你是否曾经感觉被海量数据淹没?是否在寻找一种方法来有效地整合、转换和加载这些数据?如果是,那么你来对地方了。今天,我们将深入探讨ETL(Extract, Transform, Load)过程的三个关键步骤,这是每个大数据开发者都应该掌握的核心技能。准备好踏上成为数据整合大师的旅程了吗?让我们开始吧!

目录
- 什么是ETL?
- ETL的三大步骤
- 第一步:提取(Extract)
- 第二步:转换(Transform)
- 第三步:加载(Load)
- ETL示例:电商数据分析
- 步骤1:提取(Extract)
- 步骤2:转换(Transform)
- 步骤3:加载(Load)
- ETL工具与技术
- ETL最佳实践
- 结论
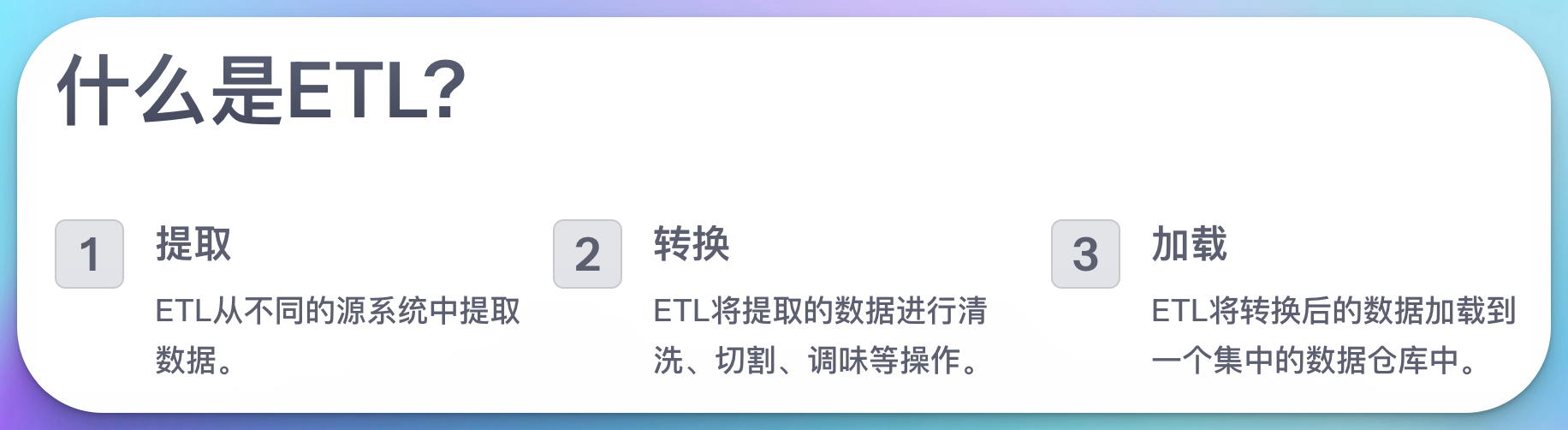
什么是ETL?
在深入探讨ETL的具体步骤之前,让我们先来理解什么是ETL。ETL是Extract(提取)、Transform(转换)和Load(加载)的缩写,它是数据仓库中最关键的过程之一。ETL负责将来自不同源系统的数据整合到一个集中的数据仓库中,以便进行后续的分析和报告。
想象一下,你是一位厨师,要准备一道复杂的菜肴。你需要从不同的供应商那里采购原料(提取),然后清洗、切割、调味这些原料(转换),最后将它们放入锅中烹饪(加载)。ETL过程就像这样,只不过我们处理的是数据,而不是食材。
ETL的三大步骤
现在,让我们详细探讨ETL的三个主要步骤,了解它们各自的作用和重要性。
第一步:提取(Extract)
提取是ETL过程的第一步,也是整个过程的基础。在这一步中,我们从各种数据源中获取所需的数据。这些数据源可能包括:
- 关系型数据库(如MySQL, Oracle, SQL Server)
- NoSQL数据库(如MongoDB, Cassandra)
- 平面文件(如CSV, JSON, XML)
- API接口
- 网页爬虫数据
提取步骤的主要作用是:
- 数据收集: 从多个异构源系统中收集原始数据。
- 数据验证: 确保提取的数据符合预期的格式和质量标准。
- 元数据管理: 记录数据的来源、时间戳和其他相关信息。
让我们看一个使用Python从CSV文件中提取数据的简单示例:
import pandas as pddef extract_data(file_path):try:# 使用pandas读取CSV文件df = pd.read_csv(file_path)print(f"Successfully extracted {len(df)} rows from {file_path}")return dfexcept Exception as e:print(f"Error extracting data from {file_path}: {str(e)}")return None# 使用函数
sales_data = extract_data('sales_data.csv')
if sales_data is not None:print(sales_data.head())
这个简单的函数演示了如何使用pandas库从CSV文件中提取数据。它不仅读取数据,还进行了基本的错误处理和日志记录,这是生产环境中ETL流程的重要组成部分。
第二步:转换(Transform)

转换是ETL过程中最复杂和最重要的步骤。在这一阶段,我们对提取的原始数据进行清理、标准化和转换,使其符合目标数据仓库的结构和业务规则。转换步骤的主要作用包括:
- 数据清洗: 处理缺失值、去除重复数据、修正错误数据等。
- 数据标准化: 统一数据格式,如日期格式、度量单位等。
- 数据集成: 合并来自不同源系统的数据。
- 数据聚合: 根据业务需求对数据进行汇总或计算。
- 数据编码: 将分类数据转换为数值编码,或者反之。
- 数据派生: 基于现有数据创建新的字段或指标。
让我们通过一个具体的例子来说明转换步骤。假设我们有一个包含销售数据的DataFrame,我们需要进行以下转换:
- 将日期字符串转换为datetime对象
- 计算总销售额(数量 * 单价)
- 对客户类型进行编码
- 处理缺失的邮政编码
以下是实现这些转换的Python代码:
import pandas as pd
import numpy as npdef transform_data(df):# 1. 将日期字符串转换为datetime对象df['Date'] = pd.to_datetime(df['Date'])# 2. 计算总销售额df['Total_Sales'] = df['Quantity'] * df['Unit_Price']# 3. 对客户类型进行编码customer_type_map = {'Regular': 0, 'VIP': 1, 'New': 2}df['Customer_Type_Code'] = df['Customer_Type'].map(customer_type_map)# 4. 处理缺失的邮政编码df['Postal_Code'].fillna('Unknown', inplace=True)# 5. 创建一个新的字段:月份df['Month'] = df['Date'].dt.monthreturn df# 假设我们已经有了一个名为sales_data的DataFrame
transformed_data = transform_data(sales_data)
print(transformed_data.head())
print(transformed_data.info())
