前言
在实际的项目开发中,我们时刻都在使用数据拷贝功能,赋值、深拷贝和浅拷贝是前端开发中常见的概念,用于复制简单数据类型(字符串、数值、布尔值)和引用类型(对象、数组)。它们的主要区别在于拷贝的层级深度以及对原始数据的引用关系。
一. 初识拷贝
赋值
赋值是将一个变量的值赋给另一个变量,包括简单数据类型(如字符串、数值、布尔值)和引用类型(如对象、数组)。
严格意义上说,赋值并不属于拷贝,因为对于简单数据类型来说,只是将a变量的值赋给b变量。而对于对象或数组类型的数据,赋值操作也只是将它们的引用传递给了新的变量。
换句话说,当你将一个对象或数组赋值给另一个变量时,两个变量将指向同一个对象或数组,它们共享同一块内存空间。如果你修改其中一个变量所指向的对象或数组,另一个变量也会跟着改变。因此,赋值操作并不会创建一个新的独立副本,而是共享相同的引用。
如果你想创建一个完全独立的对象或数组副本,你需要使用深拷贝或浅拷贝的方式。 拷贝操作则是创建一个完全独立的副本,使得副本和原始对象或数组在内存中存在不同的存储空间。
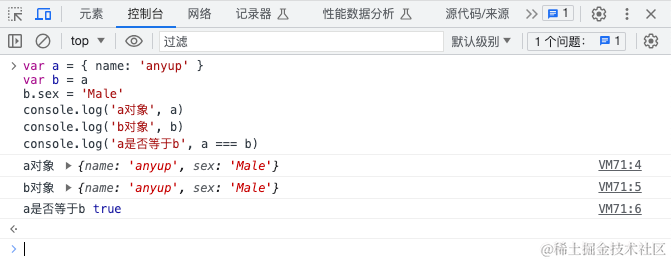
var a = { name: 'anyup' }
var b = a
b.sex = 'Male'
console.log('a对象', a)
console.log('b对象', b)
console.log('a是否等于b', a === b)
浅拷贝
浅拷贝是指创建一个新对象,新对象的属性值和原对象的属性值相同,但是它们共享同一个引用地址。换句话说,修改新对象的属性值会影响到原对象的属性值。浅拷贝适用于简单数据类型,如数字、字符串等不可变数据。
常见的浅拷贝方法有:
-
Object.assign(target, source) -
Spread Operator扩展运算符(...) -
Array.slice()和Array.concat() -
使用第三方库(如
lodash.clone)
深拷贝
深拷贝是指创建一个与原对象完全独立的新对象,它们互不影响。深拷贝适用于复杂数据类型,如对象、数组等可变数据,并且能够保留原始数据的结构和所有嵌套对象的引用关系。
常见的深拷贝方法有
-
JSON.parse(JSON.stringify(object)) -
递归实现拷贝
-
使用第三方库(如
lodash.cloneDeep)
应用场景:
-
避免改变原始数据:在某些场景下,我们需要对数据进行修改,但是不希望影响到原始数据,这时可以使用浅拷贝。
-
保存数据状态:当需要保存某个对象或数组的状态,并在后续操作中使用不同版本的数据时,深拷贝非常有用。
-
处理嵌套结构:当数据结构中包含多层嵌套对象或数组时,深拷贝能够完整复制整个数据结构,保持引用关系。
需要注意的点: 深拷贝可能存在性能问题,因为拷贝的层级越深,复制的数据量就越大,可能会影响代码性能。因此,在选择使用深拷贝还是浅拷贝时,需要根据实际情况进行权衡和选择。
深拷贝和浅拷贝的重要性
深拷贝和浅拷贝在 JavaScript 开发中具有重要性,可以带来以下好处:
-
数据安全性:拷贝数据可以防止原始数据的意外改变。特别是多人协同开发或者在复杂数据处理的场景下,使用深拷贝和浅拷贝可以确保每个开发者都能够独立地操作数据,而不会相互干扰或冲突。
-
状态保存:深拷贝和浅拷贝使得可以轻松地保存数据的不同版本或状态。在某些需要跟踪数据历史记录或回滚操作的场景中,深拷贝和浅拷贝允许我们在数据不同版本之间进行无缝切换,以便进一步处理或还原到之前的状态。
-
减少内存占用:拷贝数据时,可以避免数据引用关系的共享,从而减少内存使用。在某些场景下,如果多个对象或数组使用同一份数据,可能会造成内存浪费。通过深拷贝或浅拷贝,我们可以创建新的数据副本,从而避免额外的内存占用。
-
处理嵌套数据结构:
JavaScript中的对象和数组经常包含嵌套结构,即对象中嵌套了对象或数组,反之亦然。使用深拷贝和浅拷贝可以完整复制嵌套结构,保持原始数据的引用关系,并在处理和修改数据时不会对原始数据产生影响。
