预训练和微调

- 预训练阶段:使用公开数据经过预训练过程得到预训练模型,预训练模型具备语言的初步理解;训练周期比较长;
- 微调阶段1:SFT(指令微调/有监督微调)。如果想要预训练模型在某个垂直领域(金融、法律、电商等)有更好的知识储备,就需要使用人工标注的QA问答对进行有监督的微调训练,从而得到精调模型;训练周期较短;
- 微调阶段2:对齐。精调模型的输出并不是全部都令人满意的,我们还需要让模型知道回复的接受度。可以在运行日志中收集对齐数据,包含【问题,接受的回复,不接受的回复】,再进行对齐训练,得到最后可使用的模型;
大模型性能优化推荐
- 算法层面:利用模型量化、知识蒸馏、模型剪枝等技术,减小模型的大小和计算的复杂度;
- 软件层面:
<1>: 计算图优化:数据并行(让同一个模型的不同实例在不同设备上并行处理不同的数据);模型并行(让不同部分的模型在不同设备上并行处理);
<2>:模型编译优化:使用ONNX支持的框架(PyTorch/TF/Keras)训练好模型后,将其导出为ONNX格式,再使用ONNX Runtime或TensorRT进行优化,从而提高模型在GPU上的执行效率; - 硬件层面:英伟达H系列后就支持FP8(float point 8-bit)精度训练,相较于float32和float16,FP8进一步减少了数据存储空间和计算量,而且FP8兼顾FP16的稳定性 + int8的速度;
大模型开发的6个核心技术
- LLM大模型:一个无所不知的智者;
- Prompt提示词工程:交流的指令,越清晰越好;
- function call函数调用外部API工具:外部力量,比如抽水我们知道找抽水泵,出门看天气知道查询天气预报;
- RAG检索增强:开卷考试;
- Agent智能体:谋定而后动,事先规划,再落地行动;
- Fine-tuning微调:知识学霸,将书上的知识全部学到大脑中;
LangChain框架与RAG检索增强生成技术
LangChain是个开源框架,可以将大语言模型与本地数据源相结合,该框架目前以Python或JavaScript包的形式提供;
- 大语言模型:可以是GPT-4或HuggingFace的模型;
- 本地数据源:可以是一本书、一个PDF文件、一个包含专有信息的数据库;
LangChain的工作流程:
- 数据入库:读取本地数据并切成小块,并把这些小块经过编码embedding后,存储在一个向量数据库中(下图1——6步);
- 相关性检索:用户提出问题,问题经过编码,再在向量数据库中做相似性检索,获取与问题相关的信息块context,并通过重排序算法,输出最相关的N个context(下图7——10步);
- 问题输出:相关段落context + 问题组合形成prompt输入大模型中,大模型输出一个答案或采取一个行动(下图11——15步)
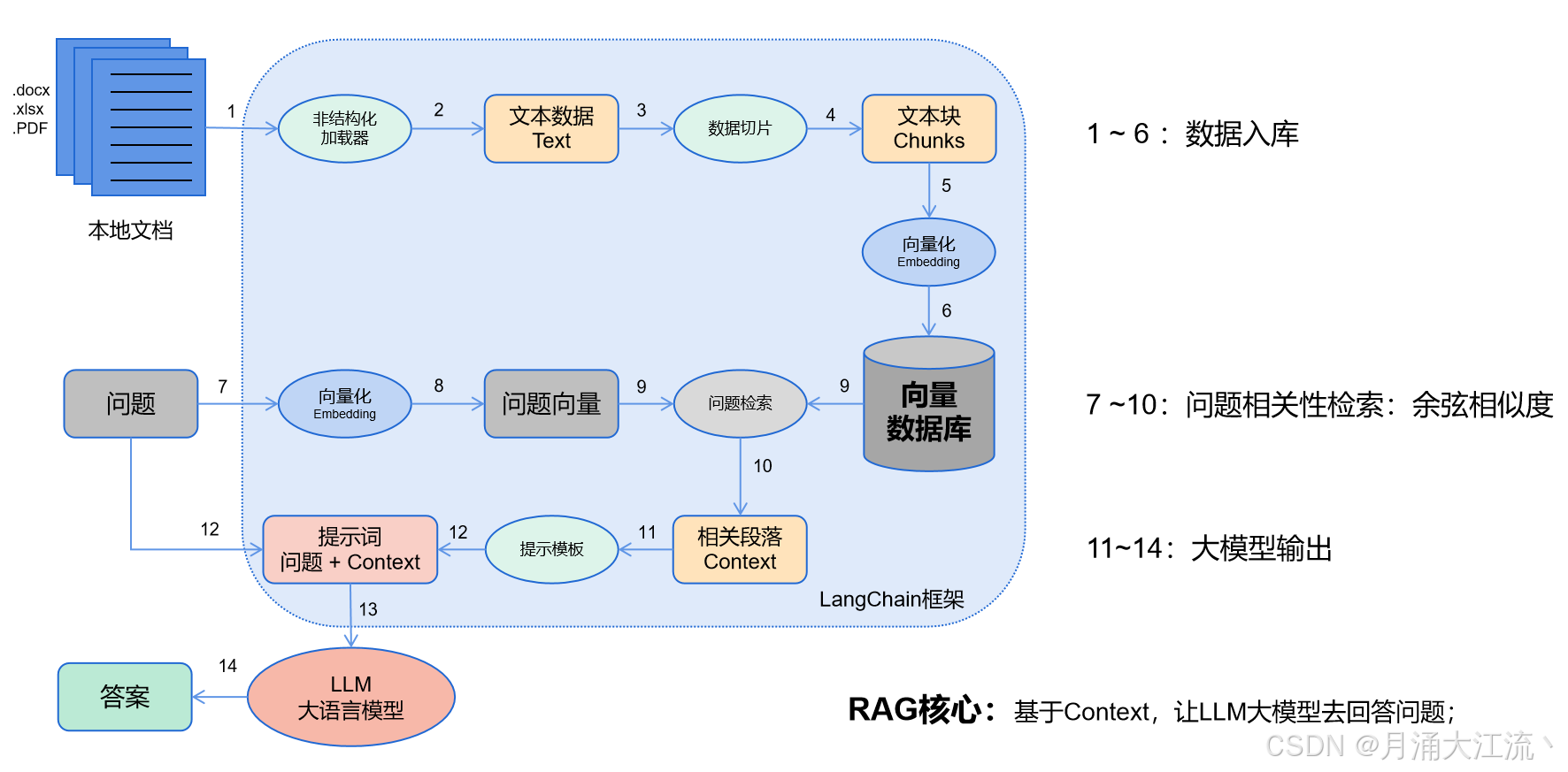
说明:RAG流程中前两步(数据入库和相关性检索)比较核心,主要难点在:知识管理(非结构化加载器做文件解析 + 数据如何切片)、知识检索算法、知识重排序算法。

