包含1,330张训练图像和540张测试图像,以及135个不同的背景场景。
-
CUHK-Shadow: 是一个大型数据集,包含10,500张阴影图像,分为7,350张用于训练,1,050张用于验证,2,100张用于测试。它包括五个类别:ShadowADE、ShadowKITTI、Shadow-MAP、ShadowUSR和Shadow-WEB。
-
SynShadow: 是一个合成数据集,包含10,000组阴影/无阴影/遮罩图像三元组。利用阴影照明模型和3D模型生成,适用于预训练或零样本学习。
-
SARA: 包含7,019张原始图像及其阴影 mask ,分为6,143张用于训练和876张用于测试,涵盖17个类别和11个背景。
用于阴影检测的视频数据集
-
ViSha: 包含120个多样化视频,提供像素级阴影标注的二值 mask 。总计11,685帧,390秒的视频,标准化为30帧每秒,训练和测试集按5:7比例划分。
-
RVSD: 从ViSha中选择86个视频,重新标注为单独的阴影实例,并添加自然语言描述提示,通过验证确保质量。
-
CVSD: 复杂视频阴影数据集,包含196个视频片段,涉及149个类别,具有多样的阴影模式。包括278,504个标注的阴影区域和19,757帧的阴影 mask ,适用于复杂场景。
评估指标
图像阴影检测的评估指标
-
BER(平衡错误率)是一种常用的评估阴影检测性能的指标。在这种评估中,阴影和非阴影区域的贡献相等,无论它们的相对面积如何。BER的计算公式为:
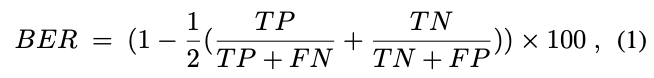
其中,、、 和 分别表示真正例、真负例、假正例和假负例。为了计算这些值,首先将预测的阴影 mask 量化为二值 mask。当像素值超过0.5时设为1,否则设为0。然后将此二值 mask 与真实 mask 进行比较。BER值越低,检测结果越有效。有时还会分别提供阴影和非阴影区域的BER值。
-
-measure 被提出用于评估阴影 mask 中的非二值预测值。该指标以加权方式计算精准率和召回率,较高的值表示更优的结果。
视频阴影检测的评估指标
视频阴影检测中使用深度学习的首篇论文采用平均绝对误差(MAE)、F-测量()、交并比(IoU)和平衡错误率(BER)来评估性能。然而,评估仅限于单个图像(帧级别),未能捕捉时间稳定性。Ding等人引入了时间稳定性指标。
时间稳定性(TS) 计算两个相邻帧的真实标签之间的光流,记为和。虽然ARFlow最初用于光流计算,但本文采用了RAFT。这是因为阴影的运动在RGB帧中难以捕捉。定义为和之间的光流。然后,通过光流对进行变形得到的重建结果记为。是视频帧的数量。接下来,视频阴影检测的时间稳定性基于相邻帧之间的流变形交并比(IoU)进行测量:
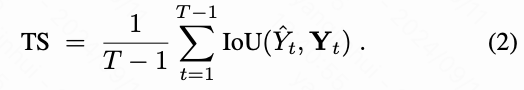
实验结果
在已有方法的原始论文中报告的比较结果在输入尺寸、评估指标、数据集和实现平台上存在不一致。因此,本文标准化实验设置,并在相同平台上对各种方法进行实验,以确保公平比较。此外,本文进一步在多个方面比较这些方法,包括模型的大小和速度,并进行跨数据集评估,以评价其泛化能力。
图像阴影检测
整体性能基准测试结果。本文使用 SBU-Refine和 CUHK-Shadow来评估各种方法的性能。SBU-Refine 通过纠正错误标记的 mask 提高了评估准确性,从而减少了比较方法中的过拟合问题。CUHK-Shadow 是最大的真实数据集,提供了多样化的场景以进行全面测试。比较的方法列在下表 3 中,本文排除了那些没有代码可用的方法。除了 DSC(在 PyTorch 中使用 ResNeXt101 主干实现)外,本文使用原始源代码重新训练了这些方法。所有比较方法都省略了后处理,例如 CRF。先前的方法采用了不同的输入尺寸。在本文中,本文将输入尺寸设置为 和 ,以在两种分辨率下呈现结果。本文采用平衡错误率(BER)作为评估指标,使用 Python 代码计算。报告了阴影区域(BERS)和非阴影区域(BERNS)的 BER。为公平比较,评估时结果被调整到与真实值相同的分辨率。
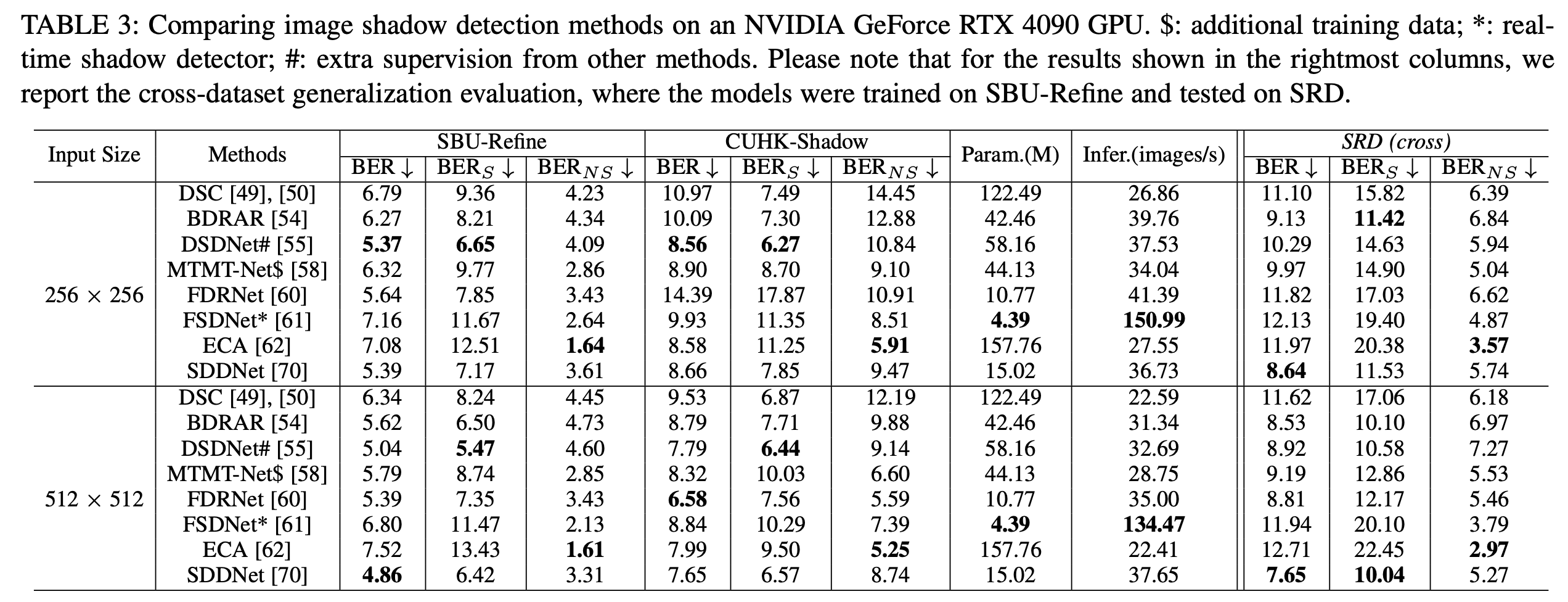
上表 3 和下图 1 展示了每种方法的准确性、运行时间和参数。本文可以观察到:
-
一些相对较旧的方法比最近的方法表现更好,表明在原始 SBU 数据集上存在过拟合问题;
-
FSDNet 是唯一一个开源(提供训练和测试代码)的实时阴影检测器,具有较少的参数和快速的推理速度;
-
DSDNet 在其训练过程中结合了 DSC和 BDRAR的结果,并在性能上与最近的方法 SDDNet相当;
-
较大的输入尺寸通常会带来性能提升,但也需要更多时间;
-
CUHK-Shadow 比 SBU-Refine 更具挑战性。FDRNet在检测 CUHK-Shadow 中的阴影时对输入分辨率特别敏感,其中包含复杂的阴影或更细的细节,这些在更高分辨率的输入()下更有利。
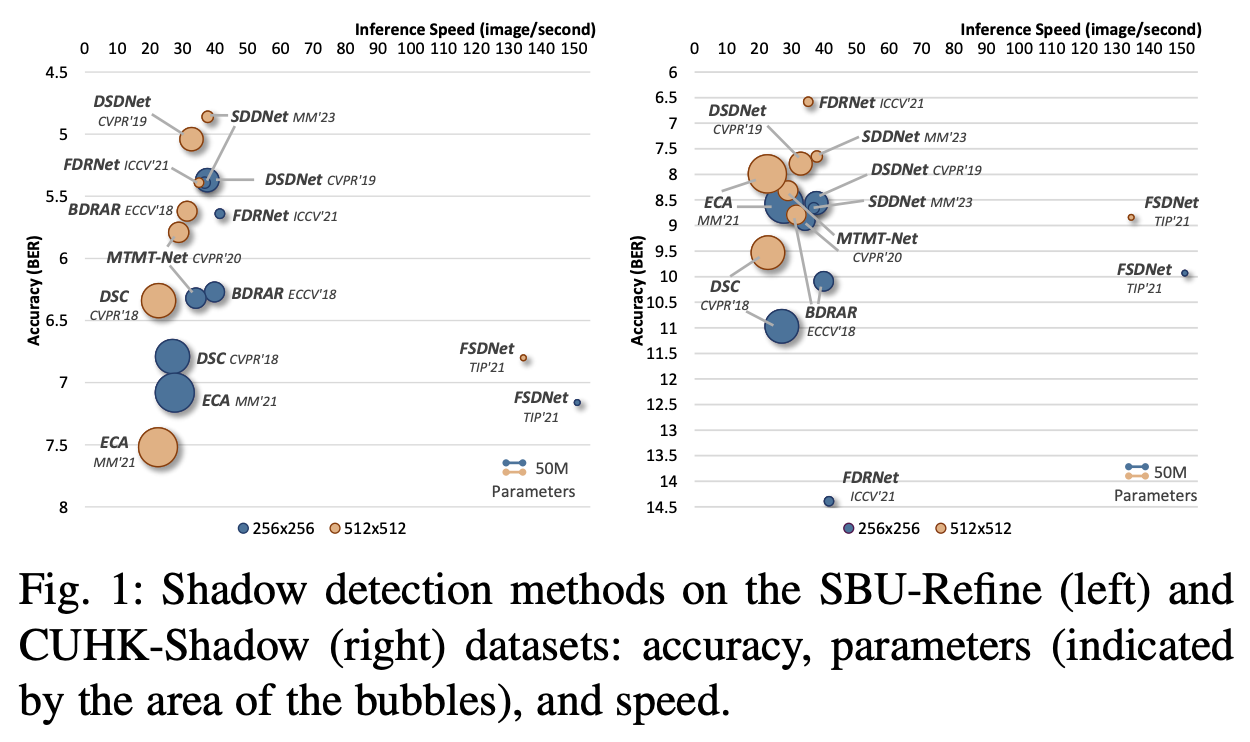
跨数据集泛化评估。 为了评估阴影检测方法的泛化能力,本文通过使用在 SBU-Refine 训练集上训练的模型,检测 SRD 测试集上的阴影来进行跨数据集评估。由于 SRD 在背景特征的复杂性上与 SBU 相似,因此被使用。请注意,这是首次在大规模数据集上评估泛化能力。
