最近思维链微调范式很火,翻出来DeepMind的文章分享出来。
大致讲了推理过程中的自改进迭代思路,注重推理过程。
来自 1UC Berkeley, 2Google DeepMind, ♦Work done during an internship at Google DeepMind 的文章
文章标题:
Scaling Llm Test-Time Compute Optimally Can Be More Effective Than Scaling Model Parameters
URL:https://arxiv.org/abs/2408.03314
注:翻译可能存在误差,详细内容建议查看原始文章。
摘要
使LLM能够通过使用更多测试时间计算来改进其输出是朝着构建普遍自改进代理的关键一步,这些代理可以在开放的自然语言上操作。在这篇论文中,我们研究了推理时间计算在LLMs中的扩展性,重点在于回答这个问题:如果一个 LLM被允许使用固定但非微不足道的推理时间计算量,它能在多大程度上提高其在挑战性提示下的性能?回答这个问题不仅对实现LLM的性能有影响,而且对未来预训练和如何权衡推理时间和预训练计算也有影响。尽管它很重要,但很少有研究试图理解各种测试时间推理方法的扩展行为。此外,目前的工作主要为这些策略提供负面结果。在这项工作中,我们分析了两种扩测试时间计算的主要机制:(1)针对密集、基于过程的验证奖励模型进行搜索;以及(2)根据提示在测试时间时适应性地更新模型对响应的分布。我们发现,在这两种情况下,扩测试时间计算效果的不同方法的有效性在很大程度上取决于提示难度。这一观察结果激发了“最优运算”缩放策略的应用,该策略以每种提示最有效地分配测试时间计算的方式运行。通过使用这种最优运算策略,我们可以将测试时间计算缩放的效率提高4倍以上与最佳N基线相比。
此外,在浮点操作匹配评估中,我们发现对于基础模型在其中取得某种程度非微不足道成功率的问题,可以利用测试时间计算超越14倍更大的模型。
Enabling LLMs to improve their outputs by using more test-time computation is a critical step towards building generally self-improving agents that can operate on open-ended natural language. In this paper, we study the scaling of inference-time computation in LLMs, with a focus on answering the question: if an LLM is allowed to use a fixed but non-trivial amount of inference-time compute, how much can it improve its performance on a challenging prompt? Answering this question has implications not only on the achievable performance of LLMs, but also on the future of LLM pretraining and how one should tradeoff inference-time and pre-training compute. Despite its importance, little research attempted to understand the scaling behaviors of various test-time inference methods. Moreover, current work largely provides negative results for a number of these strategies. In this work, we analyze two primary mechanisms to scale test-time computation: (1) searching against dense, process-based verifier reward models; and (2) updating the model's distribution over a response adaptively, given the prompt at test time. We find that in both cases, the effectiveness of different approaches to scaling test-time compute critically varies depending on the difficulty of the prompt. This observation motivates applying a "compute-optimal" scaling strategy, which acts to most effectively allocate test-time compute adaptively per prompt. Using this compute-optimal strategy, we can improve the efficiency of test-time compute scaling by more than 4× compared to a best-of-N baseline.Additionally, in a FLOPs-matched evaluation, we find that on problems where a smaller base model attains somewhat non-trivial success rates, test-time compute can be used to outperform a 14× larger model.
1. 介绍
1. Introduction
人类倾向于在难题上思考更长的时间,以可靠地提高他们的决策([9, 17, 18])。
我们能否将类似的能力注入到当今的大型语言模型(LLM)中呢?更具体地说,面对一个棘手的输入问题时,我们是否能够使语言模型在测试阶段最有效地利用额外的计算能力,从而提升其回答的准确性?理论上讲,在测试时应用额外的计算应能使LLM的表现超过其训练时所达到的水平。此外,这种测试时间的能力还有望在代理性和推理任务中开拓新的途径([28, 34, 47])。例如,如果预训练模型大小可以与推理过程中的额外计算进行权衡,这将允许在实际使用场景中部署LLM,在这些场景中,可以使用较小的设备上模型代替数据中心级别的大语言模型。通过利用测试时的计算自动化提升模型输出质量,也为实现一个能在减少人类监管的情况下自主进化的通用算法提供了途径。
先前研究推理时间计算的研究提出了混合结果。一方面,一些研究表明当前的LLM能够通过测试阶段的计算改进其输出([4, 8, 23, 30, 48]),另一方面,其他研究表明这些方法在如数学推理等更复杂任务上的有效性仍然高度有限([15, 37, 43]) ,即使推理问题往往需要对现有知识而非新知识进行推断。这类矛盾的发现促使我们有必要系统地分析各种扩展测试期计算能力的方法。
Humans tend to think for longer on difficult problems to reliably improve their decisions [9, 17, 18].
Can we instill a similar capability into today's large language models (LLMs)? More specifically, given a challenging input query, can we enable language models to most effectively make use of additional computation at test time so as to improve the accuracy of their response? In theory, by applying additional computation at test time, an LLM should be able to do better than what it was trained to do. In addition, such a capability at test-time also has the potential to unlock new avenues in agentic and reasoning tasks [28, 34, 47]. For instance, if pre-trained model size can be traded off for additional computation during inference, this would enable LLM deployment in use-cases where smaller on-device models could be used in place of datacenter scale LLMs. Automating the generation of improved model outputs by using additional inference-time computation also provides a path towards a general self-improvement algorithm that can function with reduced human supervision.
Prior work studying inference-time computation provides mixed results. On the one hand, some works show that current LLMs can use test-time computation to improve their outputs [4, 8, 23, 30, 48], on the other hand, other work shows that the effectiveness of these methods on more complex tasks such as math reasoning remains highly limited [15, 37, 43], even though reasoning problems often require drawing inferences about existing knowledge as opposed to new knowledge. These sorts of conflicting findings motivate the need for a systematic analysis of different approaches for scaling test-time compute.
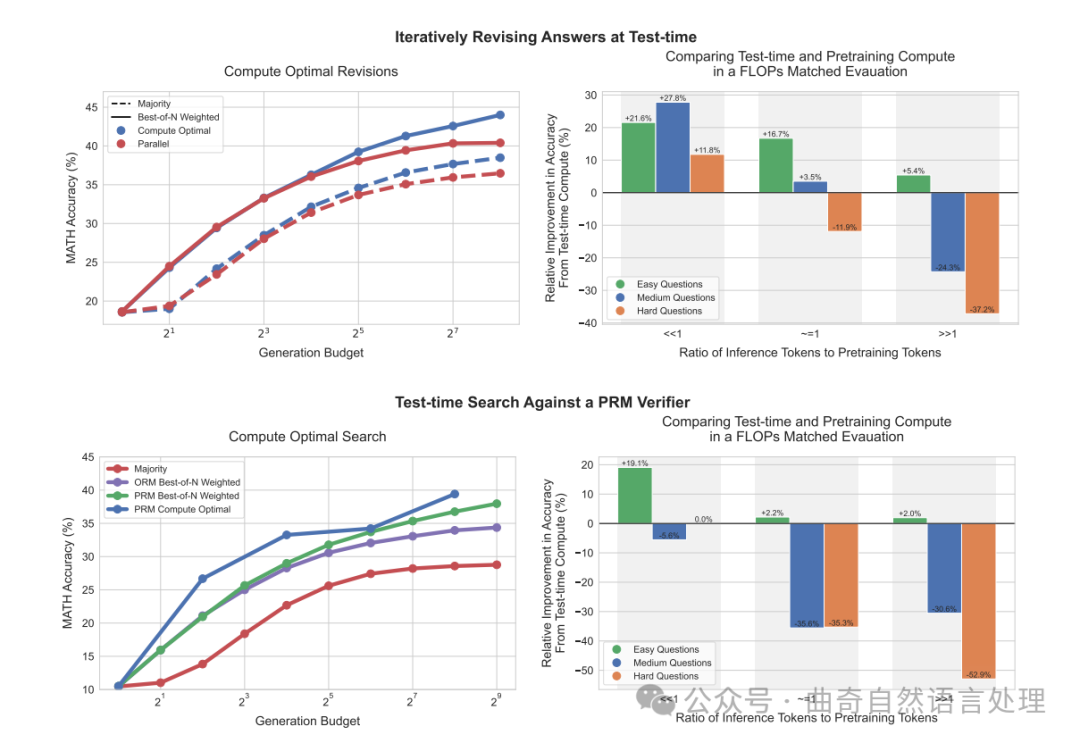
图1 ∣ 我们主要结果的概述. 左:迭代自优化(即,修订)和搜索的计算最优缩放策略。 在左边,我们将PaLM 2-S修订模型的计算最优缩放策略与基线在修订设置(顶部)以及PRM搜索设置(底部)下进行比较。我们发现,在修订情况下,标准的最好的N个策略(例如,“并行”)和计算最优缩放之间的差距逐渐扩大,使得计算最优缩放能够以4倍少的测试时间计算量超越最佳的N个策略。同样地,在PRM搜索设置下,从计算最优缩放中我们观察到对最好N个策略显著的早期改善,几乎在某些点上以4倍。较少的计算量超过最好的N个策略。具体细节请参阅第5和6节。右:比较测试时间计算量与模型参数缩放。 我们将PaLM 2-S的计算最优测试时间缩放性能与一个大约14倍大的预训练模型相比,该模型没有额外的测试时间计算(例如,贪婪采样)。我们考虑的是每个模型期望有 的预训练标记和 的推理标记的情况。通过训练更大的模型,我们实际上增加了这两项FLOPs要求。如果我们对较小的模型应用额外的测试时间计算量,以匹配这个更大模型的FLOPs要求,那么在准确性方面会有什么比较结果?我们发现,在修订(顶部)时当 << 时,测试时间计算对于较易的问题通常是更优的选择。然而,随着推理与预训练标记比率的增加,测试时间内计算在简单问题上仍然是优选的。而在难度较大的问题上,则预训练更为可取。我们在PRM搜索(底部)中也观察到了类似的趋势。更多细节请参阅第7节。
我们有兴趣理解增加测试阶段计算的好处。可以说,最简单且研究最为透彻的扩大测试阶段计算的方法是最佳N选一采样:从基础LLM平行地采样N个输出,并依据学习到的验证器或奖励模型选出分数最高的一个[7, 22]。然而,这种方法并非利用测试阶段计算提升LLM性能的唯一途径。通过修改获取响应的提议分布(例如,要求基础模型“依次”修正其原始响应[28]),或是改变验证器的使用方式(例如,训练基于过程的密集型验证器,并针对此验证器进行搜索[22, 45]),如我们在论文中所示,测试阶段计算的能力可能大幅提高。
为了理解增加测试阶段计算的好处,我们对具有挑战性的MATH[13]基准进行了实验,使用了PaLM-2[3]模型,这些模型特别微调至能够修订。在MATH上,需要进行特定于能力的微调,才能将修订和验证能力引入到基础模型中。
We are interested in understanding the benefits of scaling up test-time compute. Arguably the simplest and most well-studied approach for scaling test-time computation is best-of-N sampling: sampling N outputs in "parallel" from a base LLM and selecting the one that scores the highest per a learned verifier or a reward model [7, 22]. However, this approach is not the only way to use test-time compute to improve LLMs. By modifying either the proposal distribution from which responses are obtained (for instance, by asking the base model to revise its original responses "sequentially" [28]) or by altering how the verifier is used (e.g. by training a process-based dense verifier [22, 45] and searching against this verifier), the ability scale test-time compute could be greatly improved, as we show in the paper.
