文章目录
- 1. 前言
- 1. 1 丹摩智算平台
- 1.2 经典目标检测模型 Faster-Rcnn
- 2. 前置准备
- 2.1 WindTerm(远程连接服务器)
- 2.2 项目源码
- 3. 服务器平台配置
- 3.1 创建实例
- 3.2 远程链接
- 4. Faster-rcnn 的环境配置
- 4.1 上传文件,解压
- 4.2 安装所需环境
- 5. 数据集简介
- 6. 开始训练
- 7. 测试数据保存
- 8. 训练结果导出
- 9. 结语
1. 前言
1. 1 丹摩智算平台
DAMODEL(丹摩智算)是专为 AI 打造的智算云,致力于提供丰富的算力资源与基础设施助力 AI 应用的开发、训练、部署。
平台特点:
- 💡 超友好!配备 124G 大内存和 100G 大空间系统盘,一键部署,三秒启动,让 AI 开发从未如此简单!
- 💡 资源多!从入门级到专业级 GPU 全覆盖,无论初级开发还是高阶应用,你的需求,我们统统 Cover!
- 💡 性能强!自建 IDC,全新 GPU,每一位开发者都能体验到顶级的计算性能和专属服务,大平台值得信赖!
- 💡 超实惠!超低价格体验优质算力服务,注册即送优惠券!还有各类社区优惠活动,羊毛薅不停!
1.2 经典目标检测模型 Faster-Rcnn
Faster RCNN是two-stage目标检测模型中的典型代表,已经是多年的老模型
Fast R-CNN的工作流程是先通过选择性搜索(Selective Search)算法等方法生成候选框,这些候选框作为可能包含目标的区域。接着,整个图像与其对应的候选框一起输入到CNN中。CNN在前向传播过程中同时完成了特征提取、边界框分类和边界框回归三个任务。通过将这三个任务融合到同一个CNN中,Fast R-CNN大大提高了目标检测的效率和准确性,不再需要对每个候选框单独进行特征提取和分类,从而加快了检测速度。
fast-RCNN算法的3个步骤:
1.一张图像生成1K~2K个候选区域(使用Selective Search方法)
2.将图像输入网络得到相应的特征图,将SS算法生成的候选框投影到特征图上获得相应的特征矩阵
3.将每个特征矩阵通过ROI pooling层缩放到7x7大小的特征图,接着将特征图展平通过一系列全连接层得到预测结果
2. 前置准备
2.1 WindTerm(远程连接服务器)
WindTerm SSH工具,服务器管理,远程桌面加速软件,支持Windows,macOS,Linux - WindTerm官网
2.2 项目源码
下载地址:点击下载源码
3. 服务器平台配置
这里服务器平台我选择的是丹摩智算的平台,大家可以注册使用体验一下 丹摩智算平台
3.1 创建实例
- 创建实例,选择 4090 显卡,并且下载私钥
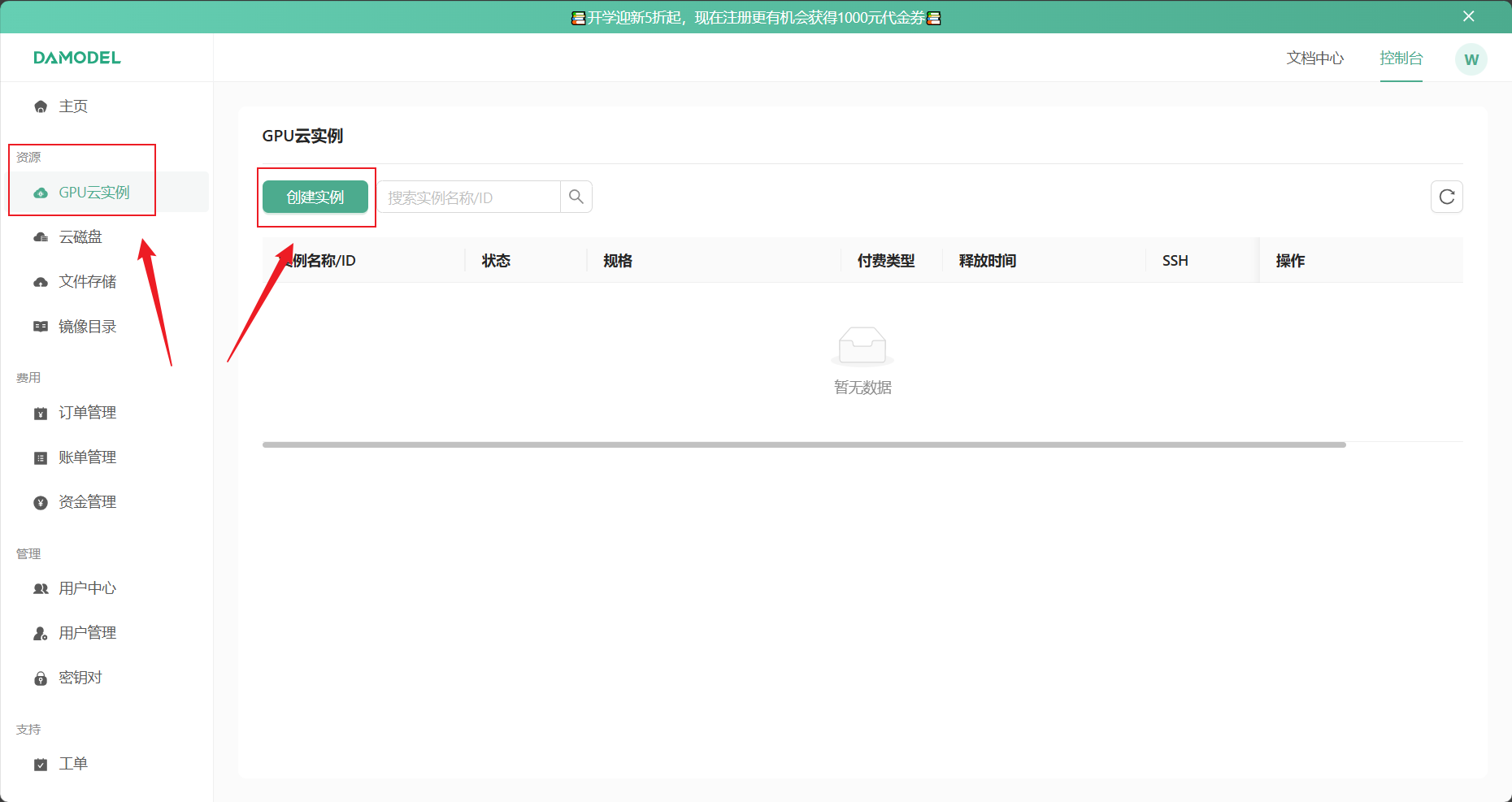
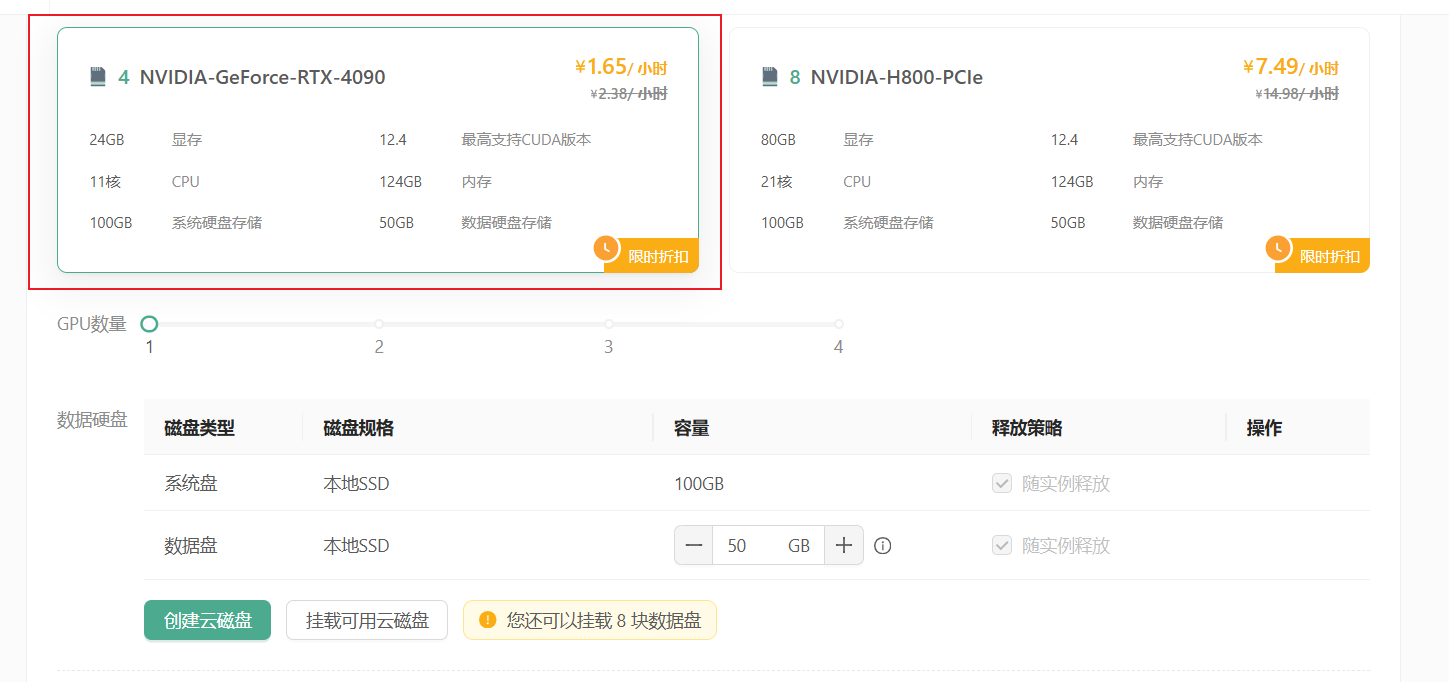