上表 3 中最右边的三列显示了结果,其中性能显著下降,尤其是在阴影区域。这突显了跨数据集评估对于稳健阴影检测的重要性。阴影区域的性能下降表明这些方法在应对 SRD 中存在的不同光照条件和复杂背景纹理时存在困难。未来的工作应着重于提高阴影检测模型的稳健性,以更好地在不同数据集间泛化。
总结 实验结果表明,如何开发一个高效且稳健的模型,以在复杂场景下实现高精度的图像阴影检测,仍然是一个具有挑战性的问题。
视频阴影检测
ViSha 数据集用于评估视频阴影检测方法,输入尺寸为 512×512,参考 [88], [92]。由于 SAM 预训练模型的位置信息embedding,ShadowSAM 使用 1024×1024 的输入尺寸。SC-Cor使用 DSDNet作为基础网络。STICT在训练中使用了额外的 SBU 数据集图像。除了常用的图像级评估指标 BER 和 IoU,本文还采用了通常被忽略的时间稳定性(TS)。结果被调整为 512×512 用于 TS 的光流计算,并调整为真实分辨率用于其他指标。
下表 4 显示了结果,揭示了视频阴影检测方法的显著优势和权衡。SCOTCH 和 SODA 展现了最佳的整体性能,具有最低的 BER 和最高的 AVG,而 ShadowSAM 虽然模型较大,但达到了最高的 IoU。STICT 因其最快的推理速度而突出,尽管 IoU 较低,但非常适合实时应用。SC-Cor 和 TVSD-Net 展示了平衡的性能,BER、IoU 和 TS 得分适中。

总结 实验结果表明,在视频阴影检测中,如何在帧级准确性、时间稳定性、模型复杂性和推理速度之间实现最佳平衡仍然是一个具有挑战性的问题。
实例阴影检测
这一部分介绍了另一个任务,即实例阴影检测,其目标是同时找到阴影及其关联的物体。了解物体与其阴影之间的关系对许多图像/视频编辑应用大有裨益,因为这样可以轻松地同时操作物体及其关联的阴影。这个任务最初在图像层面由[108]提出,随后在视频中由[111]扩展。下表5总结了所调查方法的基本特性。

用于图像实例阴影检测的深度模型
实例阴影检测旨在检测阴影实例及其投射每个阴影的相关物体实例。
-
LISA:首先生成可能包含阴影/物体实例及其关联的区域建议。对于每个建议,它预测单个阴影/物体实例的边界框和 mask ,生成阴影-物体关联(对)的边界框,并估计每个阴影-物体关联的光照方向。最后通过将阴影和物体实例与其对应的阴影-物体关联配对来完成过程。
-
SSIS:引入了一种单阶段全卷积网络架构,包含一个双向关系学习模块,用于直接端到端学习阴影和物体实例之间的关系。该模块深入研究阴影-物体关联对,学习从每个阴影实例中心到其关联物体实例中心的偏移向量,反之亦然。
-
SSISv2:通过新技术扩展了SSIS,包括可变形的MaskIoU头、阴影感知的复制粘贴数据增强策略和边界损失,旨在增强阴影/物体实例和阴影-物体关联的分割效果。
用于视频实例阴影检测的深度模型
视频实例阴影检测不仅涉及在视频帧中识别阴影及其关联的物体,还需要在整个视频序列中持续跟踪每个阴影、物体及其关联,即使在关联中阴影或物体部分暂时消失的情况下也要进行处理。
-
ViShadow 是一种半监督框架,训练于标注的图像数据和未标注的视频序列上。初始训练通过中心对比学习在不同图像中配对阴影和物体。随后,利用未标注视频和相关的循环一致性损失来增强跟踪。此外,它通过检索机制解决了物体或阴影实例暂时消失的挑战。
实例阴影检测数据集
-
SOBA 是首个用于图像实例阴影检测的数据集,包含1,100张图像和4,293个标注的阴影-物体关联。最初,[108]收集了1,000张图像,[110]又增加了100张具有挑战性的阴影-物体对图像用于专门测试。训练集包括840张图像和2,999个对。阴影实例、物体实例及其关联的标签使用Affinity Photo App和Apple Pencil进行了精细标注。
-
SOBA-VID 是为视频实例阴影检测设计的数据集,包含292个视频,共7,045帧。数据集分为232个视频(5,863帧)的训练集和60个视频(1,182帧)的测试集。值得注意的是,测试集为每个阴影和物体实例提供详细的逐帧标注,而训练集每四帧中标注一帧。
评估指标
-
SOAP (阴影-物体平均精度)通过计算交并比(IoU)的平均精度(AP)来评估图像实例阴影检测性能。它扩展了真正例的标准,要求预测和真实阴影实例、物体实例以及阴影-物体关联的 IoU 阈值大于或等于 。评估时使用特定的 值 0.5(SOAP50)或 0.75(SOAP75),并在 从 0.5 到 0.95 以 0.05 为增量的范围内计算平均值(SOAP)。
-
SOAP-VID 通过将 SOAP 中的 IoU 替换为时空 IoU 来评估视频实例阴影检测。
实验结果
图像实例阴影检测评估
整体性能基准结果 使用SOAP作为数据集,SOBA作为评估指标。比较的方法列在下表6中。本文使用其原始代码重新训练这些方法,将输入图像的短边在训练期间调整为六个尺寸之一:640、672、704、736、768或800。在推理过程中,本文将短边调整为800,确保长边不超过1333。
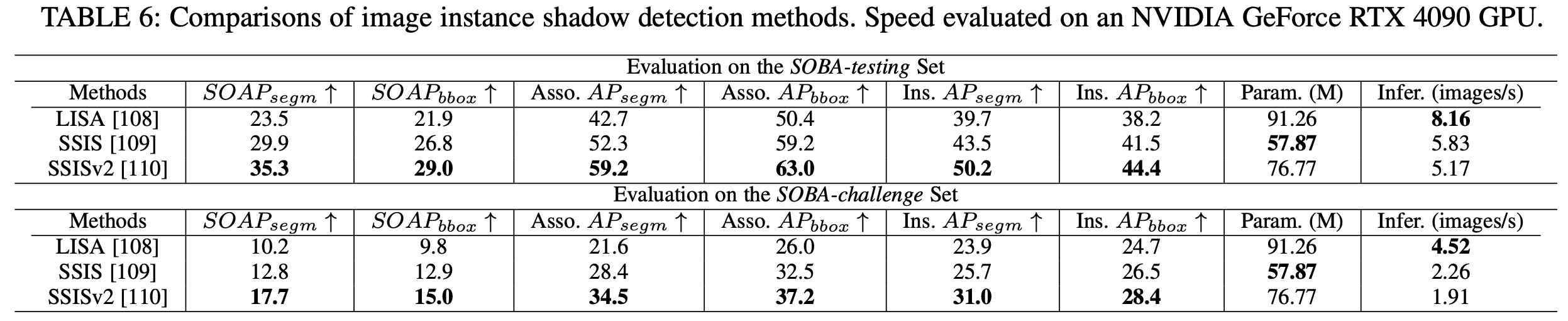