这个例子展示了几种常见的数据转换操作。在实际的ETL过程中,转换步骤可能会更加复杂,包括多表join、复杂的业务逻辑计算等。
第三步:加载(Load)
加载是ETL过程的最后一步,也是将转换后的数据写入目标系统的过程。这个目标系统通常是一个数据仓库,但也可能是数据集市或其他类型的分析系统。加载步骤的主要作用包括:
- 数据写入: 将转换后的数据插入或更新到目标表中。
- 索引管理: 创建或更新必要的索引以提高查询性能。
- 数据验证: 确保加载的数据符合目标系统的完整性约束。
- 历史数据管理: 维护历史数据,支持增量加载和全量加载。
加载过程可以采用不同的策略,主要包括:
- 完全刷新: 每次ETL运行时都删除目标表中的所有现有数据,然后插入新数据。
- 增量更新: 只加载自上次ETL运行以来发生变化的数据。
- 合并更新: 将新数据与现有数据合并,更新已存在的记录并插入新记录。

以下是一个使用SQLAlchemy将转换后的数据加载到PostgreSQL数据库的示例:
from sqlalchemy import create_engine
from sqlalchemy.types import Integer, Float, String, DateTimedef load_data(df, table_name, db_connection_string):try:# 创建数据库连接engine = create_engine(db_connection_string)# 定义列的数据类型dtype = {'Date': DateTime,'Product_ID': String(50),'Quantity': Integer,'Unit_Price': Float,'Total_Sales': Float,'Customer_Type': String(20),'Customer_Type_Code': Integer,'Postal_Code': String(10),'Month': Integer}# 将数据写入数据库df.to_sql(table_name, engine, if_exists='replace', index=False, dtype=dtype)print(f"Successfully loaded {len(df)} rows into {table_name}")except Exception as e:print(f"Error loading data into {table_name}: {str(e)}")# 使用函数
db_connection_string = "postgresql://username:password@localhost:5432/mydatabase"
load_data(transformed_data, 'sales_fact', db_connection_string)
这个例子展示了如何将转换后的数据加载到PostgreSQL数据库中。它使用SQLAlchemy ORM来处理数据库连接和数据类型映射,这是一种流行的处理数据库操作的Python库。
ETL示例:电商数据分析
为了更好地理解ETL过程,让我们通过一个完整的电商数据分析场景来演示整个ETL流程。
假设我们是一家电子商务公司的数据分析师,需要整合来自不同系统的数据以生成销售报告。我们有以下数据源:
- 订单数据(CSV文件)
- 产品信息(JSON文件)
- 客户数据(关系型数据库)
我们的目标是创建一个集成的销售事实表,用于后续的分析和报告生成。
步骤1:提取(Extract)
首先,我们需要从各个数据源提取数据:
import pandas as pd
import json
import sqlite3def extract_order_data(file_path):return pd.read_csv(file_path)def extract_product_data(file_path):with open(file_path, 'r') as f:return pd.DataFrame(json.load(f))def extract_customer_data(db_path):conn = sqlite3.connect(db_path)query = "SELECT * FROM customers"return pd.read_sql(query, conn)# 提取数据
orders = extract_order_data('orders.csv')
products = extract_product_data('products.json')
customers = extract_customer_data('customers.db')print("Extracted data:")
print("Orders shape:", orders.shape)
print("Products shape:", products.shape)
print("Customers shape:", customers.shape)
步骤2:转换(Transform)
接下来,我们需要清理、集成和转换提取的数据:
def transform_data(orders, products, customers):# 合并订单和产品数据merged_data = pd.merge(orders, products, on='product_id', how='left')# 合并客户数据merged_data = pd.merge(merged_data, customers, on='customer_id', how='left')# 计算总销售额merged_data['total_sales'] = merged_data['quantity'] * merged_data['price']# 转换日期格式merged_data['order_date'] = pd.to_datetime(merged_data['order_date'])# 提取年份和月份merged_data['year'] = merged_data['order_date'].dt.yearmerged_data['month'] = merged_data['order_date'].dt.month# 客户分类编码customer_type_map = {'Regular': 0, 'VIP': 1, 'New': 2}merged_data['customer_type_code'] = merged_data['customer_type'].map(customer_type_map)# 处理缺失值merged_data['category'].fillna('Unknown', inplace=True)return merged_data# 转换数据
transformed_data = transform_data(orders, products, customers)print("\nTransformed data:")
print(transformed_data.head())
print(transformed_data.info())
步骤3:加载(Load)
最后,我们将转换后的数据加载到数据仓库中:
from sqlalchemy import create_enginedef load_data(df, table_name, db_connection_string):engine = create_engine(db_connection_string)df.to_sql(table_name, engine, if_exists='replace', index=False)print(f"Successfully loaded {len(df)} rows into {table_name}")# 加载数据
db_connection_string = "postgresql://username:password@localhost:5432/data_warehouse"
load_data(transformed_data, 'sales_fact', db_connection_string)
这个完整的ETL示例展示了如何从多个数据源提取数据,对数据进行清理和转换,然后将结果加载到数据仓库中。这种集成的销售事实表可以用于各种分析,如销售趋势分析、客户行为分析、产品性能评估等。
ETL工具与技术
虽然我们在上面的例子中使用了Python来实现ETL过程,但在实际的企业环境中,通常会使用专门的ETL工具或框架来处理大规模的数据集成任务。以下是一些流行的ETL工具和技术:
-
Apache Spark: 一个强大的大数据处理框架,适用于大规模数据处理和ETL任务。
-
Apache NiFi: 一个易用的、基于Web的数据流管理和ETL工具。
-
Talend: 一个开源的ETL工具,提供图形化界面和代码生成功能。
-
Informatica PowerCenter: 企业级的ETL平台,广泛应用于大型企业。
-
AWS Glue: 亚马逊提供的全托管式ETL服务,与其他AWS服务集成良好。
-
Airflow: 一个用于编排复杂数据管道的开源平台,由Airbnb开发。
-
Pentaho Data Integration (Kettle): 一个功能强大的开源ETL工具,提供图形化设计器。
每个工具都有其优缺点,选择哪一个取决于你的具体需求、预算和技术栈。对于大数据开发者来说,熟悉至少一两种主流ETL工具是非常有必要的。
ETL最佳实践

无论你使用哪种工具或技术来实现ETL,以下是一些值得遵循的最佳实践:
-
数据质量优先: 在转换步骤中实施严格的数据质量检查和清理程序。垃圾进,垃圾出 - 确保你的数据仓库中只有高质量的数据。
def validate_data(df):# 检查必填字段assert df['order_id'].notnull().all(), "存在缺失的订单ID"# 检查数值范围assert (df['quantity'] > 0).all(), "存在无效的订单数量"# 检查日期有效性assert (df['order_date'] <= pd.Timestamp.now()).all(), "存在未来日期的订单"print("数据验证通过")# 在转换步骤中调用 validate_data(transformed_data) -
增量加载: 对于大型数据集,考虑实施增量加载策略,只处理新的或更改的数据,而不是每次都完全重新加载。
def incremental_load(new_data, existing_data, key_column):# 找出新数据中的新记录和更新记录merged = pd.merge(new_data, existing_data[[key_column]], on=key_column, how='left', indicator=True)to_insert = merged[merged['_merge'] == 'left_only'].drop('_merge', axis=1)to_update = merged[merged['_merge'] == 'both'].drop('_merge', axis=1)return to_insert, to_update# 使用示例 new_records, updated_records = incremental_load(new_sales_data, existing_sales_data, 'order_id') -