总之,深拷贝和浅拷贝在 JavaScript 开发中具有重要性,能够保证数据的安全性、灵活处理数据状态、优化内存使用等。根据具体需求和场景,选择合适的拷贝方式可以帮助我们更好地处理数据和开发项目。
二. 深入浅拷贝
浅拷贝的定义和原理
定义
JavaScript 浅拷贝是指创建一个新对象或数组,新对象或数组的属性值和原对象或数组的属性值相同,但是它们共享同一个引用地址。也就是说,新对象或数组中的基本数据类型的属性是独立的,但是引类型的属性仍然指向原始对象或数组中的相引用。
浅拷贝的原理
通过复制源对象或数组的引用,将其赋值给新的变量。对于基本数据类型的属性,它们是不可变的,因此改变新对象或数组的属性值不会影响始对象或数组。但是对于引用类型的属性,它们的值是一个指向内存地址的引用,新对象或数组的引用类型属性和原始对象或数组的引用类型属性指向同一个地址。所以,修改新对象或数组中的引用类型属性会影响原始对象或数组中的属性。
需要注意的点: 浅拷贝只能复制一层的属性。如果原始对象或数组的属性中包含了嵌套的对象或数组,则浅拷贝只会复制它们的引用。如果需要复制多层嵌套的对象或数组,并且保持独立性,需要使用深拷贝方式。
常见的实现浅拷贝的几种方法
在 JavaScript 中,可以使用以下几种方式手动实现浅拷贝:
1. 使用 Object.assign()方法:
function shallowCopy(obj) {return Object.assign({}, obj);
}
2. 使用扩展运算符(Spread Operator):
function shallowCopy(obj) {return { ...obj };
}
3. 使用循环遍历并赋值:
function shallowCopy(obj) {var newObj = {};for (var key in obj) {if (obj.hasOwnProperty(key)) {newObj[key] = obj[key];}}return newObj;
}
4. 使用 Object.keys()方法和 Array.forEach()方法遍历并赋值:
function shallowCopy(obj) {var newObj = {};Object.keys(obj).forEach(function (key) {newObj[key] = obj[key];});return newObj;
}
以上的这些方法可以创建一个新的对象,并将原始对象的属性复制到新对象中。这样做可以确保新对象和原始对象不共享同一内存地址,当修改新对象时不会影响到原始对象。
注意: 上述方法只能实现浅拷贝,如果原始对象中包含嵌套的对象或数组,则只会复制它们的引用,而不是进行递归的复制。如果需要实现深拷贝,应该使用其他方法,如递归遍历对象或数组并进行复制。
浅拷贝的特点和限制
特点:
-
创建一个新的对象或数组,并将原始对象或数组的值复制到新对象或数组中。
-
复制的是对象或数组的第一层属性或元素,不会递归复制嵌套的对象或数组。
-
浅拷贝后的对象或数组与原始对象或数组共享同一级别的属性和元素,即修改其中一个对象或数组的值会影响到另一个对象或数组。
限制:
-
对于对象的浅拷贝,不能复制原型链上的属性和方法。
-
对于数组的浅拷贝,不能复制数组的特殊属性,如
length属性。 -
如果原始对象或数组包含内置对象(如
Date、RegExp等),浅拷贝只能复制其引用,而不是复制其具体值。 -
嵌套层级较深或有循环引用的对象或数组可能会导致无法正确进行浅拷贝。
-
某些特殊情况下的属性会被忽略,如不可枚举的属性、
Symbol类型的属性。
三. 深入深拷贝
深拷贝的定义和原理
定义
JavaScript 深拷贝是指创建一个新的对象或数组,将原始对象或数组的所有层级的属性和元素都复制到新对象或数组中,包括嵌套的对象和数组。深拷贝后的新对象或数组与原始对象或数组完全独立,互不影响。
原理
