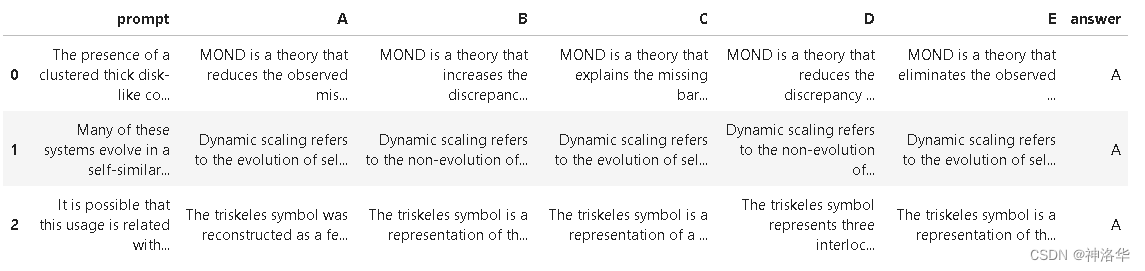
1. 插入操作优化
1.1 使用多值插入
通常情况下,插入大量数据时,使用多值插入语句比逐行插入更高效。例如,将多个数据行打包成一个 INSERT 语句:
INSERT INTO users (name, email) VALUES
('Alice', 'alice@example.com'),
('Bob', 'bob@example.com'),
('Charlie', 'charlie@example.com');
1.2 批量插入
使用 INSERT INTO ... VALUES 插入大量数据时,考虑使用 INSERT INTO ... SELECT 或 LOAD DATA INFILE 导入数据,以减少插入操作的开销。
2. 主键优化
2.1 使用适当的数据类型
选择适当的主键数据类型,通常整数类型(如 INT 或 BIGINT)比字符串类型更快。此外,考虑使用自增主键,以避免主键碎片化。
2.2 使用主键索引
主键列默认具有索引。确保查询中使用主键,以获得最佳性能。
3. ORDER BY 优化
3.1 使用索引列进行排序
如果需要对结果集进行排序,请确保 ORDER BY 子句中包含索引列。这将减少排序操作的开销。
SELECT * FROM products ORDER BY price;
3.2 限制排序行数
如果不需要对整个结果集进行排序,可以使用 LIMIT 来限制排序的行数,以提高性能。
SELECT * FROM products ORDER BY price LIMIT 10;
4. GROUP BY 优化
4.1 避免使用 SELECT *
尽量避免在 GROUP BY 查询中使用 SELECT *,只选择需要的列,以减少数据传输和处理开销。
4.2 使用合适的索引
为 GROUP BY 子句中的列创建索引,以加速分组操作。
SELECT department, AVG(salary) FROM employees GROUP BY department;
5. LIMIT 优化
5.1 使用分页
当使用 LIMIT 进行分页查询时,将 LIMIT 和 OFFSET 与合适的索引一起使用,以避免扫描整个表。
SELECT * FROM orders WHERE status = 'shipped' LIMIT 10 OFFSET 20;
5.2 使用缓存
如果查询结果不经常变化,可以使用缓存来存储结果,以减少数据库查询的频率。
6. COUNT 优化
6.1 使用 COUNT(*)
在统计行数时,使用 COUNT(*) 比 COUNT(column) 更高效,因为它不会检查列的值。
SELECT COUNT(*) FROM users;
7. UPDATE 优化
7.1 批量更新
避免逐行更新数据,而是使用批量更新语句一次性更新多行。
UPDATE products SET stock = stock - 1 WHERE category = 'electronics';
7.2 使用索引
确保 UPDATE 查询使用索引以快速定位要更新的行。
UPDATE users SET status = 'inactive' WHERE last_login < '2023-01-01';