An Evaluation of Concurrency Control with One Thousand Cores
Staring into the Abyss: An Evaluation of Concurrency Control with One Thousand Cores
ABSTRACT
随着多核处理器的发展,一个芯片可能有几十乃至上百个core。在数百个线程并行运行的情况下,协调对数据的竞争访问的复杂性可能会减少增加的核心数所带来的收益。探索当前DBMS的设计对于未来超多核数的CPU的适应性,在多核芯片上跑OLTP来进行评估,使用7种并发控制算法在内存数据库,使用计算机模拟的1024核来进行测试,所有算法都无法适配,所有数据库都有基本的性能瓶颈,因此与追求增量解决方案相比,以后应该考虑针对多核芯片完全重新设计的DBMS体系结构,该体系结构从头开始构建,并与(新)硬件紧密耦合。
1. INTRODUCTION
单核性能的提升已经很难了,考虑到当前的功率限制和单线程处理的低效率,除非出现颠覆性技术,否则增加内核数量是架构师目前能够提高计算能力的唯一方法。因此我们正在进入多核机器的时代。指令级的并行和单线程的这种性能改进将让位于大规模线程级的并行的性能改进(更有意义)。
可能很快One Chip就有a thousand cores,这时对于单节点共享内存的DBMS来说scalability就非常重要了,如果不能充分利用这些cores,那么DBMS 👎🏻。聚焦于千核下,事务处理的并发控制的具体表现,通过OLTP来研究DBMS的伸缩性。
在主存DBMS中实现了七种并发控制算法,并使用高性能分布式CPU模拟器将系统扩展到1000核。暂时缺少针对多核CPU,来大规模评估单个DBMS上的多个并发控制算法。
- 本文主要contributions:
- 对7个并发控制方案的可扩展性进行了全面的评估
- 在1000核上的OLTP DBMS的第一次评估
- 确定了非特定于实现(与数据库实现无关)的并发控制方案中的瓶颈
2. CONCURRENCY CONTROL SCHEMES
A transaction in the context of one of these systems is the execution of a sequence of one or more operations (e.g., SQL queries) on a shared database to perform some higher-level function.
-
现代OLTP工作负载中的事务有三个显著特征:
(1) they are short-lived (i.e., no user stalls)
(2) 使用索引查找一小部分数据来完成事务,没有全表扫描或者规模很大的join
(3) they are repetitive (i.e., executing the same queries with different inputs)
OLTP DBMS期望为它执行的每个事务维护四个属性:ACID,并发控制允许终端用户以Multi-programmed fashion来访问数据库,同时保持他们每个人都在专用系统上单独执行事务的错觉,并发控制本质上提供了系统中的原子性和隔离性保证。
进行探索的并发控制方案是2PL 或者 T/O的变体。
2.1 Two-Phase Locking
锁的所有权的规则:(1) 不同事物不能拥有冲突的locks (2) 一旦事务放弃了锁的所有权,可能永远无法获得其他的锁(饿死?)
2PL的两个阶段,第一个阶段增长growing phase阶段:获取锁不需要释放;第二阶段收缩shrinking phase阶段:禁止获取额外的锁,释放锁,事务commit/abort的时候所有锁返回给coordinator。 可能会产生死锁。
-
2PL with Deadlock Detection(DL_DETECT)
DBMS通过监视waits-for graph Jakob_Hu’blog CSDN(类似于进程资源图 如果有环则有死锁)来检查死锁,如果出现死锁则选择一个代价最小(资源量,拥有锁的数量)的事务进行终止来打破死锁
-
2PL with Non-waiting Deadlock Prevention (NO_WAIT)
死锁预防,如果出现冲突则立刻回滚。可能饿死所以有了wait die
-
2PL with Waiting Deadlock Prevention (WAIT_DIE):
No-Wait的非抢占式变体,如果事务比持有锁的事务老,则允许等待,如果年轻则终止这个请求锁的事务。每个事务在执行之前都需要获得一个时间戳,时间戳排序保证不会发生死锁。
2.2 Timestamp Ordering
T/O先验生成事务的可串行化执行顺序。事务在执行前被分配一个唯一的、单调递增的时间戳;这个时间戳被DBMS用来以适当的顺序处理冲突的操作。
对T/O的一些改进主要是(1) DBMS的检查粒度:tuples or partitions (2) DBMS检查冲突的时间,事务运行中或者结束的时候。

-
Basic T/O
事务每次读写元组的时候对时间戳进行比较,如果事务的时间戳<该元组最后一次写入的时间戳,则拒绝该事务的请求; 如果事务的时间戳小于该元组最后一次读的时间戳,DBMS将拒绝它。读查询读的是元组的副本,可以并发读。
Basic T/O是一个中心化的scheduler 然后本文的实现是一个decentralized 分散的scheduler。
-
MVCC
MVCC下每个写操作都会在数据库中创建一个元组的一个新版本出来, 每个版本有个时间戳对应最后对他写的事务的时间戳?还是写的时间戳,读操作由DBMS决定读版本,MVCC不延迟操作,假设要读的正在被写还是能读(对不对另说了)
-
OCC
DBMS需要track 读写集,在事务提交的时候检查该事务的读集是否和其他并发事务的写集有依赖,如果没有可以直接commit,如果有则需要abort restart。并发度高,只在commit阶段提交更新的时候才会check。Modern OCC: Silo and Hekaton,本文的OCC实现类似于Hekaton 将验证阶段并行化。
-
T/O with Partition-level Locking(H-STORE)
分区划分,每个分区都有一个排他锁由执行器的线程管理,一个事务在开始运行之前要获得所要访问的所有分区的锁。当事务请求到达时,DBMS为其分配一个时间戳,然后将其添加到其目标分区的所有锁获取队列中。如果事务具有队列中最早的时间戳,则授予它对该分区的访问权限(Lock)。
3. MANY-CORE DBMS TEST-BED
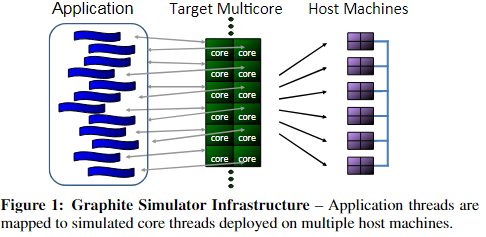
使用Graphite来模拟一个可以扩展到1024 core CPU,DBMS开发了一个内存OLTP engine。定制DBMS 可以排除变量只有并发控制一个平静,第二是使用现有的DBMS会很慢(模拟器的运算很慢?)