选择4090显卡,24g显存,124g内存,磁盘150g即可
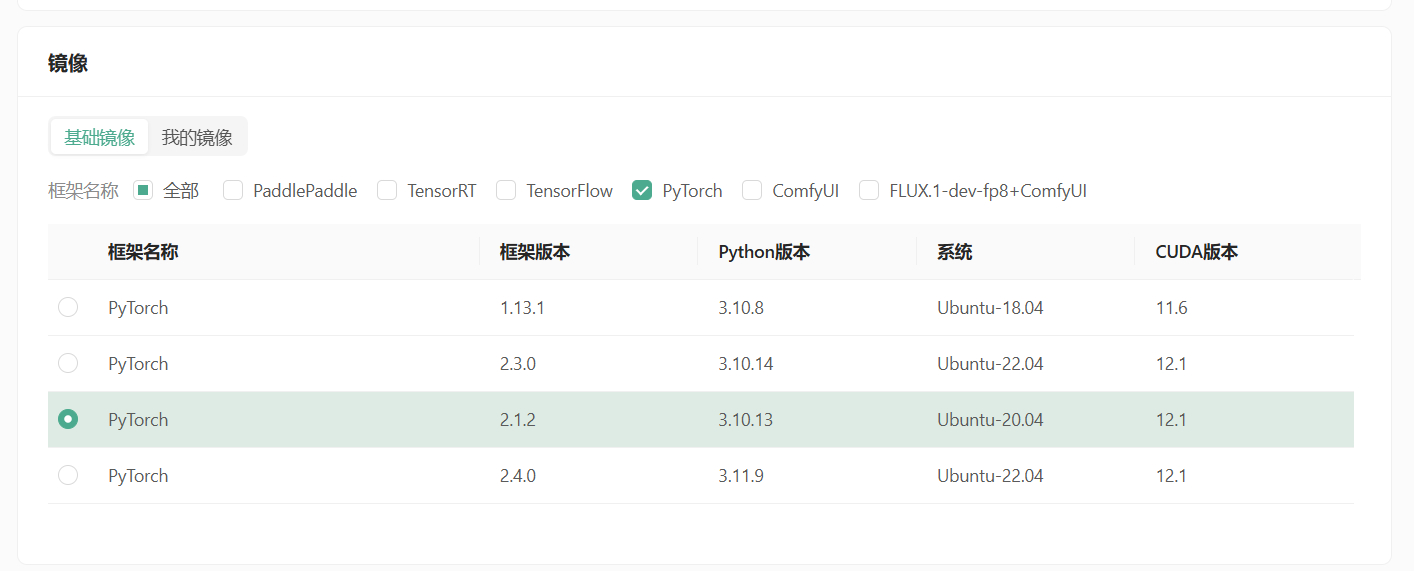
- 镜像选择:pytorch 2.1.2,python 3.10
- 创建密钥对
密钥对创建后记得保存文件,用于后续免密链接登录,也可以不记录
- 完成创建
完善相关配置后,点击创建,等待创建完成
3.2 远程链接
- 复制访问链接
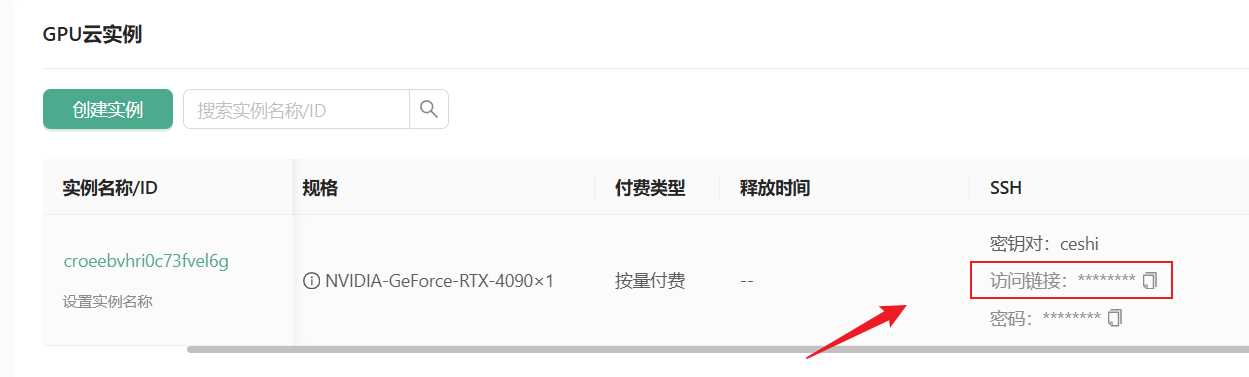
ssh -p 42894 root@cn-north-b.ssh.damodel.com
HFyoNrTei9
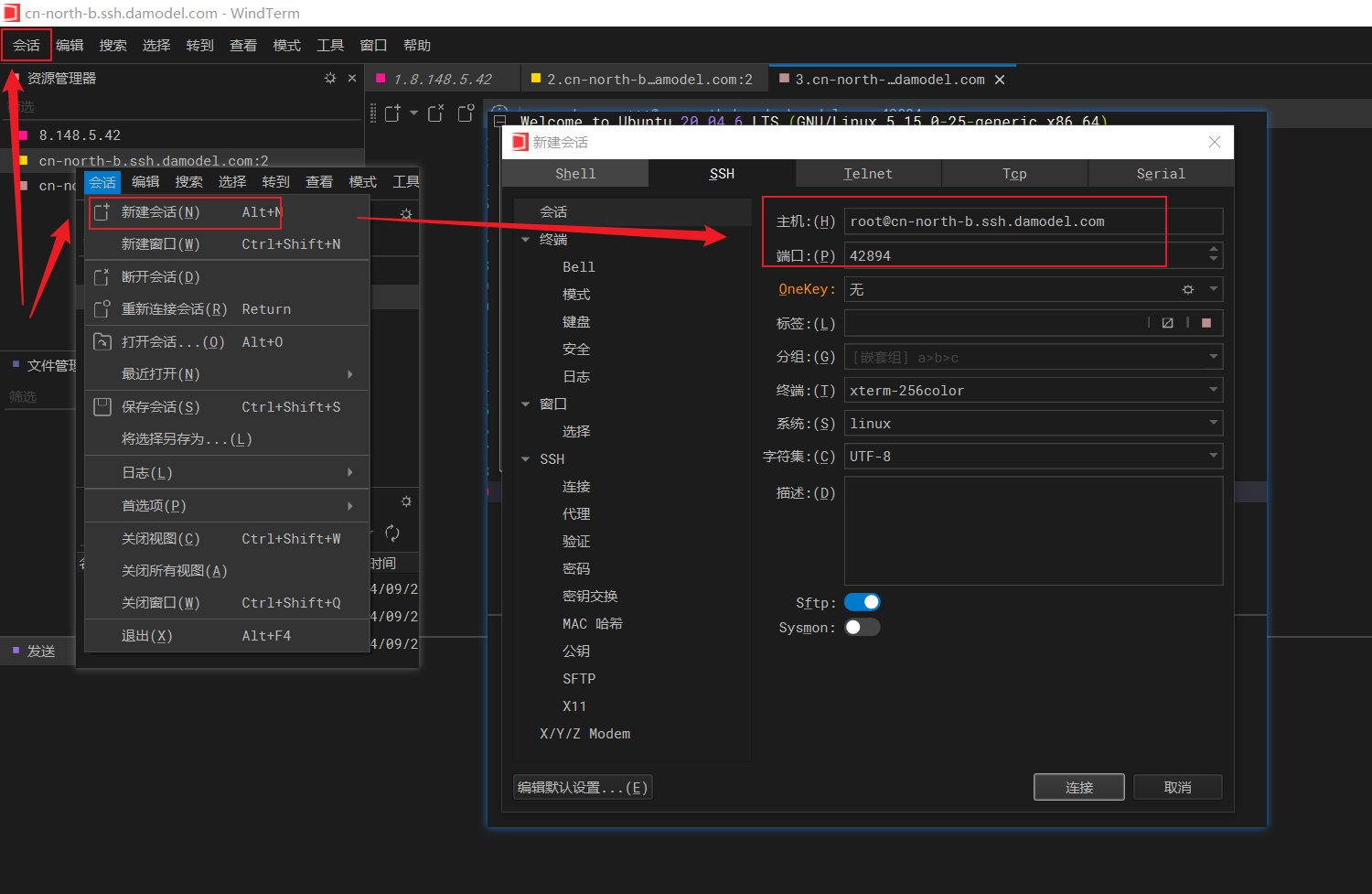
- WindTerm链接
回话-新建回话-根据链接完善主机,端口-输入密码
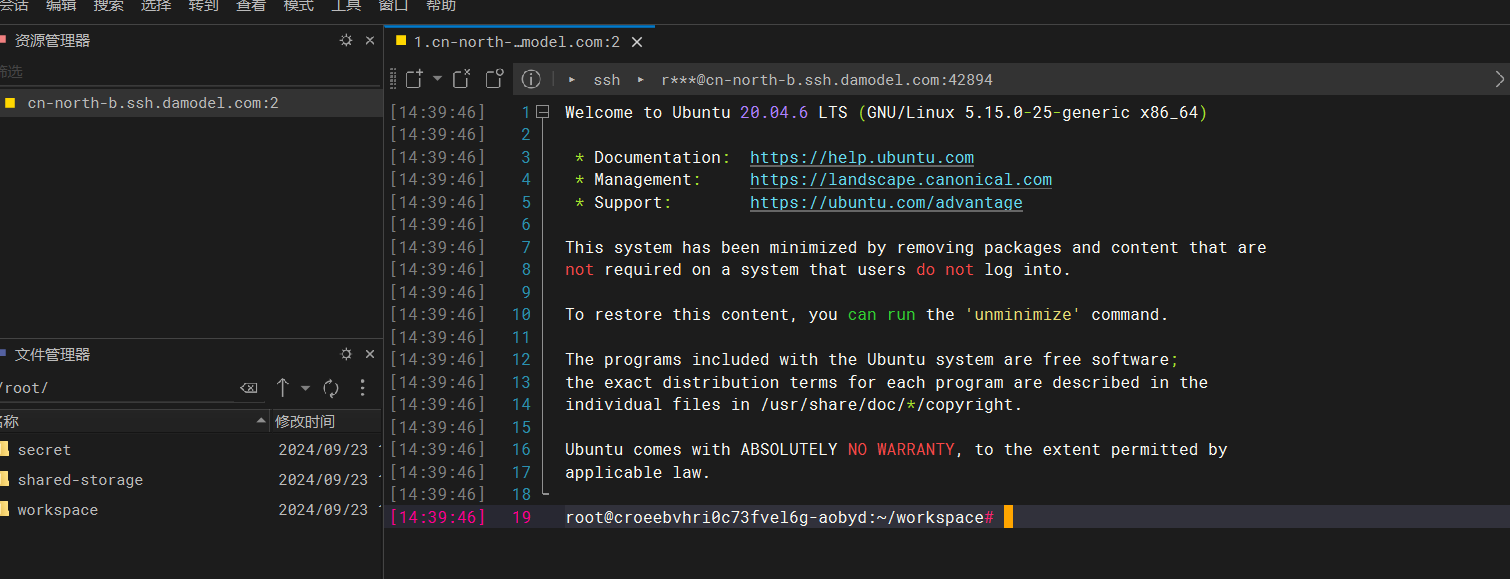
- 连接成功
显示如下界面我们就成功了!
