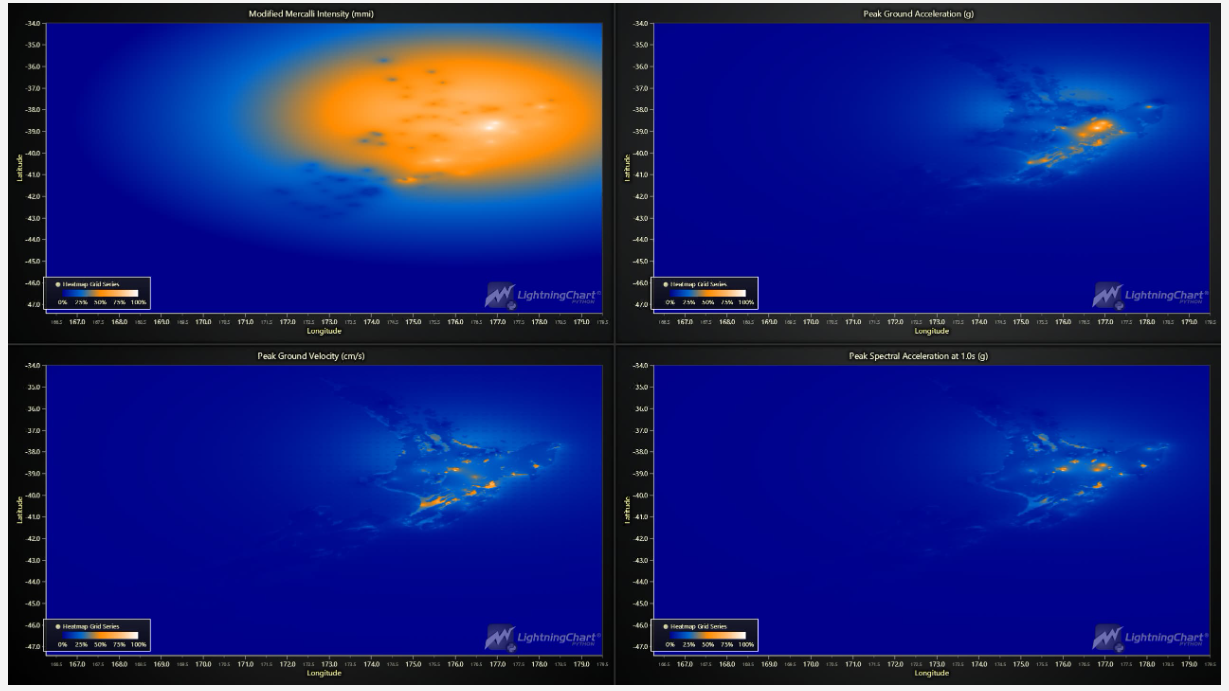
【深度学习发展史】张量与神经网络|生成模型|序列学习模型|深度强化学习是如何一步步发展的?
【深度学习发展史】张量与神经网络|生成模型|序列学习模型|深度强化学习是如何一步步发展的?
文章目录
- 【深度学习发展史】张量与神经网络|生成模型|序列学习模型|深度强化学习是如何一步步发展的?
- 前言
- 1.张量与神经网络的起源
- 2.生成模型的发展
- 3.序列学习的发展
- 4.深度强化学习的发展
- 总结
前言
深度学习作为人工智能的一个分支,经历了数十年的发展,形成了如今广泛应用的体系。以下内容将从四个关键方面详细介绍深度学习的发展历程,并结合一些里程碑式的研究与成果加以说明。
深度学习的发展史主要参考唐杰老师的学生整理的一个博文,并结合自己的理解补充。欢迎大家批评指正!