To understand the benefits of scaling up test-time computation, we carry out experiments on the challenging MATH [13] benchmark using PaLM-2 [3] models specifically fine-tuned1to either revise
1Capability-specific finetuning is necessary to induce revision and verification capabilities into the base model on MATH
对于错误答案[28](例如,改进提议分布;第6节)或使用基于过程的奖励模型(PRM)[22, 45](第5节)验证答案中各个步骤的正确性,在这两种方法下,我们发现某个特定测试时间计算策略的有效性在很大程度上取决于手头具体问题的本质以及采用的基础LLM。例如,在基础LLM已经能够轻松产生合理响应的较易问题上,允许模型通过预测N次修订序列(即,修改提议分布)迭代优化其初始答案,可能比并行采样N个独立响应更有效利用测试时间计算资源。反之,在需要探索许多不同解题高级策略的更难题目中,并行重新采样新的独立响应或利用基于过程的奖励模型进行树搜索,可能是更为有效的使用测试时间计算的方式。这一发现突显了采用适应性的“计算最优”策略来扩展测试时间计算的需求——其中具体运用测试时间计算的方法取决于提示内容以获得最优化的资源利用。我们还展示了从基础LLM的角度出发对问题难度(第4节)的概念,可以预测测试时间计算的有效性,使我们在接收到一个提示时能够实质上实现“计算最优”的策略。通过妥善分配测试时间计算资源,我们能够在很大程度上改善测试时间计算的扩展能力,在仅使用大约4倍较少的计算量下超越N选最佳基准(结合修订和搜索)的表现;见第5与6节。
利用我们改进的测试时间计算扩展策略,我们的目标是探究在多大程度上,测试时间计算可以有效地替代额外预训练。我们在较小模型加上额外测试时间计算资源与14倍更大的模型进行等量运算符(FLOPs)对比分析。我们发现,在较易和中间难度问题上,甚至在硬性问题上(具体取决于对预训练与推理工作负荷的特定条件),额外的测试时间计算往往优于扩展预训练规模。这一发现表明,在某些情况下,专注于扩大模型尺寸以进行更多预训练不如先采用较小的模型进行较少计算资源的预训练,再通过增加测试时的计算来提升模型输出效果。尽管如此,对于最具挑战性的问题,我们发现在提升测试时间计算方面所获得的好处非常有限。相反地,在这些问题上,我们发现增加额外预训练计算量更有效促进进展,这表明当前的测试时间计算扩增策略与扩大预训练规模可能并非可一比一转换。总体而言,即使采用相对朴素的方法,升级测试时计算资源已经显现出优于加大预训练的优势,且随着测试时间策略的完善将进一步提升效果。长远来看,这暗示了未来可能会减少在预训练阶段花费的FLOPs数量,而将更多FLOPs用于推理阶段。
incorrect answers [28] (e.g. improving the proposal distribution; Section 6) or verify the correctness of individual steps in an answer using a process-based reward model (PRM) [22, 45] (Section 5). With both approaches, we find that the efficacy of a particular test-time compute strategy depends critically on both the nature of the specific problem at hand and the base LLM used. For example, on easier problems, for which the base LLM can already readily produce reasonable responses, allowing the model to iteratively refine its initial answer by predicting a sequence of N revisions (i.e., modifying the proposal distribution), may be a more effective use of test-time compute than sampling N independent responses in parallel. On the other hand, with more difficult problems that may require searching over many different high-level approaches to solving the problem, re-sampling new responses independently in parallel or deploying tree-search against a process-based reward model is likely a more effective way to use test-time computation. This finding illustrates the need to deploy an adaptive "compute-optimal" strategy for scaling test-time compute, wherein the specific approach for utilizing test-time compute is selected depending on the prompt, so as to make the best use of additional computation. We also show that a notion of question difficulty (Section 4) from the perspective of the base LLM can be used to predict the efficacy of test-time computation, enabling us to practically instantiate this 'compute-optimal' strategy given a prompt. By appropriately allocating test-time compute in this way, we are able to greatly improve test-time compute scaling, surpassing the performance of a best-of-N baseline while only using about 4x less computation with both revisions and search (Sections 5 and 6).
Using our improved test-time compute scaling strategy, we then aim to understand to what extent test-time computation can effectively substitute for additional pretraining. We conduct a FLOPs-matched comparison between a smaller model with additional test-time compute and pretraining a 14x largermodel. We find that on easy and intermediate questions, and even hard questions (depending on the specific conditions on the pretraining and inference workload), additional test-time compute is often preferable to scaling pretraining. This finding suggests that rather than focusing purely on scaling pretraining, in some settings it is be more effective to pretrain smaller models with less compute, and then apply test-time compute to improve model outputs. That said, with the most challenging questions, we observe very little benefits from scaling up test-time compute. Instead, we find that on these questions, it is more effective to make progress by applying additional pretraining compute, demonstrating that current approaches to scaling test-time compute may not be 1-to-1 exchangeable with scaling pretraining. Overall, this suggests that even with a fairly naïve methodology, scaling up test-time computation can already serve to be more preferable to scaling up pretraining, with only more improvements to be attained as test-time strategies mature. Longer term, this hints at a future where fewer FLOPs are spent during pretraining and more FLOPs are spent at inference.
2. 统一的测试时计算视角:提议者和验证者
2. A Unified Perspective On Test-Time Computation: Proposer And Verifier
我们首先统一使用测试时计算的方法,然后分析一些代表性方法。
首先,我们将利用额外的测试时计算视为通过给定提示条件,在测试时适应性地修改模型预测分布的方式。理想情况下,测试时计算应该修改这个分布,从而生成比直接从LLM采样更好的输出。
一般来说,有两种方式可以调整LLM分布:**(1)在输入层面上**:
We first unify approaches for using test-time computation and then analyze some representative methods.
First, we view the use of additional test-time compute through the lens of modifying the model's predicted distribution adaptively at test-time, conditioned on a given prompt. Ideally, test-time compute should modify the distribution so as to generate better outputs than naïvely sampling from the LLM itself would.
In general, there are two knobs to induce modifications to an LLM's distribution: (1) at the input level:
通过附加一组令牌来增强给定的提示,这些令牌让LLM以此为基础获得修改后的分布,或者在(2)输出级别:从标准语言模型中抽样多个候选方案,并对这些候选方案进行手术。换句话说,我们可以通过修改由LLM本身诱导的提议分布使其优于仅依据提示条件的基础水平,或利用一些事后处理的验证器或评分器来进行输出调整。这一过程与马尔可夫链蒙特卡洛(MCMC)[2]的复杂目标分布抽样相似,但通过结合简单的提议分布和打分函数实现。直接修改输入令牌来改变提议分布并使用验证器是我们的研究中的两个独立维度。
修改提议分布。改善提议分布的一种方法是直接针对特定推理任务优化模型,采用类RL启发式的微调方法如STaR或ReSTEM [35, 50]。
需要注意的是,这些技术并不利用任何额外的输入令牌,而是专门对模型进行微调以诱导出改进后的提议分布。相反,诸如自我批评[4, 8, 23, 30]等技术使模型自行在测试时间改善其提议分布,通过指示它迭代地批判和修正自己的输出。由于直接提示现成的模型无法有效促进在测试时的有效修订,我们特别对模型进行了微调,使其能够在基于复杂推理的任务中迭代修改答案。为了达成这一目标,我们将利用根据最佳N策略指导下的在政策数据上的微调方法,改进模型响应[28]。
优化验证器。在其抽象的提议分布和验证器的框架下,验证器用于汇总或挑选来自提议分布的最佳答案。最典型地使用此类验证器的方式是通过应用最佳N抽样,即抽取N个完整解法,然后根据验证器选出最优解答[7]。然而,这一方法可以通过训练过程型验证器[22]来进一步提升,或者说,一个过程奖励模型(PRM),该模型预测每个解法中的每个中间步骤的正确性,而不仅仅是最终结果。随后,我们可以使用这些逐步预测执行基于解空间树搜索,这允许了一个可能比简单最佳N更具效率和效果的方法针对验证器进行搜寻[6, 10, 48]。
by augmenting the given prompt with an additional set of tokens that the LLM conditions on to obtain the modified distribution, or (2) at the output level: by sampling multiple candidates from the standard LM and performing surgery on these candidates. In other words, we could either modify the proposal distribution induced by the LLM itself such that it is an improvement over naïvely conditioning on the prompt or we could use some post-hoc verifiers or scorers to perform output modifications. This process is reminiscent of Markov chain Monte Carlo (MCMC) [2] sampling from a complex target distribution but by combining a simple proposal distribution and a score function. Modifying the proposal distribution directly by altering input tokens and using a verifier form two independent axes of our study.
