Kafka 是大数据领域非常流行的一款分布式消息中间件,是实时计算中必不可少的一环,同时一款 OLAP 系统能否对接 Kafka 也算是考量是否具备流批一体的衡量指标之一。ClickHouse 的 Kafka 表引擎能够直接与 Kafka 系统对接,进而订阅 Kafka 中的 Topic 并实时接受消息数据。
众所周知,在消息系统中存在三层语义,它们分别是:
- 最多一次(at most once):可能存在丢失数据的情况
- 最少一次(at least once):可能存在重复数据的情况
- 精准一次(exactly once):数据不多不少,最为理想的情况
虽然 Kafka 本身能够支持上述三层语义,但一条完整的数据链路支持的语义遵循木桶原理。ClickHouse 24.8(2024 年 9 月 3 日)前还不支持 exactly once 语义,但因为 ClickHouse 有强大的 MergeTree 系列引擎且在明确的业务场景加持下(定义业务主键)具备幂等性,当幂等性 + at least once 语义也是可以实现 exactly once。而在 ClickHouse 24.8 LST 版本中官方引入新的 Kafka 引擎这为直接实现 exactly once 语义提供了可能。
We also have a new experimental Kafka engine.
This version makes it possible to have exactly-once processing of messages from Kafka.
本文则从零开始讲述 ClickHouse 如何与 Kafka 进行深度融合,如何在生产中优雅地使用 Kafka 表引擎同时介绍新的 Kafka 表引擎是如何实现 exactly once 以及新老表引擎的对比。因此本文所使用的 ClickHouse 版本为 24.8
一、如何使用 Kafka Engine
Kafka 表引擎的声明方式如下所示:
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(name1 [type1] [ALIAS expr1],name2 [type2] [ALIAS expr2],...
) ENGINE = Kafka()
SETTINGSkafka_broker_list = 'host:port',kafka_topic_list = 'topic1,topic2,...',kafka_group_name = 'group_name',kafka_format = 'data_format'[,][kafka_schema = '',][kafka_num_consumers = N,][kafka_max_block_size = 0,][kafka_skip_broken_messages = N,][kafka_commit_every_batch = 0,][kafka_client_id = '',][kafka_poll_timeout_ms = 0,][kafka_poll_max_batch_size = 0,][kafka_flush_interval_ms = 0,][kafka_thread_per_consumer = 0,][kafka_handle_error_mode = 'default',][kafka_commit_on_select = false,][kafka_max_rows_per_message = 1];
其中必填参数如下:
kafka_broker_list: Broker 服务的地址列表,多个地址之间使用逗号分割,例如: ‘kafka01.data.center:9092, kafka02.data.center:9092’kafka_topic_list: 表示订阅消息的 topic 名称列表,多个 topic 之间使用逗号分割,例如: ‘topic01,topic02’kafka_group_name: 表示消费者组名称,遵循 kafka 消费者组订阅逻辑kafka_format: 表示用于解析消息的数据格式,所有 topic 中的数据应保持指定的数据格式否则无法解析且 format 必须是 ClickHouse 提供的格式之一,例如:TSV、CSV、JSONEachRow等。更多消息格式点击查看
常用的选填参数
kafka_num_consumers: 表示消费者的数量,默认为 1。表引擎会根据此参数在消费者组中开启对应数量的消费者线程,同时遵循一个 Partition 只能被一个消费者消费kafka_thread_per_consumer: 为每个消费者提供单独线程用于处理、刷写数据,默认值为 0。不配置则只会刷写出一个 blockkafka_skip_broken_messages: 当表引擎按照指定格式解析数据发生错误时,循序跳过失败的数据行数,默认值为 0。即不允许任务格式错误的情况发生,只要 topic 中存在无法解析的数据,表引擎将不会接收任何数据。如果将其设置为非 0 正整数,只要解析错误的数据没有超过阈值,表引擎都能正常接收消息并跳过解析错误的数据
Kafka 表引擎触发缓存刷新的条件参数(选填)
kafka_poll_timeout_ms: 控制表引擎每次 poll 拉取的间隔,数据首先会被写入缓存,在时机成熟情况下,缓存数据会被刷写到数据表kafka_poll_max_batch_size: 控制单次 poll 拉取的最大条数会被视为一个数据块,默认值为 65536。当一个数据块完成写入的时候触发缓存数据刷写操作kafka_flush_interval_ms: 控制缓存数据刷写时间间隔,默认值为 7500ms
下面使用一个具体例子说明 Kafka 表引擎的使用方式。
创建 topic
bin/kafka-topics.sh --bootstrap-server 127.0.0.1:9092 --create --replication-factor 1 --partitions 1 --topic user-queue
发送测试数据
