
论文链接:https://arxiv.org/pdf/2407.16655
项目主页:https://aim-uofa.github.io/MovieDreamer/
github链接:https://github.com/aim-uofa/MovieDreamer
亮点直击
MovieDreamer,一个新颖的分层框架,将自回归模型与扩散渲染结合起来,平衡长时间叙事连贯性与短时间视觉保真度。该方法大幅延长了生成视频内容的时长,达到数千个关键帧。
使用多模态自回归模型生成视觉token序列。自回归模型支持zero-shot和few-shot的个性化生成场景,并支持可变长度的关键帧预测。
使用了一种新颖的多模态脚本,对场景和角色身份进行分层结构化丰富描述。这种方法不仅促进了视频不同片段之间的叙事连贯性,还增强了角色控制和身份保持能力。
方法展示了卓越的生成质量,具有详细的视觉连续性、高保真度的视觉细节以及角色身份保持能力。

最近的视频生成技术进展主要利用扩散模型来生成短时内容。然而,这些方法在处理复杂叙事和保持角色一致性方面常常不足,而这些对于电影等长篇视频制作至关重要。本文提出了MovieDreamer,一个新颖的分层框架,将自回归模型的优势与基于扩散的渲染相结合,开创了具有复杂情节进展和高视觉保真度的长时视频生成。本文的方法利用自回归模型来保持整体叙事连贯性,预测视觉token序列,然后通过扩散渲染将其转换为高质量的视频帧。这种方法类似于传统的电影制作过程,将复杂的故事分解为可管理的场景拍摄。
此外,本文采用多模态脚本,丰富了场景描述,提供详细的角色信息和视觉风格,增强了场景间的连续性和角色身份一致性。本文在各种电影类型中进行了广泛的实验,证明本文的方法不仅在视觉和叙事质量上取得了优异的成绩,而且有效地将生成内容的时长显著延长,超越了当前的能力。
方法
概览
本文提出了一种新颖的框架,用于生成扩展的视频序列,该框架利用自回归模型在长期时间一致性方面的优势和扩散模型在高质量图像渲染方面的优势。本文的方法以多模态脚本作为条件,以自回归方式预测关键帧tokens,并使用这些帧作为anchor生成完整的视频。本文的方法提供了灵活性,支持zero-shot生成以及需要遵循给定风格的few-shot场景。本文特别注意在多模态脚本设计、自回归训练和扩散渲染过程中保持角色身份的一致性。下图2中展示了整体框架。
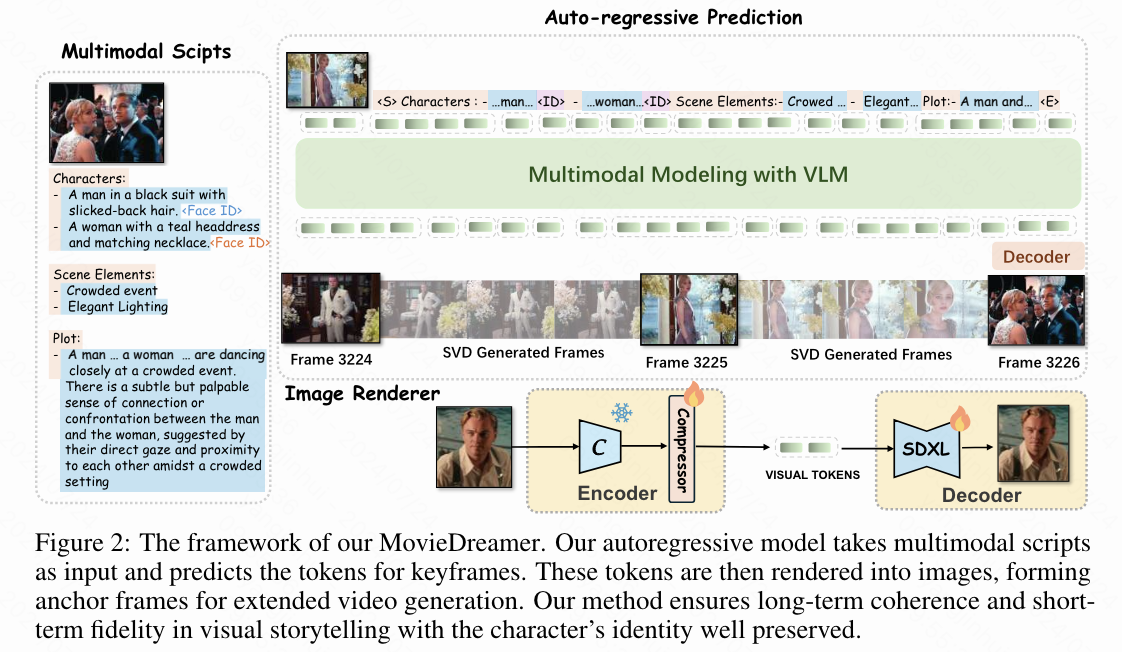
通过扩散自编码器进行关键帧tokens
为了创建简洁且忠实于图像的表示,本文采用扩散自编码器。本文的编码器 包含一个预训练的 CLIP 视觉模型和一个基于transformer的tokens压缩器,它将图像 编码为数量减少的压缩tokens,记为。解码器使用这些tokens重建图像,采用预训练的 SDXL 扩散模型,生成 的重建图像。提取的潜在图像tokens通过交叉注意力被输入到扩散解码器中。本文在训练压缩器和解码器的同时,保持CLIP视觉模型冻结。训练这个扩散自编码器的损失函数如下:
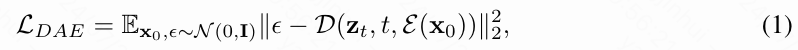
其中, 是输入图像, 是其在时间步 对应的噪声潜在表示,即 其中 , 和 定义了一个噪声调度。在本文的实验中,作者经验性地发现,仅仅两个tokens就能充分描述关键帧的主要语义,这一发现与之前的工作[42]一致。
自回归关键帧tokens生成
本文使用预训练的大型语言模型 LLaMA2-7B初始化本文的自回归模型。与大型语言模型(LLMs)不同,本文的模型 根据输入的多模态脚本 和历史信息 预测压缩的视觉tokens,其公式如下:
本文的方法首先利用预训练的大型语言模型,特别是 LLaMA2-7B,来构建本文的自回归模型 G。与传统的 LLM 不同,G 旨在从多模态脚本 和历史数据 中预测压缩的视觉tokens。模型函数定义为
传统的 LLM 通常使用交叉熵损失进行训练,这适用于离散输出。然而,本文的模型处理的是连续实值图像tokens,使得交叉熵不适用。
受 GIVT的启发,本文采用 k-混合高斯混合模型(GMM)来有效地建模这些实值tokens的分布。这涉及用 2kd 个均值、2kd 个方差和 k 个混合系数来参数化 GMM。
这些参数是通过自回归模型的一个修改后的线性输出层获得的,从而能够从 GMM 中采样连续tokens。模型通过最小化负对数似然进行训练:

其中 代表总帧数, 表示当前帧, 是每帧的压缩tokens数量。为了简化这些连续tokens的学习,本文还结合了预测tokens和真实tokens之间的 和 损失,并优化以下目标:
![]()
为了解决自回归模型在长视频关键帧生成中的过拟合问题,本文实施了几种关键策略:
-
数据增强:为了最大限度地利用本文的训练数据,本文应用了随机水平翻转和随机反转视频帧的时间顺序。这种训练数据增强大大增加了训练数据的多样性。
-
面部embedding随机化:为了防止身份泄露,本文随机检索同一角色在不同帧中的面部embedding。否则,模型会简单地通过面部embedding输入记住训练帧。
-
激进的Dropout:本文使用了异常高的50%的Dropout率,这对于从有限的训练数据中进行广泛学习至关重要。
-
tokens mask:本文以0.15的概率随机mask输入tokens,这适用于因果注意力mask。这迫使模型根据可用的上下文(如面部ID)推断缺失的信息,进一步增强了其从部分数据中进行泛化的能力。
自回归条件下的多模态脚本。本文开发了一种结构良好的多模态脚本格式,作为自回归模型的输入,如下图14所示。本文的脚本整合了多个维度:角色、场景元素和叙述弧线。仅使用文本来准确表示角色外貌是具有挑战性的;因此,本文将文本描述与面部embedding结合起来,以提供每个角色的更详细表示。为了便于自回归模型的处理,本文将脚本格式结构化,以明确区分这些元素。
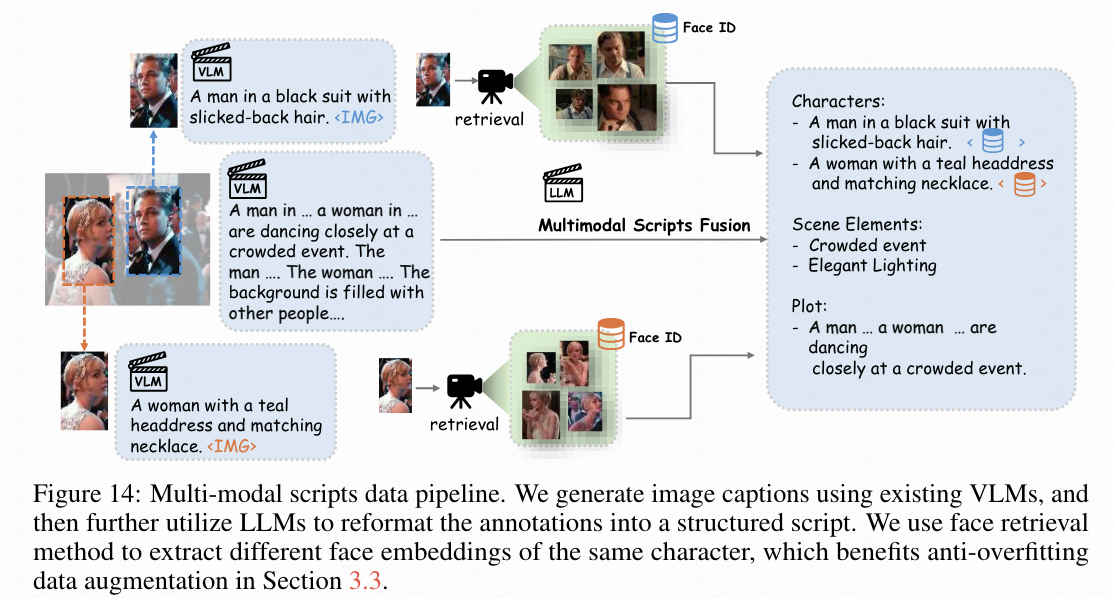
对于非文本模态(如面部embedding和压缩tokens),本文使用多层感知器将其投射到LLaMA的embedding空间中。主要的挑战在于文本数据,它往往会产生长序列,从而消耗过多的tokens空间并限制模型的上下文广度。为了解决这个问题,本文将文本视为一种单独的模态,将其分为“标识符”和“描述”(见上图2)。标识符是简洁的陈述,用于建立脚本的结构。相比之下,描述则详细说明了生成的属性,每个描述都使用CLIP编码为一个单独的[CLS]tokens,然后投射到统一的输入空间中。
这种方法通过将整个句子压缩成单个tokens,显著延长了训练期间可用的上下文长度。本文使用LongCLIP作为描述的文本编码器,支持最多248个tokens的输入,这增强了本文处理详细叙述内容的能力。因此,时间步的多模态脚本及其之前的历史数据表示为:

其中,、 和 分别表示描述、标识符和角色面部embedding的embedding。 表示之前预测的压缩帧tokens。负对数似然损失公式如下:
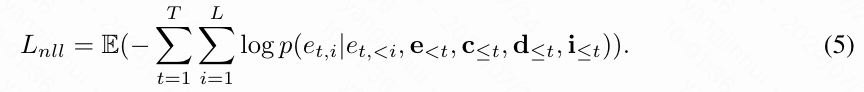
个性化生成的few-shot训练。 为了促进个性化电影内容生成,本文提出了一种利用上下文学习的few-shot学习方法。在训练过程中,本文从一集中随机选择10个帧,将它们编码为视觉tokens,并随机将这些tokens添加到该集的视觉tokens之前。这一策略不仅促进了上下文学习,使模型能够根据参考帧定制内容,还作为一种数据增强技术,有效减轻了过拟合问题。
本文的模型具有多功能性,支持zero-shot和few-shot生成模式。在zero-shot模式下,模型仅根据文本提示生成内容。在few-shot模式下,模型利用一小组用户提供的参考图像,使生成的内容更符合用户的偏好,而无需进一步训练。这一功能确保用户能够高效地生成高质量、定制化的视觉内容,符合他们期望的主题和风格。
保留 ID 的扩散渲染
在本文的方法中,虽然主要的扩散解码器能够熟练地重建目标图像,但有时在捕捉细节方面,特别是面部特征上,会有所欠缺。这是由于压缩后的token中细节的衰减。为了解决这个问题,本文增强了中的交叉注意力模块。这种增强涉及到整合来自多模态脚本的描述性文本embedding 和面部embedding 。
为了进一步提升模型对关键细节的关注能力,本文引入了一种随机mask策略,该策略会遮蔽一部分输入token。这种技术鼓励解码器更有效地利用现有的面部和文本线索,以更高的保真度重建图像,特别是在保持身份特征方面。这种身份保留渲染也弥补了在自回归建模过程中身份丢失的问题,如下图3所示,显著提高了身份感知质量。


