1. 设计目标
Bigcache 是用 Golang 实现的本地内存缓存的开源库,主打的就是可缓存数据量大,查询速度快。 在其官方的介绍文章《 Writing a very fast cache service with millions of entries in Go 》一文中,明确提出的 bigcache 的设计目标:
- 多: 缓存的元素数量非常大,可以达到百万级或千万级。
- 快: 对延迟有非常高的要求,平均延迟要求在 5 毫秒以内。redis 、memcached 之类的就不在考虑范围内了,毕竟用 Redis 还要多走一遍网络 IO 。
- 稳: 99.9 分位延迟应在 10 毫秒左右,99.999 分位延迟应在 400 毫秒左右。
目前有许多开源的 cache 库,大部分都是基于 map 实现的,例如 go-cache,ttl-cache 等。bigcache 明确指出,当数据量巨大时,直接基于 map 实现的 cache 库将出现严重的性能问题,这也是他们设计了一个全新的 cache 库的原因。
本文将通过分析 bigcache v3.1.0 的源码,揭秘 bigcache 如何解决现有 map 库的性能缺陷,以极致的性能优化,实现超高性能的缓存库。
2. 整体原理
2.1. 时序图

2.1.1. 为什么分片数需要是2的幂次
这样分片数减1之后,前几位都是1,可以通过位运算&取hash的后几位,即通过位运算实现hash取余,更加高效
1. hashkey和分片数都为uint64,
2. 如分片数为16,减1后为15,二进制为为00000000 00001111
3. 如果hashkey为17,二进制为0000000 00010001
4. hashkey&(shareds-1)=17&(16-1)=1
5. 17%16=1, 即hashkey&(shareds-1)能通过位运算实现取余
3. 数据结构
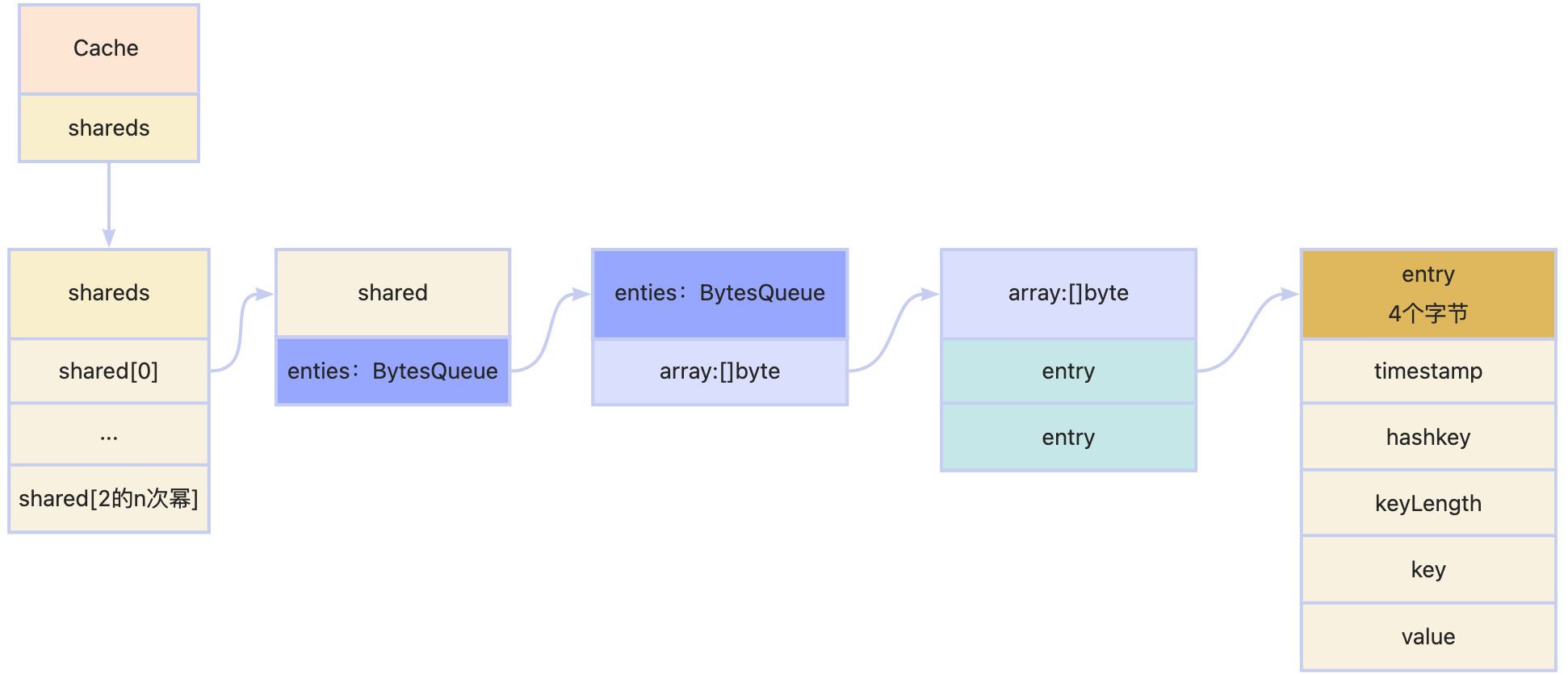
4. 注意点
- bigcache处理hash冲突的方式是把map和entries里的值删掉,然后再重新插入。之前的值会被删除
5. 初始化
func newBigCache(ctx context.Context, config Config, clock clock) (*BigCache, error) {// Shards数需要是2的次幂if !isPowerOfTwo(config.Shards) {return nil, errors.New("Shards number must be power of two")}if config.MaxEntryByte < 0 {return nil, errors.New("MaxEntrySize must be >= 0")}if config.MaxEntriesInWindow < 0 {return nil, errors.New("MaxEntriesInWindow must be >= 0")}if config.HardMaxCacheSize < 0 {return nil, errors.New("HardMaxCacheSize must be >= 0")}lifeWindowSeconds := uint64(config.LifeWindow.Seconds())if config.CleanWindow > 0 && lifeWindowSeconds == 0 {return nil, errors.New("LifeWindow must be >= 1s when CleanWindow is set")}if config.Hasher == nil {config.Hasher = newDefaultHasher()}cache := &BigCache{shards: make([]*cacheShard, config.Shards),lifeWindow: lifeWindowSeconds,clock: clock,hash: config.Hasher,config: config,shardMask: uint64(config.Shards - 1),close: make(chan struct{}),}var onRemove func(wrappedEntry []byte, reason RemoveReason)if config.OnRemoveWithMetadata != nil {onRemove = cache.providedOnRemoveWithMetadata} else if config.OnRemove != nil {onRemove = cache.providedOnRemove} else if config.OnRemoveWithReason != nil {onRemove = cache.providedOnRemoveWithReason} else {onRemove = cache.notProvidedOnRemove}for i := 0; i < config.Shards; i++ {cache.shards[i] = initNewShard(config, onRemove, clock)}if config.CleanWindow > 0 {go func() {ticker := time.NewTicker(config.CleanWindow)defer ticker.Stop()for {select {case <-ctx.Done():returncase t := <-ticker.C:cache.cleanUp(uint64(t.Unix()))case <-cache.close:return}}}()}return cache, nil
