一、 概念介绍
1.1 Langchain 是什么?
官方定义是:LangChain是一个强大的框架,旨在帮助开发人员使用语言模型构建端到端的应用程序,它提供了一套工具、组件和接口,可简化创建由大型语言模型 (LLM) 和聊天模型提供支持的应用程序的过程。LangChain是一个语言模型集成框架,其使用案例与语言模型的使用案例大致重叠,包括文档分析和摘要、聊天机器人和代码分析。
简单来说,LangChain提供了灵活的抽象和AI优先的工具,可帮助开发人员将LLM应用程序从原型转化为生产环境。 它还提供了一套工具,可帮助开发人员构建上下文感知、推理应用程序, LangChain的工具包括聊天机器人、文档分析、摘要、代码分析、工作流自动化、自定义搜索等。
1.2 如何使用 LangChain?
要使用 LangChain,开发人员首先要导入必要的组件和工具,例如 LLMs, chat models, agents, chains, 内存功能。这些组件组合起来创建一个可以理解、处理和响应用户输入的应用程序。
LangChain 为特定用例提供了多种组件,例如个人助理、文档问答、聊天机器人、查询表格数据、与 API 交互、提取、评估和汇总。
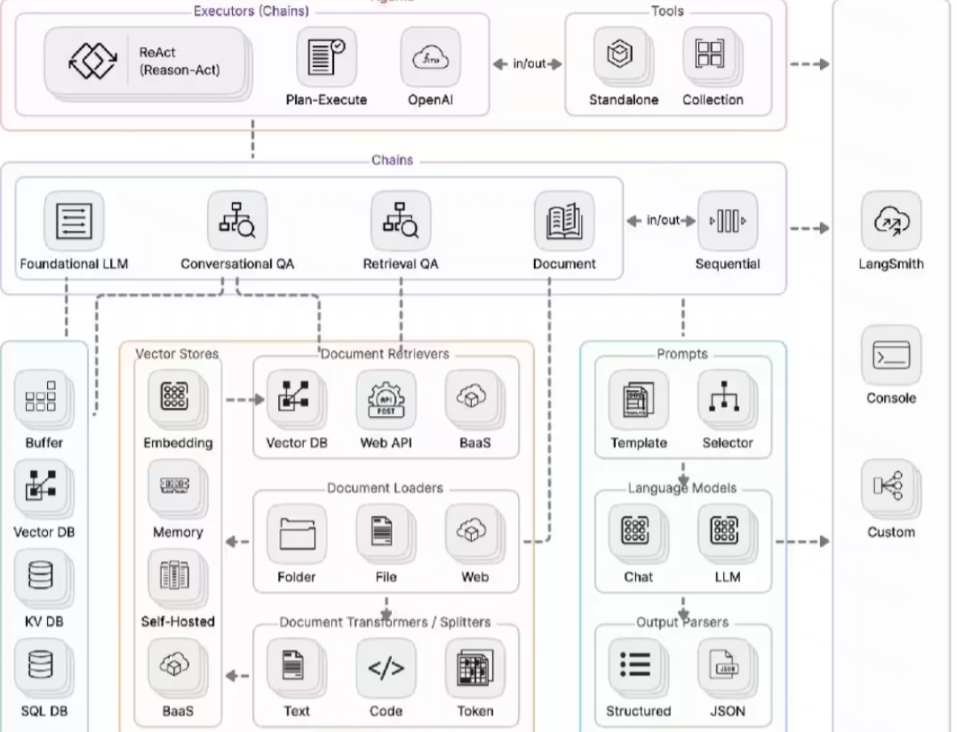
二、 主要包含组件:
- Model I/O:管理大语言模型(Models),及其输入(Prompts)和格式化输出(Output Parsers)
- Data connection:管理主要用于建设私域知识(库)的向量数据存储(Vector Stores)、内容数据获取(Document Loaders)和转化(Transformers),以及向量数据查询(Retrievers)
- Memory:用于存储和获取 对话历史记录 的功能模块
- Chains:用于串联 Memory ↔️ Model I/O ↔️ Data Connection,以实现 串行化 的连续对话、推测流程
- Agents:基于 Chains 进一步串联工具(Tools),从而将大语言模型的能力和本地、云服务能力结合
- Callbacks:提供了一个回调系统,可连接到 LLM 申请的各个阶段,便于进行日志记录、追踪等数据导流
Langchain核心模块架构图:
三、核心模块
3.1 Model I/O
模型接入 LLM 的交互组件,用于和不同类型模型完成业务交互,LangChain 将模型分为 LLMS、Chat Model两种模型方式,分别通过不同template操作完成三种模型的业务交互。
3.2 LLMs
是指具备语言理解和生成能力的商用大型语言模型,以文本字符串作为输入,并返回文本字符串作为输出。LangChain 中设计 LLM 类用于与大语言模型进行接口交互,该类旨在为 LLM 提供商提供标准接口,如 OpenAI、Cohere、Hugging Face。
以 OpenAI LLM 包装器为例,其使用方法如下:
from LangChain.llms import OpenAI llm = OpenAI(temperature=0, model_name='gpt-3.5-turbo', openai_api_key=OPENAI_API_KEY) llm("Please introduce yourself") llm.get_num_tokens(question)3.3 Chat
聊天模型是语言模型的一个变体,聊天模型以语言模型为基础,其内部使用语言模型,不再以文本字符串为输入和输出,而是将聊天信息列表为输入和输出,他们提供更加结构化的 API。通过聊天模型可以传递一个或多个消息。LangChain 目前支持四类消息类型:分别是 AIMessage、HumanMessage、SystemMessage 和 ChatMessage 。
- SystemMessage:系统消息是用来设定模型的一种工具,可以用于指定模型具体所处的环境和背景,如角色扮演等;
- HumanMessage:人类消息就是用户信息,由人给出的信息,如提问;使用 Chat Model 模型就得把系统消息和人类消息放在一个列表里,然后作为 Chat Model 模型的输入
- AIMessage:就是 AI 输出的消息,可以是针对问题的回答
- ChatMessage:Chat 消息可以接受任意角色的参数
大多数情况下,我们只需要处理 HumanMessage、AIMessage 和 SystemMessage 消息类型。此外聊天模型支持多个消息作为输入,如下系统消息和用户消息的示例