bin/kafka-console-producer.sh --broker-list 127.0.0.1:9092 --topic user-queue
>{"id":1,"name":"zs"}
>{"id":2,"name":"ls"}
验证测试数据是否发送成功
bin/kafka-console-consumer.sh --bootstrap-server 127.0.0.1:9092 --topic user-queue --from-beginning
{"id":1,"name":"zs"}
{"id":2,"name":"ls"}
Kafka 端的相关工作准备完成之后可以开始 ClickHouse 部分的工作。
首先创建一个数据表
create table user_queue_test
(id Int32 comment '用户 id',name String comment '用户姓名'
) engine Kafkasettingskafka_broker_list = '127.0.0.1:9092',kafka_topic_list = 'user-queue',kafka_group_name = 'ck-consumer-01',kafka_format = 'JSONEachRow',kafka_num_consumers = 1,kafka_skip_broken_messages = 100;
该数据表订阅了名为 user-queue 的 topic,且使用的消费者组名称为 ck-consumer-01,而消息格式采用 JSONEachRow。因为订阅的 topic 分区数为 1 表引擎的消费者数不大于即可同时允许跳过 100 条解析错误的数据。
在开启流引擎允许直接查询的配置后查询该表就可以看到 Kafka 的数据
set stream_like_engine_allow_direct_select = 1;
select * from user_queue_test;
但如果再次执行 select 查询就会发现 user_queue 的数据表空空如也(前提是 topic 没有新的数据写入)。这是因为 kafka 表引擎在执行查询后会删除表内数据,因此正确的使用方式是借助物化视图作为管道将 Kafka 表引擎的数据实时同步到 MergeTree 表中,且也为了后续高效的数据分析。
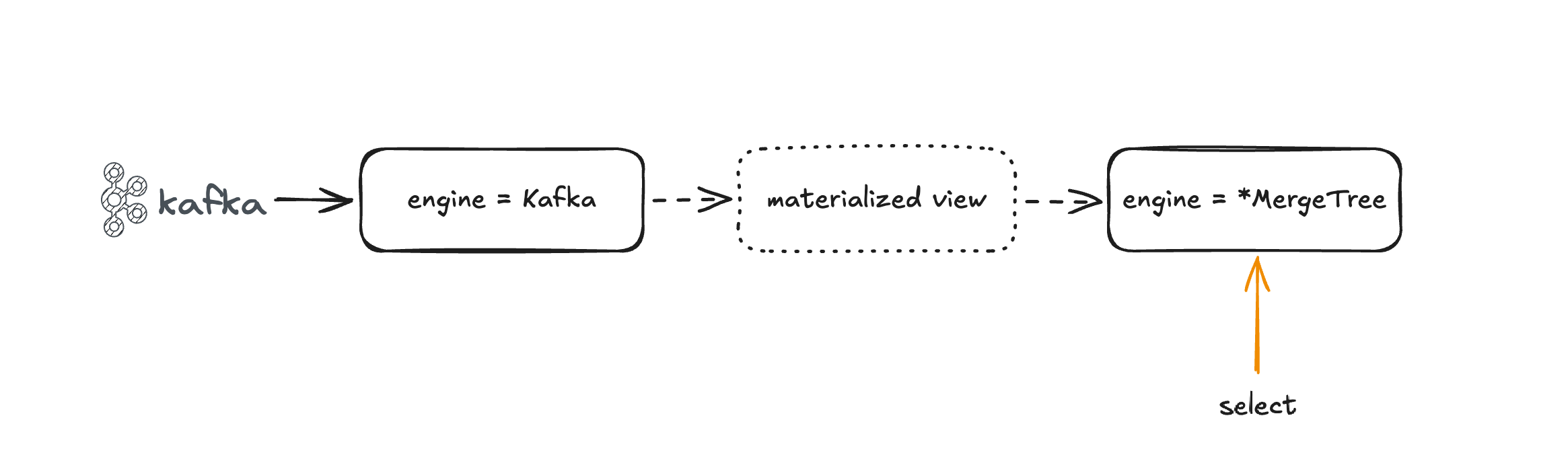
下面演示使用这种方式创建表
首先创建一张 Kafka 引擎的表
create table user_queue
(id Int32 comment '用户 id',name String comment '用户姓名'
) engine = Kafkasettingskafka_broker_list = '127.0.0.1:9092',kafka_topic_list = 'user-queue',kafka_group_name = 'ck-consumer-01',kafka_format = 'JSONEachRow',kafka_num_consumers = 1,kafka_skip_broken_messages = 100;
接着,创建一张面相用户的查询表,这里使用 MergeTree 表引擎
create table user
(id Int32 comment '用户 id',name String comment '用户姓名'
) engine = MergeTreeorder by id;
最后,创建物化视图用于 user_queue 数据实时同步到 user 中
create materialized view mv_user_queue_consumer to user as
select id, name
from user_queue;
至此,可以继续向 Kafka 的 topic 发送消息,数据的查询只面向 user 表即可
select * from user;
消费者的信息也会被 ClickHouse 记录在系统表中
select *
from system.kafka_consumers
where table = 'user_queue'format Vertical;Row 1:
──────
database: default
table: user_queue
consumer_id: ClickHouse-wjun-default-user_queue-7505e428-38c4-45aa-a2d4-22ffd20dc404
assignments.topic: ['user-queue']
assignments.partition_id: [0]
assignments.current_offset: [4]
exceptions.time: []
exceptions.text: []
last_poll_time: 2024-09-06 15:11:36
num_messages_read: 10
last_commit_time: 2024-09-06 15:10:43
num_commits: 1
last_rebalance_time: 2024-09-06 14:50:32
num_rebalance_revocations: 3
num_rebalance_assignments: 4
is_currently_used: 1
last_used: 1725606693045341
rdkafka_stat:
如果需要停止数据的同步可以删除物化视图(不推荐)或者将其卸载(推荐)
detach table mv_user_queue_consumer;
在卸载物化视图后 user_queue 将不再拉取数据,如果想要再次恢复可以使用装载命令
attach table mv_user_queue_consumer;
二、进阶使用
2.1 优雅处理解析错误数据
kafka_skip_broken_messages 控制当发生解析错误时允许跳过的数据条数,但在建表时无法评估且被跳过的数据无法被捕获,因此该配置在生产中不常用。下面介绍错误处理的相关配置以及 Kafka 表引擎支持的虚拟列。