上表6展示了每种方法的准确性、运行时间和参数数量,观察到:(i) SSISv2达到最佳性能,但速度最慢;(ii) 所有方法在处理复杂场景时性能有限;(iii) 复杂场景中的更多实例显著降低推理速度。
跨数据集泛化评估 为评估泛化能力,本文进行了跨数据集评估,将在SOBA训练集上训练的模型应用于SOBA-VID测试集的视频帧中检测图像实例阴影/物体。注意,没有进行时间一致性评估。下表7显示了结果,观察到:(i) 比较方法的趋势与在SOBA测试集上观察到的趋势一致;(ii) 性能没有显著下降,展示了实例阴影检测方法强大的泛化能力。

总结 实验结果表明,如何开发一个高效的模型以准确分割阴影和物体实例仍然是一个具有挑战性的问题。
视频实例阴影检测的评估 在此,本文展示ViShadow [111]在SOBA-VID测试集上的性能指标:SOAP-VID为39.6,关联AP为61.5,实例AP为50.9。20帧的总推理时间为93.63秒,处理速度约为0.21帧每秒,模型参数为66.26M。
阴影去除
阴影去除旨在通过恢复阴影下的颜色生成无阴影的图像或视频帧。除了普通场景,文档和面部阴影去除也是重要的特定应用。本小节全面概述了用于阴影去除的深度模型,并总结了评估阴影去除方法的常用数据集和指标。此外,为了评估各种方法的有效性,本文进行了实验并展示了比较结果。
用于图像阴影去除的深度模型
以下是下表 8 中关于图像阴影去除的论文综述。
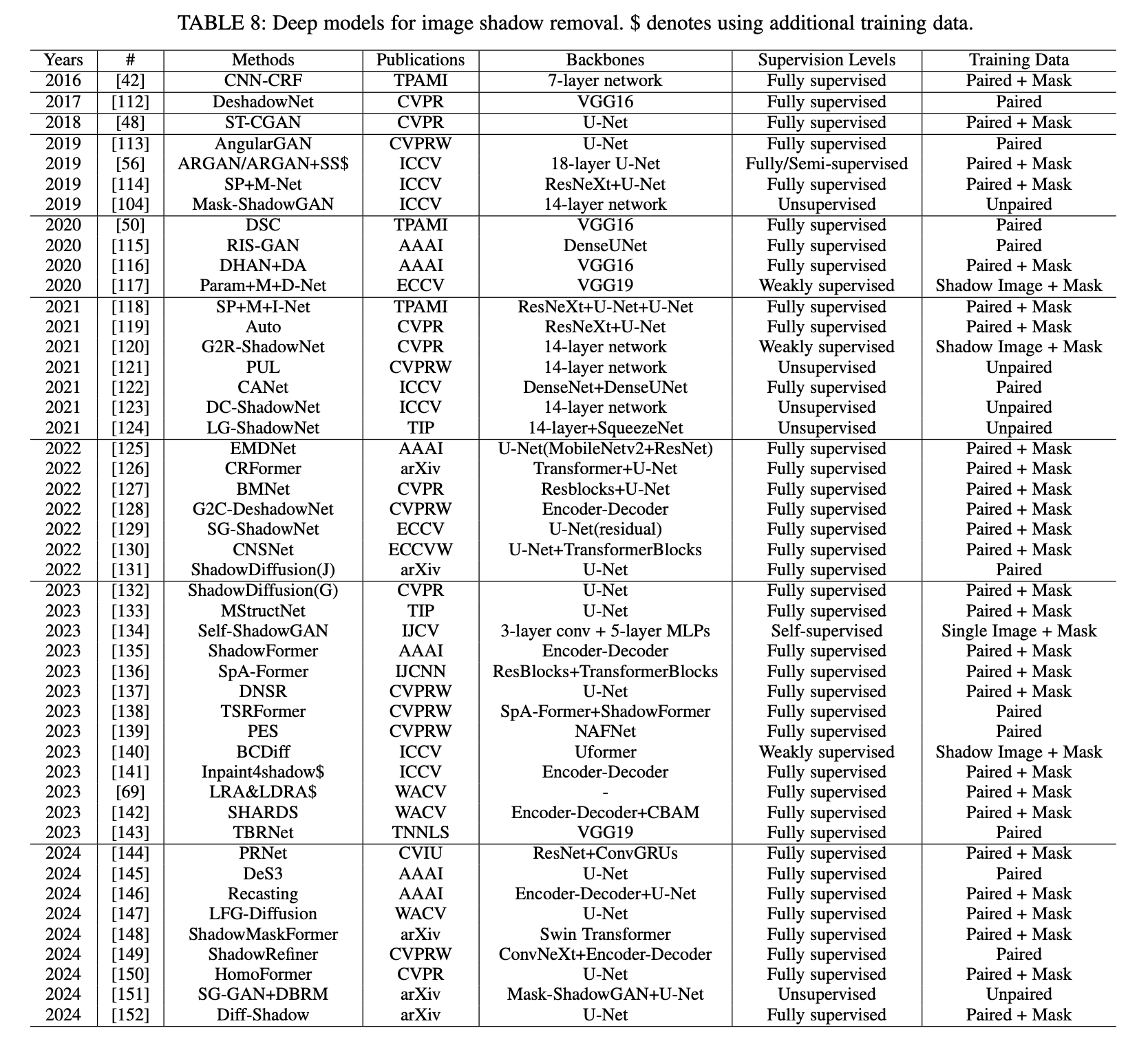
按监督级别分类的方法:
监督学习。 监督通常基于以下两种情况:
-
无阴影图像
-
无阴影图像和阴影 mask
(i)基于 CNN 的方法:
-
CNN-CRF: 使用多个 CNN 学习检测阴影,并构建贝叶斯模型去除阴影。深度网络仅用于检测阴影。
-
DeshadowNet: 一种端到端网络,包含三个子网络,从全局视角提取图像特征。
-
SP+M-Net: 将阴影图像建模为无阴影图像、阴影参数和阴影哑光的组合,然后使用两个独立的深度网络预测阴影参数和阴影哑光。在测试中,使用预测的阴影 mask 作为额外输入。
-
DSC: 引入方向感知空间上下文模块分析具有方向感的图像上下文。使用多个 DSC 模块的 CNN 生成残差,与输入结合生成无阴影图像。
-
DHAN+DA: 提出分层聚合注意力模型,结合多重上下文和来自阴影 mask 的注意力损失,使用 Shadow Matting GAN 网络合成阴影图像。
-
SP+M+I-Net: 扩展SP+M-Net,通过约束 SP-Net 和 M-Net 的搜索空间,添加半影重构损失帮助 M-Net 关注阴影半影区域,利用 I-Net 进行修复,并引入平滑损失以调节哑光层。可扩展用于基于补丁的弱监督阴影去除。
-
Auto: 匹配阴影区域与非阴影区域的颜色生成过曝图像,通过阴影感知的 FusionNet 合并输入,生成自适应内核权重图。最后,边界感知的 RefineNet 减少阴影边界的半影效果。
-
CANet: 采用两阶段上下文感知方法:首先采用上下文补丁匹配模块寻找潜在的阴影和非阴影补丁对,促进跨不同尺度的信息传递,并使用编码器-解码器进行细化和最终化。
-
EMDNet: 提出基于模型驱动的网络进行阴影去除的迭代优化。每个阶段更新变换图和无阴影图像。
-
BMNet: 双射映射网络,集成阴影去除和阴影生成共享参数。具有用于仿射变换的可逆块,并包括利用 U-Net 派生的阴影不变颜色进行颜色恢复的阴影不变颜色指导模块。
-
G2C-DeshadowNet: 两阶段阴影去除框架,首先从灰度图像中去除阴影,然后利用修改的自注意力块优化全局图像信息进行上色。
-
SG-ShadowNet: 两部分风格引导的阴影去除网络:基于 U-Net 的粗略去阴影网络进行初步阴影处理,风格引导的再去阴影网络精细化结果,采用空间区域感知原型标准化层,将非阴影区域风格渲染到阴影区域。
-
MStructNet: 重建输入图像的结构信息以去除阴影,利用无阴影的结构先验进行图像级阴影消除,并结合多级结构洞察。
-
DNSR: 基于 U-Net 的架构,具有动态卷积、曝光调整和蒸馏阶段以增强特征图。集成通道注意力和融合池以改善特征融合。
-
PES: 使用金字塔输入处理各种阴影大小和形状,以 NAFNet为基础框架。通过三阶段训练过程,改变输入和裁剪大小、损失函数、批量大小和迭代次数,并通过模型汤精炼,在 NTIRE 2023 图像阴影去除挑战赛的 WSRD 中获得最高 PSNR。
-
Inpaint4shadow: 通过在修复数据集上进行预训练来减少阴影残留,利用双编码器处理阴影和阴影 mask 图像,使用加权融合模块合并特征,并通过解码器生成无阴影图像。
-
LRA&LDRA: 通过优化堆叠框架 中的残差来改进阴影检测和去除。它通过混合和颜色校正重建阴影区域。研究表明,在包含配对阴影图像、无阴影图像和阴影 mask 的大规模合成数据集上进行预训练显著提高了性能。
-
SHARDS: 使用两个网络从高分辨率图像中去除阴影:LSRNet 从阴影图像及其 mask 生成低分辨率的无阴影图像,而 DRNet 使用原始高分辨率阴影图像细化细节。由于 LSRNet 在较低分辨率下处理主要的阴影去除工作,这一设计使 DRNet 保持轻量。
-