实现深拷贝的原理是遍历原始对象或数组的每个属性或元素,如果是基本类型,则直接复制值;如果是对象或数组,则递归进行深拷贝。
基本的深拷贝算法可以使用递归来实现,通过递归遍历对象的属性或数组的元素,并对其进行深拷贝。通过递归地处理嵌套的对象和数组,确保所有层级的属性和元素都被正确复制到新的对象或数组中。
需要注意的点: 深拷贝也有一些限制,如循环引用和处理不可枚举属性等。在实际使用中,可以根据需求使用成熟的深拷贝库或自行处理特定情况来实现更健壮的深拷贝。
常见的实现深拷贝的几种方法
1. 递归实现深拷贝:
使用递归方法遍历对象或数组的每个属性或元素,对于基本类型直接复制,对于对象或数组递归深拷贝。
function deepCopy(obj) {
if (typeof obj !== "object" || obj === null) {return obj; // 如果是基本类型或null,直接返回
}let copy;if (Array.isArray(obj)) {copy = []; // 如果是数组,创建一个空数组用于复制obj.forEach((item, index) => {copy[index] = deepCopy(item); // 递归深拷贝每个元素});
} else {copy = {}; // 如果是对象,创建一个空对象用于复制Object.keys(obj).forEach((key) => {copy[key] = deepCopy(obj[key]); // 递归深拷贝每个属性});
}return copy;
}
2. JSON 序列化和反序列化:
利用 JSON.stringify 将对象转换为字符串,再使用 JSON.parse 将字符串转换为新的对象,实现深拷贝。但该方法有一些限制,无法复制函数和循环引用对象。
function deepCopy(obj) {return JSON.parse(JSON.stringify(obj));
}
深拷贝的特点和限制
特点:
-
完全独立性:深拷贝创建了一个全新的对象或数组,与原始对象或数组完全独立,互不影响。
-
层级复制:深拷贝会递归复制对象或数组的所有层级,包括嵌套的对象和数组。
-
数据一致性:深拷贝会保留原始对象或数组的所有属性和元素的值,确保复制后数据的一致性。
限制:
-
性能开销:深拷贝可能会带来较大的性能开销,特别是对于复杂的对象或数组结构。递归遍历并复制每个属性或元素可能需要较长时间和消耗大量的计算资源。
-
内存占用:深拷贝会占用额外的内存空间,尤其是当对象或数组结构很大时。如果需要深拷贝大型对象或数组,可能会对内存造成压力。
-
循环引用:深拷贝可能会遇到循环引用的问题,即对象中存在互相引用的情况。在处理循环引用时,深拷贝可能会进入无限循环,导致栈溢出或代码崩溃。
-
函数和原型方法:深拷贝不能复制函数和原型方法。JSON.stringify()和 JSON.parse()方法在进行深拷贝时会将函数序列化为 null,并丢失函数的功能。
-
不可枚举属性:深拷贝可能会丢失对象的不可枚举属性。使用 Object.assign()或扩展运算符(...)进行深拷贝时,不可枚举属性不会被复制。
四. 深拷贝 vs 浅拷贝
区别和选择
区别:
-
深拷贝:深拷贝创建了一个原始对象的完全独立副本,包括所有层级的属性和元素。对拷贝后的对象进行修改不会影响原始对象。
-
浅拷贝:浅拷贝创建了一个对原始对象的引用,拷贝后的对象与原始对象共享同一地址和内存。对拷贝后的对象进行修改可能会影响原始对象。
选择:
-
使用深拷贝的情况:
-
需要创建原始对象的完全独立副本,在修改副本时不影响原始对象。
-
原始对象包含嵌套的对象或数组,需要完整复制整个层级的属性或元素。
-
对象中存在循环引用,需要处理循环引用的情况。
-
需要复制函数和原型方法。
-
-
使用浅拷贝的情况:
-
只需要复制原始对象的一层属性或元素,不需要递归复制整个层级。
-
原始对象很大,使用深拷贝可能会导致性能和内存占用问题。