}
6. set
func (c *BigCache) Set(key string, value []byte) error {hashedKey := c.hash.Sum64(key)shard := c.getShard(hashedKey)return shard.set(key, hashedKey, value)
}
核心代码在shard.go上
func (s *cacheShard) set(key string, hashedKey uint64, value []byte) error {currentTimestamp := uint64(s.clock.Epoch())s.lock.Lock()//检查 hashmap 中是否已有相同的 hashedKey。如果有,则清理掉//获取先前的条目,并调用 resetHashFromEntry 函数重置该条目的哈希值(通常是为了清理之前的哈希映射)。//然后,从 hashmap 中删除旧的 hashedKey 条目if previousIndex := s.hashmap[hashedKey]; previousIndex != 0 {if previousEntry, err := s.entries.Get(int(previousIndex)); err == nil {//打上一个已处理的标记,保证数据在淘汰的时候不再去调用OnRemove的callbackresetHashFromEntry(previousEntry)//remove hashkeydelete(s.hashmap, hashedKey)}}//如果清理(淘汰)功能未启用,则检查缓存中是否存在最旧的条目(oldestEntry)。//如果存在,调用 s.onEvict 方法处理淘汰操作,将最旧的条目移除或进行其他处理if !s.cleanEnabled {if oldestEntry, err := s.entries.Peek(); err == nil {s.onEvict(oldestEntry, currentTimestamp, s.removeOldestEntry)}}// 使用 wrapEntry 函数将条目封装起来。wrapEntry 函数创建一个新的条目对象,//包括时间戳、哈希键、原始键、条目数据以及一个缓冲区(entryBuffer),以便在缓存中进行存储w := wrapEntry(currentTimestamp, hashedKey, key, value, &s.entryBuffer)//使用循环将封装的条目 (w) 推入 entries 数据结构中。如果成功,更新 hashmap 中的索引,并解锁 lock,然后返回 nil 表示成功。//如果推入操作失败(例如由于空间不足),调用 s.removeOldestEntry(NoSpace) 尝试移除最旧的条目以腾出空间。//如果此操作仍未成功(即条目太大无法放入缓存),则解锁并返回一个错误,表示条目超出了最大缓存分片大小for {// 将包装过的value放入entries中if index, err := s.entries.Push(w); err == nil {s.hashmap[hashedKey] = uint64(index)s.lock.Unlock()return nil}if s.removeOldestEntry(NoSpace) != nil {s.lock.Unlock()return errors.New("entry is bigger than max shard size")}}
}
7. get
func (c *BigCache) Get(key string) ([]byte, error) {hashedKey := c.hash.Sum64(key)shard := c.getShard(hashedKey)return shard.get(key, hashedKey)
}
func (s *cacheShard) get(key string, hashedKey uint64) ([]byte, error) {s.lock.RLock()wrappedEntry, err := s.getWrappedEntry(hashedKey)if err != nil {s.lock.RUnlock()return nil, err}//zhmark 2024/8/21 有可能因为不同的key生成的hashedKey相同,虽然这次get时候的hashkey在map中存在,//但是实际上是其他key存入的,这个时候实际上是没有set过这个key的if entryKey := readKeyFromEntry(wrappedEntry); key != entryKey {s.lock.RUnlock()s.collision()if s.isVerbose {// 发生碰撞s.logger.Printf("Collision detected. Both %q and %q have the same hash %x", key, entryKey, hashedKey)}return nil, ErrEntryNotFound}value := readEntry(wrappedEntry)s.lock.RUnlock()s.hit(hashedKey)return value, nil
}
8. 设计优点
8.1. 处理并发访问
8.1.1. 设计点1:将数据打散后存储