PRNet: 将通过浅层六块 ResNet 的阴影特征提取与通过再集成模块和基于 ConvGRU 的更新 [155] 的渐进阴影去除相结合。再集成模块迭代增强输出,更新模块生成用于预测的阴影衰减特征。
(ii) 基于 GAN 的方法采用生成器预测无阴影图像,判别器进行判断。
-
ST-CGAN: 使用一个条件 GAN 检测阴影,并利用另一个条件 GAN 去除阴影。
-
AngularGAN: 使用 GAN 端到端预测无阴影图像。该网络在合成配对数据上进行训练。
-
ARGAN: 首先开发一个阴影注意力检测器生成注意力图以标记阴影,然后递归恢复较轻或无阴影的图像。注意,它可以使用未标记数据和 GAN 中的对抗损失以半监督方式进行训练。
-
RIS-GAN: 在编码器-解码器结构中采用四个生成器和三个判别器来生成负残差图像、中间阴影去除图像、反向光照图和精细化阴影去除图像。
-
TBRNet: 是一个具有多任务协作的三分支网络。它由三个专门分支组成:阴影图像重建以保留输入图像细节;阴影遮罩估计以识别阴影位置并调整光照;阴影去除以对齐阴影区域与非阴影区域的光照,从而生成无阴影图像。
(iii) 基于Transformer的方法通过自注意力机制更好地捕获全局上下文信息。
-
CRFormer: 是一个混合CNN-Transformer框架,使用不对称的CNN从阴影和非阴影区域提取特征,采用区域感知的交叉注意力机制聚合阴影区域特征,并使用U形网络优化结果。
-
CNSNet: 采用双重方法进行阴影去除,集成了面向阴影的自适应归一化以保持阴影和非阴影区域之间的统计一致性,并使用Transformer进行阴影感知聚合以连接阴影和非阴影区域的像素。
-
ShadowFormer: 使用通道注意力编码器-解码器框架和阴影交互注意力机制,利用上下文信息分析阴影和非阴影块之间的相关性。
-
SpA-Former: 由Transformer层、系列联合傅里叶变换残差块和双轮联合空间注意力组成。双轮联合空间注意力与DSC相同,但使用阴影 mask 进行训练。
-
TSRFormer: 是一个两阶段架构,采用不同的Transformer模型进行全局阴影去除和内容细化,有助于抑制残留阴影并优化内容信息。SpA-Former和ShadowFormer是其骨干。
-
ShadowMaskFormer: 将Transformer模型与补丁embedding中的阴影 mask 集成,采用0/1和-1/+1二值化以增强阴影区域的像素。
-
ShadowRefiner: 使用基于ConvNeXt的U-Net提取空间和频率表示,将受阴影影响的图像映射到无阴影图像。然后,它使用快速傅里叶注意力Transformer确保颜色和结构一致性。
-
HomoFormer: 是一个基于局部窗口的Transformer用于阴影去除,均匀化阴影退化。它使用随机打乱操作及其逆操作来重新排列像素,使局部自注意力层能够有效处理阴影并消除归纳偏差。新的深度卷积前馈网络增强了位置建模并利用了图像结构。
(iv) 基于扩散的方法有助于生成更具视觉吸引力的结果。
-
ShadowDiffusion(J): 使用分类器驱动的注意力进行阴影检测,使用DINO-ViT特征的结构保留损失进行重建,并使用色度一致性损失确保无阴影区域的颜色均匀。
-
ShadowDiffusion(G): 通过退化和扩散生成先验逐步优化输出,并增强阴影 mask 估计的准确性,作为扩散生成器的辅助方面。
-
DeS3: 使用自适应注意力和ViT相似性机制去除硬阴影、软阴影和自阴影。它采用DDIM作为生成模型,并利用自适应分类器驱动的注意力强调阴影区域,DINO-ViT损失作为推理过程中的停止准则。
-
Recasting: 包含两个阶段:阴影感知分解网络使用自监督正则化分离反射率和照明,双边校正网络使用局部照明校正模块调整阴影区域的照明。然后,使用照明引导的纹理恢复模块逐步恢复退化的纹理细节。
-
LFG-Diffusion: 训练一个扩散网络在无阴影图像上,以在潜在特征空间中学习无阴影先验。然后使用这些预训练的权重进行高效的阴影去除,最小化编码的无阴影图像和带有 mask 的阴影图像之间的不变损失,同时增强潜在噪声变量与扩散网络之间的交互。
-
Diff-Shadow: 是一个全球引导的扩散模型,具有并行的 U-Nets:一个用于局部噪声估计的分支和一个用于无阴影图像恢复的全局分支。它使用重新加权的交叉注意力和全球引导采样来探索非阴影区域的全局上下文,并确定补丁噪声的融合权重,保持光照一致性。
无监督学习
这类方法在训练深度网络时不使用成对的阴影和无阴影图像,因为这些图像难以获取。
-
Mask-ShadowGAN: 是第一个无监督阴影去除方法,它自动学习从输入阴影图像中生成阴影 mask ,并利用 mask 通过重新制定的循环一致性约束来指导阴影生成。该框架同时学习生成阴影 mask 和去除阴影。
-
PUL: 通过四个附加损失改进了 Mask-ShadowGAN: mask 损失(采样和生成 mask 之间的 差异)、颜色损失(平滑图像之间的均方误差)、内容损失(来自 VGG-16 的特征损失)和风格损失(VGG-16 特征的 Gram 矩阵)。
-
DC-ShadowNet: 使用阴影/无阴影域分类器处理阴影区域。它通过熵最小化在对数色度空间中训练一个基于物理的无阴影色度损失,以及使用预训练的 VGG-16 的阴影鲁棒感知特征损失、边界平滑损失和一些类似于 Mask-ShadowGAN 的附加损失。