-
对拷贝后的对象进行修改需要影响原始对象。
-
性能比较
在性能方面,一般情况下,浅拷贝的性能比深拷贝要更高效。这是因为浅拷贝只是复制了对象的引用或数组的引用,不会递归复制所有层级的属性或元素,所以执行速度相对较快。
相比之下,深拷贝需要递归遍历并复制对象的每个属性或元素,如果对象或数组的结较复杂、层级较深,或者数据量较大,深拷贝的性能会受到大的影响。特别是当原始对象中存在循环引用时,深拷贝容易陷入无限递归,进而导致性能问题,甚至导致代码崩溃。
因此,在对性能要求较高的场景下,如果不需要对对象的所有层级进行复制,可以选择使用浅拷贝方法。浅拷贝方法如 Object.assign()、扩展运算符(...)、Array.prototype.slice()等在大多数情况下都能满足需要。
不过,需要注意的是,深拷贝的性能缺点并不是普遍的,它主要取决于数据的大小、结构的复杂程度以及所选择的深拷贝方法的实现方式。对于小型、简单的对象或数组,深拷贝过程可能并不明显地影响性能。此外,一些专门优化过的深拷贝库,如 lodash 的 cloneDeep 方法,可以提供更好的性能。
因此,在实际使用中,需要根据具体的需求和数据特点,在性能和需求之间进行权衡和选择,找到最合适的拷贝方式。
五. 使用场景和注意事项
不同场景的拷贝需求
在 JavaScript 中,不同场景可能有不同的拷贝需求。以下是几个常见的场景以及对应的拷贝需求:
-
修改原始数据:如果你需要在修改数据的同时保留原始数据的不变性,你通常会需要使用深拷贝。深拷贝会创建原始数据的完全独立副本,使得你可以自由地修改副本而不会影响到原始数据。
-
传递数据给函数:当你将对象或数组作为参数传递给一个函数时,你通常希望函数内部的操作不会影响到原始数据。这时候你可以选择使用浅拷贝,将原始数据的引用传递给函数,确保函数内部只对副本进行操作。
-
对象或数组的展开赋值:在 ES6 中,可以使用扩展运算符(...)来将一个对象或数组展开成一个新的对象或数组。这时候,你可能需要使用浅拷贝来创建新的对象或数组,以确保新对象或数组与原始数据没有引用关系。
-
缓存数据:在一些情况下,你可能需要将某个对象或数组缓存起来以备后续使用,但又不希望后续对缓存数据的修改影响到原始数据。这时候你可以选择使用深拷贝,创建一个独立副本来作为缓存数据。
需要根据具体的场景和需求来选择合适的拷贝方式,可以是深拷贝或浅拷贝,以满足数据操作的要求,并确保数据的一致性和完整性。
避免循环引用问题
要避免 JavaScript 中的循环引用问题,可以使用以下方法进行拷贝:
-
使用递归和缓存:在进行深拷贝时,可以通过递归遍历对象的属性或数组的元素,并使用缓存来跟踪已经拷贝过的对象。当遇到循环引用时,检查缓存中是否已经存在该对象的拷贝,如果存在则直接使用缓存的拷贝对象,避免无限递归。
-
使用第三方库:许多第三方库(如 lodash、immer 等)已经为拷贝操作提供了专门优化的方法,可以处理循环引用问题。这些库通常会使用类似于上述的递归和缓存的方法来实现深拷贝,建议使用这些库来处理复杂的拷贝场景。
-
手动处理循环引用:如果不想依赖第三方库,并且知道自己的数据结构和循环引用的位置,也可以手动处理循环引用问题。在拷贝过程中,设置一个标记来表示已经拷贝过的对象,并在遇到循环引用时,将属性或元素设置为之前拷贝的对象的引用。
无论采用哪种方法,都需要谨慎处理循环引用问题,以确保拷贝过程的正确性和性能。如果数据结构非常复杂或循环引用较多,建议使用专门的拷贝库或借助第三方库来处理循环引用问题。
避免拷贝过程中的副作用
在 JavaScript 中,避免拷贝过程中的副作用可以采取以下方法:
-
使用纯函数:确保拷贝过程中的函数没有副作用。纯函数是指函数的输出仅由输入决定,没有对外部状态的修改和影响。使用纯函数可以避免在拷贝过程中产生意外的副作用。
-
使用不可变数据结构:在拷贝过程中,尽量使用不可变数据结构。不可变数据结构不允许在原始对象上进行修改操作,而是通过创建新的对象来实现更改。这样可以避免原始对象被不小心修改,导致副作用的产生。