Modifying the proposal distribution. One way to improve the proposal distribution is to directly optimize the model for a given reasoning task via RL-inspired finetuning methods such as STaR or ReSTEM [35, 50].
Note that these techniques do not utilize any additional input tokens but specifically finetune the model to induce an improved proposal distribution. Instead, techniques such as self-critique [4, 8, 23, 30] enable the model itself to improve its own proposal distribution at test time by instructing it to critique and revise its own outputs in an iterative fashion. Since prompting off-the-shelf models is not effective at enabling effective revisions at test time, we specifically finetune models to iteratively revise their answers in complex reasoning-based settings. To do so, we utilize the approach of finetuning on on-policy data with Best-of-N guided improvements to the model response [28].
Optimizing the verifier. In our abstraction of the proposal distribution and verifier, the verifier is used to aggregate or select the best answer from the proposal distribution. The most canonical way to use such a verifier is by applying best-of-N sampling, wherein we sample N complete solutions and then select the best one according to a verifier [7]. However, this approach can be further improved by training a process-based verifier [22], or a process reward model (PRM), which produces a prediction of the correctness of each intermediate step in an solution, rather than just the final answer. We can then utilize these per-step predictions to perform tree search over the space of solutions, enabling a potentially more efficient and effective way to search against a verifier, compared to naïve best-of-N [6, 10, 48].
3. 如何最优地扩大测试时计算规模
3. How To Scale Test-Time Computation Optimally
鉴于各种方法的统一,我们现在希望了解如何最有效地利用测试时间计算以提高LM在给定提示下的性能。具体来说,我们希望建立:
问题设置

我们获得一个提示和一个用于解决问题的测试时间计算预算。根据上述抽象框架,有不同的方法来利用测试时间计算。这些方法的效率可能因具体给定的问题而异。我们如何确定*最有效*地利用测试时间计算的方法以解决给定的提示?而这种方法跟简单使用更大预训练模型相比效果会怎样?
无论是在优化提议分布还是在验证器上进行搜索时,都可以通过调整几种不同的超参数来决定如何分配测试时间的计算预算。
例如,在将一个用于修订的模型作为提议分布且基于ORM的验证中,我们既可以花费整个测试时间计算预算生成N个独立样本并行地从模odel,并应用N中选最佳的策略;或者顺序地采样N次修正,使用修正模型,然后利用ORM选择序列中的最优答案;或者在这两个极端之间找到平衡。直观上来说,“较容易”的问题可能更多受益于修订,因为模型初始生成的样本更有可能在正确的道路上但可能只需要进一步精细调整。
另一方面,挑战性的问题可能需要对不同层面的问题解决方案进行更多的探索,因此在这种情况下,独立并行采样多次可能更为有利。
就验证器而言,我们还有选择不同搜索算法的选项(例如,束状搜索,前瞻搜索,N中选最佳),其中每种可能根据手上的验证质量和提议分布表现出不同的特性。在更难的问题上,相比简单的N中选最佳或多数基线策略,更复杂的搜索程序可能会更加有用。
Given the unification of various methods, we would now like to understand how to most effectively utilize test-time computation to improve LM performance on a given prompt. Concretely we wish to answer: Problem setup.
We are given a prompt and a test-time compute budget within which to solve the problem. Under the abstraction above, there are different ways to utilize test-time computation. Each of these methods may be more or less effective depending on the specific problem given. How can we determine the most effective way to utilize test-time compute for a given prompt? And how well would this do against simply utilizing a much bigger pretrained model?
When either refining the proposal distribution or searching against a verifier, there are several different hyper-parameters that can be adjusted to determine how a test-time compute budget should be allocated.
For example, when using a model finetuned for revisions as the proposal distribution and an ORM as the verifier, we could either spend the full test-time compute budget on generating N independent samples in parallel from the model and then apply best-of-N, or we could sample N revisions in sequence using a revision model and then select the best answer in the sequence with an ORM, or strike a balance between these extremes. Intuitively, we might expect "easier" problems to benefit more from revisions, since the model's initial samples are more likely to be on the right track but may just need further refinement.
On the other hand, challenging problems may require more exploration of different high-level problem solving strategies, so sampling many times independently in parallel may be preferable in this setting.
In the case of verifiers, we also have the option to choose between different search algorithms (e.g.
beam-search, lookahead-search, best-of-N), each of which may exhibit different properties depending on the quality of the verifier and proposal distribution at hand. More sophisticated search procedures might be more useful in harder problems compared to a much simpler best-of-N or majority baseline.
3.1. 测试时计算最优缩放策略
3.1. Test-Time Compute-Optimal Scaling Strategy
一般来说,我们因此希望为给定问题选择最优的测试时间计算资源分配。为此,对于任何给定的利用测试时间计算的方法(例如,在本文中是对修订和验证器进行搜索,在其他地方还有各种其他方法),我们定义“测试时间 计算-最优缩放策略”是那种在给定提示下,选择对应于特定测试时间策略且具有最大性能效益的超参数的策略。形式上,我们将定义为
对于给定提示: ,模型诱导出的自然语言输出令牌分布,在使用测试时间计算超参数 和计算预算 的情况下。我们希望选取能够最大化目标分布准确性的超参数 ,针对特定问题。我们正式地表达为:
其中 表示问题 q 的真实正确答案, 代表在计算预算为 N 的情况下,问题 q 的测试时计算最优缩放策略。
In general, we would therefore like to select the optimal allocation of our test-time compute budget for a given problem. To this end, for any given approach of utilizing test-time compute (e.g., revisions and search against a verifier in this paper, various other methods elsewhere), we define the "test-timecompute-optimal scaling strategy" as the strategy that chooses hyperparameters corresponding to a given test-time strategy for maximal performance benefits on a given prompt at test time. Formally, define Target(, , ) as the distribution over natural language output tokens induced by the model for a given prompt , using test-time compute hyper-parameters , and a compute budget of . We would like to select the hyper-parameters which maximize the accuracy of the target distribution for a given problem. We express this formally as:
3.2. 计算最优缩放的问题难度估计
3.2. Estimating Question Difficulty For Compute-Optimal Scaling
为了有效地分析在第二节中讨论的不同机制(例如提议分布和验证器)的测试时间扩展特性,我们将制定一个关于给定提示统计量函数的最优策略 近似值 。这个统计量估计了对于特定提示的一种“难度”概念。计算优化型策略被定义为基于该提示难度的函数。尽管只是问题1所示问题的大致解决方案,我们发现它仍能显著提高性能,相比将推断时间运算资源随机分配或均匀采样的基线策略。
我们对问题难度的估计将给定的问题归类到五个不同的难度级别之中。然后我们可以使用这种离散化难度分类来在特定测试时间计算预算下,在验证集上评估 。接着,我们在测试集上应用这些运算优化型策略。具体来说,我们独立地为每个难度区间选择最佳的测试时间计算策略。这样,问题难度成了设计运算最优策略之下一个给定问题的充分统计量。
定义问题难度。
沿用Lightman等人 [22]的方法,我们将问题难度定义为基于特定基础LLM(大语言模型)的一个函数。具体而言,我们根据每个测试集上问题的model在pass@1率——从2048个样本中估算出来——将这些结果分为五个分位数,每一个代表一个递增的难度级别。我们发现这种特定于模型的难度区间比MATH数据集中的人工标定难度区间更能预测利用测试时间运算的有效性。
尽管如此,也需注意到上述评估问题难度的方式假设了能访问到真相检查函数来准确判断正确性,而在实际部署中我们仅拿到无法得知答案的问题提示,并没有这样一个函数。为了使基于难度的运算优化扩展策略在实践中可行,它首先需要估计难度,接着利用合适的策略解决这个问题。因此,我们将问题难度约化至一个模型预测出的难度概念,该概念对于每个问题都使用2048个样本在其上运行的学习验证器获得的平均最终答案得分数执行相同的分箱处理——而非基于真实的正确性检查——来进行评估。我们把此设定叫做模型预测难度,而依赖于真实正确性的设定则是真相检测难度。
虽然模型预测难度消除了对了解真相标签的需求,按照这种方式估计难度在推理期间依然会带来额外运算成本。然而,这一时间的推断花费可以被包涵在实际运行推断时间内策略的成本里(例如,在使用验证器时,相同的推理计算可用于搜索)。更宽泛的角度来说,这类似强化学习中常见的探索与利用之间的权衡:在真实的部署情况下,我们必须平衡评估难度所消耗的运算和应用最优化算计法之间的关系。这是未来研究的关键领域(更多细节请看第八节),而我们的试验主要是简化处理,没有考虑这部分开销 - 因为我们旨在展示通过有效分配测试时间运算力能够达到的效果。
出于避免使用同一组测试集来计算难度区间以及选择运算最优策略时可能产生的混淆变量,我们对每个难度级别的题目在测试集中进行两倍交叉验证。我们将基于一份折上的表现择优挑选最佳策略,再利用该策略评估另一份折上的表现并反其道而行之,将两个验证折的结论予以平均化处理。
In order to effectively analyze the test-time scaling properties of the different mechanisms discussed in Section 2 (e.g. the proposal distribution and the verifier), we will prescribe an approximation to this optimal strategy () as a function of a statistic of a given prompt. This statistic estimates a notion of difficulty for a given prompt. The compute-optimal strategy is defined as a function of the difficulty of this prompt. Despite being only an approximate solution to the problem shown in Equation 1, we find that it can still induce substantial improvements in performance over a baseline strategy of allocating this inference-time compute in an ad-hoc or uniformly-sampled manner.