众所周知 Kafka 的一条消息不仅包含实际的业务数据,也包含该消息的元数据。这些元数据有时也会被要求获取参与后续的业务分析,因此 Kafka 表引擎内置 topic 元数据虚拟列以及用于解析错误的虚拟列
_topic: 消息所属的 Kafka Topic,数据类型 LowCardinality(String)_key: 消息的 Key,数据类型 String_offset: 消息的偏移量,数据类型 UInt64_timestamp: 消息的时间戳,数据类型 Nullable(DateTime)_timestamp_ms: 消息的时间戳毫秒数,数据类型 Nullable(DateTime(3))_partition: 消息所属的 Kafka Topic 分区数,数据类型 UInt64_headers.name: 消息头 key,数据类型 Array(String)_headers.value: 消息头 value,数据类型 Array(String)
额外的,Kafka 表引擎提供 kafka_handle_error_mode 默认值为 default,当配置为 stream 时在遇到解析错误的消息时会将解析错误的原始消息和错误原因写入下面两个虚拟列中
_raw_message: 存储无法解析的原始消息,数据类型 String_error: 存储解析错误的原因,数据类型 String
Tips: _raw_message 和 _error 仅在解析错误时有值,正确解析时这两个虚拟列为空
下面演示如何存储元数据以及存储无法解析的数据,保证 Kafka Topic 的数据全部存储到 ClickHouse 中
首先,创建测试 Topic
bin/kafka-topics.sh --bootstrap-server 127.0.0.1:9092 --create --replication-factor 1 --partitions 4 --topic user-queue01
bin/kafka-topics.sh --bootstrap-server 127.0.0.1:9092 --create --replication-factor 1 --partitions 2 --topic user-queue02
bin/kafka-topics.sh --bootstrap-server 127.0.0.1:9092 --create --replication-factor 1 --partitions 1 --topic user-queue03
接着,借助工具发送测试数据并随机发送若干非 json 格式数据
最后,创建 ClickHouse 端的相关表
create table user_queue_for_error
(_topic LowCardinality(String),_key String,_offset UInt64,_timestamp Nullable(DateTime),_timestamp_ms Nullable(DateTime64(3)),_partition UInt64,`_headers.name` Array(String),`_headers.value` Array(String),id Int32 comment '用户 id',name String comment '用户姓名',_raw_message String,_error String
) engine = Kafkasettingskafka_broker_list = '127.0.0.1:9092',kafka_topic_list = 'user-queue01,user-queue02,user-queue03',kafka_group_name = 'ck-consumer-02',kafka_format = 'JSONEachRow',kafka_num_consumers = 1,kafka_skip_broken_messages = 0,kafka_handle_error_mode = 'stream';create table user_for_error
(_topic LowCardinality(String),_key String,_offset UInt64,_timestamp Nullable(DateTime),_timestamp_ms Nullable(DateTime64(3)),_partition UInt64,`_headers.name` Array(String),`_headers.value` Array(String),id Int32 comment '用户 id',name String comment '用户姓名',_raw_message String,_error String
) engine = MergeTreeorder by id;create materialized view mv_user_queue_for_error_consumer to user_for_error as
select *
from user_queue_for_error;
可以通过虚拟列 _raw_message 是否有值直接找出无法解析的消息,而这种处理思路和 flink 的侧数据出流有着异曲同工之妙
2.2 极限情况下的重复消费
Kafka 使用 offset 记录 topic 数据被消费的位置信息,当应用端接收到消息之后通过自动或手动执行 Kafka Commit 提交当前的 offset 信息以保证消息的语义。ClickHouse 的 Kafka 表引擎通过 kafka_commit_every_batch 控制 Kafka Commit 的提交频率,默认值为 0,即当一整个 Block 数据块完全写入数据表后才执行 commit。如果设置为 1,则每写完一个 batch 批次数据就执行一次 commit(一次 Block 写入操作由多次 batch 写入操作完成)。
