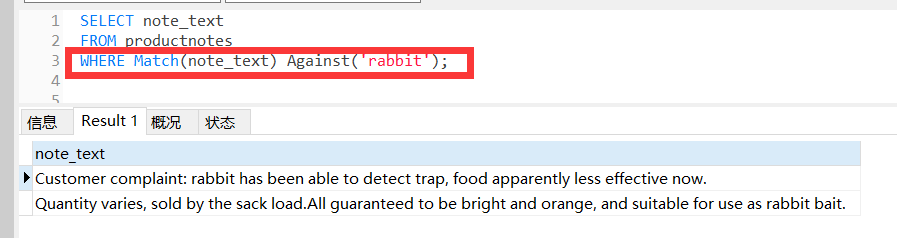
引言
在组队学习——贝叶斯分类器(一)中布置了一个鸢尾花分类的任务,以下是关于它的代码详解:
要求对鸢尾花数据集进行分类,如何进行数据预处理(提示:将分类数据转换成定量数据)
第2——145行数据为训练集和验证集数据
第146——151行数据为测试集数据

第一步:模型库的导入和数据的读取
import numpy as np
from scipy import stats
from sklearn.model_selection import train_test_split
import pandas as pd
from sklearn.naive_bayes import GaussianNB, MultinomialNB, BernoulliNB, ComplementNB
from sklearn.metrics import accuracy_score# 设置文件路径
file_path = 'E:\\Jupyter Workspace\\数学建模\\多分类鸢尾花.csv'
# 使用 pandas 的 read_csv 函数读取 CSV 文件,注意查看csv文件的编码,默认不填为utf-8编码
data = pd.read_csv(file_path,encoding='gbk')
# 显示数据的前几行来验证读取是否成功
print(data.head())
pd.set_option('display.unicode.ambiguous_as_wide', True)
pd.set_option('display.unicode.east_asian_width', True)
pd.set_option('display.width', 300) # 设置打印宽度(**重要**)
print(data.isnull().any())第二步: 用独热编码表示种类
# 转化其中一列
kind_encoder=pd.get_dummies(data[['种类']])
data2=pd.concat([kind_encoder,data],axis=1)
print(data2)
第三步:将独热编码转化为整数标签,同时划分训练集、验证集、测试集
# 选择第二列到最后一列,第一列相当于序号列可以忽略
X = data2.iloc[0:144, 3:7] # [:)左闭右开
# print(X)
Y_onehot = np.array(data2.iloc[0:144, 0:3])
Y = np.argmax(Y_onehot, axis=1)
print(Y)test_X = data2.iloc[144:, 3:7]
# print(test_X)# 划分数据集为训练集和验证集
X_train, X_valid, Y_train, Y_valid = train_test_split(X, Y, test_size=0.2, random_state=42)第二步和第三步用其它工具也可以操作,不一定非得用python代码,比如用excel将对应的“山鸢尾”标记为0,“变色鸢尾”标记为1,等等操作。
第四步:用不同的朴素贝叶斯分类器进行预测,选择最优的朴素贝叶斯
# 高斯朴素贝叶斯
gaussian_model = GaussianNB()
gaussian_model.fit(X_train, Y_train)
Y_pred = gaussian_model.predict(X_valid)
print(f"Gaussian Naive Bayes Accuracy: {accuracy_score(Y_valid, Y_pred)}")# 多项式朴素贝叶斯
multinomial_model = MultinomialNB()
multinomial_model.fit(X_train, Y_train)
Y_pred = multinomial_model.predict(X_valid)
print(f"Multinomial Naive Bayes Accuracy: {accuracy_score(Y_valid, Y_pred)}")# 伯努利朴素贝叶斯
bernoulli_model = BernoulliNB()
bernoulli_model.fit(X_train, Y_train)
Y_pred = bernoulli_model.predict(X_valid)
print(f"Bernoulli Naive Bayes Accuracy: {accuracy_score(Y_valid, Y_pred)}")# 补充朴素贝叶斯
complement_model = ComplementNB()
complement_model.fit(X_train, Y_train)
Y_pred = complement_model.predict(X_valid)
print(f"Complement Naive Bayes Accuracy: {accuracy_score(Y_valid, Y_pred)}")
![AGI 之 【Hugging Face】 的【从零训练Transformer模型】之二 [ 从零训练一个模型 ] 的简单整理](https://i-blog.csdnimg.cn/direct/e6a72f56c71c49aaaea3803878c195cf.png)