Our estimate of the question difficulty assigns a given question to one of five difficulty levels. We can then use this discrete difficulty categorization to estimate () on a validation set for a given test-time compute budget. We then apply these compute-optimal strategies on the test-set. Concretely, we select the best performing test-time compute strategy for each difficulty bin independently. In this way, question difficulty acts as a sufficient statistic of a question when designing the compute-optimal strategy.
Defining difficulty of a problem. Following the approach of Lightman et al. [22], we define question difficulty as a function of a given base LLM. Specifically, we bin the model's pass@1 rate - estimated from 2048 samples - on each question in the test set into five quantiles, each corresponding to increasing difficulty levels. We found this notion of model-specific difficulty bins to be more predictive of the efficacy of using test-time compute in contrast to the hand-labeled difficulty bins in the MATH dataset.
That said, we do note that assessing a question's difficulty as described above assumes oracle access to a ground-truth correctness checking function, which is of course not available upon deployment where we are only given access to test prompts that we don't know the answer to. In order to be feasible in practice, a compute-optimal scaling strategy conditioned on difficulty needs to first assess difficulty and then utilize the right scaling strategy to solve this problem. Therefore, we approximate the problem's difficulty via a model-predicted notion of difficulty, which performs the same binning procedure over the the averaged final answer score from a learned verifier (and not groundtruth answer correctness checks) on the same set of 2048 samples per problem. We refer to this setting as model-predicted difficulty and the setting which relies on the ground-truth correctness as oracle difficulty.
While model-predicted difficulty removes the need for need knowing the ground truth label, estimating difficulty in this way still incurs additional computation cost during inference. That said, this one-time inference cost can be subsumed within the cost for actually running an inference-time strategy (e.g., when using a verifier, one could use the same inference computation for also running search). More generally, this is akin to exploration-exploitation tradeoff in reinforcement learning: in actual deployment conditions, we must balance the compute spent in assessing difficulty vs applying the most computeoptimal approach. This is a crucial avenue for future work (see Section 8) and our experiments do not account for this cost largely for simplicity, since our goal is to present some of the first results of what is in fact possible by effectively allocating test-time compute.
So as to avoid confounders with using the same test set for computing difficulty bins and for selecting the compute-optimal strategy, we use two-fold cross validation on each difficulty bin in the test set. We select the best-performing strategy according to performance on one fold and then measure performance using that strategy on the other fold and vice versa, averaging the results of the two test folds.
4. 实验设置
4. Experimental Setup
我们首先概述实验设置,用于进行分析,其中包括多种验证器设计选择和提议分布,随后的部分将给出分析结果。
数据集。
当模型已经具备回答问题所需的所有基本“知识”,而主要的挑战在于从这些知识中得出(复杂的)推理时,我们预计测试时间计算将会最为有效。为此,我们将焦点放在MATH[13]基准上,该基准包含了一系列高中竞赛水平的数学题目,难度层次多样。在所有实验中,我们都使用Lightman等人[22]使用的数据集分割,其中包括1.2万训练题和500道测试题。
模型。
我们采用PaLM 2-S*[3](Codey)基础模型来进行分析。我们认为这个模型代表了众多现代大型语言模型的能力,因此认为我们的发现可能适用于类似的模型。最重要的是,该模型在MATH上的表现非同寻常,但并未达到饱和状态,因此我们预期此模型为我们提供了一个良好的测试平台。
We first outline our experimental setup for conducting this analysis with multiple verifier design choices and proposal distributions, followed by the analysis results in the subsequent sections.
Datasets. We expect test-time compute to be most helpful when models already have all the basic "knowledge" needed to answer a question, and instead the primary challenge is about drawing (complex) inferences from this knowledge. To this end, we focus on the MATH [13] benchmark, which consists of high-school competition level math problems with a range of difficulty levels. For all experiments, we use the dataset split consisting of 12k train and 500 test questions, used in Lightman et al. [22].
Models. We conduct our analysis using the PaLM 2-S* [3] (Codey) base model. We believe this model is representative of the capabilities of many contemporary LLMs, and therefore think that our findings likely transfer to similar models. Most importantly, this model attains a non-trivial performance on MATH and yet has not saturated, so we expect this model to provide a good test-bed for us.
5. 通过验证器扩大测试时计算量
5. Scaling Test-Time Compute Via Verifiers
在这一节中,我们分析了通过优化验证器以尽可能有效的方式扩展测试时间计算的方法。为此,我们研究了使用进程验证器(PRMs)执行测试时间搜索的不同方法,并分析了这些不同方法的测试时间计算扩展特性。
In this section we analyze how test-time compute can be scaled by optimizing a verifier, as effectively as possible. To this end, we study different approaches for performing test-time search with process verifiers (PRMs) and analyze the test-time compute scaling properties of these different approaches.
5.1. 可搜索的验证器训练
5.1. Training Verifiers Amenable To Search
PRM 训练。原来的 PRM 训练 [22, 42] 使用的是由人工众包工作者标注的标签。虽然 Lightman 等人 [22] 发布了他们的 PRM 训练数据(即,PRM800k 数据集),我们却发现这些数据对我们而言在很大程度上效果欠佳。我们发现,即使采用像最好的 N 采样这样的简单策略,也很容易利用在这种数据集上训练的 PRM。我们推测这很可能是因为他们数据集中 GPT-4 生成样本与我们的 PaLM 2 模型之间的分布偏移所致。为了避免进行收集我们 PaLM 2 模型的人工众包 PRM 标签这一昂贵过程,我们采用 Wang 等人 [45] 的方法在没有人工标签的情况下监督 PRMs,并使用从解决方案每一步运行蒙特卡洛推演所得到的每次步骤正确性估计。因此,我们的 PRM 的每个步骤预测相当于对基础模型采样策略未来的奖励价值估计,这与最近的工作 [31, 45] 类似。我们还与一个 ORM 基线(附录 F)进行了比较但发现我们的 PRM 一直优于 ORM。因此,本节中的所有搜索实验使用的是 PRM 模型。有关 PRM 训练的更多细节请参阅附录 D。
答案聚合。在测试时,过程验证器可用于为从基础模型采样的一组解中每个单独步骤评分。为了让 PRM 选择最好的 N 答案,我们需要一个可以跨每个答案的所有每步评分进行聚合以确定最佳候选正确答案的函数。为此,我们首先聚合每个独立答案的每步评分以取得完整答案的最终分数(逐步聚合)。然后对所有答案聚合以决定最佳答案(答案间聚合)。具体而言,我们这样处理逐步和答案间的聚合:
-
逐步聚合。我们没有使用乘法或最小值来聚合每步评分 [22, 45],而是使用 PRM 在最后一步的预测作为完整解答分数。
我们发现这在我们研究的所有聚合方法中表现最佳(参阅附录 E)。
-
答案间聚合。我们遵循 Li 等人 [21] 的做法应用“最好的 N 加权”选择而不是标准的最佳 N。最好的加权 N 选择对具有相同最终答案的所有解决方案的验证器正确性评分进行边际化,选取总和最大的最终答案。
PRM training. Originally PRM training [22, 42] used human crowd-worker labels. While Lightman et al. [22] released their PRM training data (i.e., the PRM800k dataset), we found this data to be largely ineffective for us. We found that it was easy to exploit a PRM trained on this dataset via even naïve strategies such as best-of-N sampling. We hypothesize that this is likely a result of the distribution shift between the GPT-4 generated samples in their dataset and our PaLM 2 models. Rather than proceeding with the expensive process of collecting crowd-worker PRM labels for our PaLM 2 models, we instead apply the approach of Wang et al. [45] to supervise PRMs without human labels, using estimates of per-step correctness obtained from running Monte Carlo rollouts from each step in the solution. Our PRM's per-step predictions therefore correspond to value estimates of reward-to-go for the base model's sampling policy, similar to recent work [31, 45]. We also compared to an ORM baseline (Appendix F) but found that our PRM consistently outperforms the ORM. Hence, all of the search experiments in this section use a PRM model. Additional details on PRM training are shown in Appendix D.
Answer aggregation. At test time, process-based verifiers can be used to score each individual step in a set of solutions sampled from the base model. In order to select the best-of-N answers with the PRM, we need a function that can aggregate across all the per-step scores for each answer to determine the best candidate for the correct answer. To do this, we first aggregate each individual answer's per-step scores to obtain a final score for the full answer (step-wise aggregation). We then aggregate across answers to determine the best answer (inter-answer aggregation). Concretely, we handle step-wise and inter-answer aggregation as follows:
-
Step-wise aggregation. Rather than aggregating the per-step scores by taking the product or minimum [22, 45], we instead use the PRM's prediction at the last step as the full-answer score.
We found this to perform the best out of all aggregation methods we studied (see Appendix E).
-
Inter-answer aggregation. We follow Li et al. [21] and apply "best-of-N weighted" selection rather than standard best-of-N. Best-of-N weighted selection marginalizes the verifier's correctness scores across all solutions with the same final answer, selecting final answer with the greatest total sum.