错误处理和日志记录: 实施全面的错误处理和日志记录机制,以便快速识别和解决问题。
import logginglogging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')def safe_transform(func):def wrapper(*args, **kwargs):try:result = func(*args, **kwargs)logging.info(f"Successfully executed {func.__name__}")return resultexcept Exception as e:logging.error(f"Error in {func.__name__}: {str(e)}")raisereturn wrapper@safe_transform def transform_data(df):# 转换逻辑pass -
并行处理: 利用并行处理技术来提高ETL过程的效率,特别是对于大型数据集。
from multiprocessing import Pooldef process_chunk(chunk):# 处理数据块的逻辑return transformed_chunkdef parallel_transform(data, num_processes=4):chunks = np.array_split(data, num_processes)with Pool(num_processes) as p:results = p.map(process_chunk, chunks)return pd.concat(results)# 使用示例 transformed_data = parallel_transform(large_dataset) -
版本控制和文档: 对ETL脚本和配置进行版本控制,并保持文档的更新。这对于长期维护和团队协作至关重要。
-
测试: 为ETL过程编写单元测试和集成测试,确保数据转换的正确性和一致性。
import unittestclass TestETLProcess(unittest.TestCase):def setUp(self):self.sample_data = pd.DataFrame({'order_id': [1, 2, 3],'product_id': ['A', 'B', 'C'],'quantity': [2, 3, 1],'price': [10.0, 15.0, 20.0]})def test_total_sales_calculation(self):result = transform_data(self.sample_data)expected_total_sales = [20.0, 45.0, 20.0]self.assertTrue(np.allclose(result['total_sales'], expected_total_sales))if __name__ == '__main__':unittest.main() -
监控和警报: 实施监控系统来跟踪ETL作业的性能和状态,并在出现问题时发送警报。
-
数据隐私和安全: 确保ETL过程符合数据隐私法规(如GDPR),并实施适当的数据安全措施。
from cryptography.fernet import Fernetdef encrypt_sensitive_data(df, sensitive_columns, key):f = Fernet(key)for col in sensitive_columns:df[col] = df[col].apply(lambda x: f.encrypt(str(x).encode()).decode())return df# 使用示例 key = Fernet.generate_key() encrypted_data = encrypt_sensitive_data(customer_data, ['email', 'phone'], key)
结论
ETL是数据仓库和大数据项目中不可或缺的一部分。通过掌握提取、转换和加载这三个关键步骤,你可以有效地整合来自不同源系统的数据,为后续的数据分析和商业智能提供坚实的基础。
在本文中,我们深入探讨了ETL的每个步骤,提供了实际的代码示例,并讨论了一些常用的工具和最佳实践。记住,成功的ETL过程不仅需要技术技能,还需要对业务需求的深入理解和对数据质量的不懈追求。
作为一名大数据开发者,持续学习和实践ETL技术将使你在竞争激烈的数据科学领域中脱颖而出。无论你是在构建数据湖、实施实时分析系统,还是开发机器学习模型,扎实的ETL技能都将是你的强大武器。
最后,我想强调的是,ETL不仅仅是一个技术过程,它是连接原始数据和有价值洞察之间的桥梁。通过精心设计和实施ETL流程,你可以将杂乱无章的数据转化为结构化的、可操作的信息,为企业决策提供强有力的支持。
你准备好接受ETL的挑战了吗?开始实践吧,让数据为你所用!
![[B站大学]Zotero7教程](https://i-blog.csdnimg.cn/direct/74115aa4495c4e38b0dc99585abd0cfc.png)