基于关键帧的视频生成
在获得电影中的关键帧后,本文可以基于这些关键帧生成电影片段。一种直接的方法是利用现有的图像到视频模型,例如Stable Video Diffusion (SVD),来生成这些片段。具体来说,SVD将输入图像转化为用于条件的潜在特征,并通过交叉注意力引入与输入图像的CLIP特征的交互。虽然SVD能够生成高质量的短视频,例如25帧,但在生成更长的电影片段时会遇到困难。
为了生成更长的电影片段,一种直接的方法是利用前一个视频的最后一帧作为生成后续视频的初始帧。这个过程可以迭代进行,以获得较长的视频序列。然而,本文通过实验证明,这会导致严重的错误积累:随着时间的推移,视频帧的质量会逐渐恶化。
为了解决这个问题,本文提出了一种简单而有效的解决方案。本文的动机是始终使用第一帧的特征作为视频扩展过程中的“锚”,以增强模型对原始图像分布的感知。在实际操作中,本文在生成后续视频时,使用原始输入图像的CLIP特征,而不是前一个视频的最后一帧进行交叉注意力交互。
实验
与最先进的模型比较
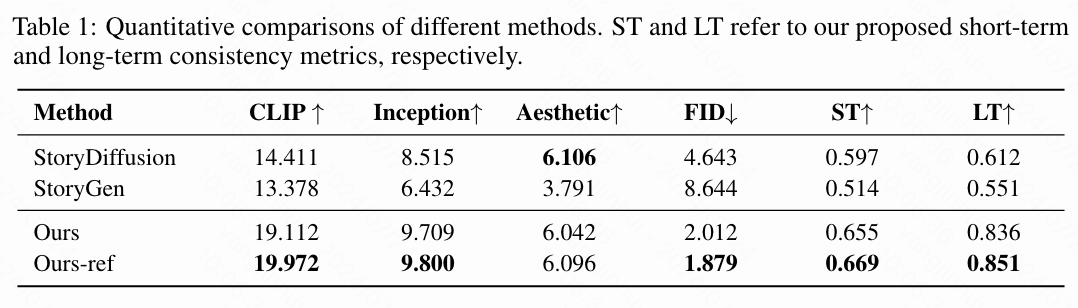
故事生成。 许多现有的故事生成方法专注于使用小数据集进行微调,表现出较差的泛化能力。因此,本文仅与那些展示出高泛化能力的方法进行比较,即StoryDiffusion和 StoryGen。如下图4所示,StoryDiffusion无法保持长期一致性。例如,角色的头发不一致,关键帧77中的角色与关键帧968中的角色不一致。类似地,StoryGen也未能保持一致性并生成了异常结果。相比之下,本文的方法在生成极长内容的同时,能够在多个角色之间保持短期和长期的一致性。这个观察也通过下表1中的定量结果得到了证实,本文的方法在LT和ST指标上均取得了高分。此外,更高的CLIP得分反映了本文生成的结果与故事情节很好地契合。更好的IS、AS和FID得分表明本文的方法生成了高质量的图像。