messages = [ SystemMessage(content="You are a helpful assistant that translates English to French."), HumanMessage(content="I love programming.") ] chat(messages) AIMessage(content="J'aime programmer.", additional_kwargs={})使用generate来生成多组消息
batch_messages = [ [ SystemMessage(content="You are a helpful assistant that translates English to French."), HumanMessage(content="I love programming.") ], [ SystemMessage(content="You are a helpful assistant that translates English to French."), HumanMessage(content="I love artificial intelligence.") ], ] result = chat.generate(batch_messages)3.4 Prompts
提示(Prompt)指的是模型的输入,这个输入一般很少是硬编码的,而是从使用特定的模板组件构建而成的,这个模板组件就是 PromptTemplate 提示模板,可以提供提示模板作为输入,模板指的是我们希望获得答案的具体格式和蓝图。LangChain 提供了预先设计好的提示模板,可以用于生成不同类型任务的提示。当预设的模板无法满足要求时,也可以使用自定义的提示模板。
在 LangChain 中,我们可以根据需要设置提示模板,并将其与主链相连接以进行输出预测。此外,LangChain 还提供了输出解析器的功能,用于进一步精炼结果。输出解析器的作用是指导模型输出的格式化方式,以及将输出解析为所需的格式。
LangChain 提供了几个类和函数,使构建和处理提示变得容易:
3.4.1 PromptTemplate 提示模板
可以生成文本模版,通过变量参数的形式拼接成完整的语句:
from langchain.llms import OpenAI from langchain import PromptTemplate import os openai_api_key = os.environ["OPENAI_API_KEY"] # 使用 openAi 模型 llm = OpenAI(model_name="gpt-3.5-turbo", openai_api_key=openai_api_key) # 模版格式 template = "我像吃{value}。我应该怎么做出来?" # 构建模版 prompt = PromptTemplate( input_variables=["value"], template=template, ) # 模版生成内容 final_prompt = prompt.format(value='红烧肉') print("输入内容::", final_prompt) print("LLM输出:", llm(final_prompt))输入内容:: 我想吃红烧肉。我应该怎么做出来? LLM输出: 做红烧肉的步骤如下: 1.准备材料:500克猪五花肉、2颗蒜瓣、1块姜、2勺糖、3勺生抽、1勺老抽、2勺料酒、500毫升水。 2.将五花肉切成2-3厘米见方的块状。 3.将切好的五花肉放入冷水中煮沸,焯水去腥,捞出备用。 4.热锅冷油,加入姜片和蒜瓣煸炒出香味。 5.将焯水后的五花肉加入锅中,煎至两面微黄。 6.加入糖,小火翻炒至糖溶化并上色。 7.加入生抽和老抽,均匀翻炒均匀上色。 8.倒入料酒,翻炒均匀。 9.加入煮肉的水,水量需稍微淹没五花肉,再放入一个小茶包或者香料包提味,盖上锅盖,大火烧沸。 10.转小火炖煮40-50分钟,期间要时常翻煮肉块,保持肉块上色均匀。 11.最后收汁,汁液收浓后即可关火。 12.盛出红烧肉,切片装盘即可享用。
3.4.2 FewShotPromptTemplate 选择器
将提示的示例内容同样拼接到语句中,让模型去理解语义含义进而给出结果。
from langchain.prompts.example_selector import SemanticSimilarityExampleSelector from langchain.vectorstores import FAISS from langchain.embeddings import OpenAIEmbeddings from langchain.prompts import FewShotPromptTemplate, PromptTemplate from langchain.llms import OpenAI import os ## prompt 选择器示例 openai_api_key = os.environ["OPENAI_API_KEY"] llm = OpenAI(model_name="gpt-3.5-turbo", openai_api_key=openai_api_key) example_prompt = PromptTemplate( input_variables=["input", "output"], template="示例输入:{input}, 示例输出:{output}", ) # 这是可供选择的示例列表 examples = [ {"input": "飞行员", "output": "飞机"}, {"input": "驾驶员", "output": "汽车"}, {"input": "厨师", "output": "厨房"}, {"input": "空姐", "output": "飞机"}, ] # 根据语义选择与您的输入相似的示例 example_selector = SemanticSimilarityExampleSelector.from_examples( examples, # 生成用于测量语义相似性的嵌入的嵌入类。 OpenAIEmbeddings(openai_api_key=openai_api_key), # 存储词向量 FAISS, # 生成的示例数 k=4 ) # 选择器示例 prompt similar_prompt = FewShotPromptTemplate( example_selector=example_selector, example_prompt=example_prompt, # 加到提示顶部和底部的提示项 prefix="根据下面示例,写出输出", suffix="输入:{value},输出:", # 输入变量 input_variables=["value"], ) value = "学生" # 模版生成内容 final_prompt = similar_prompt.format(value=value) print("输入内容::", final_prompt) print("LLM输出:", llm(final_prompt))输入内容:: 根据下面示例,写出输出 示例输入:厨师, 示例输出:厨房 示例输入:驾驶员, 示例输出:汽车 示例输入:飞行员, 示例输出:飞机 示例输入:空姐, 示例输出:飞机 输入:学生,输出: LLM输出: 教室
3.4.3 ChatPromptTemplate 聊天提示模版
以聊天消息作为输入生成完整提示模版。
from langchain.schema import HumanMessage from langchain.prompts import PromptTemplate, ChatPromptTemplate, HumanMessagePromptTemplate # 我们将使用聊天模型,默认为 gpt-3.5-turbo from langchain.chat_models import ChatOpenAI # 解析输出并取回结构化数据 from langchain.output_parsers import StructuredOutputParser, ResponseSchema import os openai_api_key = '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' chat_model = ChatOpenAI(temperature=0, model_name='gpt-3.5-turbo', openai_api_key=openai_api_key) prompt = ChatPromptTemplate( messages=[ HumanMessagePromptTemplate.from_template("根据用户内容,提取出公司名称和地域名, 用用户内容: {user_prompt}") ], input_variables=["user_prompt"] ) user_prompt = "水滴公司总部在北京吗?" fruit_query = prompt.format_prompt(user_prompt=user_prompt) print('输入内容:', fruit_query.messages[0].content) fruit_output = chat_model(fruit_query.to_messages()) print('LLM 输出:', fruit_output)输入内容: 根据用户内容,提取出公司名称和地域名, 用用户内容: 水滴公司总部在北京吗? LLM 输出: content='公司名称: 水滴公司\n地域名: 北京' additional_kwargs={} example=False
3.4.4 StructuredOutputParser 输出解析器