3.1 Simulator and Target Architecture
Graphite是一个用于大规模多core系统的CPU模拟器,为架构中每一个core创建一个单独的线程来运行linux process。每个线程被attached to一个模拟的内核线程,然后可以将其映射到不同物理主机上的不同进程上。只执行应用程序不会模拟操作系统,在本文中部署Graphite到一个22节点的集群中,每个node有双插槽(double-socket)Intel Xeon E5-2670和64GB DRAM。
Target architecture是tiled分层多核CPU,平铺式芯片多处理器,使用高带宽、二维网格片上网络相互连接,每跳需要两个周期。使用共享的L2-cache configuration。
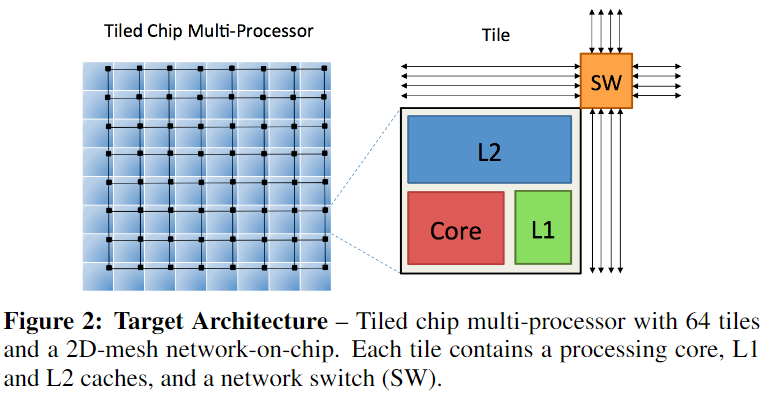
3.2 DBMS
事务运行时的数据:throughput、latency and abort rates.其他六种度量
- useful work:事务执行和操作元组的时间
- ABORT:事务回滚所做的所有更改的开销
- TS ALLOCATION:对于需要时间戳的并发控制协议,系统从centralized allocator获取时间戳的时间
- INDEX:事务在hash index上花费的时间
- WAIT:事务必须等待的总时间,2PL,T/O
- MANGAER:除了等待时间,事务在lock管理器、时间戳管理器的中花费的时间。
3.2 Workloads
TCSB+TPC-C
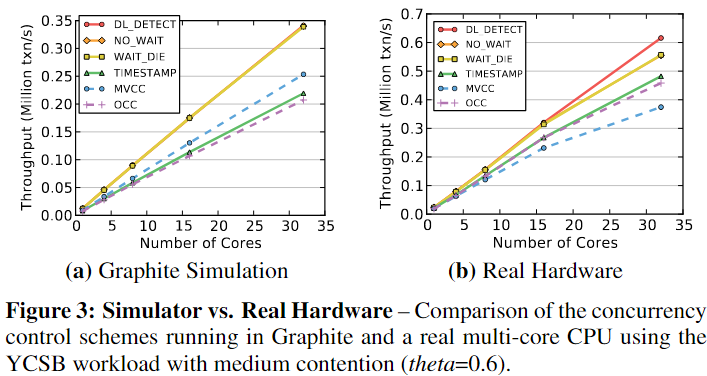
3.3 Simulator vs. Real Hardware
为了证明Graphite的效果和真实硬件的效果差不多,在现有硬件上部署DBMS,执行了一个读密集型YCSB,使用相同数量的core在graphite上执行相同的负载。所有并发方案在graphite和真是硬件上表现出相同的性能变化趋势,MVCC T/O OCC之间的相对性能差异有不同,MVCC访问内存更多在tw0-socket system中代价更高,而graphite建模是single CPU socket,没有inter-socket的代价.32核的时候TO和WAIT_DIE性能下降,主要因为在分配时间戳的时候需要进行跨核通讯。
4. DESIGN CHOICES & OPTIMIZATIONS
主要挑战之一就是:设计一个扩展性很好的DBMS以及并发控制方案,主要需要消除共享数据结构,设计经典版本的并发控制方案的分布式版本。还确定了2PL / T/O 算法的基本瓶颈,并展示了硬件支持来解决该问题。
4.1 General Optimizations
对所有并发控制方案做的对DBMS的优化
-
Memory Allocation
malloc,DBMS花费大量时间来等待内存分配,即使对于读也有复制Records,并为访问跟踪数据结构创建内部元数据句柄,TCmalloc jemalooc效果都不好,自己重写了malloc,每个线程都被分配了自己的内存池,本文的allocator会根据工作负载自动调整池的大小。
-
Lock Table
锁表是dbms中的另一个关键争用点,没有使用centralized lock table 或者 timestamp manager而是实现了一个元组粒度的加锁。提高了可伸缩性,但增加了内存开销
-
Mutexes
互斥锁,由互斥锁保护的中心临界区将限制任何系统的可伸缩性。因此,避免在关键路径上使用互斥锁是很重要的。对于2PL,保护集中式死锁检测器的互斥锁是主要瓶颈,而对于T/O算法,用于分配唯一时间戳的互斥锁是主要瓶颈。