进阶版RAG技术:主要为提升检索的准确率,提高回复的质量
- 检索前:
<1>:增强数据粒度(校准知识库数据,在确保准确性的前提下,使内容变得简洁、准确、无冗余)
<2>:调整切片长度(每个文本块chunks内容要简洁、知识互相独立)
<3>:添加元数据信息(比如使用【日期、价格】等元数据加强敏感数据的检索,增强相关性)
<4>:混合检索和对齐优化(为每个chunks创建假设性问题来解决文档间的不一致问题) - 检索中:
<1>:知识库分类:将相近知识存在一个知识库中;
<2>:微调Embedding模型:利用特定领域的语料来微调Embedding模型,将特定知识嵌入到模型中;
<3>:Rerank重排序:设计更为复杂的模块对召回的结果进行精细化排序,提高召回质量; - 检索后:
<1>:提示词精炼:压缩无关上下文,突出关键段落,减少总体长度;
<2>:选用更好的模型:提高知识处理能力,增加输出长度;
RAG与Agent的区别

- RAG的本质:是为了弥补大模型在特定领域知识的不足。整个过程相对稳定,LLM可发挥的空间较少;
- Agent的本质:是为了解决复杂的任务。不同模型对任务的拆解相差较大,所以Agent对LLM的推理能力要求较高;
实际项目中会使用Agent + RAG的方式,对Agent中的每一个【任务n】都走一遍RAG流程;
RAG与微调,实际应用时该如何选择
微调场景:
- 大模型能力的定制:
- 对响应时间有要求:
- 智能设备中的应用:
对开源模型做微调,影响的权重也只占1%~5%左右,微调数据与原本数据是否能相容、新模型的鲁棒性是否有提高都比较难把控,所以在实际项目中,能不使用微调就不微调。有兴趣可以试试LLaMA-Factory大模型微调平台;
RAG场景:
模型量化、蒸馏、剪枝
大语言模型在训练和使用中都会占据大量资源,为了能在有限的硬件资源下,保证大模型的质量,一般会使用模型压缩技术,一般的模型压缩的方式有以下三种:
- 模型量化(Quantization):实施在训练端、测试端、移动端部署,主要是牺牲模型精度,用低精度的参数代替高精度参数参与计算,从而降低模型大小和计算复杂度;
- 模型蒸馏(Distillation):实施在数据端,用最强模型的输出反馈做数据蒸馏,微调自身小模型具备最强模型的输出能力;
- 模型剪枝():落地效果不好,很少用,实施在模型端,移除模型中不重要的权重,减小模型大小和计算复杂度;
模型量化:
举例:一个6B的模型(60亿参数),参数精度是float16(一个参数占2字节),那么它模型大小就是12G左右。不同参数精度所占的字节数不同,一般有四个等级的参数精度(8bit等于1字节):
- FP32(单精度32位浮点数):高精度,一个参数占4字节,更大的内存占用和更长的计算时间;
- FP16(半精度16位浮点数):常用精度,一个参数占2字节,资源占用与精度相对均衡;
- FP8:英伟达H系列后就支持FP8精度,兼顾FP16的精度和INT8的速度;