-
避免直接引用和修改外部状态:在拷贝过程中,避免直接引用和修改外部状态,即避免对全局变量、共享对象等进行修改。应该通过函数参数传递需要拷贝的数据,将拷贝的操作封装在函数内部,从而避免对外部状态造成意外的改变。
-
使用浅拷贝而非深拷贝:在某些场景下,深拷贝可能会引入不必要的副作用,尤其是当对象或数组中包含大量的嵌套对象时。在这种情况下,可以考虑使用浅拷贝来避免不必要的开销和潜在的副作用。
-
使用专门的拷贝库:许多第三方库(如
lodash、immer等)提供了专门优化的拷贝方法,旨在避免副作用。这些库通常会采用不可变数据结构和纯函数的概念,并提供高效且安全的拷贝操作,可以减少副作用的风险。
尽管以上方法可以减少副作用的发生,但仍需在编写代码时谨慎操作和评估拷贝过程中的可能副作用。理解数据的结构和操作,并熟悉相关的拷贝方法,有助于避免副作用的产生。
六. 总结
深拷贝和浅拷贝的优缺点
深拷贝和浅拷贝都是在 JavaScript 中用于复制对象或数组的方法,它们各自有一些优点和缺点:
| 拷贝方式 | 优点 | 缺点 |
|---|---|---|
| 浅拷贝 | 1. 简单快速:浅拷贝只是复制引用,而不复制对象本身,因此执行速度更快。 2. 节省内存:由于只是复制引用,不会占用额外的内存空间。 | 1. 引用关系:如果原始对象或数组发生变化,拷贝后的对象或数组也会受到影响,这可能会导致副作用。 2. 嵌套对象或数组:浅拷贝只复制一层深度的对象或数组,如果遇到嵌套的对象或数组,仍然会存在引用关系。 |
| 深拷贝 | 1. 完全独立:深拷贝创建了完全独立的对象或数组,与原始对象没有任何引用关系。 2. 完整复制:深拷贝复制了对象或数组的所有层级,包括嵌套对象或数组。 | 1. 性能消耗:深拷贝会对原始对象或数组的每个元素进行递归遍历和复制,所以对于大型的嵌套结构,可能会消耗较多的时间和内存。 2. 循环引用问题:如果对象或数组存在循环引用的情况,深拷贝可能导致无限递归,需要额外的处理来解决循环引用问题。 |
实际项目中如何选择
在实际 JavaScript 项目中,开发者选择深拷贝和浅拷贝的方法应该基于具体的需求和场景。以下是一些常见的选择场景和建议:
-
对象属性的简单复制:如果只需要复制的属性,并且这些属性是原始值类型(如字符串、数字等),则可以使用浅拷贝。这样可以节省资源并保持简洁性。
-
嵌套对象或数组的复制:如果需要复制一个对象或数组,并且它们包含嵌套的对象或数组,那么需要使用深拷贝。这样可以确保复制的对象是完全独立的,避免副作用。
-
避免副作用和引用关系:如果在项目中有涉及对数据的修改且需要保证拷贝后的对象与原始对象无关联,那么应该使用深拷贝。这样可以避免对原始对象产生意外的副作用。
-
循环引用问题:如果在对象或数组中存在循环引用的情况,使用深拷贝时需要注意解决循环引用问题。可以使用第三方库或手动编写代码来检测和处理循环引用,确保深拷贝的正确性和可靠性。
总体而言,深拷贝提供了更强大的复制能力和完全独性,但也带来了性能消耗。浅拷贝简单快速,适用于简单的复制场景。根据具体情选择合适的拷贝方式,可以在项目开发中取得更好的效果。
参考文档
如果是处理复杂的拷贝场景,建议使用专门的拷贝库:许多第三方库(如 lodash 等)提供了专门优化的拷贝方法,旨在避免副作用。这些库通常会采用不可变数据结构和纯函数的概念,并提供高效且安全的拷贝操作,可以减少副作用的风险。
-
MDN - 深拷贝
-
MDN - 浅拷贝
-
Lodash - 深拷贝
-
Lodash - 浅拷贝
-
jQuery:提供的
$.extend()方法可以进行浅拷贝,没有直接提供深拷贝的方法。
结语
以上是在实际项目实践后的总结,其中的拷贝方法也是经常自己使用的方法,尽管许多第三方库实现的非常优秀,但是我们也应该理解深拷贝和前拷贝的实现原理和应用场景,理解出现某些问题后我们应该如何解决。希望本文能让你对拷贝有一个新的认识和收获。