4.2 Scalable Two-Phase Locking
-
Deadlock Detection
死锁检测,死锁检测是一个瓶颈,多个线程竞争更新等待图(centralized),通过跨核划分数据结构并且让死锁检测器完全无锁来解决。(没看懂
-
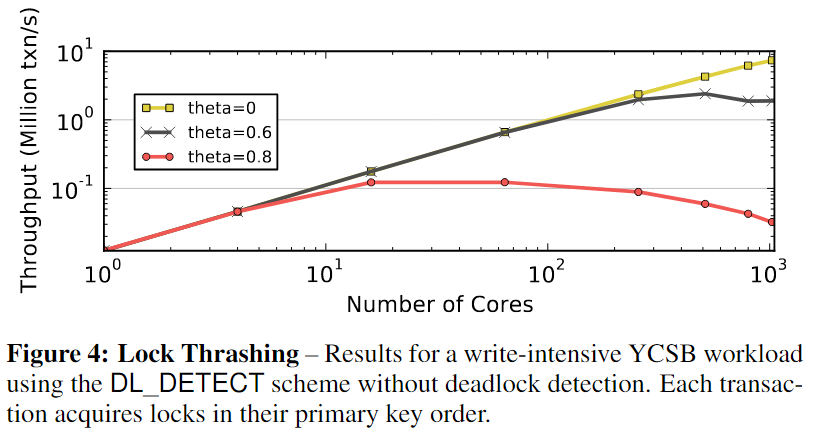
Lock Thrashing
锁抖动,由于锁抖动,DL_DETECT还是不能扩展,当事务在提交之前保持其锁,阻塞所有其他试图获取这些锁的并发事务时,就会发生这种情况。具体的,在写密集型中按照事务的主键顺序来获得锁,就不需要进行死锁检测了,来观察锁抖动,随着写事务比例增加,竞争增加,在核数增多的情况下,不能够线性扩展,所以说明锁方法本事就是一个瓶颈,限制了在多核高争用场景下的可伸缩性。
-
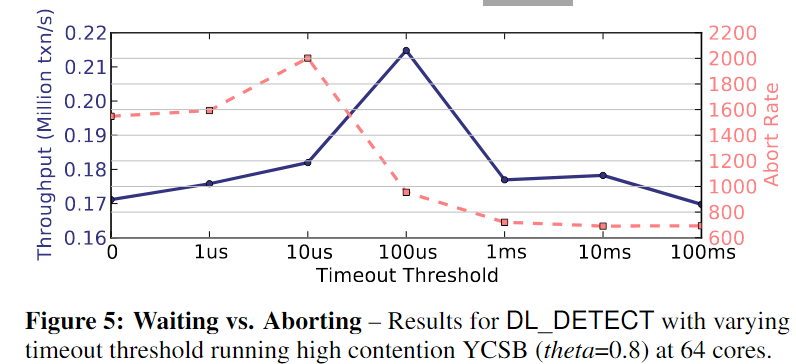
Waiting vs. Aborting
通过在某些时间点终止事务来减少活动事务数,来解决DL_DETECTION抖动问题,设置一个超时阈值timeout threshold,重启等待锁时间超过阈值的事务,如果threshold =0 ,就是No-Wait,在64核CPU上使用不同的超时阈值运行具有高争用的相同YCSB工作负载。我们测量了DL_DETECTscheme在0-100 ms之间扫描超时的DBMS中的吞吐量和中断率,如果超时时间较短,则中止率较高,从而减少了正在运行的事务数量并缓解了抖动问题。使用更长的超时可以降低中止率,但代价是更多的抖动。在本文中,我们将超时阈值设置为100μs来评估dl_detect。
4.3 Scalable Timestamp Ordering
-
Timestamp Allocation
根据分配的时间戳对事务进行排序决策,保证时间戳unique,navie的方法是对allocator的临界区加mutex锁,但是verybad 性能。另一个方法是使用atomic addition operation来推进全局逻辑时间戳,需要的指令更少因此比mutex锁临界区的时间更短。对千核cpu来说还是不够的,讨论三种timestamp allocation方案,(1) atomic addition with batching 带批处理的原子加法, (2) CPU clocks, and (3) hardware counters.
批处理的原子加法:DBMS使用相同的原子指令来分配时间戳,但是时间戳管理器为每个请求批量返回多个时间戳。
clock-based allocation:每个工作线程从其本地核心读取逻辑时钟,然后将其与其线程id连接起来。只要所有时钟都是同步的,这就提供了良好的可伸缩性。在分布式系统中,同步是通过软件协议或外部时钟来完成的。然而,在多核CPU上,这会带来很大的开销,因此需要硬件支持。截至2014年7月,只有英特尔cpu支持跨核同步时钟。
使用高效内置硬件计数器,计数器物理上位于CPU的中心,这样到每个内核的平均距离就最小化了。目前没有现有的CPU支持此操作,本文在Graphite上实现了一个计数器,通过on-chip network来发送时间戳请求,以便在单个周期内自动增加时间戳请求。
