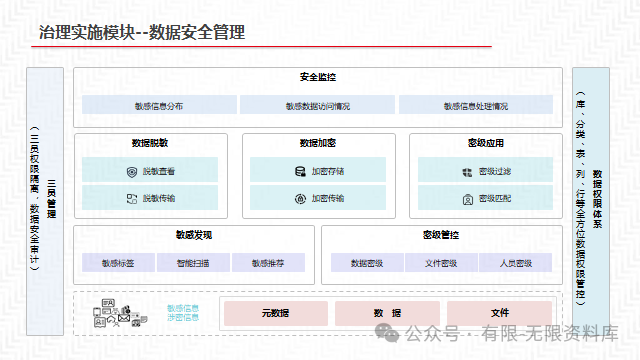
这里写目录标题
- 文本嵌入方案总结
- 一、文本嵌入三种层次
- 词向量应用:
- 句向量应用:
- 扩展:文本嵌入和句子相似度、文本匹配的逻辑关系?
- 二、词向量有哪些方案、优缺点、工具?
- 方案一:统计编码
- 方案二:静态词向量
- 方案三:开源词向量
- 方案四:动态词向量
- 三、句向量有哪些方案、优缺点、工具?
- 方案一:基于词典和词频进行统计
- 方案二:word2vec类静态词向量取平均
- 方案三:使用原生的bert生成句向量
- 取CLS向量:
- token向量取平均:
- 方案四:微调bert模型使其具备句向量生成能力
- Sentence-Bert(2019.8)
- Bert-Flow(2020.11)
- Bert-whitening(2021.3)
- SimCSE(2021.9)
- PromptBert
- 方案五: 大模型时代的通用嵌入模型
- 四、总结:方案如何选取?
文本嵌入方案总结
2024.11.13阶段性总结
一、文本嵌入三种层次
文本嵌入包括词嵌入(词向量)、句嵌入(句向量)、**篇章嵌入(篇章向量)**三种层次。
词向量应用:
近似词、不同类的词、词距离、计算句嵌入、降维可视化
句向量应用:
检索、排序、句子相似度、推理、分类、聚类、平均等。
扩展:文本嵌入和句子相似度、文本匹配的逻辑关系?
- 基于文本嵌入可以完成许多下游任务,句子相似度只是其中一个;
- 句子相似度,可以使用计算字符串相似度或者语义相似度,其中句子的语义相似度可以使用专门的句子相似度模型(如SimCSE、sentence-bert),也可以使用通用的嵌入模型(如m3e-base)得到句子嵌入再计算余弦相似度;
- 文本匹配通常指语义匹配,核心就是计算句子相似度。
总结就是:基于文本嵌入可以用于计算句子的语义相似度,基于句子相似度可以完成文本匹配或检索
二、词向量有哪些方案、优缺点、工具?
方案一:统计编码
典型方式为onehot编码、TF编码
- 优点:最原始简单的表示方式,首次将文本转换为数值后,计算机才能理解和处理;
- 缺点:假设词与词之间相互独立、没有考虑共现关系;2)向量长度和词典长度一样大,维度灾难
- 工具:
sklearn
方案二:静态词向量
典型模型为word2vec、Glove、FastText,这三个中Glove经常作为Bert类的基准模型进行比较。
- 优点:训练速度非常快
- 缺点:无法处理一词多义问题;
- 工具:
gensim:包含word2vec、fasttext(词向量)、LDA、LSA、TF-IDF、paragraph2vec等算法;
FastText:Facebook发布的工具;
Glove库
方案三:开源词向量
方案一需要用自己的数据训练才能得到词向量,若是不想训练,则可以使用别人以训练完成的词向量,典型的有腾讯AI lab的Tencent_AIlab_ChineseEmbedding(6.3G),其基于Skip-Gram 模式进行训练。
- 优点:大厂用于训练的数据量更多,得到的词向量更准确,词条也较为丰富;
- 缺点:可能存在着开源的词条无法完全覆盖你的应用场景中所需词条的情况;同时它也是静态词向量,因此也无法处理一词多义的问题。
参考:https://zhuanlan.zhihu.com/p/47518633

方案四:动态词向量
典型模型为Bert/Roberta系列,直接获取编码后对应token的向量作为字向量/词向量。

- 优点:每个词的语义都和其上下文所关联,因此其是动态生成的词向量,如“苹果公司股价再创新高”和“我早饭吃了一个苹果”,这两句话中都出现了“苹果”,如果通过静态词向量方式则得到完全相同的向量;通过bert则得到不同的向量,即bert可以解决一词多义问题;
- 缺点:计算成本更高,更耗时。
- 工具:
模型下载地址:Modelscope或Huggingface(国内不可用)
三、句向量有哪些方案、优缺点、工具?
首先,什么是一个好的句向量?
一个好的句向量应准确表征句子的信息,不同句子之间的相似度就可以用对应句向量的距离来表示。
方案一:基于词典和词频进行统计
典型的模型为词袋模型、TF-IDF编码
- 缺点:完全忽略了句子语序关系,eg:“我打了你”和“你打了我”完全等价;
- 工具:
Gensim
方案二:word2vec类静态词向量取平均
这里包括直接平均和加权平均两种方式,简单不赘述。
方案三:使用原生的bert生成句向量
(方案三和四参考:https://zhuanlan.zhihu.com/p/444346578)
原生的这类是在不改变原始bert模型的基础上,提出各种思路提取出bert的句向量,输入是一句话,如下,CLS和SEP是bert的辅助标记:

原生的bert如何获得一句话的向量表示?有这样几种表征方式:
取CLS向量:
取CLS位置的向量,视为包含了整句话的信息,作为句向量。
token向量取平均:
这里具体又包括2种方式:1)全部token向量取平均;2)去CLS和SEP的向量平均。但因为上面相同的问题原因,效果也并不好。
-
优点:方法简单,github上一行代码使用bert生成句向量就是这类方法。

