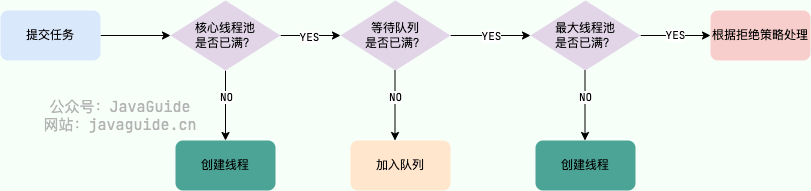
Presto的任务队列配置主要涉及到查询队列和资源组的配置,这些配置通常用于管理Presto集群中的查询执行和资源分配。但是注意这两个东西是共存,互补的关系,并不需要纠结那种配置方式更加出色
一、查询队列配置
Presto的查询队列配置主要通过编辑Presto安装目录下的config.properties文件来实现。在config.properties文件中,你可以指定查询队列的配置文件路径,并在该配置文件中定义队列和规则。
-
指定查询队列配置文件路径
在
config.properties文件中添加如下配置,指定查询队列配置文件的路径:query.queue-config-file=/path/to/your/queue_config.json其中,
/path/to/your/queue_config.json应替换为你的查询队列配置文件的实际路径。 -
编辑查询队列配置文件
在指定的查询队列配置文件中(如
queue_config.json),你可以定义多个队列和规则。队列定义在queues下,每个队列包含三个主要属性:队列名称(如user.hive)、最大并发数(maxConcurrent)和最大排队数(maxQueued)。规则定义在rules下,用于将查询分配到不同的队列。示例配置如下:
{"queues": {"user.hive": {"maxConcurrent": 5,"maxQueued": 50},"admin": {"maxConcurrent": 5,"maxQueued": 100},"global": {"maxConcurrent": 3,"maxQueued": 5}},"rules": [{"user": "bob","queues": ["admin"]},{"queues": ["user.hive", "global"]}] }在这个示例中,定义了三个队列(
user.hive、admin、global)和两个规则。第一个规则将用户名为bob的查询分配到admin队列,第二个规则将所有其他查询分配到user.hive和global队列。
二、资源组配置
Presto的资源组功能提供了更细粒度的资源管理和隔离能力。通过配置资源组,你可以为不同的查询或用户组分配不同的资源(如CPU、内存、并发数等)。
-
创建资源组配置文件
在Presto Coordinator节点的安装目录下(如
/etc/),创建一个新的资源组配置文件(如resource-groups.json)。 -
编辑资源组配置文件
在资源组配置文件中,定义资源组的主要配置项,包括资源组名称、最大排队数(
maxQueued)、硬并发限制(hardConcurrencyLimit)、软内存限制(softMemoryLimit)等。还可以定义资源组选择器,用于将查询分配到不同的资源组。示例配置如下:
{"groups": [{"name": "global","maxQueued": 1000,"hardConcurrencyLimit": 100,"softMemoryLimit": "60%","schedulingPolicy": "weighted_fair","schedulingWeight": 1},{"name": "pipeline","maxQueued": 500,"hardConcurrencyLimit": 50,"softMemoryLimit": "50%","schedulingPolicy": "fair","userRegex": "pipeline_.*"}],"selectors": [{"userRegex": "pipeline_.*","group": "pipeline"},{"group": "global"}] }在这个示例中,定义了两个资源组(
global和pipeline)和两个选择器。第一个选择器将所有用户名以pipeline_开头的查询分配到pipeline资源组,第二个选择器将所有其他查询分配到global资源组。 -
在
config.properties中指定资源组配置文件在
config.properties文件中,添加如下配置,指定资源组配置文件的路径:resource-groups.configuration-manager=file resource-groups.config-file=/etc/resource-groups.json
通过以上步骤,你可以完成Presto的任务队列和资源组配置,从而实现对Presto集群中查询执行和资源分配的精细管理。请注意,以上配置仅为示例,具体配置应根据你的实际需求和Presto版本进行调整。