-
LG-ShadowNet: 使用一个亮度引导网络改进了 Mask-ShadowGAN。在 Lab 颜色空间中,CNN 首先调整 L 通道中的亮度,然后另一个 CNN 使用这些特征在所有 Lab 通道中去除阴影。多层连接在双流架构中融合亮度和阴影去除特征。
-
SG-GAN+DBRM: 包含两个网络。(i) SG-GAN 基于 Mask-ShadowGAN,产生粗略的阴影去除结果和合成的成对数据,由使用 CLIP的多模态语义提示器引导文本语义。(ii) DBRM 是一个扩散模型,精细化粗略结果,该模型在真实无阴影图像和阴影去除图像上训练,去除前的阴影由 Mask-ShadowGAN 合成。
弱监督学习
这类方法仅使用阴影图像和阴影 mask 训练深度网络。阴影 mask 可以通过阴影检测方法预测。
-
Param+M+D-Net: 使用阴影分割 mask 作为监督在阴影图像上训练。它将图像划分为补丁,学习从阴影边界补丁到非阴影补丁的映射,并应用基于物理阴影形成模型的约束。
-
G2R-ShadowNet: 包含三个子网络:生成、去除和细化阴影。阴影生成网络在非阴影区域创建伪阴影,与非阴影区域形成训练对用于阴影去除网络。细化阶段确保颜色和光照一致性。阴影 mask 引导整个过程。
-
BCDiff: 是一个边界感知条件扩散模型。通过迭代维护反射率来增强无条件扩散模型,支持阴影不变的内在分解模型,以保留阴影区域内的结构。它还应用光照一致性约束以实现均匀照明。基础网络使用 Uformer。
单图像自监督学习
此任务通过在测试期间对图像本身进行训练来学习去除阴影,消除了对训练数据的需求。然而,阴影 mask 是必需的。
-
Self-ShadowGAN: 采用阴影重光网络作为阴影去除的生成器,由两个判别器支持。重光网络使用轻量级 MLPs 根据物理模型预测像素特定的阴影重光系数,参数由快速卷积网络确定。它还包括一个基于直方图的判别器,使用无阴影区域的直方图作为参考来恢复阴影区域的光照,以及一个基于补丁的判别器来提高去阴影区域的纹理质量。
文档阴影去除
去除文档中的阴影可以提高数字副本的视觉质量和可读性。一般的阴影去除方法在处理文档时面临挑战,因为需要大量配对数据集,并且缺乏对特定文档图像属性的考虑。下表9总结了用于此任务的深度模型。
-
BEDSR-Net: 是第一个专为文档图像阴影去除设计的深度网络。它由两个子网络组成:
-
BE-Net 估计全局背景颜色并生成注意力图。这些结果与输入阴影图像一起被 SR-Net 用来生成无阴影图像。
-
-
BGShadowNet: 利用来自颜色感知背景提取网络的背景进行阴影去除,采用两阶段过程。
-
第一阶段:融合背景和图像特征以生成逼真的初始结果。
-
第二阶段:使用基于背景的注意力模块校正光照和颜色不一致,并通过细节增强模块(受图像直方图均衡化启发)增强低级细节。
-
-
FSENet: 旨在通过首先将图像分割为低频和高频分量来实现高分辨率文档阴影去除。
-
低频部分 使用 Transformer 进行光照调整。
-
高频部分 使用级联聚合和膨胀卷积来增强像素并恢复纹理。
-
面部阴影去除
面部阴影去除涉及消除外部阴影、柔化面部阴影以及平衡光照。上表9总结了深度模型。这一主题与面部重光照相关,因为准确的阴影处理对实现照片级真实效果至关重要。此外,去除阴影还能提高面部特征点检测的鲁棒性。
-
Zhang 等人提出了第一个针对面部图像阴影去除的深度学习方法。该方法使用两个独立的深度模型:一个用于去除外部物体投射的外部阴影,另一个用于柔化面部阴影。这两个模型都基于修改后的GridNet。
-
He 等人提出了第一个无监督的面部阴影去除方法,将其框定为图像分解任务。该方法处理单个有阴影的肖像,生成无阴影图像、全阴影图像和阴影 mask ,使用预训练的面部生成器如StyleGAN2和面部分割 mask 。
-
GS+C通过将阴影去除分为灰度处理和上色来实现。阴影在灰度中被识别和去除,然后通过修补恢复颜色。为了在视频帧中保持一致性,它包含一个时间共享模块,解决姿势和表情变化。
-
Lyu 等人提出了一个两阶段模型,用于去除眼镜及其阴影。第一阶段使用跨域分割模块预测 mask ,第二阶段使用这些 mask 指导去阴影和去眼镜网络。该模型在合成数据上训练,并使用域适应网络处理真实图像。
-
GraphFFNet是一个基于图的特征融合网络,用于去除面部图像中的阴影。它使用多尺度编码器提取局部特征,图像翻转器利用面部对称性生成粗略的无阴影图像,并使用基于图的卷积编码器识别全局关系。特征调制模块结合这些全局和局部特征,融合解码器生成无阴影图像。
用于视频阴影去除的深度模型
PSTNet 是一种用于视频阴影去除的方法,结合了物理、空间和时间特征,并通过无阴影图像和 mask 进行监督。它使用物理分支进行自适应曝光和监督注意力,空间和时间分支则用于提高分辨率和连贯性。特征融合模块用于优化输出,S2R策略使得在不重新训练的情况下,将合成数据上训练的模型适应于真实世界的应用。
GS+C 是一种用于视频中面部阴影去除的方法。
阴影去除数据集
通用图像阴影去除数据集
-