-
缺点:
这两类方法在实际用于句子相似度等任务时效果非常差,甚至比Glove向量平均差远了。造成这种现象的原因主要是:原生的Bert预训练的任务只有MLM跟NSP(next sentence prediction),在下游任务计算句子相似度时,也是把两个句子通过[CLS]拼接到一起输入Bert,将Bert输出的结果传入一个全连接层计算相应概率值做一个二分类任务,所以原生的Bert一开始就没有考虑到怎么去生成一个适合向量搜索或者相似度计算的句向量。

因此,原始Bert生成的的词向量在空间分布不均匀,受频率影响,高频词相对集中,更靠近远点,低频词由于训练不够充分相对分散,远离原点。所以词向量之间的距离不能很好的表示词之间的相关性。所以句向量也收到影响。
因此,在实际使用中,几乎不会使用原生的bert来生成句向量。
方案四:微调bert模型使其具备句向量生成能力
Sentence-Bert(2019.8)
在原始的bert训练任务中添加句子相似度计算任务进行微调,使Bert具备生成高质量句向量的能力,质量是基于句子相似度任务而言的。
- 效果:明显优于原生Bert和其他向量表征方法。其验证池化措施选择的是向量平均值,效果最好。

Bert-Flow(2020.11)
在Bert的基础上增加一个flow可逆变换,实现将一个标准的高斯分布转化成一个Bert的句向量embedding分布,那么它的逆变化就可以将一个Bert的句向量embedding分布转化成一个标准高斯分布了。推理过程就是在将Bert的句向量输出到这个训练好的可逆变换flow做转换,就可以得到分布均匀的句向量。
- 效果:作为一种无监督训练的方法,效果明显优于原生的bert和glove。

Bert-whitening(2021.3)
Bert-whitening跟Bert-flow一样也是想直接对Bert生成的句向量做转换,但是Bert-whiltening更加简单明了,直接对语料数据求特征值分解,将当前坐标系变换到标准正交基下,进而实现句向量空间的各向同性。
- 效果:Bert-whitening在效果上可以媲美Bert-flow。

SimCSE(2021.9)
引入对比学习的方式用于相似文本任务训练,它希望表征相同语义的句向量之间的距离足够靠近,表征不同语义的句向量距离尽可能疏远。是一个破圈之作。
- 效果:无论是无监督还是有监督,在多个数据集上效果优于之前的方法,且有较大的提升。

PromptBert
之前涉及到的方法的句向量要不是[CLS]位置的输出向量,要不就是所有位置的输出向量的平均值,但是PromptBert方法使用的句向量却设置prompt模版得到的。PromptBert通过预先定义好的模版将文本填入[X]的位置然后输入到Bert,得到对应[MASK]位置的输出向量作为句向量。第二点是句子相似度计算过程加入了消除有关prompt模版影响的部分。
-
效果:效果明显优于其他方法包括simcse。prompt模版的选择对于最终效果的影响很大。

-
优点:上述方法都没有修改Bert原始结构,而是引入句子相似对任务对bert做了相应的训练任务。换言之,Bert其实功能还是很强大,并且具备学到句向量生成的能力的,只是需要针对性的训练,才能具备句向量生成的能力。同时可以看到,对比学习对于句向量生成的提升效果显著。
-
缺点:无论是无监督还是有监督的方式来微调Bert,都需要准备额外的数据,同时,基于句子显示度微调完成的bert在跨任务场景(如在排序、检索任务)的表现可能并不是很好,这是bert类模型的统一缺点,一任务一模型。
-
工具:参考各算法源码实现
方案五: 大模型时代的通用嵌入模型
如图大模型统一了各种NLP子任务一样,在大模型时代,文本嵌入模型也迎来了大一统时代:使用更多的数据,更大的模型来训练得到一个专门的嵌入模型,如此,使用一个嵌入模型生成的句向量,能够同时支持多种应用场景,而且表现都很不错。
目前,在中文领域有m3e、gte、bge等嵌入模型可选,其中bge-large-zh-v1.5流行度较广,可以作为一个首选的基准模型进行使用。
bge介绍:https://blog.csdn.net/eagleofstar/article/details/132186774

要想获取最新的、最强的中文嵌入模型,搜索C-MTEB 评测基准
在2024.10月这个节点,最厉害的是conan-embedding-v1

- 优点:和方案四的任务定向微调模型相比,嵌入模型具备更好的泛化能力;任务四的模型通常基于bert/roberta,其max tokens为512,而嵌入模型目前有多种规格可选,比如4K、8K,甚至是128K,如此大的窗口,可以很好的完成长文本嵌入。
- 缺点:若在细分领域上需要更好的表现时,仍需要进行微调。
- 工具:
模型下载地址:Modelscope或Huggingface(国内不可用)
模型本地部署:Xinference(模型更多)或ollama(部署更方便)
四、总结:方案如何选取?
建议方案选取的一个原则是:方案挑选从简单到复杂,简单方案有简单方案的优点,有时候杀鸡不需要牛刀。
面对一个场景,不知道怎么选方案或模型时,可以优先用Glove或者Fasttext完成词向量训练,使用词向量平均的方式来获得句向量,成本非常低,快速在应用中构建出一个基准模型,后期若发现应用中存在着多义词、或者或句子中词的顺序敏感的场景,则可以考虑换用bert类的方法进行微调或者直接使用专门的嵌入模型。其中bert类微调模型推荐使用Sentence-bert或SimCSE作为基准模型,嵌入模型推荐使用bge-large-zh-v1.5作为基准模型。
如果图省事,不想去了解模型,更不想训练,则建议直接用嵌入模型。