输出解析器是指对模型生成的结果进行解析和处理的组件。它的主要功能是将模型生成的文本进行解析,提取有用的信息并进行后续处理。如对模型生成的文本进行解析、提取有用信息、识别实体、分类和过滤结果,以及对生成文本进行后处理,从而使生成结果更易于理解和使用。它在与大型语言模型交互时起到解析和处理结果的作用,增强了模型的应用和可用性。
语言模型输出文本。但是很多时候,可能想要获得比文本更结构化的信息。这就是输出解析器的作用。即输出解析器是帮助结构化语言模型响应的类,LangChain 中主要提供的类是 PydanticOutputParser。
3.5 Data connection
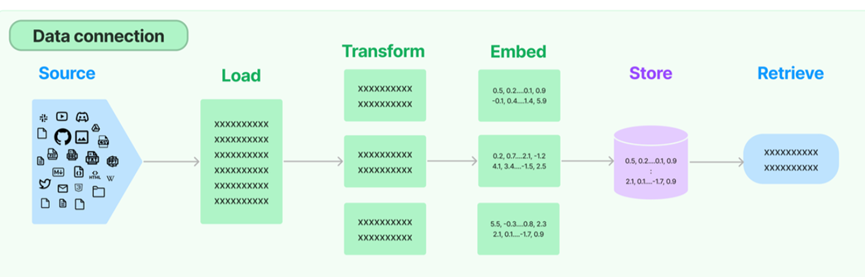
打通外部数据的管道,包含文档加载,文档转换,文本嵌入,向量存储几个环节,此模块包含用于处理文档的实用工具函数、不同类型的索引,以及可以在链中使用这些索引
LangChain 可以将外部数据和 LLM 进行结合来理解和生成自然语言,其中外部数据可以是本地文档、数据库等资源,将这些数据进行分片向量化存储于向量存储数据库中,再通过用户的 Prompt 检索向量数据库中的相似信息传递给大语言模型进行生成和执行 Action。

3.5.1 Document loaders 文档加载器
重点包括了 txt(TextLoader)、csv(CSVLoader),html(UnstructuredHTMLLoader),json(JSONLoader),markdown(UnstructuredMarkdownLoader)以及 pdf(因为 pdf 的格式比较复杂,提供了 PyPDFLoader、MathpixPDFLoader、UnstructuredPDFLoader,PyMuPDF 等多种形式的加载引擎)几种常用格式的内容解析。
3.5.2 Document transformers 文档转换器
LangChain 有许多内置的文档转换器,可以轻松地拆分、组合、过滤和以其他方式操作文档,重点关注按照字符递归拆分的方式 RecursiveCharacterTextSplitter 。
3.5.3 Text embedding models 文本嵌入
LangChain 中的 Embeddings 基类公开了两种方法:一种用于嵌入文档,另一种用于嵌入查询。前者采用多个文本作为输入,而后者采用单个文本。将它们作为两种单独方法的原因是,某些嵌入提供程序对文档(要搜索的)与查询(搜索查询本身)有不同的嵌入方法。
文本嵌入模型 text-embedding-model 是将文本进行向量表示,从而可以在向量空间中对文本进行诸如语义搜索之类的操作,即在向量空间中寻找最相似的文本片段。而这些在 LangChain 中是通过 Embedding 类来实现的。
Embedding 类是一个用于与文本嵌入进行交互的类。这个类旨在为提供商(有许多嵌入提供商,如 OpenAI、Cohere、Hugging Face 等)提供一个标准接口
from langchain.schema import HumanMessage from langchain.prompts import PromptTemplate, ChatPromptTemplate, HumanMessagePromptTemplate # 我们将使用聊天模型,默认为 gpt-3.5-turbo from langchain.chat_models import ChatOpenAI # 解析输出并取回结构化数据 from langchain.output_parsers import StructuredOutputParser, ResponseSchema import os openai_api_key = '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' chat_model = ChatOpenAI(temperature=0, model_name='gpt-3.5-turbo', openai_api_key=openai_api_key) prompt = ChatPromptTemplate( messages=[ HumanMessagePromptTemplate.from_template("根据用户内容,提取出公司名称和地域名, 用用户内容: {user_prompt}") ], input_variables=["user_prompt"] ) user_prompt = "水滴公司总部在北京吗?" fruit_query = prompt.format_prompt(user_prompt=user_prompt) print('输入内容:', fruit_query.messages[0].content) fruit_output = chat_model(fruit_query.to_messages()) print('LLM 输出:', fruit_output)3.5.4 VectorStores 向量存储