为了确定一下每种方法分配时间戳的最大速率,进行了micro-benchmark,基于互斥锁效率最低,再就是原子加法,由于write back和每个timestamp cache line last copy invalid,需要在芯片上进行一次往返通信,对1024core 来说需要100个周期,所以1GHz下最大吞吐量是1000 million Ts/s。Hardware基于硬件的解决方案能够随着核心数量的增加而扩展,由于使用基于硬件计数器的方法增加时间戳只需要一个周期,因此该方法可以实现1 bilion ts/s的最大吞吐量,性能增益来自于通过远程执行加法操作来消除coherence traffic浅谈多核系统的缓存一致性协议与非均一缓存访问 - 知乎 (zhihu.com)基于时钟的方法具有理想的(即线性)扩展,因为这种解决方案是完全分散的。
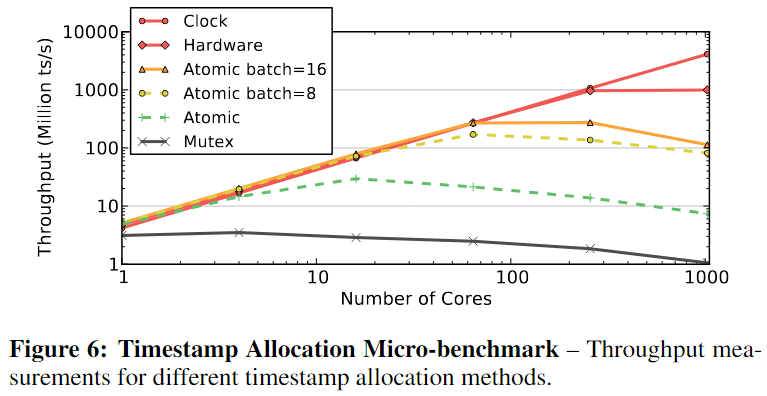
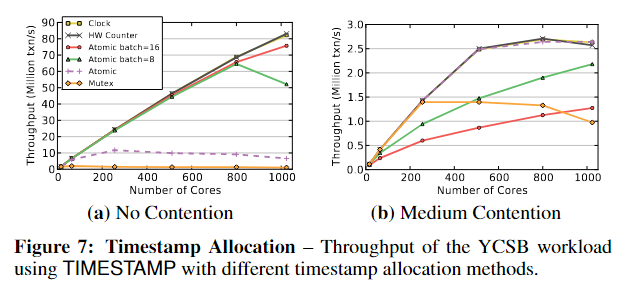
还测试了DBMS中的不同分配方案在实际工作负载下的表现。No Contention情况下结果7.a = 6,首先,DBMS 使用批处理原子加法方法的吞吐量要差得多。这是因为当事务由于冲突而重新启动时,它会在同一个工作线程中重新启动,并在最后一批中分配下一个时间戳。但是这个新的时间戳也将小于导致中止的其他事务的时间戳,因此它将不断重新启动,直到线程获取新批次。非批处理的atomic addition和clock、硬件计数器方法表现得一样好, 本文使用atomic addition without batching来分配时间戳,因为其他的方式需要特定的硬件支持,并不一定适用于所有cpus
-
Distributed Validation
原始的OCC存在一个critical section来比较当前事务的读集和之前事务的写集是否有冲突,虽然很短,但是任何mutex-protected 临界区都会损害可扩展性。using per-tuple validation,类似于HekatonHigh-performance concurrency control mechanisms for main-memory databases
-
Local Partitions
优化了原始的 H-SORE 协议以利用共享内存:我们允许多分区事务直接访问远程分区上的元组,而不是发送由远程分区的工作线程执行的查询请求。这样可以实现比使用进程内通信更快的更简单的实现。使用这种方法,数据不需要进行物理分区,因为片上通信延迟很低。所有线程都可以访问只读表,而不需要进行复制,从而减少了内存占用。使用上述相同的时间戳分配优化来避免强制等待时间
5 EXPERIMENTAL ANALYSIS
两组实验(1) scalability:固定workload参数,增加core 到1024看性能。(2) sensitivity evaluations.改变单个工作负载参数(例如,事务访问倾斜)。 即可扩展性和灵敏度测试。
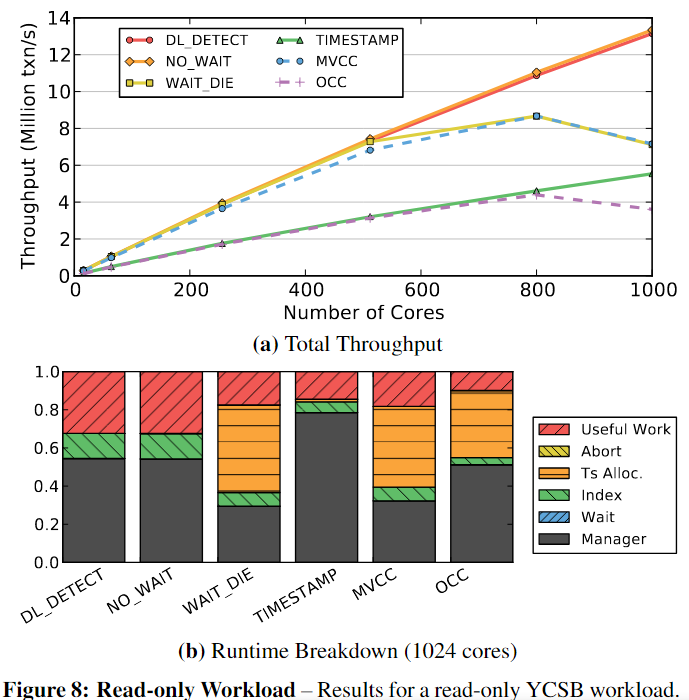
5.1 Read-Only Workload
在一个完全可扩展的DBMS中,吞吐量应该随着核心数量的增加而线性增加,但是T/O时间戳分配变成瓶颈,OCC遇到瓶颈的时间更早,因为它需要为每个事务分配两次时间戳(即,在事务开始时和验证阶段之前)。无论内核数量多少,OCC和TIMESTAMP的性能都明显比其他算法差。这些算法浪费循环,因为它们复制元组来执行读操作,而其他算法则直接读取元组。
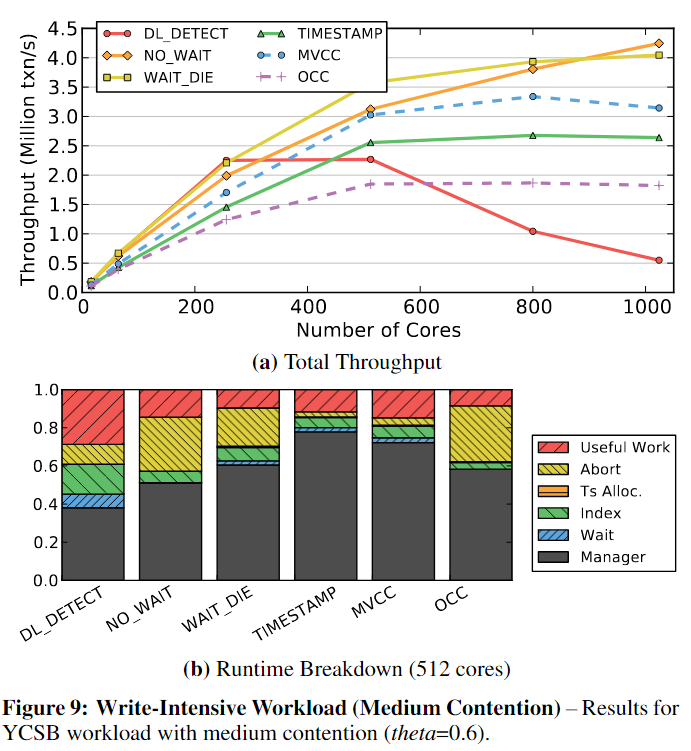
5.2 Write-Intensive Workload
写密集型负载,中等程度竞争结果如下:
- no_wait和WAIT_DIE是唯一可以扩展到512核以上的2PL方案。NO_WAIT优于WAIT_DIE。