- INT8(将浮点数转换为8位整数):精度较低,一个参数占1字节,但可以显著减少存储和计算的需求
- INT4(将浮点数转换为4位整数):精度很低,一个参数占0.5字节,很激进的量化方式,很可能导致模型失真;
GPT3.5有1750亿个参数,以float16精度为例,模型就有350G左右,对于模型加载、训练、测试都不是很方便,选择合适的量化方式,在模型精度与资源占用中寻找合适的平衡,
模型蒸馏:
模型蒸馏主要作用于数据端。假设我们找到了世界上最顶尖的大模型:GPT_dream,我们想要自己的小模型也能达到类似于GPT_dream的回复效果,那我们就准备好很多你想涵盖的问题,向GPT_dream提问并记录输出,再用输入 + 输出组合成新QA数据,对自己小模型做微调训练,以此让小模型的行为、动作接近于最顶尖的大模型;
2019年10月的DistilBERT模型就是BERT的精炼版,速度提高了 60%,内存减少了 40%,但仍然保留了 BERT 97% 的性能;
大模型幻觉
大模型幻觉主要有哪些:
- 荒谬回复、违背事实:例如人类生活在火星
- 上下文自相矛盾:
- 答非所问:
大模型为什么会出现幻觉:
- 数据质量:训练数据包含错误、偏见、不一致信息,模型可能会学习并放大这些问题;
- 训练过程:预训练或者微调时候,过分拟合了训练数据中的异常值;
- 生成过程:提示词设计不当,或模型过小、模型有缺陷、输出长度太短;
如何解决、规避大模型幻觉问题:主要就是限定回答的范围
- 根据权威信息回复;
- 根据企业文档回复;
- 连接数据库信息;
- 配合知识图谱:向量数据库会弱化对象之间的关系,所以与向量文本互补使用;
RAG效果评估方案推荐
- Trulens:上手简单,和LlamaIndex结合较好,评估指标较少(3个),测试问题需要自己准备;
- Ragas:评估指标较多(超过9个),与LangChain结合较好,提供端到端的评估流程;
- 自写:灵活的评估指标,方便集成与改写,开发难度较大;
- 人为打分:
向量数据库推荐
- Elasticsearch:ES
- PGVector:
- Milvus:
- Pinecone:
大模型必备的开源工具
- 模型平台(模型管理、数据集管理、各类功能排行榜):国外是Huggingface,国内是魔搭社区;
- 模型能力定制:pytorch框架(自写训练程序)、LLaMA-Factory(可视化页面点选训练);
- 模型部署(模型管理、模型调用):ollama,容器化管理;
- 模型应用开发框架:LangChain、LlamaIndex;
Agent实施方案
- 在线平台:coze扣子、Dify等,快速实现一些简单需求,上手难度小,但是不能私有化部署;
- 开源项目:AutoGen、mateGPT等,基于这些项目进行二次开发,完全开源;
- 开发框架:LangChain、LlamaIndex等框架、适合专职做大项目开发的人,专业,学习曲线稍长;
- 完全自写:适合专职做大项目开发的人,Agent只是一个应用大模型的思想,并不是一门技术,可以不使用任何一个框架,灵活控制;