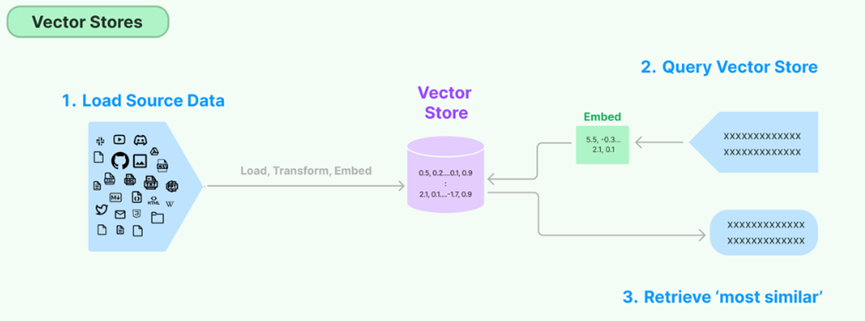
存储和搜索非结构化数据的最常见方法之一是嵌入它并存储生成的嵌入向量,然后在查询时嵌入非结构化查询并检索与嵌入查询“最相似”的嵌入向量。
矢量存储负责存储嵌入数据并为您执行矢量搜索。。处理向量存储的关键部分是创建要放入其中的向量,这通常是通过 embedding 来创建的。这个就是对常用矢量数据库(Chroma、FAISS,Milvus,Pinecone,PGVector 等)封装接口的说明,大概流程:初始化数据库连接信息——>建立索引——>存储矢量——>相似性查询,下面以 Chroma 为例:
# 加载文件 loader = TextLoader(filePath) documents = loader.load() # 切块数据 text_splitter = CharacterTextSplitter( chunk_size=chunkSize, chunk_overlap=0, length_function=len, separator=separator) split_docs = text_splitter.split_documents(documents) # 初始请求向量化数据 embeddings = OpenAIEmbeddings(openai_api_key=OPENAI_API_KEY) # 持久化文件地址 persist_directory = '/data/' + collectName # 执行向量化 vectorstore = Chroma.from_documents( split_docs, embeddings, persist_directory=persist_directory) # 持久化到本地 vectorstore.persist()3.5.5 Retrievers 查询
检索器是一个接口,它根据非结构化查询返回文档。它比矢量存储更通用。检索器不需要能够存储文档,只需返回(或检索)它。矢量存储可以用作检索器的骨干,但也有其他类型的检索器。
检索器接口是一种通用接口,使文档和语言模型易于组合。LangChain 中公开了一个 get_relevant_documents 方法,该方法接受查询(字符串)并返回文档列表。
重点关注数据压缩,目的是获得相关性最高的文本带入 prompt 上下文,这样既可以减少 token 消耗,也可以保证 LLM 的输出质量。
from langchain.llms import OpenAI from langchain.retrievers import ContextualCompressionRetriever from langchain.retrievers.document_compressors import LLMChainExtractor from langchain.document_loaders import TextLoader from langchain.vectorstores import FAISS documents = TextLoader('../../../state_of_the_union.txt').load() text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0) texts = text_splitter.split_documents(documents) retriever = FAISS.from_documents(texts, OpenAIEmbeddings()).as_retriever() docs = retriever.get_relevant_documents("What did the president say about Ketanji Brown Jackson") # 基础检索会返回一个或两个相关的文档和一些不相关的文档,即使是相关的文档也有很多不相关的信息 pretty_print_docs(docs) llm = OpenAI(temperature=0) compressor = LLMChainExtractor.from_llm(llm) # 迭代处理最初返回的文档,并从每个文档中只提取与查询相关的内容 compression_retriever = ContextualCompressionRetriever(base_compressor=compressor, base_retriever=retriever) compressed_docs = compression_retriever.get_relevant_documents("What did the president say about Ketanji Jackson Brown") pretty_print_docs(compressed_docs)3.5.6 Caching Embeddings 缓存嵌入