4. Faster-rcnn 的环境配置
4.1 上传文件,解压
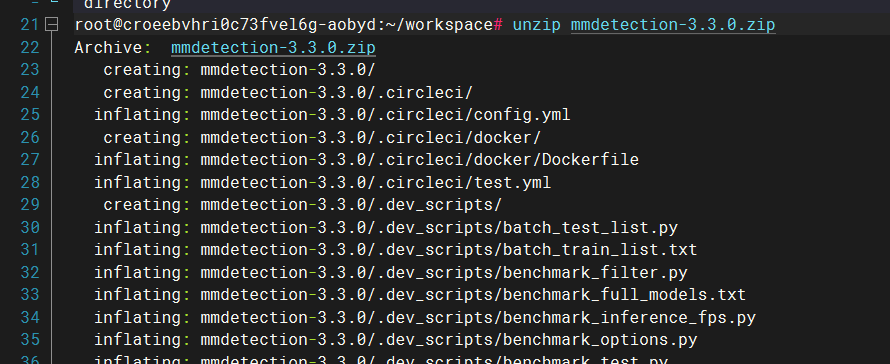
将我们的代码文件拖入/root/workspace/目录下,然后解压
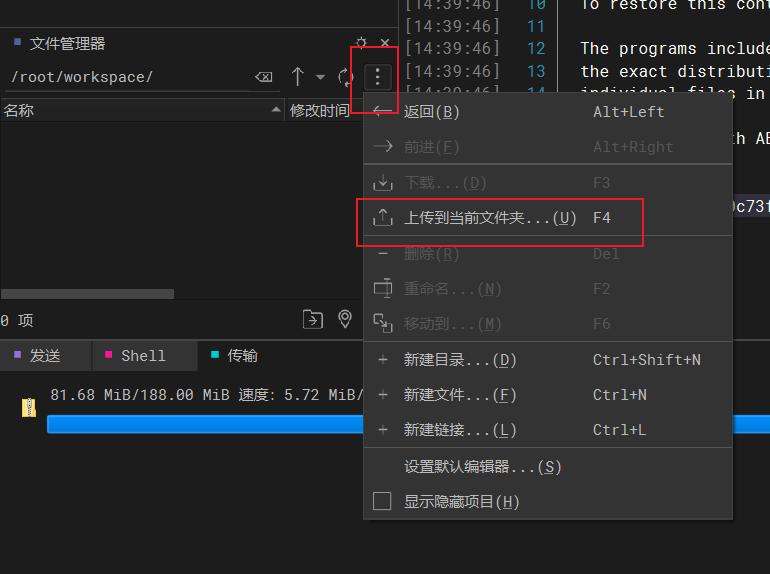
解压文件
unzip mmdetection-3.3.0.zip
4.2 安装所需环境
# 安装mmcv包
pip install mmcv==2.1.0 -f https://download.openmmlab.com/mmcv/dist/cu121/torch2.1/index.html -i https://mirrors.aliyun.com/pypi/simple/# 从源码安装mmdetection-3.3.0
cd mmdetection-3.3.0
pip install -r requirements/build.txt -i https://pypi.tuna.tsinghua.edu.cn/simple/
pip install -v -e ./ -i https://pypi.tuna.tsinghua.edu.cn/simple/# 安装必要包
pip install numpy==1.24.4 -i https://pypi.tuna.tsinghua.edu.cn/simple/