5.2. 针对A prm的搜索方法
5.2. Search Methods Against A Prm
我们在测试时间通过搜索方法优化PRM。我们研究了三种从少量示例提示的基本LLM中采样输出的搜索方法(参见附录G)。图2展示了这一过程。
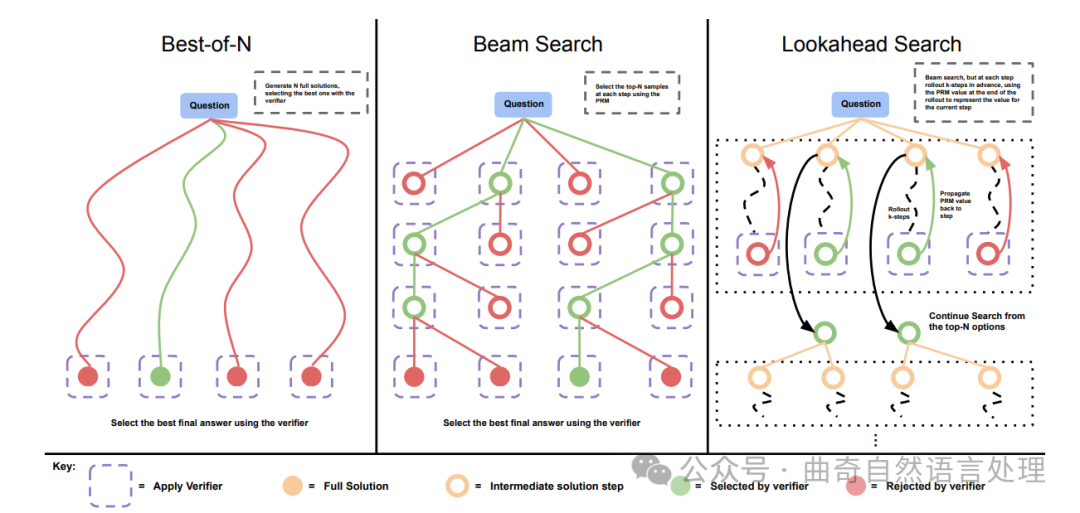
图 2 ∣ 比较不同的 PRM 搜索方法. 左: 最佳-N 样本 N 完整答案,然后根据 PRM 的最终分数选择最佳答案。中: 束搜索在每一步采样 N 个候选者,并依据 PRM 选出前 M 名以继续进行搜索。右: 展望-搜索将束搜索的每一步扩展到利用 k 步展望,同时评估需要保留哪部分步骤以及继续从何处开始搜索。因此,展望-搜索需要更多的计算量。
N选最佳加权。我们独立地从基本LLM中抽取N个答案,然后根据PRM的最终答案判断选择最佳答案。
束搜寻。束搜寻通过对其按步骤预测进行搜索来优化PRM。我们的实现类似于BFS-V[10, 48]。具体来说,我们考虑了一个固定数量的束(beam)和一个束宽度(beam width)。然后执行以下步骤:
-
对解决方案的第一步抽样初始预测
-
根据PRM预测到结束的逐步奖励估计对产生的步骤进行评分(这也对应着从开始部分得到的总奖励,因为在这种设置下奖励是稀疏的)
-
仅保留最高得分的前几步
-
现在从每个候选步骤中,从下一步抽样提案,总共得到N/ M× M候选前缀。然后重复步骤2-4。
我们运行此算法直到解决方案结束或达到束扩展的最大轮数(在我们的案例是40)。搜索结束时我们得到了N个最终答案候选项,我们应用上述的N选最佳加权选择来做出最终的答案预测。
展望搜索. 展望搜索修改了束搜索评估个步的方法。它使用展望回放来提高在搜索过程每一步中 PRM 的价值估计准确性。具体而言,在束搜索的每一步中,我们不是利用当前步骤的 PRM 分数来选择首位的候选者; 而是进行模拟,向前回放最多 步,并且如果到达解的终点则提前停止。为了减少模拟回放中的变化度,我们使用温度为0来进行回放。在回放结束时 PRM 的预测值被用来给束搜索当前步骤评分。换言之,我们可以将束搜索看作展望搜索的一个特殊情况,其中 k = 0。对于准确的 PRM 而言,增加 应该能提高每一步价值估计的准确性,但代价是额外计算需求的增加。此外还要注意到这种版本的展望搜索实际上是 MCTS [38] 的一个特例,在此特例中去除了 MCTS 中为促进探索设计的随机元素;因为我们已训练好 PRM 并且不再更新它了,所以这些随机元素大都只对学习价值函数有用(这个功能我们已经通过我们的 PRM 实现),但对于测试期我们需要充分利用而不是继续探索而言它们用处不大。因此展望搜索在很大程度上代表了 MCTS 风格方法应用于测试时期的使用方式。
Figure 2 ∣ Comparing different PRM search methods. Left: Best-of-N samples N full answers and then selects the best answer according to the PRM final score. Center: Beam search samples N candidates at each step, and selects the top M according to the PRM to continue the search from. Right: lookahead-search extends each step in beam-search to utilize a k-step lookahead while assessing which steps to retain and continue the search from. Thus lookahead-search needs more compute.
Lookahead search. Lookahead search modifies how beam search evaluates individual steps. It uses lookahead rollouts to improve the accuracy of the PRM's value estimation in each step of the search process. Specifically, at each step in the beam search, rather than using the PRM score at the current step to select the top candidates, lookahead search performs a simulation, rolling out up to steps further while stopping early if the end of solution is reached. To minimize variance in the simulation rollout, we perform rollouts using temperature 0. The PRM's prediction at the end of this rollout is then used to score the current step in the beam search. That is, in other words, we can view beam search as a special case of lookahead search with = 0. Given an accurate PRM, increasing should improve the accuracy of the per-step value estimates at the cost of additional compute. Also note that this version of lookahead search is a special case of MCTS [38], wherein the stochastic elements of MCTS, designed to facilitate exploration, are removed since the PRM is already trained and is frozen. These stochastic elements are largely useful for learning the value function (which we've already learned with our PRM), but less useful at test-time when we want to exploit rather than explore. Therefore, lookahead search is largely representative of how MCTS-style methods would be applied at test-time.
5.3. 分析结果:使用验证器进行搜索的测试时间缩放
5.3. Analysis Results: Test-Time Scaling For Search With Verifiers
我们现在比较各种搜索算法的结果,并确定一个依赖于提示难度的计算最优缩放策略用于搜索方法。
比较搜索算法。我们首先对多种不同的搜索设置进行扫瞄。除了标准的最佳N选一(best-of-N)方法之外,我们还对区分不同树搜索方法的主要两个参数进行扫瞄:波束宽度 M和前瞻步数k 。虽然我们无法广泛地遍历每个单个配置,但我们以256的最大预算对以下设置进行了扫瞄:
-
波束搜索,其中波束宽度被设定为 √N,此处的 是生成预算。
-
固定波束宽度为4的波束搜索。
-
对于光束搜索设置 1) 和 2),应用了步长为 k=3 的前瞻搜索。
-
对于光束搜索设置 1),应用了步长为 k=1 的前瞻搜索。
为了公平地比较不同生成预算下的搜索方法,我们建立了一个估算每种方法成本的协议。我们将一次生成定义为从基本 LLM 中采样的答案。对于光束搜索和 N 个选择中的最优解而言,生成预算是指光束的数量和 N 的值分别对应。
然而,前瞻搜索需要额外的计算资源:在每个搜索步骤中,我们向前采样额外的步数。因此,我们将前瞻搜索的成本定义为 N× ( k + 1) 次样本。
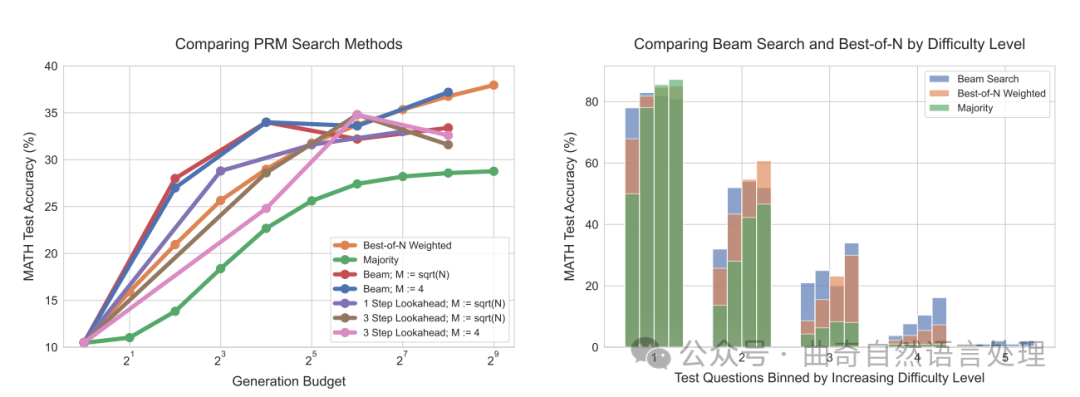
图 3
结果。如图 3(左)所示,在较小的生成预算下,光束搜索显著优于 N 个选择中的最优解。然而,随着预算的增加,这种提升逐渐减小,光束搜索常常表现得不如 N 个选择中的最优基线。我们还发现,在同样的生成预算下,前瞻搜索通常比其他方法效果差,这可能是由于模拟前瞻步骤所需的额外计算导致的。搜索收益的减少可能是因为过度利用了 PRM 的预测结果。例如,我们在某些实例中观察到(如图 29 所示),搜索会导致模型在解决方案末尾生成低信息量且重复的步骤。在其他情况下,我们发现过度优化搜索可能导致解决方案变得过短,仅包含 1-2 步骤。
这就是为什么最强大的搜索方法(即前瞻搜索)表现最差的原因。
我们在附录 M 中列出了一些通过搜索找到的例子。
搜索在哪类问题上有所改进?为了了解如何计算最优地扩展搜索方法,我们现在进行了难度区间分析。具体来说,我们将光束搜索 ( = 4) 和 N 个选择中的最优解进行比较。
由图 3(右)可知,虽然在高生成预算下,整体而言光束搜索和 N 个选择中的最优解表现相似,但在不同的难度区间内评估它们的有效性揭示了截然不同的趋势。对于简单问题(第 1 和 2 级别),作为两种方法中更强大的优化器,光束搜索在随着生成预算的增加而降低了性能,这表明了 PRM 信号可能被过度利用的迹象。相反,在较难的问题(第 3 和 4 级别)上,光束搜索始终优于 N 个选择中的最优解。对于最难的问题(第 5 级别),没有任何方法能取得实质性进展。
