文章目录
- 前言
- 一、介绍
- 二、方法
- 2. Open vocabulary detector
- 2.1 encoder
- 2.2 decoder
- 3. Object captioner
- 三、数据工程
- 1. Auto-annotation data pipeline
- 四、训练策略
- 五、实验
- 总结
前言
目前多模态目标检测逐渐成为检测领域的主要发力方向,从最初的检测大模型grounding dino, 到YOLO-world, 本文记录最新的多模态目标检测论文DetCLIPv3
paper:http://arxiv.org/pdf/2404.09216
一、介绍
现有的开放词汇表目标检测器(OVD)通常需要用户提供预定义的类别集,这在实际应用场景中限制了它们的使用。
与现有方法不同,人类认知能够以分层的方式理解不同粒度的对象,这在当前的OVD系统中尚未实现。
为了解决这些限制,作者提出了 DetCLIPv3,这是一种新型的目标检测器,能够扩展开放词汇表目标检测的范围。
以下面这张图做个简单说明,就能更好的理解作者的purpose;
对于当前OVD来说,输入一张图,模型只能给出预定义的category list中的certain class
但对于人类,我们可以从多粒度去感知它,Phrase, Category, Parent Category
so 作者想实现一个能够多粒度感知的OVD系统

二、方法

2. Open vocabulary detector
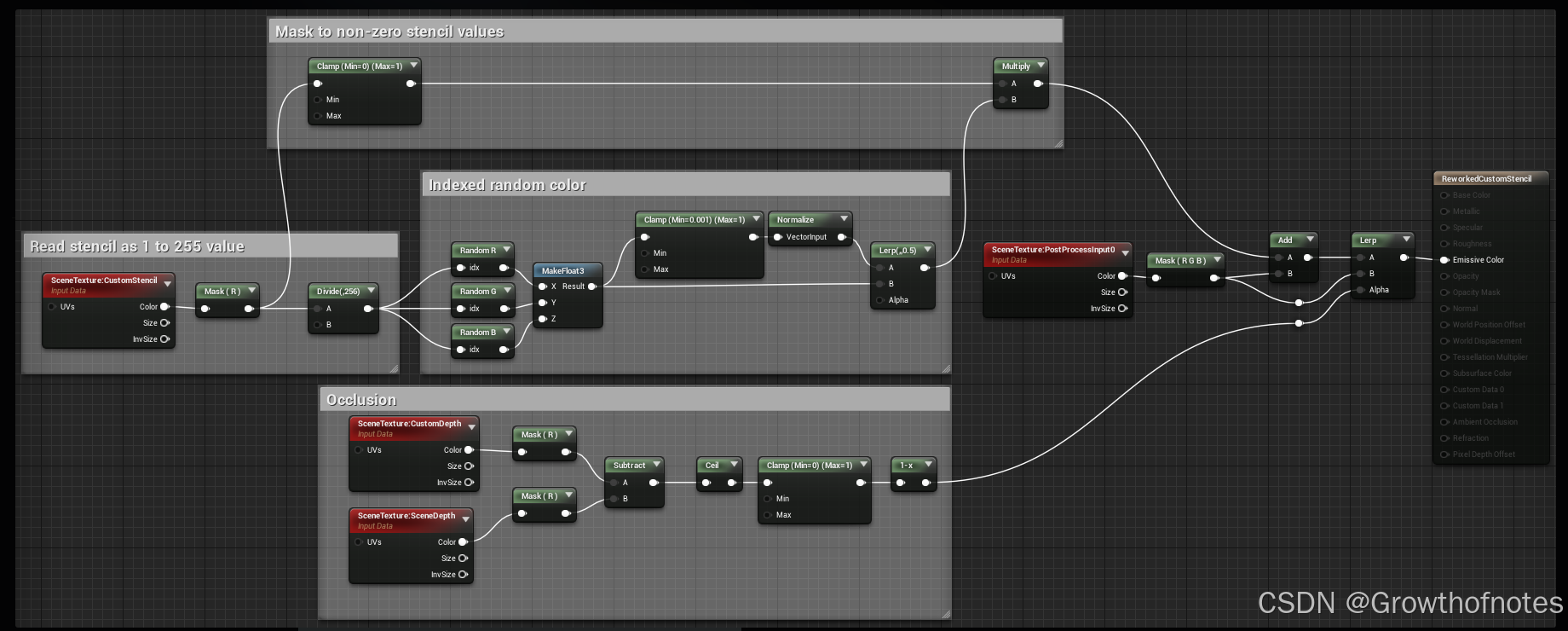
该架构是一个双路径的模型,包括 image encoder and text encoder,detector部分包括一个pixel encoder 和 object decoder。encoder部分指导细粒度特征融合,为decoder提出候选query。
2.1 encoder
这部分思想类似Grounding Dino中的Language-Guided Query Selection
"""
Input:
image_features: (bs, num_img_tokens, ndim)
text_features: (bs, num_text_tokens, ndim)
num_query: int.
Output:
topk_proposals_idx: (bs, num_query)
"""
logits = torch.einsum("bic,btc->bit",
image_features, text_features)
# bs, num_img_tokens, num_text_tokens
logits_per_img_feat = logits.max(-1)[0]
# bs, num_img_tokens
topk_proposals_idx = torch.topk(
logits_per_image_feature,
num_query, dim = 1)[1]
# bs, num_query
具体来说,通过CLIP分别获得其文本特征和图像特征,输入两个特征张量 image_features 和 text_features,其中 image_features 的维度为 (bs, num_img_tokens, ndim),text_features 的维度为 (bs, num_text_tokens, ndim),bs 表示 batch size,num_img_tokens 和 num_text_tokens 分别表示图像特征和文本特征的总数,ndim 则表示特征维度。
代码首先使用 torch.einsum 函数计算两个特征张量之间的得分矩阵 logits,得分矩阵中的每个元素表示一个图像特征与一个文本特征之间的得分。接下来使用 logits.max(-1)[0] 得到 logits_per_img_feat 张量,该张量的维度为 (bs, num_img_tokens),其中每个元素表示一个图像特征与所有文本特征之间的最大得分。因为我们只需要最大值张量,所以使用 [0] 表示取出最大值张量。使用 torch.topk 函数得到每个图像特征对应的前 num_query 个文本特征的索引。具体来说,该函数用于在某个维度上寻找前k个最大值。
encoder部分思想和grounding dino的基本一致,grounding dino encoder部分如下图:

2.2 decoder
解码器部分直接采用DETR-like detector,loss函数如下:

作者使用 L1 损失及 GIOU 损失用于框回归;沿用 GLIP,对预测目标是否匹配文本使用对比损失约束(和Grounding Dino采用相同的loss)。
3. Object captioner

本文的核心要点在于此,对象标题生成器使 DetCLIPv3 能够为对象生成详细和层次化的标签。设计灵感来自 Qformer,采用多模态 Transformer 架构,输入包括视觉(对象或图像)查询和文本标记。
据论文介绍,该模型能够在两种模式下工作:当提供预定义的类别词汇表时,DetCLIPv3 直接预测列表中提到的对象的位置。在没有词汇表的情况下,DetCLIPv3 能够定位对象并为每个对象生成层次化标签。
三、数据工程
1. Auto-annotation data pipeline
训练数据情况如下:

图中展示了经过多次处理后的标注信息变化,经过VLLM和GPT的调整,图像标注信息越来越丰富,果然数据工程才是如今多模态的core point!!!
数据集包括检测、定位和图像-文本对数据,这些数据包含边界框伪标签。每个输入样本被结构化为一个三元组,包括输入图像、一组边界框和一组概念文本。
此外文章提出了一个自动标注数据pipeline,流程图如下:

1)Recaptioning with VLLM:
首先利用BLIP对240K图像-文本对重新标注。prompt如下:
“Given a noisy caption of the image: {raw caption}, write a detailed clean description of the image.”
2)Entity extraction using GPT-4:
利用GPT-4过滤来自VLLM的无实体描述 prompt:
“Here is a caption for an image: {caption}. Extract the part of factual description related to what is directly observable in the image, while filtering out the parts that refer to inferred contents, description of atmosphere/appearance/style and introduction of history/culture/brand etc. Return solely the result without any other contents. If you think there is no factual description, just return ‘None’.”
从过滤后的caption中提取目标实体 prompt:


3)Instruction tuning of VLLM for large-scale annotation:
在此阶段,使用caption文本和刚获取的目标实例信息fine-tune LLaVA。作者合并了之前的信息使其成为一个简洁的prompt。question-answer pair is constructed as:

fine-tune 过程VLLM使用 原始图像和原始caption作为输入,目的是让VLLM去生成精细化的标签。

4)Instruction tuning of VLLM for large-scale annotation:
自动标注边界框,使用预训练的开放词汇表对象检测器为图像-文本对数据分配伪边界框标签。
当从VLLM中获得准确的候选对象实体时,可以大大提高检测器的精度。具体来说,我们使用字段“phrase”和“category”作为检测器的文本输入,并使用预定义的分数阈值来过滤产生的边界框。如果两个字段中的任何一个匹配,我们为该对象分配整个实体{phrase, category, parent category}。在使用预定义的置信度阈值进行过滤后,大约有50M的数据被采样用于后续的训练,我们称之为GranuCap50M。
为了训练检测器,我们使用“phrase”和“category”字段作为文本标签; 而对于对象captioner,我们将三个字段连接起来——“phrase|category|parent category”——作为对象的基本真理描述。
四、训练策略
为了解决高分辨率输入的计算成本问题,作者提出了一个基于“预训练+微调”的多阶段训练策略,包括:
1)训练开放词汇表检测器 (Stage 1)。
2)预训练对象标题生成器 (Stage 2),使用较低分辨率的输入以提高效率。
3)整体微调 (Stage 3),旨在使标题生成器适应高分辨率输入,同时改进开放词汇表检测器。
通过这些设计,DetCLIPv3 在开放词汇表检测性能上取得了显著的成果,例如,在 LVIS minival 基准测试中,使用 Swin-T 骨干模型取得了 47.0 的零样本固定 AP,显著优于以前的工作。

五、实验

作者还是做了蛮多评测实验的,上表在LVIS数据集上评估了模型的零样本性能,即模型的零样本开放词汇表对象检测能力,可以看出,通过使用固定AP(Average Precision)作为评价指标,DetCLIPv3 在 LVIS minival 上取得了 47.0 和 48.8 的AP,显著优于先前的方法,包括但不仅限于 GD 和 GLIP。
(其它实验评测可以参考原文)
总结
DetCLIPv3是一个创新的开放词汇表(OV)检测器,它不仅能够根据类别名称定位对象,还能生成具有层次结构和多粒度(multi-granular)的对象标签。这种增强的视觉能力使得DetCLIPv3能够实现更全面的细粒度(fine-grained)视觉理解,从而扩展了开放词汇表检测(OVD)模型的应用场景。
读完文章不得不说,现在的数据工程真的是百花齐放,利用VLLM+GPT产生的数据fine-tune VLLM的想法实在令人赞叹!