参考链接:
https://weibo.com/2126427211/GavUQjfLa?type=comment#_rnd1543322198481
1.张量与神经网络的起源
-
1958年,Frank Rosenblatt 提出了感知器(Perceptron),这是最早的神经网络模型之一,能够实现二元分类任务。然而,由于当时的计算能力不足,感知器在处理复杂任务时表现受限,尤其在多层神经网络的训练上出现瓶颈,导致这类网络的发展陷入停滞。
-
1979年,Kunihiko Fukushima 提出了Neocognitron,它被认为是卷积神经网络(CNN)的雏形。这一模型引入了卷积和池化的概念,用于提取图像中的局部特征,对后来的图像识别有重要影响。
-
1986年,Geoffrey Hinton 提出了反向传播算法(Backpropagation),这是神经网络训练的一次革命性突破。Hinton的工作使得多层神经网络(即多层感知器,MLP)可以通过梯度下降进行有效训练,推动了深度学习的发展。反向传播算法成为深度学习的核心基础之一,直到今天仍在广泛使用。
-
1998年,Yann LeCun 提出了LeNet-5,这是一个7层的卷积神经网络,用于手写数字识别(MNIST 数据集)。LeNet-5 的提出标志着卷积神经网络(CNN)开始进入实用阶段,成为处理图像数据的主要工具之一。
-
2012年,AlexNet 在 ImageNet 大赛上取得突破,显著提升了图像识别的准确性。AlexNet 的成功归功于使用了更深的网络结构、ReLU 激活函数和 Dropout 正则化技术,以及当时强大的 GPU 算力。AlexNet 的成功使得深度学习在计算机视觉领域的应用广泛普及。
-
2015年,Google 的团队提出了 GoogLeNet 和 Inception 模型,进一步优化了网络的深度和计算效率。
-
2016年,华人学者何恺明提出了ResNet(残差网络),通过引入残差结构,成功解决了深层网络中的梯度消失问题,推动了超深神经网络的发展。ResNet 也是卷积神经网络在各类竞赛和应用中广泛使用的重要模型。
-
2017年,何恺明的团队又提出了DenseNet,这种网络通过密集连接将每一层的输出直接传递到所有后续层,进一步提高了网络的学习效率和特征复用能力。
2.生成模型的发展
-
20世纪80年代,Hinton 提出了受限玻尔兹曼机(RBM),用于无监督学习。2006年,RBM 被叠加成深度信念网络(DBN),这标志着叠加网络的一个重要开端。DBN 可以逐层训练,解决了深层网络训练中的梯度消失问题。
-
1980年代,Autoencoder(自编码器) 作为一种无监督学习方法被提出。Autoencoder 用于降维和特征提取,后来被广泛应用于生成模型。
-
2008年,Yoshua Bengio 提出了去噪自编码器(Denoising Autoencoder),在自编码器的基础上增强了网络的鲁棒性。
-
2013年,Kingma 和 Welling 提出了变分自编码器(VAE),这是一种生成模型,能够对数据进行概率建模。
-
2014年,Ian Goodfellow 和 Bengio 等提出了生成对抗网络(GAN),这是生成模型的一个革命性发展。GAN 由生成器和判别器组成,通过博弈论的方式训练,能够生成逼真的数据。GAN 的提出极大地推动了生成模型的研究,使得该领域迅速成为热门。随后,出现了许多 GAN 的变种模型,包括DCGAN、CGAN、WGAN 等。
3.序列学习的发展
-
1982年,Hopfield 网络被提出,用于处理时间序列数据。这是序列学习的早期模型。
-
1997年,Sepp Hochreiter 和 Jürgen Schmidhuber 提出了长短期记忆网络(LSTM),LSTM 能够有效地捕捉序列中的长期依赖,解决了传统 RNN 中梯度消失的问题。LSTM 广泛应用于语音识别、机器翻译等序列任务。
-
2013年,Hinton 的团队将RNN 和 LSTM 应用于语音识别,取得了显著的突破,极大地推动了序列学习的发展。
-
2003年,语言模型(LM)开始逐步成熟,2013年,Mikolov 提出了Word2Vec,引入了词向量的概念,为自然语言处理领域的研究奠定了基础。
-
随后,Glove、FastText 等词向量模型相继出现,并不断提升 NLP 任务的表现。
-
2018年,基于Transformer架构的预训练模型BERT横空出世,成为 NLP 领域的重要突破。BERT 能够在多个 NLP 任务中取得最佳效果,并改变了 NLP 的主流方法。
4.深度强化学习的发展
-
2013年,Google 的 DeepMind 团队提出了Deep Q-Learning(深度 Q 学习),将深度学习引入强化学习,取得了良好的表现。该方法在 Atari 游戏中展现了极高的智能水平,成为深度强化学习的里程碑。
-
2015年,Double DQN 提出,进一步提高了 Q-learning 的稳定性。
-
2016年,DeepMind 提出了AlphaGo,通过结合深度学习和蒙特卡洛树搜索,成功击败了人类围棋冠军。AlphaGo 的成功极大地提升了公众对 AI 的关注度,并推动了深度强化学习的快速发展。
-
2017年,AlphaGo Zero 推出,这一版本的 AlphaGo 不再依赖人类数据,通过自我对弈进行训练,展现了 AI 自我学习的潜力。
总结
深度学习从最早的神经网络模型逐步演化为今天的多层网络、生成模型、序列学习和强化学习系统。
在过去的几十年中,得益于反向传播算法、卷积神经网络、生成对抗网络、LSTM 和 AlphaGo 等一系列突破性成果,深度学习已被广泛应用于图像识别、自然语言处理、游戏智能体、医疗诊断等众多领域。
未来,随着计算资源的不断提升和算法的持续优化,深度学习将继续在更多领域展现其巨大的潜力。


![[PICO VR]Unity如何往PICO VR眼镜里写持久化数据txt/json文本](https://i-blog.csdnimg.cn/direct/b11d7ed2d1f94ea79daf1eb8c2377184.png)