SRD: 是第一个大规模的阴影去除数据集,包含 3,088 对阴影和无阴影的图像。该数据集的多样性涵盖四个维度:光照(硬阴影和软阴影)、广泛的场景(从公园到海滩)、在不同物体上投射阴影的反射率变化,以及使用不同形状的遮挡物产生的多样轮廓和半影宽度。SRD 的阴影 mask 由 Recasting 重新标注。
-
ISTD和 ISTD+: 两者都包含阴影图像、无阴影图像和阴影 mask ,具有 1,330 张训练图像和 540 张来自 135 个独特背景场景的测试图像。ISTD 存在阴影和无阴影图像之间的颜色和亮度不一致问题,ISTD+ 通过颜色补偿机制修正了这一问题,以确保在真实图像中像素颜色的一致性。
-
GTAV: 是一个合成数据集,包含 5,723 对阴影和无阴影图像。这些场景由 Rockstar 的电子游戏 GTAV 渲染,描绘了两种版本的真实世界场景:有阴影和无阴影。它包括 5,110 个标准日光场景和额外的 613 个室内和夜间场景。
-
USR: 旨在用于无配对阴影去除任务,包含 2,511 张带阴影图像和 1,772 张无阴影图像。该数据集涵盖了多种场景,展示了由各种物体投射的阴影。它跨越了超过一千个独特场景,为阴影去除技术的研究提供了丰富的多样性。
-
SFHQ: Shadow Food-HQ,包含 14,520 张高分辨率食物图像(12MP),并附有标注的阴影 mask 。它包括在各种光照和视角下的多样场景,分为 14,000 个训练和 520 个测试三元组。
-
WSRD: 在一个受控的室内环境中创建,具有定向和漫射光照。它包含 1,200 对高分辨率(1920x1440)图像:1,000 张用于训练,100 张用于验证,100 张用于测试。该数据集包括各种颜色、纹理和几何形状的表面,以及不同厚度、高度、深度和材料(包括不透明、半透明和透明类型)的物体。它被 19 个团队用于 NTIRE23 图像阴影去除挑战。
通用视频阴影去除数据集
-
SBU-Timelapse: 是一个视频阴影去除数据集,包含50个静态场景视频,主要特征是只有阴影移动,没有物体移动。每个视频使用“max-min”技术生成一个伪无阴影帧。
-
SVSRD-85: 是一个来自 GTAV 的合成视频阴影去除数据集,包含85个视频,共4,250帧。通过切换阴影渲染器收集,涵盖了各种对象类别和运动/光照条件,每帧都配有无阴影图像。
文档阴影去除数据集
-
SDSRD:这是一个用 Blender 创建的合成数据集,包含970张文档图像和8,309张在不同光照和遮挡条件下合成的阴影图像。数据集有7,533个训练三元组和776个测试三元组。
-
RDSRD:这是一个通过相机捕获的真实数据集,包含540张图像,涉及25个文档,包括阴影图像、无阴影图像和阴影 mask 。该数据集仅用于评估。
-
RDD:使用了文档背景如纸张、书籍和小册子。包含4,916对图像,每对图像分别在有阴影和无阴影的情况下拍摄,通过放置和移除遮挡物获得。其中4,371对用于训练,545对用于测试。
-
SD7K:包含7,620对高分辨率的真实世界文档图像,有阴影和无阴影版本,并附有标注的阴影 mask 。涵盖各种文档类型(如漫画、纸张、图表),使用了30多种遮挡物和350多份文档,在三种光照条件(冷光、暖光和日光)下拍摄。
Facial Shadow Removal Datasets
-
UCB: 包含合成的外部和面部阴影。外部阴影是通过在一个包含5,000张没有外部阴影的人脸数据集上,使用阴影蒙版混合明亮和阴影图像创建的;然而,眼镜阴影被视为固有的。面部阴影是通过对85名受试者进行Light Stage 扫描生成的,涵盖各种表情和姿势,使用加权的一次一光组合。
-
SFW: 是为真实环境中的面部阴影去除而组装的,包含来自20名受试者的280个视频,大多数视频以1080p分辨率录制。提供了各种阴影蒙版的标签,如投射阴影、自身阴影、明亮或饱和的面部区域,以及眼镜,共440帧。
-
PSE: ,即带眼镜的肖像合成,是通过3D渲染生成的合成数据集。它通过节点注册模拟3D眼镜在面部扫描上的效果,并在各种光照条件下渲染,生成四种带有蒙版的图像类型。在438个身份中,选择了73个,每个都有20个表情扫描,配有五种眼镜样式和四种HDR照明条件,生成了29,200个训练样本。
Evaluation Metrics
-
RMSE在LAB色彩空间中计算出地面真实无阴影图像与恢复图像之间的均方根误差,确保局部感知的一致性。
-
LPIPS(Learned Perceptual Image Patch Similarity)评估图像块之间的感知距离,得分越高表示相似性越低,反之亦然。本文采用VGG作为LPIPS中的特征提取器。
SSIM(结构相似性指数)和PSNR(峰值信噪比)有时用于评估。
实验结果
一般图像阴影去除
整体性能基准测试结果。 采用了两个广泛使用的数据集,SRD 和 ISTD+,来评估阴影去除方法的性能。比较的方法列在下表10中,本文排除了那些代码不可用的方法。使用原始代码重新训练了比较的方法,输入尺寸设置为 和 ,以在两个分辨率下报告结果。