- NO_WAIT是最具可伸缩性的,消除了等待
- no_wait和WAIT_DIE都有很高的事务中止率,但是重新启动一个中止的事务的开销很低。undo事务所需的时间略少于重新执行事务查询所需的时间,但是如果undo涉及到多个表、索引和物化视图的改变,实际代价更高。
在更高争用场景下
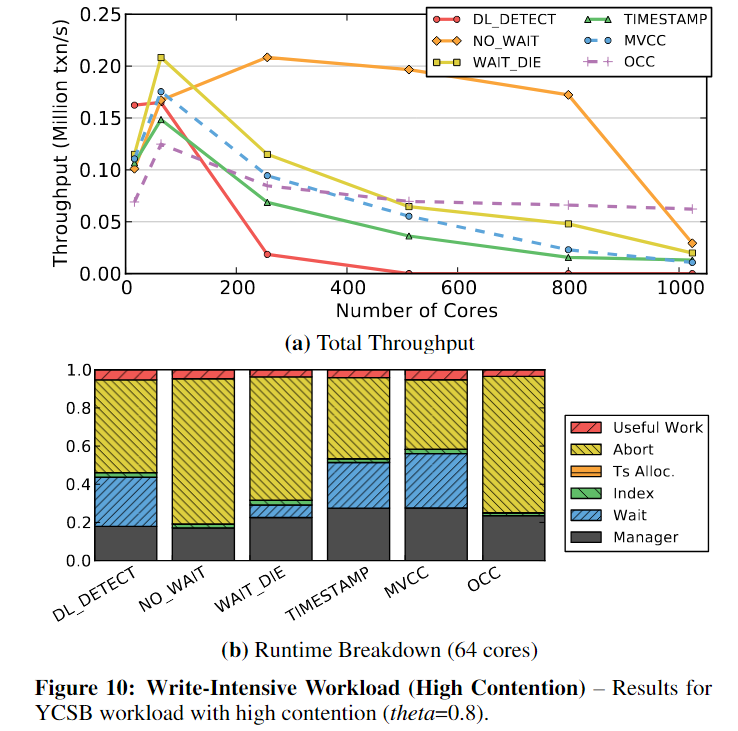
- 几乎所有算法都无法扩展到64 core+
- NO_WAIT最初的性能优于所有其他,但随后屈服于锁抖动
- OCC在1024核时性能最好。这是因为尽管在验证阶段有大量事务发生冲突并且必须中止,但总是允许提交一个事务。
为了更好地理解随着争用增加,每种方案何时开始出现问题,我们将内核数量固定为64,并对倾斜参数(theta)进行敏感性分析。
- 当theta值小于0.6时,争用对性能的影响很小。
- 对于更高的设置,吞吐量会突然下降,使得所有算法都无法扩展,并且当值大于0.8时接近于零。
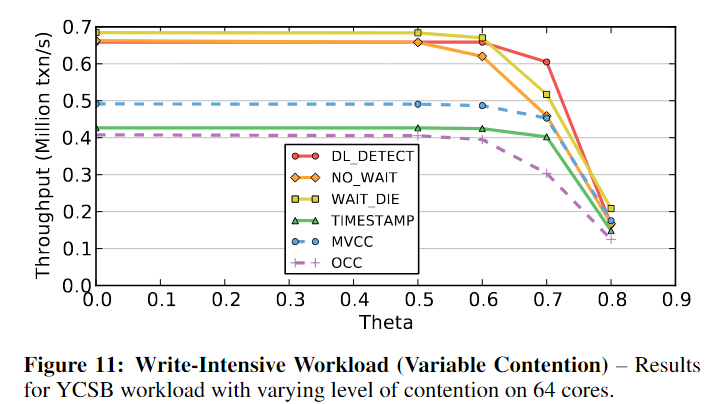
5.3 Working Set Size
事务访问的元组数量是影响可伸缩性的另一个因素。当事务的工作集很大时,并发事务访问相同数据的可能性就会增加。对于2PL算法,这增加了事务持有锁的时间长度。然而,对于T/O,较长的事务可能会减少时间戳分配争用。在写密集型YCSB工作负载中改变每个事务访问的元组数量。因为短事务导致更高的吞吐量,所以我们测量每秒访问元组的数量,而不是完成的事务。我们使用中等倾斜设置(theta=0.6)并将核心计数固定为512。
- 短事务的时候:DL_DETECT和NO_WAIT的性能最好,因为死锁很少,中止的数量也很低。但是,随着事务工作集大小的增加,由于抖动的开销,DL_DETECT的性能会下降。
- 对于T/O算法和WAIT_DIE,当事务较短时吞吐量较低,因为DBMS将大部分时间用于分配时间戳。但是随着事务变长,时间戳分配成本被平摊。
- OCC的性能最差,因为它为每个事务分配的时间戳数量是其他方案的两倍。
- 基于T/O的算法比DL_DETECT更能容忍争用。
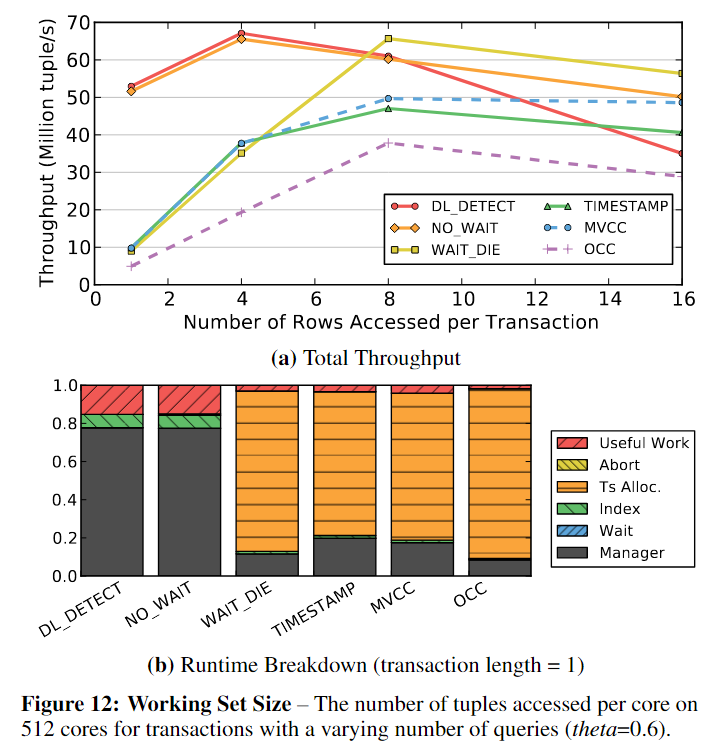
5.4 Read/Write Mixture
在这个实验中,我们在64核配置上使用YCSB,并改变每个事务执行的读查询的百分比。每个事务使用高倾斜设置(theta=0.8)执行16个查询。
- 在100%读取时,TIMESTAMP和OCC表现不佳,因为它们复制元组以供读取。
- 当有少量写事务时,MVCC表现出最好的性能。这也是支持跨多个版本的非阻塞读取最有效的一个例子;读查询根据时间戳访问元组的正确版本,不需要等待写事务。
- 这是与TIMESTAMP的一个关键区别,在TIMESTAMP中,延迟到达的查询被拒绝,它们的事务被中止。
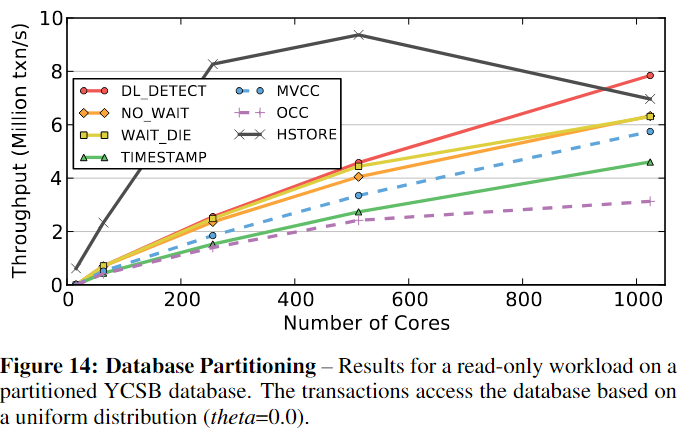
5.5 Database Partitioning
DBMS将数据库划分为不相交的子集以增加可扩展性.通过大多数事务只需要访问单个分区上的数据这样的保证来进行分区,可以提高数据库的性能。
H-STORE的锁是粗粒度的,当工作负载包含多分区事务时,H-STORE不能很好地工作。每个事务访问多少分区也很重要;例如,即使有少量的多分区事务访问所有分区,H-STORE的性能仍然很差。先在理想条件下比较H-store和其他六种方案,然后用多分区事务来测试它的性能。
假设DBMS在运行时开始之前知道将每个事务分配到哪个分区,在第一个实验中,我们执行了一个仅由单分区事务组成的工作负载。图14的结果表明,HSTORE在高达800核的情况下优于所有其他方案。H-Store取决于时间戳的分配和调度,因此在较高核数下性能下降。