pip install setuptools==69.5.1 -i https://pypi.tuna.tsinghua.edu.cn/simple/
pip install instaboostfast -i https://pypi.tuna.tsinghua.edu.cn/simple/# 安装全景分割依赖panopticapi
cd panopticapi
pip install -e . -i https://pypi.tuna.tsinghua.edu.cn/simple/
cd ..# 安装 LVIS 数据集依赖
cd lvis-api
pip install -e . -i https://pypi.tuna.tsinghua.edu.cn/simple/
cd ..# 安装 albumentations 依赖
pip install -r requirements/albu.txt -i https://pypi.tuna.tsinghua.edu.cn/simple/
pip install mmengine -i https://pypi.tuna.tsinghua.edu.cn/simple/
逐个处理,保证环境配置正确
环境安装完成,简单测试
python 1.py

5. 数据集简介
COCOmini 数据集是一个用于各种计算机视觉任务的数据集,包括但不限于目标检测、实例分割、关键点检测、和图像分类。
特点与组成部分:
- 多标签:不同于单一标签的数据集,COCO 中的图像通常包含多个不同的对象类别,这使得它非常适合上下文理解的研究。
- 多样性和复杂性:图像涵盖了广泛的生活场景,从室内到室外,从城市到自然环境,提供了丰富的视觉多样性。
- 详尽的注释:每个对象实例都有精确的边界框和分割掩码,以及关键点注释对于人体类别的对象。
- 80 个对象类别:COCO 包含了 80 种常见的物体类别,如人、动物、交通工具、家具等。

6. 开始训练
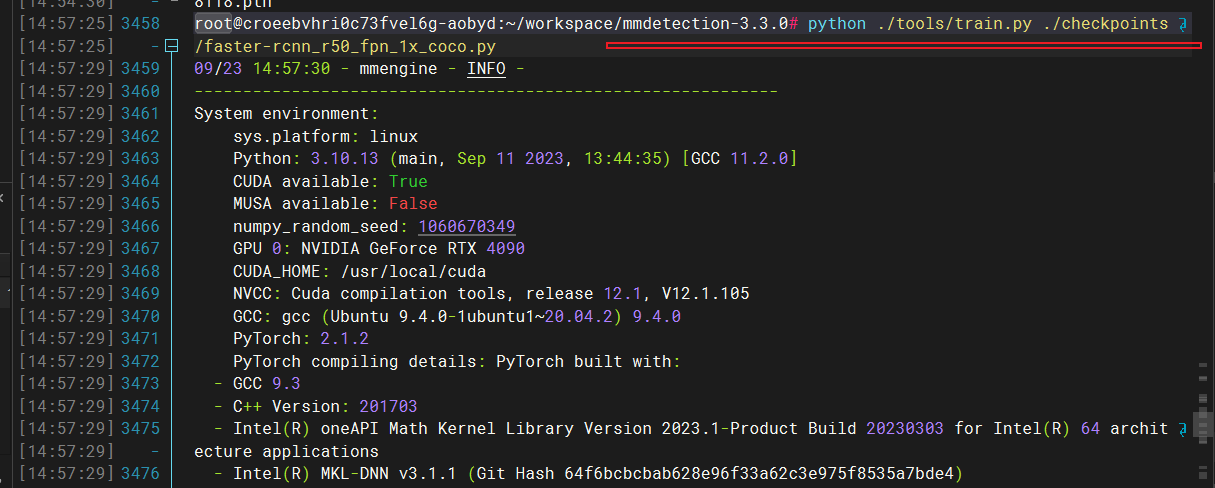
# 为了方便上手,因此我们的代码都是调试好的,因此可以直接输入命令进行训练python ./tools/train.py ./checkpoints/faster-rcnn_r50_fpn_1x_coco.py# 他会自动下载权重,并开始训练,耐心等待即可~~~
- 输入命令,开始程序
- 自行下载,数据准备
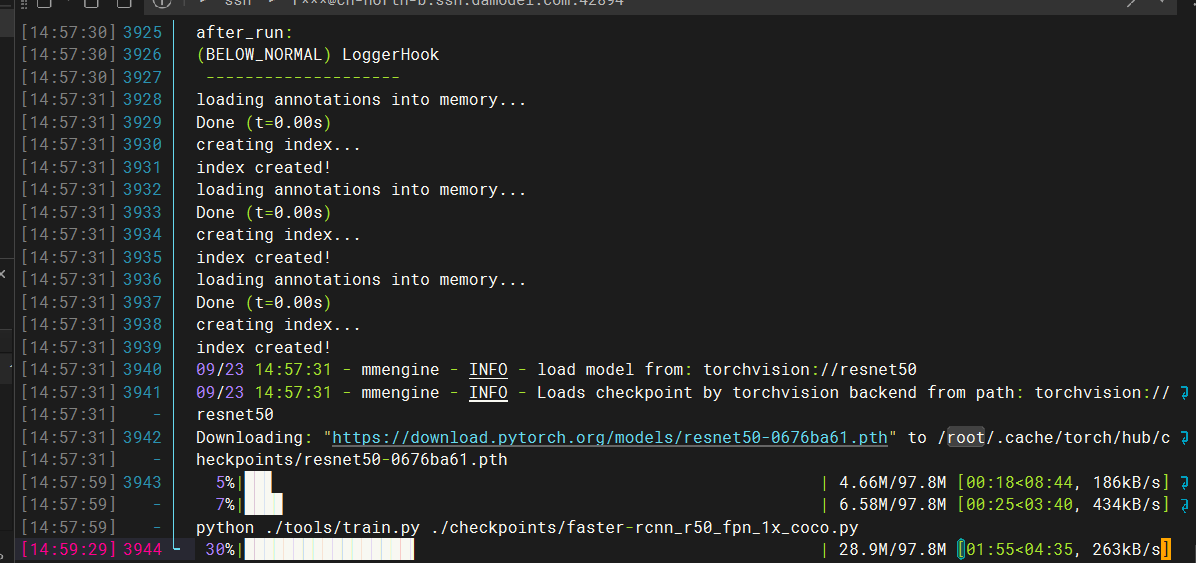
- 数据训练中
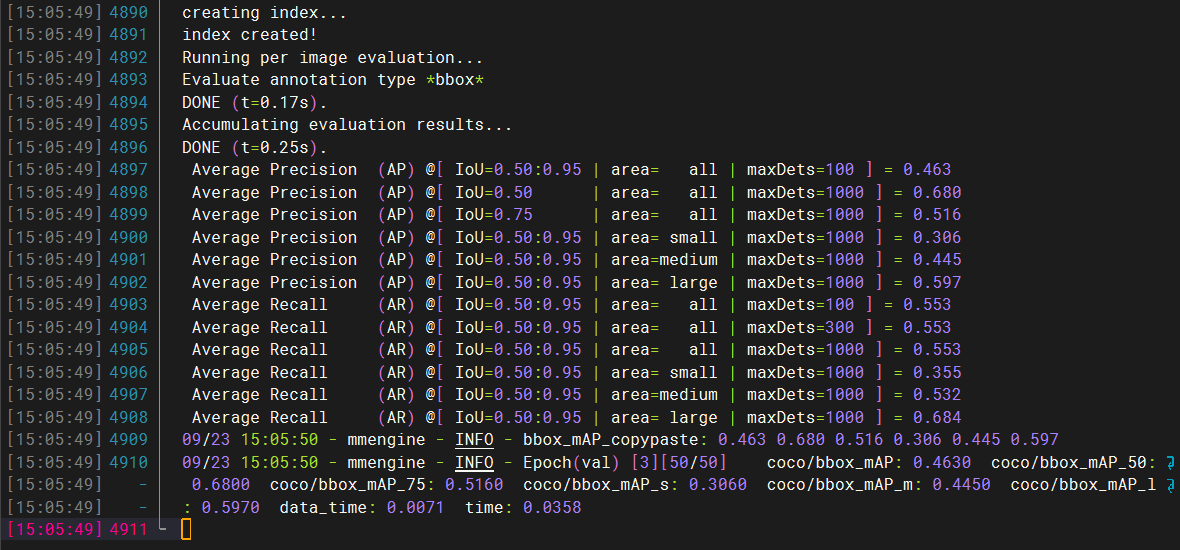
7. 测试数据保存