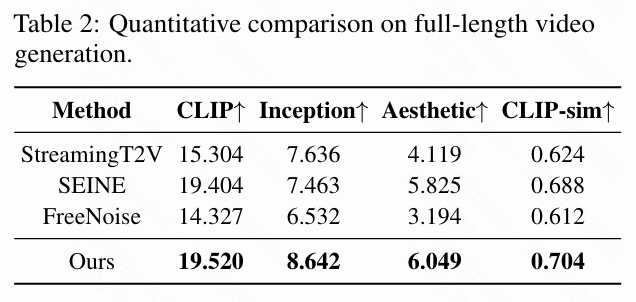
视频结果。 本文对生成长视频的方法进行了详细比较。对于文本到视频的方法,本文使用测试集中准备的详细描述作为输入。对于图像到视频的方法,本文采用由本文的方法生成的关键帧作为输入。如下表2所示,本文的方法在质量方面显著优于现有的开源模型,展示了强大的泛化能力。最重要的是,本文的方法能够生成持续数小时的视频,且质量几乎没有妥协,达到了最先进的水平。
分析
反过拟合策略。 大型自回归模型是强大的学习器,这使得它们很容易对数据集过拟合。如下图6的第一行所示,生成的内容主要由输入字符主导。即使给出不同的文本提示,模型也会生成相似的视觉内容。本文的反过拟合策略旨在削弱字符ID与目标帧之间的对应关系,从而避免简单的记忆。如第二行所示,这有助于生成与文本描述高度一致的多样化高质量结果。

多模态电影脚本。 多模态脚本引入了面部embedding,以更好地保持一致性。下图5有力地展示了这种设计的有效性。具体来说,移除面部embedding会导致模型保持角色一致性的能力下降。面部embedding携带了比单纯文本更细致和精确的信息。使用面部embedding后,短期和长期的一致性都得到了很好的保持。

ID保持渲染。 在启用ID保持渲染之前,本文的解码器已经显示出重建目标图像的能力。然而,对于训练集外的图像,由于压缩token中细微面部特征的丢失,重建的角色外观可能与预期目标略有不同。应用ID保持渲染后,本文的解码器在保持角色身份方面表现出显著增强的能力。实验结果如上图3所示,清楚地展示了后处理步骤的有效性。
few-shot个性化生成。 本文的方法作为一个强大的上下文学习者,能够根据用户提供的少量参考生成与风格或角色一致的结果。结果展示在下图7中。本文的模型在few-shot场景下能够生成与参考风格和角色更一致的结果。




结论
本文提出了MovieDreamer,以应对生成具有复杂叙事的长时间视觉内容的挑战。该方法巧妙地结合了自回归和扩散的优势,能够生成长视频。此外,本文设计了多模态脚本,旨在保持生成序列中角色的一致性。本文进一步引入了身份保持渲染,以更好地保持角色身份,并通过上下文建模支持few-shot电影创作。这项工作有望为自动化长时间视频制作的未来发展开辟令人兴奋的可能性。
参考文献
[1] MovieDreamer: Hierarchical Generation for Coherent Long Visual Sequences













![【Python】pandas:查看数据(head, tail, values属性, at, iat, loc, iloc, [ ], sample)](https://i-blog.csdnimg.cn/direct/f685ca51b3fa43cdbf7cb0d3a6eaea69.png)





![[Unity] ShaderGraph实现不同贴图素材的同一材质球复用](https://i-blog.csdnimg.cn/direct/6b32e18f3d8f463084aef4dd4002440b.png)