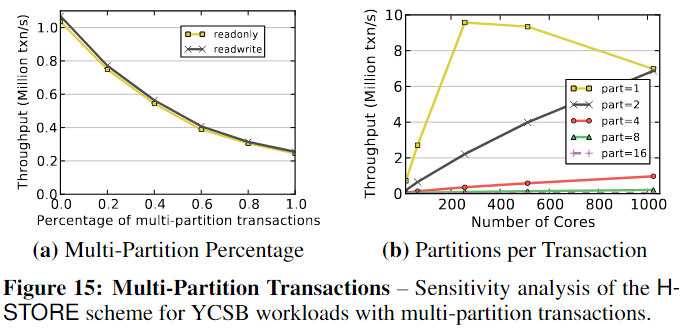
改变工作负载中多分区事务的百分比,将DBMS部署在64核CPU上。图15a中的结果说明了H-STORE方案的两个重要方面。首先,无论工作负载是否包含修改数据库的事务,性能都没有差异;这是因为H-STORE锁的方案。其次,DBMS的吞吐量随着工作负载中多分区事务数量的增加而降低,因为它们减少了系统中的并行性。图15b:由于降低了并行性和增加了跨核心通信,DBMS不能扩展访问四个或更多分区的事务。
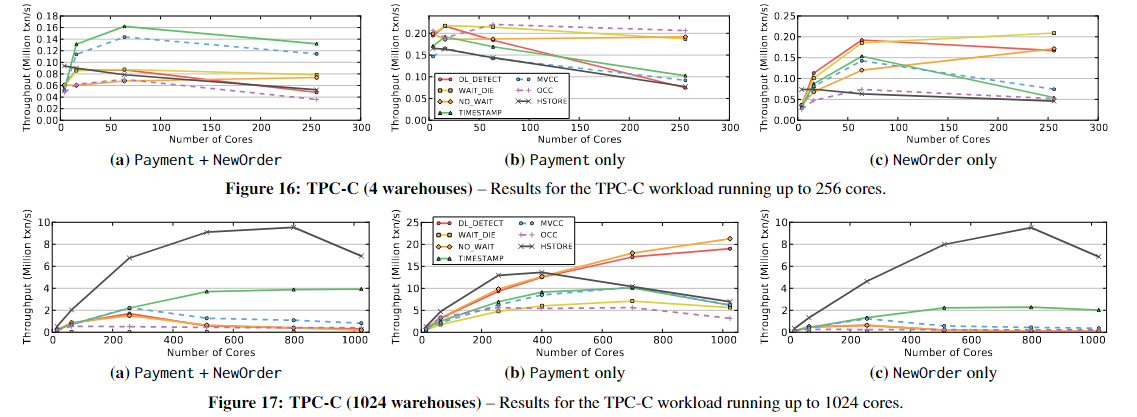
5.6 TPC-C
TPC-C中的事务比YCSB中的事务更复杂,代表了一大类OLTP应用程序。例如,它们以读-修改-写访问模式访问多个表,一些查询的输出用作同一事务中后续查询的输入。TPC-C事务也可能因为程序逻辑中的某些条件而中止,而不是仅仅因为DBMS检测到冲突。
50% Neworder 50% Payment
TPC-C数据库的大小通常由仓库的数量来衡量,遵循TPC-C规范,其中约10%的NewOrder事务和约15%的payment事务访问“远程”仓库。对于基于分区的方案,如H-STORE,每个分区由单个仓库的所有数据组成。这意味着远程仓库事务将访问多个分区。
首先在一个4仓库数据库上执行TPC-C工作负载,每个仓库有100MB数据(总共0.4GB)。这允许我们在工作线程多于仓库时评估算法。然后,我们在1024仓库数据库上再次执行相同的工作负载。由于在Graphite simulator中运行的内存限制,我们将这个数据库的大小减少到每个仓库26MB的数据(总共26GB)。这不会影响我们的测量,因为每个事务访问的元组数量与数据库大小无关。
-
5.6.1 4 Warehouses
当仓库数量少于core数量时,所有方案都难以扩展。使用h - store时,由于它的分区方案,DBMS无法利用额外的核;额外的工作线程基本上是空闲的。
对图16 c:对NewOrder大概能扩展到64核,TIMESTAMP、MVCC和OCC由于高中止率而具有较差的可伸缩性。由于抖动和死锁,DL_DETECT不能扩展。
对图16 b: 扩展很差,因为Payment事务需要更新仓库的一个单独的字段W_YTD,需要1. 加排他锁 或者2.prewrite。如果线程的数量大于仓库的数量,那么更新仓库表就会成为瓶颈。
这两个事务的主要问题是更新WAREHOUSE表时的争用。每个Payment事务更新其相应的仓库条目,每个neworder将读取它。2PL-based算法中这些读和写操作相互阻碍。两种基于T/O的算法,TIMESTAMP和MVCC,优于其他方案,因为它们的写操作不会被读阻塞。这消除了2PL中的锁阻塞问题。因此,NewOrder事务可以与Payment事务并行执行
-
5.6.2 1024 Warehouses
使用1024个仓库,最多1024个内核。No scheme is able to Scale。原因各不相同
对于几乎所有的方案,主要的瓶颈是维护locks and latches的开销,即使没有争用也会发生。
对于2PL模式,每次访问都会在DBMS中创建一个共享锁条目。有大量并发事务时,锁元数据会变得很大,因此需要更长的时间来更新它们。OCC在事务运行时不使用这种锁,但是他在验证阶段使用latches来获取tuple进行控制。虽然MVCC也没有锁,但是每个读请求都会生成一个新的历史记录,这会增加内存流量。同时注意到,所有这些在技术上都是不必要的工作,因为ITEM表从未被修改过。