通用解法: 缓存支持并发访问是很基本的要求,比较常见的解决访问是对缓存整体加读写锁,在同一时间只允许一个协程修改缓存内容。这样的缺点是锁可能会阻塞后续的操作,而且高频的加锁、解锁操作会导致缓存性能降低。
设计点: BigCache使用一个shardshard数组来存储数据,将数据打散到不同的shardshard里,每个shardshard里都有一个小的locklock,从而减小了锁的粒度,提高访问性能。
8.1.2. 设计点2:打散数据过程中借助位运算加快计算速度
接下来看一下将某个数据放到缓存的过程的源代码:
// Set saves entry under the key
func (c *BigCache) Set(key string, entry []byte) error {hashedKey := c.hash.Sum64(key)shard := c.getShard(hashedKey)return shard.set(key, hashedKey, entry)
}
func (c *BigCache) getShard(hashedKey uint64) (shard *cacheShard) {return c.shards[hashedKey&c.shardMask]
}
可以得到setset的过程如下:
- 进行hashhash操作,将stringstring类型keykey哈希为一个uint64uint64类型的hashedKeyhashedKey
- 根据hashedKeyhashedKey做shardingsharding,最后落到的shardshard的下标为hashedKey%nhashedKey%n,其中nn是分片数量。理想情况下,每次请求会均匀地落在各自的分片上,单个shardshard的压力就会很小。
- 调用对应shardshard的set方法来设置缓存
设计点:
当nn为22的幂次方的时候,对于任意的xx,下面的公式都成立的。
x mod N=(x&(N−1))x mod N=(x&(N−1))
所以可以借助位运算快速计算余数,因此倒推回去 缓存分片数必须要设置为22****的幂次方。
8.1.3. 设计点3 避免栈上的内存分配
默认的哈希算法为fnv64fnv64算法,该算法采用位运算的方式在栈上运算,避免了在堆上分配内存
package bigcache// newDefaultHasher returns a new 64-bit FNV-1a Hasher which makes no memory allocations.
// Its Sum64 method will lay the value out in big-endian byte order.
// See https://en.wikipedia.org/wiki/Fowler–Noll–Vo_hash_function
func newDefaultHasher() Hasher {return fnv64a{}
}type fnv64a struct{}const (// offset64 FNVa offset basis. See https://en.wikipedia.org/wiki/Fowler–Noll–Vo_hash_function#FNV-1a_hashoffset64 = 14695981039346656037// prime64 FNVa prime value. See https://en.wikipedia.org/wiki/Fowler–Noll–Vo_hash_function#FNV-1a_hashprime64 = 1099511628211
)// Sum64 gets the string and returns its uint64 hash value.
func (f fnv64a) Sum64(key string) uint64 {var hash uint64 = offset64for i := 0; i < len(key); i++ {hash ^= uint64(key[i])hash *= prime64}return hash
}
8.2. 减少GC开销
8.2.1. 设计点1:利用go1.5+特性,减少GC扫描
golanggolang里实现缓存最简单的方式是mapmap来存储元素,比如map[string]Itemmap[string]Item。
使用mapmap的缺点为垃圾回收器GCGC会在标记阶段访问mapmap里的每一个元素,当mapmap里存储了大量数据的时候会降低程序性能。
BigCacheBigCache使用了go1.5go1.5版本以后的特性:如果使用的map的key和value中都不包含指针,那么GC会忽略这个map
具体而言,BigCacheBigCache使用map[uint64]uint32map[uint64]uint32
来存储数据,不包含指针,GCGC就会自动忽略这个mapmap。
mapmap的keykey存储的是缓存的keykey经过hashhash函数后得到的值
mapmap的valuevalue存储的是序列化后的数据在全局[]byte[]byte中的下标。
因为BigCacheBigCache是将存入缓存的valuevalue序列化为bytebyte数组,然后将该数组追加到全局的bytebyte数组里(说明:结合前面的打散思想可以得知一个shardshard对应一个全局的bytebyte数组)
这样做的缺点是删除元素的开销会很大,因此BigCacheBigCache里也没有提供删除指定keykey的接口,删除元素靠的是全局的过期时间或是缓存的容量上限,是先进先出的队列类型的过期
9. 可优化点
- shard的默认为1024,不需要使用方配置