对于 DSC,本文将代码从 Caffe 转换为 PyTorch,并使用 ResNeXt101 作为主干网络。ShadowDiffusion(G)使用了预训练的 Uformer权重进行 ISTD+ 推理。对于需要阴影 mask 作为输入的方法,与之前一些在训练期间使用预测阴影 mask 的方法不同,本文在 SRD 和 ISTD+ 中采用了标注良好的 mask 。与某些依赖于推理期间的真实 mask 的方法不同(可能导致数据泄漏),本文使用由 SDDNet 检测器生成的阴影 mask 。该检测器在 分辨率的 SBU 数据集上训练,显示出卓越的泛化能力,如上表3所示。使用的评估指标包括 RMSE、PSNR、SSIM 和 LPIPS。结果被调整为与真实分辨率匹配,以便进行公平比较。一些调整真实图像尺寸的论文是错误的,因为这会扭曲细节,导致对图像质量的评估偏差且不准确。上表10和下图2总结了每种方法的准确性、运行时间和模型复杂性。关键见解包括:
-
(i)早期方法如 DSC 和 ST-CGAN 在多个评估指标上优于后来的方法;
-
(ii)无监督方法在 SRD 和 ISTD+ 上表现出与有监督方法相当的性能,可能是因为训练集和测试集中的背景纹理相似,其中 Mask-ShadowGAN 在效果和效率之间提供了最佳平衡;
-
(iii)较小的模型如 BMNet (0.58M) 提供了具有竞争力的性能,而没有显著增加模型大小;
-
(iv)大多数方法在更高分辨率(如 )下显示出改进的结果。
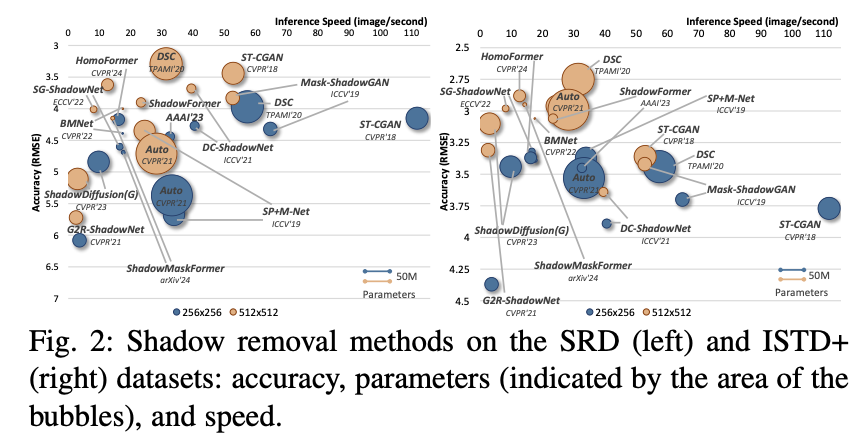
跨数据集泛化评估。 为了评估阴影去除方法的泛化能力,本文使用在 SRD 训练集上训练的模型进行跨数据集评估,以检测 DESOBA训练和测试集上的阴影。两个数据集都包含户外场景,但 SRD 缺乏投射阴影的遮挡物,而 DESOBA 则呈现出更复杂的环境。这标志着首次在如此具有挑战性的数据集上进行的大规模泛化评估。请注意,DESOBA 仅标记投射阴影,本文在评估中将物体上的自阴影设为“不关心”。SSIM 和 LPIPS 被排除,因为 SSIM 依赖于图像窗口,LPIPS 使用网络激活,这两者都与“不关心”政策相冲突。上表10中最右边的两列显示,在像 SRD 和 ISTD+ 这样的受控数据集上表现良好的模型在 DESOBA 的更复杂环境中表现不佳。这是因为 SRD 主要特征是简单、局部场景中的投射阴影,阴影较软且无遮挡物,而 DESOBA 则呈现出更复杂的场景,具有更硬的阴影和遮挡。这突出了需要多样化的训练数据和更能适应处理现实世界阴影场景的模型。
总结 实验结果表明,如何开发一个稳健的模型并准备一个具有代表性的数据集,以在复杂场景中实现高性能的图像阴影去除,仍然是一个具有挑战性的问题。
文档阴影去除
RDD 数据集用于训练和评估文档阴影去除方法,输入尺寸为 。结果如下表 11 所示,本文观察到 FSENet 在准确性和效率上显著优于 BEDSR-Net,使其在所有指标上成为更好的方法。
阴影生成
阴影生成主要有三个目的:
-
(i)图像合成,涉及为照片中的物体生成投影阴影,以便能够插入或重新定位照片中的物体;
-
(ii)数据增强,旨在在图像中创建投影阴影,以生成逼真的图像来支持深度神经网络的训练;
-
(iii)素描,专注于为手绘草图生成阴影,以加速绘图过程。
图像阴影生成的深度模型
图像合成的阴影生成
-
ShadowGAN: 使用生成对抗网络(GAN)为图像中的虚拟物体生成逼真的阴影。它具有一个生成器和双鉴别器,确保阴影的形状和场景的整体光照相协调。
-
ARshadowGAN: 是一种GAN模型,在单光源条件下为增强现实中的虚拟物体添加阴影。它使用注意力机制,通过建模虚拟物体阴影与现实世界对手之间的关系来简化阴影生成,无需估计光照或3D几何。
-
SSN: 提供了一个实时交互系统,使用二维物体遮罩在照片中创建可控的柔和阴影。它使用动态阴影生成和环境光照图来训练其网络,生成多样化的柔和阴影数据。同时,它预测环境遮挡以增强真实性。
-
SSG: 引入了像素高度,一种新的几何表示法,可以在图像合成中精确控制阴影的方向和形状。该方法使用投影几何进行硬阴影计算,并包括一个训练过的U-Net来为阴影添加柔和效果。
-
SGRNet: 是一个两阶段网络,首先通过合并前景和背景的生成器创建阴影遮罩,然后预测阴影参数并填充阴影区域,生成具有逼真阴影的图像。
-
Liu 等人 通过多尺度特征增强和多层次特征融合来增强图像合成中的阴影生成。该方法提高了遮罩预测的准确性,并在阴影参数预测中最大限度地减少信息损失,从而增强了阴影的形状和范围。
-
PixHt-Lab: 将像素高度映射到三维空间,以创建逼真的光照效果,如阴影和反射。它通过重建剪切物体和背景的3D几何,使用3D感知缓冲通道和神经渲染器来克服传统2D限制,提高柔和阴影的质量。
-
HAU-Net & IFNet: 由两个组件组成:层次注意力U-Net(HAU-Net)用于推断背景光照并预测前景物体的阴影形状;以及光照感知融合网络(IFNet),使用增强的光照模型融合曝光不足的阴影区域,创造出更自然的阴影。
-
Valença 等人通过解决真实地面阴影与投影到虚拟实体的交互来增强照片编辑时的阴影整合。其生成器从虚拟阴影和场景图像创建阴影增益图和阴影遮罩,然后通过光照和相机参数进行后处理,实现无缝整合。
-
DMASNet: 是一种两阶段方法,用于生成逼真的阴影。第一阶段将任务分解为盒子和形状预测,以形成初始阴影遮罩,然后进行细化以增强细节。第二阶段专注于填充阴影,调整局部光照变化以与背景无缝融合。
-
SGDiffusion: 使用稳定扩散模型,结合自然阴影图像的知识,克服与精确阴影形状和强度生成相关的困难。具体来说,它通过ControlNet适配和强度调制模块增强阴影强度。