对图17-b: 当仓库的数量等于或大于工作线程的数量时,Payment事务中的瓶颈被消除了,这几乎提高了所有方案的性能。但是对于T/O方案,在较大的核数下吞吐量会变得太高,因此它们会受到时间戳分配的抑制。因此,它们无法达到高于~ 1000万txn/s的速率。H-STORE总体上表现最好,因为它能够利用分区,即使工作负载中有~ 12%的多分区事务。这证实了先前的研究结果,即当包含多分区事务的工作负载少于20%时,h - store优于其他方法。但是,在1024核时,它受到DBMS的时间戳分配的限制。
6. DISCUSSION
讨论分析前几节的结果,提出避免多核dbms出现这些可伸缩性问题的解决方案。
6.1 DBMS Bottlenecks
评估表明,由于不同的原因和条件,所有七种并发控制方案都无法扩展到大量的内核,确定了可伸缩性的几个瓶颈:(1)锁抖动,(2)抢占式中止,(3)死锁,(4)时间戳分配,以及(5)内存到内存复制。
| DL_DETECT | 低竞争下可扩展,高竞争会遇到lock thrashing | |
|---|---|---|
| 2PL | NO_WAIT | 高度可伸缩,没有中心化的竞争区,但是高中止率 |
| WAIT_DIE | 会遇到lock thrashing 以及 时间戳分配的瓶颈 | |
| TIMESTAMP | 本地复制数据带来的高开销,非阻塞写,但是会遭受时间戳瓶颈。 | |
| T/O | MVCC | 在读写密集型工作负载下性能良好。非阻塞读写。遭受时间戳瓶颈。 |
| OCC | 本地复制数据的开销很高。中止成本高。遭受时间戳瓶颈。 | |
| H-STORE | 分区工作负载的最佳算法。会遇到多分区的事务和时间戳的瓶颈的问题。 |
- 抖动会发生在任何基于等待的算法中,如第4.2节所讨论的,通过主动中止来减轻抖动。这导致中止和性能之间的权衡。一般来说,对于高争用工作负载,非等待死锁预防方案(NO_WAIT)比死锁检测(DL_DETECT)执行得好得多。
- 虽然没有一种并发控制方案适用于所有场景,但是在不同场景下都能找到一个效果不错的方案。因此,可以将两个或多个算法类组合到一个DBMS中,并根据工作负载在它们之间进行切换。例如,DBMS可以对竞争较少的工作负载使用dl_detect,但当事务由于抖动而花费太长时间才能完成时,则切换到NO_WAIT或基于T/的算法。还可以采用混合方法,例如MySQL的DL_DETECT + MVCC方案,其中只读事务使用多版本控制,而所有其他事务使用2PL。
- 需要新硬件来克服这些瓶颈。当吞吐量很高时,所有的T/O方案都会遇到时间戳分配瓶颈,因为当内核数量很大时,使用原子加法方法会导致工作线程在芯片上发送许多消息来修改时间戳。
- 内存问题:缓解这个问题的一种方法是在CPU上添加硬件加速器,以便在后台进行内存复制。这将消除通过CPU的管道加载所有数据的需要。本文认为,未来的cpu将需要切换到分散或分层内存控制器,以提供更快的内存分配。
6.2 Multi-core vs. Multi-node Systems
多节点,也就是分布式,存在一个瓶颈:分布式事务,因为网络上节点之间的通信很慢,这种协议的协调开销抑制了分布式dbms的可伸缩性。相比之下,共享内存环境中线程之间的通信要快得多。这意味着除了最大的OLTP应用程序外,单个具有大量DRAM的多核节点可能在所有应用程序中都优于分布式DBMS。
还有一种可能的架构,shared-nothing 在多个节点之间,然后单个芯片内多线程共享内存。高性能,需要分层并发控制。