这些发现符合直觉:对于简单问题,我们可能会期望验证者的正确性评估主要是正确的。因此,通过应用额外的优化即光束搜索,我们只会放大任何由验证者学习到的异常特征,从而导致性能降低。对于更难的问题,基本模型首先采样出正确答案的概率要小得多,因此搜索可以用来帮助引导模型产生正确的答案。
计算最优搜索。鉴于上述结果,很明显,问题难度可以用作预测给定计算预算下最适搜索策略的一个有用统计量。此外,根据这个难度指标选择的最佳搜索策略可能会有大幅度的变化。因此,我们可视化了“计算最优”的增长趋势,即图中每个难度级别表现最佳的搜索策略分别对应在图 4 中。我们看到,在较低生成预算的情况下,使用实际和预测难易度时,“计算最优”扩展可以接近地以至多 4 倍测试时间较少计算资源(例如,16 次对比于 64 次生成)大大超越 N 个选择中的最优解。而在较高预算区间内,当使用预测难度时这些优势在一定程度上减弱,不过对于实际分段来说我们仍看到通过最优分配测试时间计算获得了持续改进。
这一结果展示了根据搜索过程中的需要动态分配测试时间计算所能带来的性能提升。
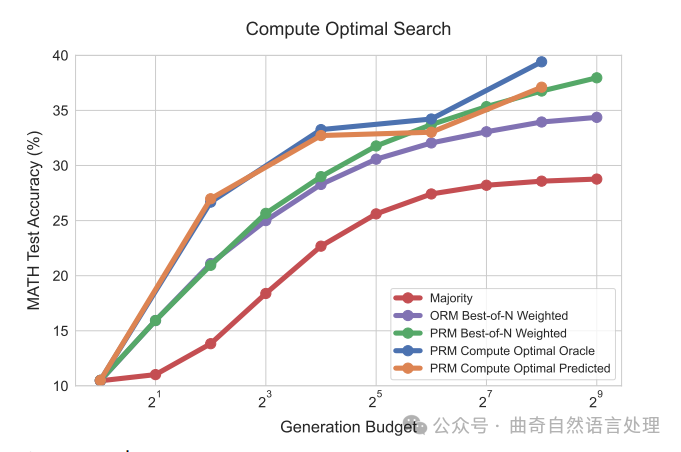
图 4 ∣ 与使用 PRM 搜索的基本方法相比,比较计算最优的测试时间计算分配。根据问题难度的概念调整测试时间计算后,我们发现可以几乎以少至 4 倍的测试时间计算(例如,16 对比 64 轮迭代)超过 PRM 的最佳 N 中的表现。「计算最优 oracle」指的是利用来源于真实正确信息的 oracle 难度区间;而「计算最优预测」则指的是使用 PRM 的预测生成难度区间。观察到无论哪种类型的难度区间的曲线大部分都彼此重叠。
计算最优的验证者扩展总结
Takeaways For Compute-Optimal Scaling Of Verifiers
我们发现,任何给定验证器搜索方法的有效性在很大程度上取决于计算预算和手头的问题。具体来说,在更难的问题和较低的计算预算下,束搜索(beam-search)更为有效;而在较容易的问题和较高预算下,N中最优(best-of-N)更为有效。此外,通过为给定问题难度和测试时间计算预算选择最佳搜索设置,我们几乎可以用少至4倍的测试时间计算量超过N中最优的表现。
We find that the efficacy of any given verifier search method depends critically on both the compute budget and the question at hand. Specifically, beam-search is more effective on harder questions and at lower compute budgets, whereas best-of-N is more effective on easier questions and at higher budgets. Moreover, by selecting the best search setting for a given question difficulty and test-time compute budget, we can nearly outperform best-of-N using up to 4x less test-time compute.
6. 优化提议分布
6. Refining The Proposal Distribution
到目前为止,我们研究了搜索相对于验证者的测试时间计算扩展特性。现在我们转向研究修改提议分布的扩展特性(第2节)。具体而言,我们使模型能够迭代地修正自己的答案,允许模型在测试时动态改进自身的分布。简单提示现有的LMs纠正它们自己的错误,在推理问题上提高性能往往效果不大[15]。因此,我们在Qu等人规定的配方基础上进行构建[28],结合对我们设置的修改,并对语言模型进行微调以迭代修正它们自己的答案。我们首先描述如何训练和使用通过依次基于自身回答同一题目的前次尝试来调节其提议分布的模型。然后,我们分析修订模型的推断时间扩展特性。
So far, we studied the test-time compute scaling properties of search against verifiers. Now we turn to studying the scaling properties of modifying the proposal distribution (Section 2). Concretely, we enable the model to revise their own answers iteratively, allowing the model to dynamically improve it's own distribution at test time. Simply prompting existing LLMs to correct their own mistakes tends to be largely ineffective for obtaining performance improvements on reasoning problems [15]. Therefore, we build on the recipe prescribed by Qu et al. [28], incorporate modifications for our setting, and finetune language models to iteratively revise their own answers. We first describe how we train and use models that refine their own proposal distribution by sequentially conditioning on their own previous attempts at the question. We then analyze the inference-time scaling properties of revision models.
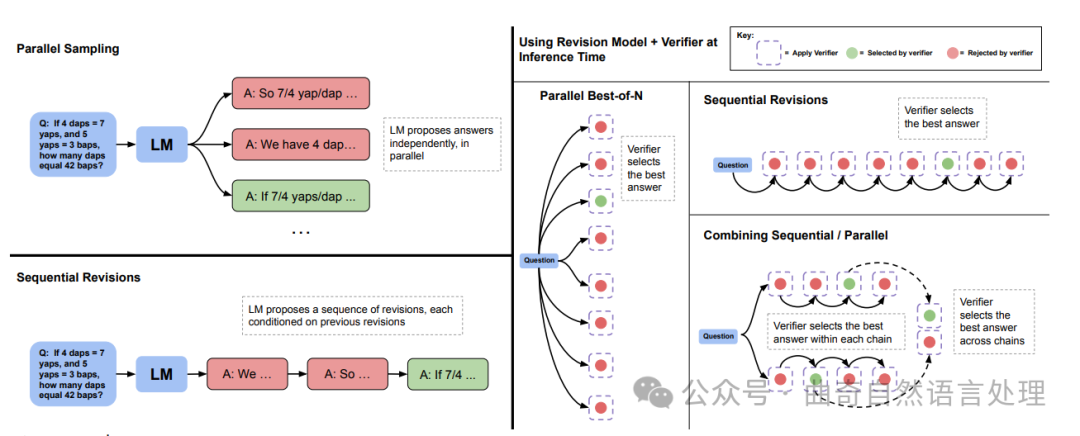
图 5 ∣ 并行采样(例如,最佳的N项)与顺序修订。 左: 并行采样独立地并行生成N个答案,而顺序修订则根据之前的尝试顺序生成每个答案。右:在顺序和并行两种情况下,我们都可以使用验证器来确定最佳的N项答案(例如,通过应用加权的最佳的N项)。我们也可以将部分预算分配给并行采样,部分分配给顺序采样,从而有效地结合了这两种采样策略。在这种情况下,我们首先使用验证器在每个顺序链中选择最好的答案,然后跨链选择最佳的答案。
6.1. 设置:训练和使用修订模型
6.1. Setup: Training And Using Revision Models
我们对修订模型进行微调的程序类似于[28],但我们引入了一些关键性的差异。为了进行微调,我们需要由一系列错误答案后跟一个正确答案组成的轨迹,这样我们就可以运行SFT了。理想情况下,我们希望正确的答案与提供的上下文中的错误答案相关,以便有效地教导模型在提供的情境中隐式地识别示例中的错误,然后通过编辑而非完全忽略情境示例重新开始来纠正这些错误。
生成修订数据。Qu等人提出的[28]的在线策略被证明用于获得多回合的回放是有效的,但是在我们的基础设施上并不完全可行,因为需要承担与运行多回合回放相关的计算成本。因此,我们在更高的温度下并行采样了64个响应,并从这些独立样本中进行事后构造以形成多回合的回放。
具体来说,遵循[1]提供的方法,我们将每个正确答案与来自这个集合的一系列错误答案配对作为上下文,以便构建多回合微调数据。我们包含最多四个在上下文中的错误答案,其中情境下解决方案的具体数量从0到4的均匀分布类别中随机采样。我们使用字符编辑距离度量来优先选择与最终正确答案相关的错误答案(见附录H)。请注意,令牌编辑距离并不是相关性的完美衡量标准,但我们发现这一启发式方法足以将情境下的不正确的答案与正确的目标答案关联起来以促进训练有意义的修订模型,而不是随机地配对和不相关应答的不正确和正确的响应。
在推理时间使用修订。有了经过微调的修订模型后,我们就可以在测试时从模型中抽样一系列修订了。虽然我们的修订模型仅在最多四个先前答案的情境下进行训练,但我们可以通过将上下文截断到最近四个修订响应中最新的四个来采更长的链。在图6(左)中我们可以看到随着我们在修订模型中抽取更长的链步逐渐改善了模型每一步中的通过率@1的能力,这表明我们能够有效地教导模型从情境中前一个答案所犯错误中学习。
Our procedure for finetuning revision models is similar to [28], though we introduce some crucial differences. For finetuning, we need trajectories consisting of a sequence of incorrect answers followed by a correct answer, that we can then run SFT on. Ideally, we want the correct answer to be correlated with the incorrect answers provided in context, so as to effectively teach the model to implicitly identify mistakes in examples provided in-context, followed by correcting those mistakes by making edits as opposed to ignoring the in-context examples altogether, and trying again from scratch.