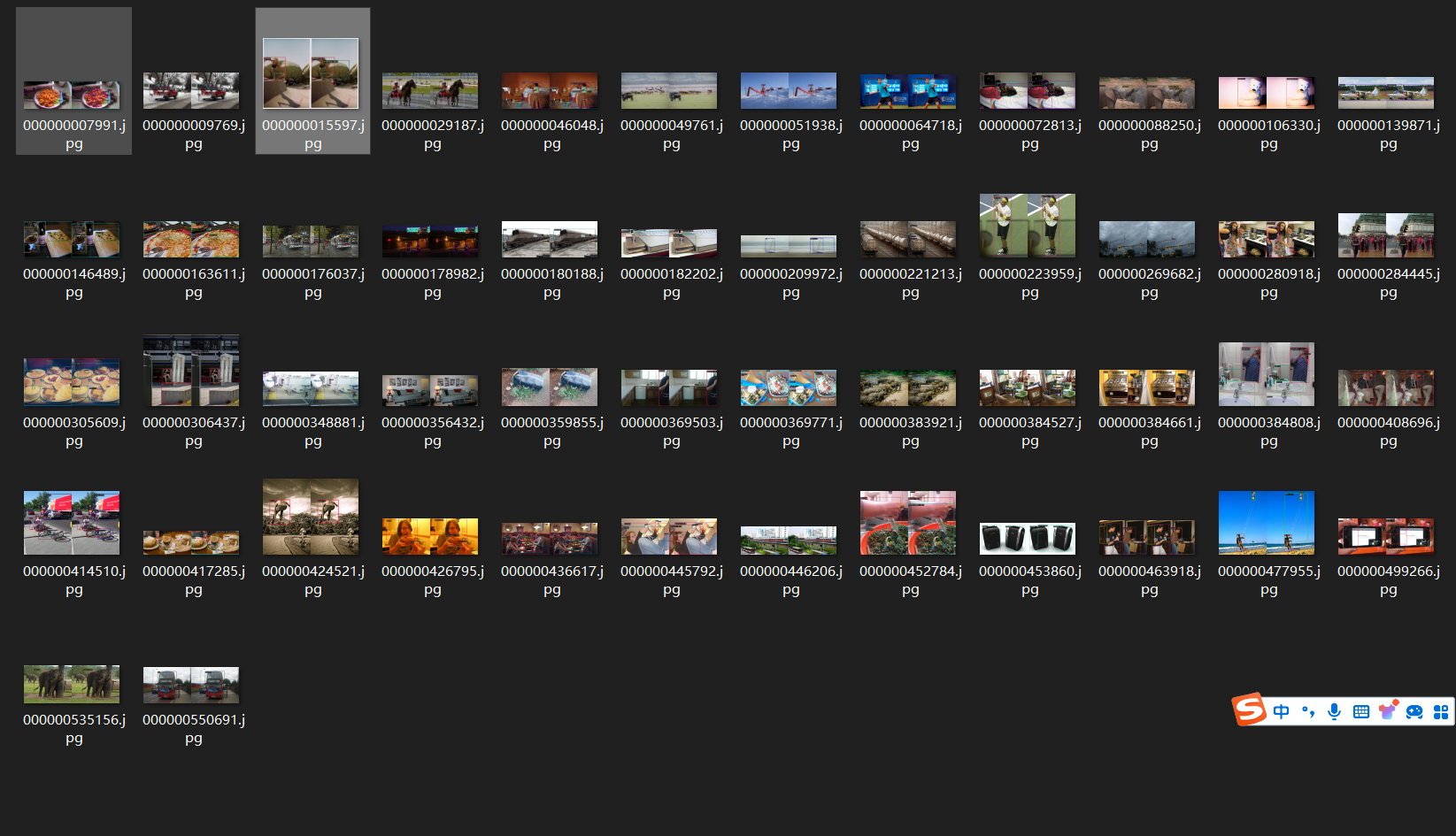
# 经过训练,我们得到pth权重,通过pth权重预测我们的数据集,左侧为真实物体的位置,右侧为预测结果。
# 我们这里直接使用训练好的权重进行预测python tools/test.py ./checkpoints/faster-rcnn_r50_fpn_1x_coco.py ./checkpoints/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth --show-dir /root/workspace/mmdetection-3.3.0/result/
训练完成,数据保存result文件夹
8. 训练结果导出
选择result文件夹,导出本地文件
下载传输速度也是非常可观的
训练结果展示:


9. 结语
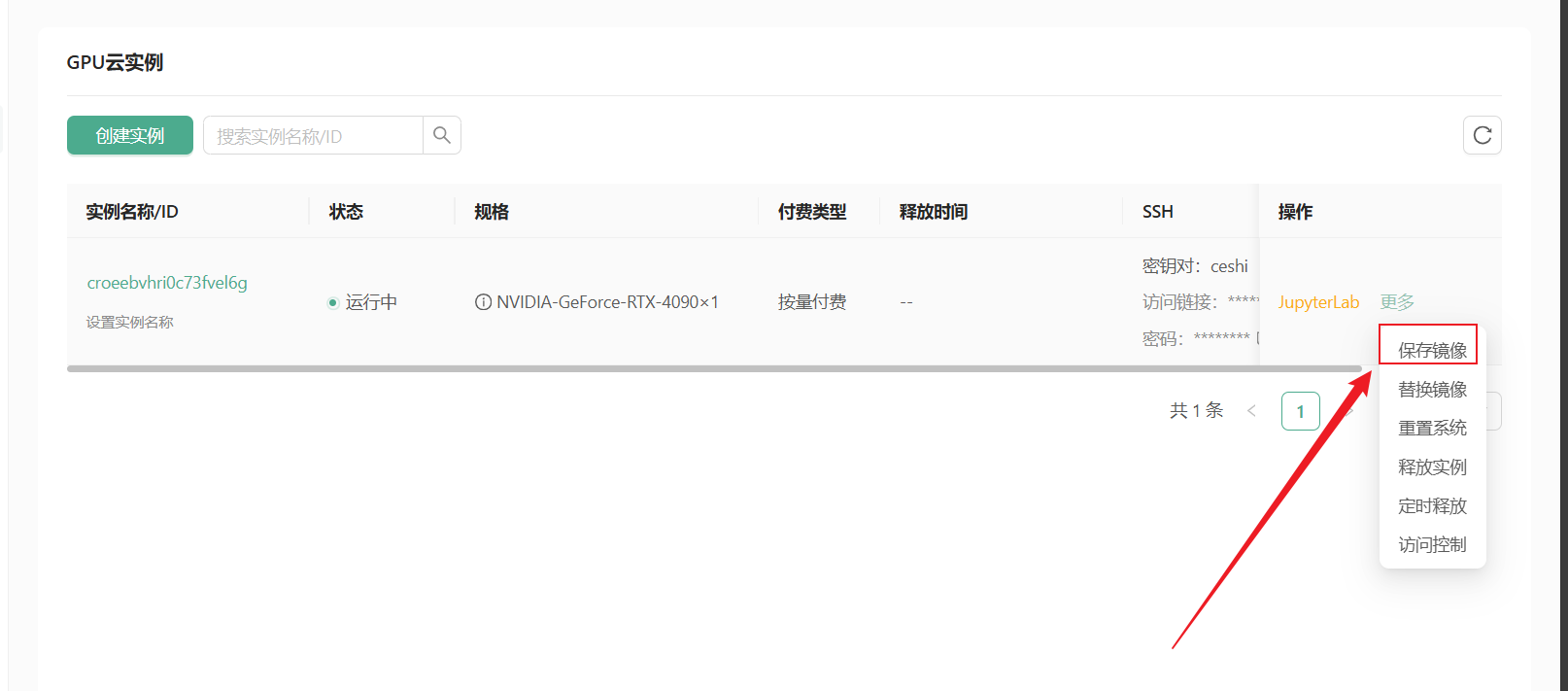
前往控制台-GPU云实例,保存镜像,这样我们可以下次使用时省去配置环境的过程。
整体体验下来,我的使用感受还是很好的,有以下个人感受
- 收费较低,目前优惠力度很大,学生福利够给力
- 性能强劲,训练速度很快,响应快捷
- 官方界面整洁OK,感官不错
- 售后保证,有问题联系官方及时反馈
大家想做科研训练,需要算力可以考虑一下:丹摩智算