7. RELATED WORK
| Performance of an OLTP application on Symmetry multiprocessor system | 多处理器系统,如何将进程分配给处理器以避免带宽瓶颈 |
|---|---|
| 在多核cpu上设计更具可扩展性的独立锁管理器 | |
| Shore- mt | 是Shore的多线程版本,它采用了类似于DL_DETECT的死锁检测方案。Shore-MT的许多改进来自于优化系统中的瓶颈,而不是并发控制,如日志记录。在高争用工作负载上,系统仍然遭受与DL_DETECT相同的抖动瓶颈。 |
| DORA | 与传统DBMS体系结构中将事务分配给线程不同,DORA将线程分配给分区。当事务需要访问特定分区上的数据时,将其句柄发送给该分区的相应线程,然后在队列中等待轮到它。这类似于H-STORE的分区模型,只不过DORA支持每个分区多个记录级锁(而不是每个分区一个锁)。我们研究了在DBMS中实现DORA,但发现它不容易调整,需要单独的系统实现。 |
| Silo | 全局临界段是OCC的主要瓶颈。为了克服这个问题,他们使用了基于批处理原子添加时间戳的去中心化验证阶段。但是正如我们在4.3节中所展示的,当部署在大量核心上时,DBMS必须使用大批量来分摊集中分配的成本。这种批处理反过来又增加了系统在争用下的延迟。 |
| Hekaton | 是Microsoft SQL Server的主存表扩展,它使用无锁数据结构的MVCC变体。管理员将某些表指定为内存表,然后与常规的磁盘驻留表一起访问这些表。Hekaton的主要限制是时间戳分配与本文评估的其他基于T/O based算法一样受到瓶颈的影响 |
| VLL集中式锁管理器 | 使用每个元组2PL来消除争用瓶颈。它是dl_detect的优化版本,当争用较低时,它所需的存储和计算开销比我们的实现要小得多。VLL通过将数据库划分为不相交的子集来实现这一点。像H-STORE,这种技术只适用在工作负载分区。在内部,每个分区仍然有一个临界区,这将限制高争用工作负载下的可伸缩性。 |
| A scalable lock manager for multicores | 将latches争用作为Mysql主要的扩展瓶颈,通过将读后写的原子同步模式替换为写后读的模式来消除这种争用,还建议批量预分配和释放锁,以提高可伸缩性。但是,该系统仍然基于集中式死锁检测,因此当数据库中存在争用时,性能会很差。还需要global barriers 所以在更高核情况下不太可以。 |
| Bionic Database | 研究了使用软硬件协同设计方法来提高DBMS的性能。侧重于在fpga中实现OLTP DBMS操作,而不是直接在CPU上使用新硬件。 |
8. FUTURE WORK
本文主要是揭示了并发控制算法的瓶颈,这些瓶颈会随着内核数量的增加而限制它们的可伸缩性。是算法固有的瓶颈,无法尽在软件算法层面克服,需要软硬件协同、新硬件。并发控制只是DBMS影响可伸缩性的几个方面之一。要构建一个真正可伸缩的DBMS,还需要研究其他组件。计划研究日志记录和索引实现,然后分析针对这些组件的可能的优化。还将扩展我们的工作,包括具有多个多核CPU的多套接字系统multisocket systems with more than one many-core CPU。
10. CONCLUSION
pluggable architecture支持七种并发控制方案。发现基于2pl的方案擅长处理在key-value工作负载中常见的具有低争用的短事务。而基于T/ o的算法则擅长处理在复杂OLTP工作负载中更常见的较长事务的较高争用。