1. 引言
本文重点讨论Polygon Miden所设计的UTXO+账户混合状态模型,以实现某些有趣的属性。
Miden的目标是:【即越具有隐私性,其可扩展性越好】
- 构建可扩展去中心化的rollup
- 采用支持隐私的架构

Miden支持灵活的交易模式:
- 公开交易
- 无状态交易
- 私人交易
- 本地交易

2. 何为去中心化zkRollup?
常规zkRollup方案是:
- L2用户将L2交易提交给operators
- 由 operators将L2交易打包为区块
- 由operators生成对应区块状态转换的ZK proof,并将该ZK proof提交给L1

去中心化zkRollup方案的:
- 安全性继承自L1
- 独立于L1的L2链,可有其自己的共识机制
- 可有permissionless的operators集合
构建去中心化rollup的挑战有:
- 1)共识机制
- 2)execution bloat执行膨胀
- 3)state bloat状态膨胀
本文重点关注执行膨胀和状态膨胀。
-
所谓执行膨胀,是指网络需执行所有交易:
- 产块者需执行某区块内的所有交易
- 网络中的其它节点也需要重新执行该区块内的所有交易

-
所谓状态膨胀,是指状态大小随时间增长:
- 节点需要全量状态来验证区块。
- 节点需要全量状态来生成新的区块。

3. Miden解决方案:UTXO+账户混合状态模型
执行膨胀和状态膨胀会带来如下问题:
- 1)中心化问题:需要强大(如大磁盘大内存等)的机器来运行节点。
- 2)缺少隐私性问题:网络中的每个人可看到链上发生的每笔交易细节。(Everyone sees everything)每个人都需要重新执行所有交易,并维护全量状态。
- 3)不可持续性问题(not sustainable):永远增长的状态。其增长速度超过了单个硬件机器配置的增长速度。
为此,希望所构建的解决方案能:
- 1)使执行膨胀最小化:即:
- 所有交易(包括网络交易)仅执行一次:【ZKP可实现】
- 可由不同的网络参与者并行执行交易:【要求并发状态模型】
- 本地执行:对不影响 具有共享状态账户 的交易,其可在本地执行,并在本地证明:

- 2)使状态膨胀最小化:即:
- 轻量验证节点:验证节点可丢弃绝大多数状态(即nullifier DB),无需维护全量状态即可验证区块:【ZKP可实现】
- 动态裁剪:产块者可独立决定维护哪些状态,即,无需维护全量状态即可生成新的区块:【要求并发状态模型】
- 由吞吐量驱动状态大小:状态大小主要依赖于当前TPS,而不是账户总数,也不是notes总数。


当前的区块链状态模型主要有2大类:
- 1)基于账户的状态模型:其具有如下特征:
- 适于表达智能合约
- 不太适于并行交易执行
- 不利于匿名
- 2)基于UTXO的状态模型:其具有如下特征:
- 不太适于表达智能合约
- 适于并行交易执行,各个UTXO是相互独立的。
- 适于实现匿名
Miden借助 账户模型 + UTXO模型 + ZK proofs,来实现:
- Actor-based model with concurrent off-chain state,即具备链下并行状态的、基于actor的模型。

3. Miden的交易模型:actor-based model with concurrent off-chain state
常规的actor模型是指:
- actors为具有“inboxes”的状态机
- actors之间通过消息传递来通信
- 消息的生成和消费是异步的
对应到Miden中的actor模型为:
- 账户维护了 状态 + 对外暴露的(Miden VM程序)接口
- 消息以notes来表示,notes中携带了 资产 + 花费该资产的“spend script”(为Miden VM程序)
- 不同于以太坊中仅需要1笔交易来实现资产转移。由于消息的生成和消费是异步的,即意味着,当在2个账户之间转移资产时,需要2笔交易。
- 1笔交易用于创建note。
- 另1笔交易用于消费该note。

3.1 Miden中的交易解析
与以太坊中的交易不同,Miden中的交易:
- 总是仅包含一个账户,其无法关联更多账户
- 消费0个或多个notes:通过执行某note的“spend script”来消费该note
- 生成0个或多个notes

Miden交易执行的流程为:

- 通过执行note1的script来消费note1
- note1的script会调用账户的接口函数(如receive()函数来接收资产,从而使得note1可将其资产传给)
- 账户的函数可修改该账户的状态,并创建新的notes。
- 重复以上流程来消费note2。note scripts会依次顺序执行。
3.2 Miden中交易的证明
由于Miden中的交易仅关联单个账户,因此看立即为交易生成ZK proof(Miden中采用STARK证明系统Winterfell):
- 交易的正确执行可在单个STARK proof中证明
- 所有交易的STARK proofs可并行生成