上述的 offset 提交逻辑在 Kafka 和 ClickHouse 之间是非原子操作,这导致在重试时存在数据重复的可能。因此在 24.8 LST 版本中 ClickHouse 新增了新的 Kafka 表引擎,offset 通过 ClickHouse Keeper 来处理,无论网络或系统的错误导致 block 插入失败,它都将获取相同的 chunk 重复插入这为实现 exactly once 提供了可能
三、新的 Kafka Engine
新的 Kafka Engine 将 offset 存储在 ClickHouse Keeper(下简称 Keeper) 中,虽然 keeper 依然会尝试将 offset 提交给 kafka,但在任何情况下 ClickHouse 都只会使用存储在 Keeper 中的 offset。除了提交的偏移量之外,它还存储上一批消费了多少条消息,因此如果插入失败,将消费相同数量的消息,从而在必要时删除重复数据。
3.1 ClickHouse Keeper
ClickHouse Keeper 提供数据复制和分布式 DDL 查询执行的协调系统,兼容 Zookeeper 协议。使用 C++开发,区别于 Zookeeper 的 ZAB 协调算法,Keeper 使用 RAFT 算法这就导致二者的快照和数据格式是不相同的,因此混用 Zookeeper / Keeper 是不可能的。Keeper 的立项主要是用来解决 ZooKeeper 存在 full gc 的情况,从理论上 keeper 具有比 Zookeeper 更高的性能和可用性。下面快速安装 Keeper
ClickHouse Keeper 捆绑在 ClickHouse 安装包中只需要提供必要的配置信息即可。
创建 keeper_config.xml 配置文件
<clickhouse><logger><level>information</level><log>/Users/wjun/env/clickhouse/24.8/logs/clickhouse-keeper.log</log><errorlog>/Users/wjun/env/clickhouse/24.8/logs/clickhouse-keeper.err.log</errorlog><size>100M</size><count>10</count></logger><keeper_server><tcp_port>12181</tcp_port><server_id>1</server_id><log_storage_path>/Users/wjun/env/clickhouse/24.8/logs/coordination.log</log_storage_path><snapshot_storage_path>/Users/wjun/env/clickhouse/24.8/data/coordination/snapshots</snapshot_storage_path><storage_path>/Users/wjun/env/clickhouse/24.8/data/keeper</storage_path><coordination_settings><operation_timeout_ms>10000</operation_timeout_ms><session_timeout_ms>30000</session_timeout_ms><raft_logs_level>warning</raft_logs_level><experimental_use_rocksdb>1</experimental_use_rocksdb></coordination_settings><raft_configuration><server><id>1</id><hostname>localhost</hostname><port>9234</port></server></raft_configuration></keeper_server>
</clickhouse>
启动 Keeper
./clickhouse keeper --config-file config/keeper_config.xml --pid-file ./clickhouse-keeper.pid
后续可以使用 Zookeeper Client 进行连接且具备相同的操作命令
在 ClickHouse Server 的配置文件中添加 Keeper 连接信息
<zookeeper><node><host>127.0.0.1</host><port>12181</port></node>
</zookeeper>
无需重启,ClickHouse Server 会自动加载新的配置文件
3.2 新老引擎对比
ClickHouse 新特性都会在第一个版本中作为实验性功能推出,因此使用新的 Kafka Engine 需要开启对应的配置
set allow_experimental_kafka_offsets_storage_in_keeper = 1;
新老版本的 Kafka Engine 在关键字上保持一致,只需要添加额外的两个配置即可使用新的表引擎
kafka_keeper_path: 指定 keeper 中的表路径kafka_replica_name: 指定 keeper 中的副本名
这里的两个配置参数可以完全等价于 ReplicatedMergeTree 中的 zk_path 和 replica_name,实际上二者的作用也是一样的。
创建新的 Kafka Engine
create table user_queue_for_error_new
(_topic LowCardinality(String),_key String,_offset UInt64,_timestamp Nullable(DateTime),_timestamp_ms Nullable(DateTime64(3)),_partition UInt64,`_headers.name` Array(String),`_headers.value` Array(String),id Int32 comment '用户 id',name String comment '用户姓名',_raw_message String,_error String