用于阴影消除的阴影生成
请参见前文中Mask-ShadowGAN、Shadow Matting GAN和G2R-ShadowNet。
草图的阴影生成
-
郑等人利用指定的光照方向,从手绘草图中创建详细的艺术阴影。他们在潜在空间中构建了一个3D模型,并渲染与草图线条和3D结构对齐的阴影,包括自阴影和边缘光等艺术效果。
-
SmartShadow为数字艺术家提供了三个工具来为线条画添加阴影:用于初始放置的阴影笔刷、用于边缘精确控制的阴影边界笔刷,以及用于保持阴影方向一致的全局阴影生成器。通过卷积神经网络(CNN),它可以根据草图输入和用户指导预测全局阴影方向和阴影图。
影子生成数据集
用于图像合成的阴影生成数据集
-
Shadow-AR: 是一个合成数据集,包含3,000个五元组,每个五元组包括一个带有和不带有渲染阴影的合成图像、一个合成物体的二值 mask 、一个标注的真实世界阴影抠图及其相关的标注遮挡物。
-
DESOBA: 是一个基于真实世界图像的合成数据集,源自SOBA。阴影被去除以作为阴影生成的真实值。它包含840张训练图像和2,999对阴影-物体对,以及160张测试图像和624对阴影-物体对。
-
RdSOBA: 是使用Unity游戏引擎创建的合成数据集。它包含30个3D场景和800个物体,总计114,350张图像和28,000对阴影-物体对。
-
DESOBAv2: 是一个利用实例阴影检测方法和修复方法构建的大型数据集。它包含21,575张图像和28,573个阴影-物体关联。
草图阴影生成数据集
SmartShadow 提供了真实和合成数据,包括:
-
1,670 对由艺术家创作的线条艺术和阴影。
-
25,413 对由渲染引擎合成的阴影。
-
291,951 对从互联网上的数字绘画中提取的阴影。
讨论
不同的方法由于其独特的模型设计和应用,需要特定的训练数据。例如,SGRNet 需要前景阴影 mask 和目标阴影图像用于图像合成。相比之下,Mask-ShadowGAN 只需要未配对的阴影和无阴影图像用于阴影去除。ARShadowGAN 使用真实阴影及其遮挡物的二值图进行训练,以生成增强现实中的虚拟对象阴影。SmartShadow 利用艺术家提供的线条画和阴影对来训练深度网络,以在线条画上生成阴影。由于篇幅限制,本文建议读者探索每个应用的结果,以了解方法的有效性和适用性。
然而,目前的阴影生成方法主要集中在图像中的单个对象上,如何为视频中的多个对象生成一致的阴影仍然是一个挑战。此外,除了为缺乏阴影的对象生成阴影之外,通过调整光照方向来编辑各种对象的阴影提供了更多实际应用。
结论 & 未来方向
总结而言,本论文通过调查一百多种方法并标准化实验设置,推进了深度学习时代的阴影检测、去除和生成研究。本文探索了模型大小、速度和性能之间的关系,并通过跨数据集研究评估了模型的鲁棒性。以下,本文进一步提出了开放问题和未来研究方向,强调AIGC和大模型对该领域学术研究和实际应用的推动作用。
一个集成阴影和物体检测、去除及生成的全能模型是一个有前景的研究方向。目前大多数方法专注于某一特定任务——阴影的检测、去除或生成。然而,所有与阴影相关的任务本质上是相关的,可以从共享的见解中受益,特别是考虑到物体与其阴影之间的几何关系。开发一个统一的模型可以揭示底层关系,并最大化训练数据的使用,从而增强模型的泛化能力。
在阴影分析中,物体的语义和几何特征仍未被充分探索。现代大型视觉和视觉语言模型,配备了大量的网络参数和庞大的训练数据集,在分析图像和视频中的语义和几何信息方面表现出色,且具备显著的零样本能力。例如,Segment Anything提供像素级分割标签;Depth Anything估计任何图像输入的深度;ChatGPT-4o预测图像和视频帧的叙述。利用这些语义和几何见解进行阴影感知,可以显著增强阴影分析和编辑,甚至有助于分离重叠阴影。
阴影-物体关系有助于执行各种图像和视频编辑任务。实例阴影检测生成物体和阴影实例的 mask,促进了如图像修复、实例克隆和阴影修改等编辑任务。例如,通过实例阴影检测分析观察到的物体及其阴影,以估计未观察到物体的布局,实现图像扩展。将这些应用整合到手机中进行照片和视频编辑既简单又有益。鉴于现代手机配备了多个摄像头和高动态范围,探索如何利用这些摄像头进行增强的阴影-物体编辑是一个新颖的研究方向。
阴影是区分AI生成视觉内容与真实内容的有效手段。AI生成内容(AIGC)的最新进展使得多样化的图像和视频创作成为可能。然而,这些AI生成的内容常常忽视几何方面,导致阴影属性上的差异,破坏了3D感知。实例阴影检测被用于分析物体-阴影关系,当光源对齐和物体几何不一致时,揭示图像的合成性质。AI生成的视频(例如,Sora3)也需要遵循3D几何关系。因此,探索未来研究方向,关注AI生成内容中的阴影一致性,并评估或定位潜在的不一致性,既重要又有趣。此外,阴影是一种自然且隐蔽的对抗攻击,可以破坏机器学习模型。
参考文献
[1]Unveiling Deep Shadows: A Survey on Image and Video Shadow Detection, Removal, and Generation in the Era of Deep Learning
更多精彩内容,请关注公众号:AI生成未来