嵌入可以被存储或临时缓存以避免需要重新计算它们。缓存嵌入可以使用CacheBackedEmbeddings。
3.5.7 Memory
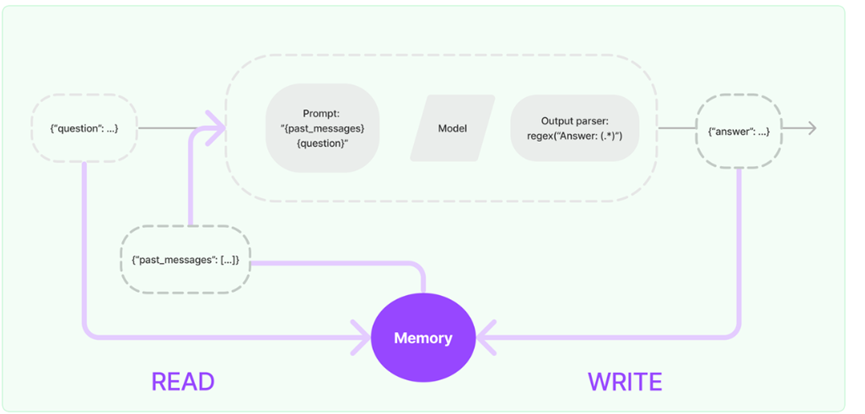
Memory 是在用户与语言模型的交互过程中始终保持状态的概念。体现在用户与语言模型的交互聊天消息过程,这就涉及为从一系列聊天消息中摄取、捕获、转换和提取知识。Memory 在 Chains/Agents 调用之间维持状态,默认情况下,Chains 和 Agents 是无状态的,这意味着它们独立地处理每个传入的查询,但在某些应用程序中,如:聊天机器人,记住以前的交互非常重要,无论是在短期的还是长期的。“Memory”这个概念就是为了实现这一点。
LangChain 提供了两种方式使用记忆存储 Memory 组件,一种是提供了管理和操作以前的聊天消息的辅助工具来从消息序列中提取信息;另一种是在 Chains 中进行关联使用。Memory 可以返回多条信息,如最近的 N 条消息或所有以前消息的摘要等。返回的信息可以是字符串,也可以是消息列表。
LangChain 提供了从聊天记录、缓冲记忆、Chains 中提取记忆信息的方法类以及接口,如 ChatMessageHistory 类,一个超轻量级的包装器,提供了一些方便的方法来保存人类消息、AI 消息,然后从中获取它们;再如 ConversationBufferMemory 类,它是 ChatMessageHistory 的一个包装器,用于提取变量中的消息等等。
from langchain.memory import ChatMessageHistory from langchain.chat_models import ChatOpenAI import os openai_api_key=os.environ["OPENAI_API_KEY"] chat = ChatOpenAI(temperature=0, openai_api_key=openai_api_key) # 声明历史 history = ChatMessageHistory() history.add_user_message("你是一个很好的 AI 机器人,可以帮助用户在一个简短的句子中找出去哪里旅行") history.add_user_message("我喜欢海滩,我应该去哪里?") # 添加AI语言 history.add_ai_message("你应该去广东深圳") # 添加人类语言 history.add_user_message("当我在那里时我还应该做什么?") print('history信息:', history.messages) # 调用模型 ai_response = chat(history.messages) print('结果', ai_response) # 继续添加 AI 语言 history.add_ai_message(ai_response.content) print('history信息:', history.messages) # 继续添加人类语言 history.add_user_message("推荐下美食和购物场所") ai_response = chat(history.messages) print('结果', ai_response)3.5.8 Chains
通常我们使用单独的 LLM 也可以解决问题,但是对于更加复杂的应用程序需要在 LLM 之间或与其他系统进行链接来完成任务,这个通常称为链接 LLM。
链允许将模型或系统间的多个组件组合起来,创建一个单一的、一致的应用程序。举例来说,我们创建一个链,该链接受用户的输入,通过 PromptTemplate 模板对输入进行格式化并传递到 LLM 语言模型。还可以将多个链组合起来,或者将链与其他系统组件组合起来,来构建更复杂的链,实现更强大的功能。LangChain 为链提供了标准接口以及常见实现,与其他工具进行了大量集成,并为常见应用程序提供了端到端链。
基础顺序链:
from langchain.llms import OpenAI from langchain.chains import LLMChain from langchain.prompts import PromptTemplate from langchain.chains import SimpleSequentialChain import os openai_api_key = os.environ["OPENAI_API_KEY"] llm = OpenAI(temperature=1, openai_api_key=openai_api_key) # 第一个链模版内容 template1 = "根据用户的输入的描述推荐一个适合的地区,用户输入: {value}" prompt_template1 = PromptTemplate(input_variables=["value"], template=template1) # 构建第一个链 chain1 = LLMChain(llm=llm, prompt=prompt_template1) # 第二个链模版内容 template2 = "根据用户的输入的地区推荐该地区的美食,用户输入: {value}" prompt_template2 = PromptTemplate(input_variables=["value"], template=template2) # 构建第二个链 chain2 = LLMChain(llm=llm, prompt=prompt_template2) # 将链组装起来 overall_chain = SimpleSequentialChain(chains=[chain1, chain2], verbose=True) # 运行链 review = overall_chain.run("我想在中国看大海") print('结果:', review) from LangChain.prompts import PromptTemplate from LangChain.llms import OpenAI from LangChain.chains import LLMChain llm = OpenAI(temperature=0.9) prompt = PromptTemplate( input_variables=["product"], template=" Please help me to find a new name for my company that makes {product}?", ) chain = LLMChain(llm=llm, prompt=prompt) print(chain.run("super phone"))上例中接受用户输入通过模板格式化输入后传递到语言模型就可以通过一个简单的链类来实现,如在 LangChain 中的 LLMChain 类。它是一个简单的链,可接受一个提示模板,使用用户输入对其进行格式化,并从 LLM 返回响应。当然 LLMChain 也可以用于聊天模型。
3.5.9 Agents
通常用户的一个问题可能需要应用程序的多个逻辑处理才能完成相关任务,而且往往可能是动态的,会随着用户的输入不同而需要不同的 Action,或者 LLM 输出的不同而执行不同的 Action。因此应用程序不仅需要预先确定 LLM 以及其他工具调用链,而且可能还需要根据用户输入的不同而产生不同的链条。使用代理可以让 LLM 访问工具变的更加直接和高效,工具提供了无限的可能性,LLM 可以搜索网络、进行数学计算、运行代码等等相关功能。
LangChain 中代理使用 LLM 来确定采取哪些行动及顺序,查看观察结果,并重复直到完成任务。LangChain 库提供了大量预置的工具,也允许修改现有工具 或创建新工具。当代理被正确使用时,它们可以非常强大。在 LangChain 中,通过“代理人”的概念在这些类型链条中访问一系列的工具完成任务。根据用户的输入,代理人可以决定是否调用其中任何一个工具。如下是一段简单的示例:
#加载要使用的语言模型来控制代理人 llm = OpenAI(temperature=0); #加载一些需要使用的工具,如serpapi和llm-math,llm-math工具需要使用LLM tools = load_tools(["serpapi", "llm-math"], llm=llm) #使用工具、语言模型和代理人类型初始化一个代理人。 agent = initialize_agent(tools, llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True) #控制代理执行 agent.run("Who is Vin Diesel's girlfriend? What is her current age raised to the 0.5 power?")
3.5.10 Callbacks
LangChain 提供了一个回调系统,允许您连接到 LLM 申请的各个阶段。这对于日志记录、监控、流传输和其他任务非常有用。
可以使用整个 API 中可用的参数来订阅这些事件。该参数是处理程序对象的列表,这些对象预计将实现下面更详细描述的一个或多个方法。