) engine = Kafkasettingskafka_keeper_path = '/clickhouse/default/user_queue_for_error_new',kafka_replica_name = 'r1',kafka_broker_list = '127.0.0.1:9092',kafka_topic_list = 'user-queue01,user-queue02,user-queue03',kafka_group_name = 'ck-consumer-new',kafka_format = 'JSONEachRow',kafka_num_consumers = 2,kafka_thread_per_consumer = 1,kafka_skip_broken_messages = 0,kafka_handle_error_mode = 'stream'settings allow_experimental_kafka_offsets_storage_in_keeper = 1;create table user_for_error_new
(_topic LowCardinality(String),_key String,_offset UInt64,_timestamp Nullable(DateTime),_timestamp_ms Nullable(DateTime64(3)),_partition UInt64,`_headers.name` Array(String),`_headers.value` Array(String),id Int32 comment '用户 id',name String comment '用户姓名',_raw_message String,_error String
) engine = MergeTreeorder by id;create materialized view mv_user_queue_for_error_consumer_new to user_for_error_new as
select *
from user_queue_for_error_new;
此时的 offset 会被记录在 Keeper 中
[zk: 127.0.0.1:12181(CONNECTED) 1] get /clickhouse/default/user_queue_for_error_new/topics/user-queue01/partitions/0/committed
2
虽然 Kafka 也会存储消费者每个 Topic 的 offset 但这里的数据 ClickHouse 不会使用,新老引擎最直观的测试方式就是删除 Kafka 中存储的两个消费者的 offset
暂时卸载 mv_user_queue_for_error_consumer、mv_user_queue_for_error_consumer_new,目的是让两者的消费者下线,因为 Kafka 不允许对正在工作的消费者做任何外部操作。
detach table mv_user_queue_for_error_consumer_new;
detach table mv_user_queue_for_error_consumer;
接下来删除新老表使用的消费者组
./kafka-consumer-groups.sh --bootstrap-server localhost:9092 --delete --group ck-consumer-02
Deletion of requested consumer groups ('ck-consumer-02') was successful../kafka-consumer-groups.sh --bootstrap-server localhost:9092 --delete --group ck-consumer-new
Deletion of requested consumer groups ('ck-consumer-new') was successful.
Tips: 卸载物化视图后需要等待一段时间消费者组才会下线
再次装载物化视图
attach table mv_user_queue_for_error_consumer_new;
attach table mv_user_queue_for_error_consumer;
观察 user_for_error 和 user_for_error_new
select 'user_for_error' as tb, count() as cnt
from user_for_error
union all
select 'user_for_error_new', count()
from user_for_error_new;┌─tb─────────────────┬─cnt─┐
│ user_for_error_new │ 12 │
└────────────────────┴─────┘
┌─tb─────────────┬─cnt─┐
│ user_for_error │ 24 │
└────────────────┴─────┘
因为老的引擎完全依赖 Kafka 的 offset 当消费者组被删除后重新上线则被视为新的消费者组从最老的消息处开始消费,这就导致数据重复。而新的引擎尝试从 Keeper 中获取 offset 并直接定位到指定位置处开始消费,这是新老引擎最大的区别。同时新引擎 offset 的处理思路与 flink 的 kafka-connector 从 checkpoint 处获取 offset 思路再次不期而遇
当然新的 Kafka Engine 存在一定的使用限制
- 不允许直接查询,即使开启流读配置。因此使用物化视图是获取数据的唯一方式
- keeper path 需要注意路径的唯一性
- 为了确保可重复读,不允许单个线程消费多个分区的数据,因此
kafka_thread_per_consumer必须配置。涉及复杂的事务隔离级别不在这里过多介绍 - 消费者的数据不再存储到
system.kafka_consumers中