Generating revision data. The on-policy approach of Qu et al. [28] for obtaining several multi-turn rollouts was shown to be effective, but it was not entirely feasible in our infrastructure due to compute costs associated with running multi-turn rollouts. Therefore, we sampled 64 responses in parallel at a higher temperature and post-hoc constructed multi-turn rollouts from these independent samples.
Specifically, following the recipe of [1], we pair up each correct answer with a sequence of incorrect answers from this set as context to construct multi-turn finetuning data. We include up to four incorrect answers in context, where the specific number of solutions in context is sampled randomly from a uniform distribution over categories 0 to 4. We use a character edit distance metric to prioritize selecting incorrect answers which are correlated with the final correct answer (see Appendix H). Note that token edit distance is not a perfect measure of correlation, but we found this heuristic to be sufficient to correlate incorrect in-context answers with correct target answers to facilitate training a meaningful revision model, as opposed to randomly pairing incorrect and correct responses with uncorrelated responses.
Using revisions at inference-time. Given a finetuned revision model, we can then sample a sequence of revisions from the model at test-time. While our revision model is only trained with up to four previous answers in-context, we can sample longer chains by truncating the context to the most recent four revised responses. In Figure 6 (left), we see that as we sample longer chains from the revision model, the model's pass@1 at each step gradually improves, demonstrating that we are able to effectively teach the model to learn from mistakes made by previous answers in context.
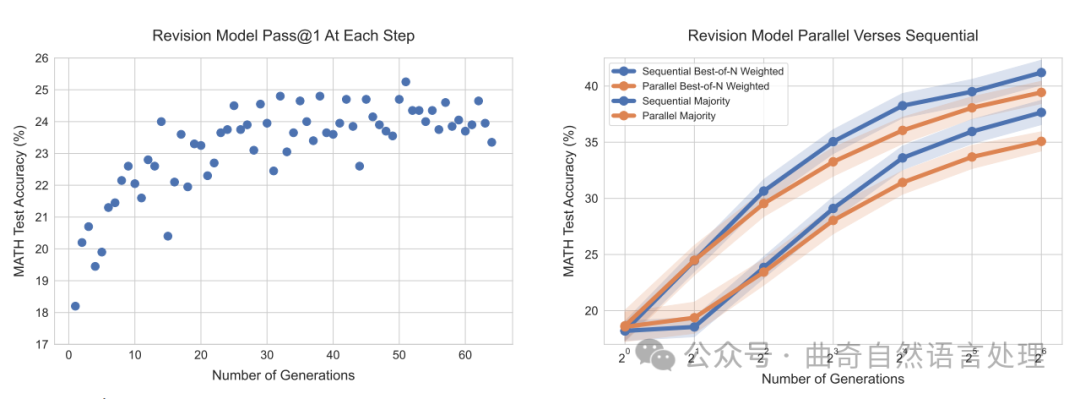
图 6 ∣ 左侧:我们修订模型在每个修订步骤中的 pass@1 表现。 在每次修订后,pass@1 的表现逐渐提高,甚至超过了训练时的 4 步修订限制。我们通过计算测试集中每个问题 4 条长度为 64 的修订轨迹的表现平均值来估算每一步的 pass@1。右侧:顺序采样与并行采样来自修订模型的结果对比。比较在生成初始答案时,使用我们的修订模型并行生成 N 个答案和按顺序生成 N 次修改表现的区别。当同时使用验证器和多数投票选取答案时,我们发现采用修订模型顺序生成答案的表现稍好于并行生成。
也就是说,推理时存在分布偏移:模型仅在上下文中带有错误答案的序列上进行训练,但在测试时,模型可能采样到包含在上下文中的正确答案。在这种情况下,它可能会意外地将正确答案在下一次修订步骤中变成错误的答案。我们发现确实如此,类似于Qu等人 [28] 的结果,大约38%的正确答案使用我们的修订模型和简单的方法被转换回了错误答案。因此,我们采用基于顺序多数投票或验证器基础上的选择机制来从模型所做的修订序列中选择最正确的答案(参见图5),以产生最佳答案。
比较。为了测试通过修订修改提议分布的有效性,我们在对问题进行N次连续修正的性能与并行采样N次尝试之间设置了一个公平的对比。我们发现在图6(右)中,无论是基于验证器还是多数选择机制,在顺序上采样解都优于并行采样它们。
That said, there is a distribution shift at inference time: the model was trained on only sequences with incorrect answers in context, but at test-time the model may sample correct answers that are included in the context. In this case, it may incidentally turn the correct answer into an incorrect answer in the next revision step. We find that indeed, similar to Qu et al. [28], around 38% of correct answers get converted back to incorrect ones with our revision model using a naïve approach. Therefore, we employ a mechanism based on sequential majority voting or verifier-based selection to select the most correct answer from the sequence of revisions made by the model (see Figure 5) to produce the best answer.
Comparisons. To test the efficacy of modifying the proposal distribution via revisions, we setup an even comparison between the performance of sampling N revisions in sequence and sampling N attempts at a question in parallel. We see in Figure 6 (right), that with both the verifier-based and majority-based selection mechanisms sampling solutions in sequence outperforms sampling them in parallel.
6.2. 分析结果:修订版的测试时间缩放
6.2. Analysis Results: Test-Time Scaling With Revisions
我们之前看到,顺序提出答案的表现优于并行提出答案。然而,我们可能预期顺序和并行采样具有不同的特性。并行采样答案可能会更像一个全局搜索过程,在原则上,可以涵盖许多完全不同的解决问题的方法,例如,不同的候选答案可能总体上利用了不同的高级方法。另一方面,顺序采样可能更像是一个局部优化过程,修改已经大致正确的回应。由于这些互补优势,我们应该在这两个极端之间找到平衡,将一部分推理时间预算分配给并行采样(例如,√N),其余部分用于顺序修订(例如,√N)。
我们现在将展示顺序和并行采样的计算最优比率的存在,并根据给定提示的难度理解它们各自的优缺点。
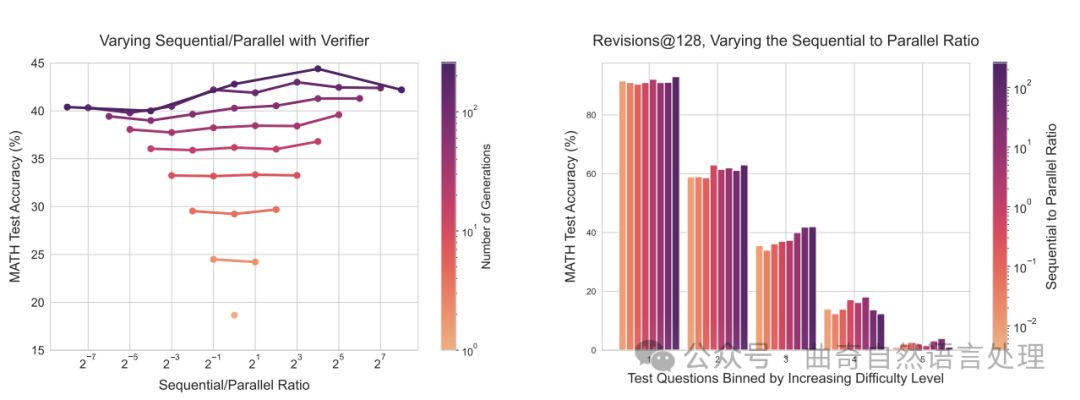
图 7 ∣ 左:改变分配给顺序修订与并行采样比例的生成预算。 每条线代表在比例变化下的固定生成预算。我们使用验证器进行答案选择。我们可以看到,虽然增加顺序修订倾向于胜过更多并行计算,在更高的生成预算下存在一个理想的比例,在两个极端之间找到了平衡。右:对于难度区间内的128个生成预算,改变顺序与并行的比值。采用基于验证的选择方法,我们发现较容易的问题在完全顺序计算时达到最佳性能。而对于更难的问题,在测试时间计算上有一个理想的顺序到并行比例。
在顺序和并行测试时间计算之间进行权衡。为了了解如何最优分配顺序和并行计算,我们对许多不同的比例进行了扫瞄。我们看到,在图7(左)中,确实,在一定的生成预算下,实现了最高的准确度。我们还从图7(右)中看到,序列处理与并行处理的理想比例会根据给定问题的难度而变化。具体而言,简单的问题更多地受益于序列修订,而对于难题,则需要在序列和并行计算之间找到最佳平衡点。这一发现支持了以下假设:序列修订(即,改变提议分布)和平行采样(即,使用验证器进行搜索)是扩大测试时间计算量的两大互补方向,在每个提示下可能更加有效。我们在附录L中包含了模型生成的示例。更多结果见于附录B。
计算最优修订。鉴于序列和并行采样的有效性取决于问题难度,我们可以根据难度区间选择最佳的序列与并行计算比例。
在图8中,我们描绘了采用我们的困难度理论计算和预测值时,在使用计算最优规模化策略的成效。两种情况下,通过修订来改进提议分布的方式,我们均大幅度提升了测试时间计算量的规模化效率。特别地,可以看到在更高的生成预算下,并行采样似乎达到平台期,而计算最优规模化却持续展现了提升。
对于计算出的最佳和预测难度区间,我们都发现,相对于N佳选择策略,在多至4倍减少测试时间计算量的情况下(比如64个样本对256),计算最优规模化可以表现更优。整体而言,这些结果展示了在每个提示下调整提议分布有可能提升测试时间的计算量规模化效率的巨大潜力。
achieves the maximum accuracy. We also see in Figure 7 (right) that the ideal ratio of sequential to parallel varies depending on a given question's difficulty. In particular, easy questions benefit more from sequential revisions, whereas on difficult questions it is optimal to strike a balance between sequential and parallel computation. This finding supports the hypothesis that sequential revisions (i.e., varying the proposal distribution) and parallel sampling (i.e., search with verifiers) are two complementary axes for scaling up test-time compute, which may be more effective on a per-prompt basis. We include examples of our model's generations in Appendix L. Additional results are shown in Appendix B.
