在数据库系统中,数据的安全性和一致性至关重要。无论是面对事务故障、系统故障还是介质故障,数据库都需要具备强大的恢复机制来应对这些潜在风险。本文将带领大家详细了解数据库恢复的实现技术,重点介绍如何利用冗余数据、转储和日志文件来实现各种故障后的数据恢复。
9.2 恢复的实现技术
数据库恢复的核心理念是基于冗余数据,即通过保存额外的副本或日志信息,确保在出现异常时,数据库能够恢复到一致状态。数据库恢复机制的两个关键问题是:如何建立冗余数据以及如何利用这些冗余数据进行恢复。
9.2.1 数据转储
数据转储是指数据库管理员(DBA)定期将整个数据库的数据复制并保存到安全的存储设备上。通过这种方式,即使数据库数据损坏或丢失,也可以从转储的副本中恢复。
1. 转储的分类
转储操作可以根据不同的标准进行分类:
(1)按转储期间是否允许事务运行
- 静态转储:在没有任何事务运行的情况下进行的转储。静态转储期间,数据库停止服务,所有事务执行完毕后才会进行备份。其优点是操作简单,且生成的副本是一致性副本。但缺点是系统在转储期间不可用,降低了数据库的可用性。
- 动态转储:允许在转储期间继续执行事务。动态转储并发进行,但可能会导致备份中的数据不一致。尽管转储期间系统可用,但备份副本中的部分数据可能因为事务的更新而过时。
(2)按转储数据量的不同
- 海量转储:将整个数据库完整地备份,适用于大规模的全面备份。
- 增量转储:仅备份自上次转储后更新过的数据,这种方式可以节省存储空间和转储时间。
2. 转储策略
DBA需要根据数据库的使用情况来制定合适的转储策略。例如:
- 对于银行、购票系统等需要24小时不间断服务的数据库,适合采用每小时动态增量转储的策略。
- 对于一些使用频率不高的数据库,每月进行一次静态海量转储即可。
9.3 故障恢复机制:应对不同类型故障的策略
数据库系统会遇到多种类型的故障,最常见的包括事务故障、系统故障和介质故障。恢复过程通常依赖于提前生成的日志文件和转储副本。接下来,我们将介绍如何针对不同的故障进行恢复。
9.3.1 事务故障的恢复
事务故障是指事务在执行过程中未能正常完成,导致数据不一致。事务故障的恢复过程依赖日志文件,具体步骤如下:
-
反向扫描日志,从最后一条日志记录开始,查找该事务的所有更新操作。
-
对每个更新操作执行逆操作:
- 对于插入操作,将其删除。
- 对于删除操作,将其重新插入。
- 对于修改操作,将数据恢复为更新前的值。
-
继续反向扫描,直到找到该事务的开始标记,恢复完成。
总结:事务故障的恢复主要通过UNDO操作(撤销操作)来确保数据的一致性。
9.3.2 系统故障的恢复
系统故障(如断电或系统崩溃)会影响所有正在运行的事务。恢复过程涉及两类事务:已完成的事务和未完成的事务。
恢复步骤如下:
- 正向扫描日志文件,找出故障发生前已提交的事务,将其加入重做(REDO)队列,未完成的事务则加入撤销(UNDO)队列。
- 对UNDO队列中的事务进行撤销,方法是反向扫描日志文件,将每个更新操作恢复为更新前的值。
- 对REDO队列中的事务进行重做,方法是正向扫描日志文件,重新执行每个事务的操作,确保所有已提交的事务的结果被正确写入数据库。
总结:系统故障恢复通过UNDO和REDO的结合,确保事务数据的一致性和完整性。
9.3.3 介质故障的恢复
介质故障是指存储介质(如磁盘)损坏,导致数据库数据和日志文件丢失或损坏。这是最严重的故障类型,恢复难度较大。
恢复步骤如下:
- 修复或更换损坏的存储设备,并重新启动数据库系统。
- 装入最近的转储副本,将数据库恢复到上一次转储时的一致状态。如果是静态副本,数据库直接恢复到一致状态;如果是动态副本,还需要利用日志文件来完成恢复。
- 利用日志文件:根据日志文件记录的更新操作,执行REDO(重做)操作,确保数据库恢复到故障前的状态。
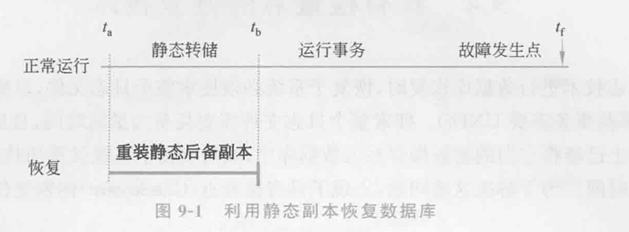
静态副本恢复示例:
假设数据库在时刻T₀发生了故障,使用最近的静态副本可以直接恢复到T₀时刻的一致状态,如图所示:
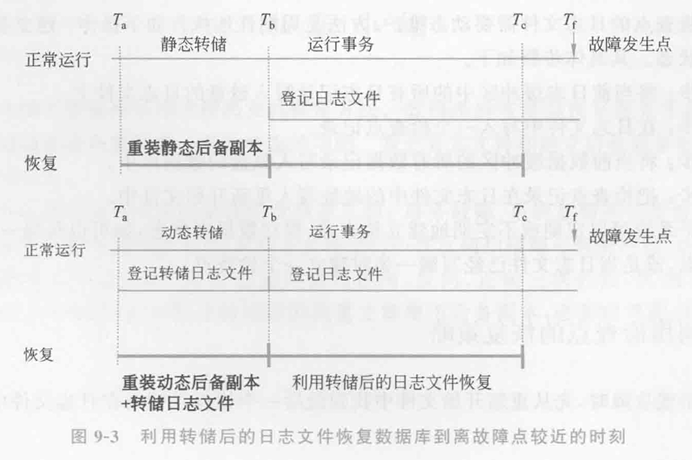
动态副本恢复示例:
使用动态副本和日志文件结合的方式,可以将数据库恢复到T₁时刻,如图:

介质故障恢复通过转储副本和日志文件结合,确保数据库恢复到故障发生前的最新一致状态。
总结与展望
数据库恢复技术是保障数据安全和系统稳定的核心手段。通过冗余数据的建立、定期数据转储和日志文件的登记,数据库能够从各种故障中快速恢复,确保业务不中断。对于不同类型的故障,数据库系统提供了UNDO和REDO操作来实现一致性恢复。