3.3 Miden中区块的证明


基本流程为:
- 对区块内的一堆tx proofs进行递归聚合,来获得batch proof
- 然后再对batch proof进行递归聚合,来获得block proof
- 最后对block进行递归聚合,来生成最终提交给L1的validity proof(如称为Epoch proof)
需注意的是:
- 以上递归聚合流程可并行进行
- 以上tx proofs可并行生成
- 以上batch proofs可并行生成
- 以上block proofs不可并行生成

还有一个很有趣的点在于:
- tx proofs可在用户本地生成
- batch proofs、block proofs、Epoch proofs需在网络中生成,如由产块者生成。
3.4 Miden中的本地交易和网络交易
传统的交易执行流程为:
- prepare:为交易准备输入
- execute:执行该交易
- prove:为该交易生成证明

其中: - 网络交易中,由网络(如产块者)来执行交易并为该交易生成证明。
- 本地交易中:由用户在本地:准备交易输入、执行该交易、为该交易生成证明。而:
- 产块者不需要执行该交易,也不需要为该交易生成证明。
- 产块者仅需要聚合该交易proof。

本地交易和网络交易,这2种交易模式的对比情况为:

3.5 Miden中共享状态处理逻辑
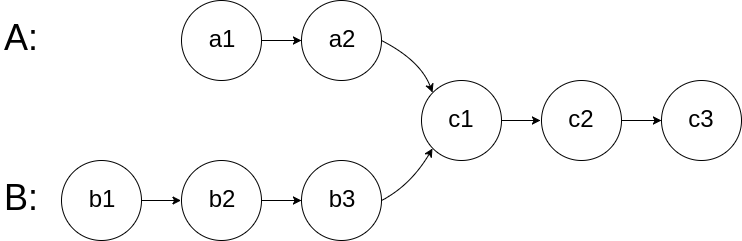
以Uniswap(为具有共享状态的账户)为例,有多个账户与其交互,需对共享状态进行处理:
- 2个用户独立执行交易tx1和交易tx2,分别创建了note1和note2。这2笔交易的目标都是uniswap account。
- 产块者创建交易tx3,并执行交易tx3。交易tx3会消费note1和note2,然后输出note3和note4。note3和note4分别 以 其note1和note2的原始account为目标。

- 然后这2个用户独立执行交易tx4和交易tx5,来分别消费note3和note4。

即:
- 与具有共享状态账户 进行交互的交易,其必须为网络交易,而不能是本地交易。
4. Miden中的状态模型
Miden rollup中的状态主要分为3大类:
- 1)account DB:存储所有账户的当前状态。以Spare Merkle tree作为数据存储结构,来将account IDs 映射到 account Hashes。不过Miden提供了2种不同的存储账户到数据库的方式:
- 1.1)on-chain state链上状态:对于具有链上状态的账户,节点会存储该账户的整个状态。与以太坊的账户存储模式相同。
- 1.2)off-chain state链下状态:对于具有链下状态的账户,节点仅存储该账户的哈希值。
- 由用户自己来负责存储其账户的实际状态。

- 2)notes DB:存储了目前为止所创建的所有notes。采用Merkle Mountain Range(MMR)数据结构来存储,为append-only accumulator。其叶子节点为某区块内所创建的一组notes。
选择Merkle Mountain Range(MMR)数据结构的原因在于:- 即使丢弃了大多数节点,notes也可添加到MMR。
- inclusion witness永远不会不新鲜,但其可能需要扩展。

- 3)nullifier DB:用于跟踪所有已消费的notes。采用Sparse Merkle tree作为数据结构来存储,用于映射note hash 到 0/1。其中1表示已消费,0表示未消费。nullifiers被组织成epochs,如4到6个月。实际有稍微更成熟的数据结构,即每个epoch共用一棵树,然后又创建新的树给下一epoch使用。节点仅需要维护最近2个epochs的nullifiers。

由区块 n n n引起的状态变更示意为:

Miden状态增长驱动因素为:
- 1)account DB:
- 增长主要来源为:具有链上状态的账户数 的增加
- 增长次要来源为:账户总数 的增加
- 裁剪策略为:忽略链上账户数据,但保留这些账户的哈希值
- 2)notes DB:
- 增长主要来源为:未消费的public notes的数量 的增加
- 增长次要来源为:未消费的notes数量 的增加
- 裁剪策略为:忽略链上note数据
- 3)nullifier DB:
- 增长主要来源为:吞吐量(TPS) 的增加
- 增长次要来源为:nullifier epoch长度 的增加
- 裁剪策略为:无

参考资料
[1] 2022年10月在哥伦比亚波哥大举行的DevCon 6中,Polygon Miden联合创始人Bobbin Threadbare分享的视频Using a Hybrid UTXO and Account-based State Model in a ZK Rollup by Bobbin Threadbare
Miden系列博客
- zk、zkVM、zkEVM及其未来
- Polygon L2扩容方案揭秘
- 混合Rollup:探秘 Metis、Fraxchain、Aztec、Miden和Ola
- Polygon Miden:扩展以太坊功能集的ZK-optimized rollup