Compute-optimal revisions. Given that the efficacy of sequential and parallel sampling depends on question difficulty, we can select the ideal ratio of sequential to parallel compute per difficulty bin.
In Figure 8, we plot results using this computeoptimal scaling strategy when employing both our oracle and predicted notions of difficulty. In both cases, we're able to substantially improve testtime compute scaling by improving the proposal distribution via revisions. In particular, we see that at higher generation budgets, parallel sampling seems to plateau, whereas compute-optimal scaling demonstrates continued improvements.
For both oracle and predicted difficulty bins, we see that compute-optimal scaling can outperform best-of-N using up to 4x less test-timecompute (e.g. 64 samples verses 256). Overall, these results demonstrate the potential for improved test-time compute scaling by adjusting the proposal distribution on a per-prompt basis.
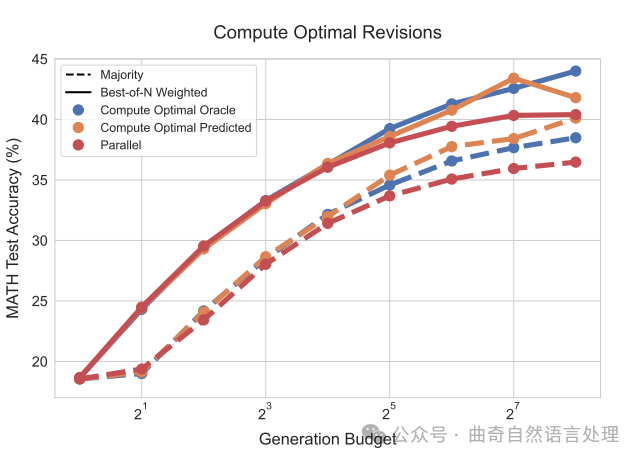
图8 ∣ 将计算最优的测试时间计算分配与使用我们的修订模型的并行计算基线进行比较。通过根据问题难度最优地缩放测试时间计算,我们发现可以使用最多4倍少的测试时间计算(例如64个样本对比256个)胜过N优算法。"计算最优理想状态"指的是使用从真实的正确信息中得出的理想难度区间,而"计算最优预测"是指利用PRM的预测产生模型预测的难度区间。
通过细化提议分布进行修订,以实现计算最优的扩展:要点总结
Takeaways For Compute-Optimal Scaling By Refining The Proposal Distribution With Revisions
我们发现,在顺序计算(如修订)与并行计算(如标准的最佳N次中的一个)的测试时间计算之间存在权衡,而顺序计算到并行测试时间计算的理想比例严重依赖于计算预算和手头的具体问题。具体而言,较简单的问题从纯顺序的测试时间计算中获益,而较难的问题通常在某一个理想的顺序与并行计算的比例下表现最佳。此外,通过为给定的问题难度和测试时间计算预算选择最优设置,我们可以在使用至多4倍少的测试时间计算的情况下胜过并行的最佳N次中的一个基线。
We find that there exists a tradeoff between sequential (e.g. revisions) and parallel (e.g. standard best-of-N) test-time computation, and the ideal ratio of sequential to parallel test-time compute depends critially on both the compute budget and the specific question at hand. Specifically, easier questions benefit from purely sequential test-time compute, whereas harder questions often perform best with some ideal ratio of sequential to parallel compute. Moreover, by optimally selecting the best setting for a given question difficulty and test-time compute budget, we can outperform the parallel best-of-N baseline using up to 4x less test-time compute.
8. 讨论与未来工作
8. Discussion And Future Work
在本项工作中,我们对旨在提高针对验证者搜索效率或优化LLM建议分布的不同技术进行了深入分析,以提升数学推理的测试时间计算能力。总体而言,我们发现某一给定方法的有效性与从基础LLM能力角度的问题难度高度相关。这促使我们将“计算最优”扩展的理念引入到测试时间计算中,该理念倡导一个适应性的、基于提示的策略,在既定的测试时间计算预算下提升性能。通过应用这种计算最优缩放策略,我们发现可以在2-4倍的范围内提高测试时间计算能力的效率。当比较额外的测试时间计算收益与匹配FLOPs设置下的预训练计算收益时,我们首次展示使用看似简单的(即修订和搜索)方法在某些类型的提示上已经可以很好地扩展,并提供了比将这些FLOps用于预训练更好的增益。
但是,本研究中也存在局限性,未来的研究可以设法加以解决。
进一步改进测试时间计算的扩展。在此项工作中,我们专注于提升两大主要机制的测试时间计算扩展:验证者与提案分布(通过修订)。
尽管我们在第6节将验证者和修订结合使用了,但我们并未尝试PRM树搜索技术与修订相结合的实验,也未研究其他方法如批判与修正[23]。未来的工作应当探索如何通过结合各种这些方法进一步改进测试时间计算扩展。另外,我们也发现整体而言,在困难问题上这些方案只能带来微小的提升;未来工作应努力开发利用测试时间计算的新方式以克服这一局限。
快速评估问题难度。我们使用了一种问题难度概念作为约当的充分统计量,来近似计算最优测试时间缩放策略。虽然该方法有效,但估计我们的困难度概念本身就需要应用不菲的测试时间计算资源。
未来的工作应当考虑更高效地估计问题难度的替代方式(例如,通过预训练或微调模型直接预测问题难度),或者在评估难度与试图解决一个问题之间进行动态切换。
交织测试时间和训练时间计算。本工作中我们纯粹关注于测试时间计算扩展以及测试时间和计算如何可以用于额外的预训练交换。
然而,在未来,我们可以预见应用额外测试时间计算的结果可以被回传到基础LLM中,使一个基于开放语言自我改进循环成为可能。为此,未来工作应当拓展我们的发现,并研究如何使用应用测试时冪算的产出改善基础LLM自身。
In this work, we conducted a thorough analysis of the efficacy of different techniques that aim to either improve search against a verifier or to refine an LLM's proposal distribution, for scaling test-time compute for math reasoning. In general, we found that the efficacy of a given approach heavily correlates with the difficulty of the problem from the perspective of the base LLM's capabilities. This motivated us to introduce the notion of "compute-optimal" scaling of test-time computation, which prescribes a adaptive, prompt-dependent strategy to improve performance under a given test-time compute budget. By applying such a compute-optimal scaling strategy, we find that can improve the efficiency of test-time compute scaling by a factor of 2 − 4×. When comparing benefits obtained from additional test-time compute against benefits from additional pre-training compute in a FLOPs-matched setting, we show for the first time that using test-time computation with seemingly simple methods (i.e., revisions and search) can already scale well on certain types of prompts, providing gains over spending those FLOPs in pretraining.
That said, there are also limitations associated with our study that future work can aim to address.
Further improving test-time compute scaling. In this work we focused on improving the test-time compute scaling of two primary mechanisms: the verifier and the proposal distribution (via revisions).
While we combined verifiers with revisions in Section 6, we did not experiment with PRM tree-search techniques in combination with revisions. Neither did we study other techniques such as critique and revise [23]. Future work should investigate how test-time compute scaling can be further improved by combining a variety of these approaches. Additionally, we found that across the board these schemes provided small gains on hard problems; future work should work to develop new ways of using test-time compute which can circumvent this limitation.
Assessing question difficulty quickly. We used a notion question difficulty as a simple sufficient statistic for approximating the compute-optimal test-time scaling strategy. While this scheme was effective, estimating our notion of difficulty requires applying a non-trivial amount of test-time compute itself.
Future work should consider alternative ways of more efficiently estimating question difficulty (e.g., by pretraining or finetuning models to directly predict difficulty of a question) or dynamically switching between assessing difficulty and attempting to solve a question.
Interleaving test-time and training-time compute. We focused purely on test-time compute scaling in this work and the degree to which test-time compute can be traded off for additional pretraining.
However, in the future, we envision that the outputs of applying additional test-time compute can be distilled back into the base LLM, enabling an iterative self-improvement loop that operates on open-ended natural language. To this end, future work should extend our findings and study how the outputs of applying test-time compute can be used to improve the base LLM itself.

公众号:曲奇自然语言处理

![[Linux入门]---使用exec函数实现简易shell](https://i-blog.csdnimg.cn/direct/279c39cd58ed4833beb72334d683ac9e.png)