1 背景
在过去的几年,随着自动驾驶技术的不断发展,神经网络逐渐进入人们的视野。Transformer的应用也越来越广泛,逐步走向自动驾驶技术的前沿。笔者也在博客《人工智能---什么是Transformer?》中大概介绍了Transformer的一些内容:结构和简单应用。
本篇博客带领读者朋友们领略视觉Transformer在自动驾驶领域的应用。主要参考文献为:《A Survey of Vision Transformers in Autonomous Driving: Current Trends and Future Directions》。
2 视觉Transformer
论文中主要探索了视觉Transformers模型在自动驾驶中的适应性,这一转变受到Transformers在自然语言处理中所获得成功的启发。Transformers在序列图像处理等任务中超越了传统的递归神经网络(RNNs),在全局上下文捕获任务中优于卷积神经网络(CNNs),就如复杂场景识别所证明的那样,它在计算机视觉中越来越受欢迎。这些能力在自动驾驶中实时、动态的视觉场景处理方面是至关重要的。
在论文中全面概述了视觉Transformers在自动驾驶中的应用,着重于自注意力、多头注意力和编码器-解码器架构等基本概念。涵盖了目标检测、分割、行人检测、车道检测等领域的应用,比较了它们的架构优势和局限性。
2.1 主要内容
Transformer已经彻底改变了自然语言处理(NLP),BERT、GPT和T5等模型在语言理解方面树立了新的标准。它们的影响超出了NLP,因为计算机视觉(CV)采用了Transformers进行视觉数据处理。从传统的卷积神经网络(CNNs)和递归神经网络(RNNs)到CV中的变换器的这种转变意味着它们的影响力越来越大,在图像识别和对象检测中的早期实现显示出有希望的结果。
在自动驾驶中,Transformer正在转换一系列关键任务,包括对象检测、车道检测和分割,并且可以与强化学习相结合来执行复杂的路径查找。它们擅长处理空间和时间数据,优于传统的细胞神经网络和复杂函数中的RNN,如场景图的生成和跟踪。Transformer的自我注意机制提供了对动态驾驶环境的更全面的理解,这对自动驾驶汽车的安全导航至关重要。
论文中对自动驾驶中的视觉Transformer进行了广泛的概述,探讨了它的发展、分类和各种应用。从Transformer架构的基本方面开始,论文深入研究了视觉Transformer在自动驾驶中的作用,强调了对3D和2D感知任务的改进。
基本架构图可参考下图:
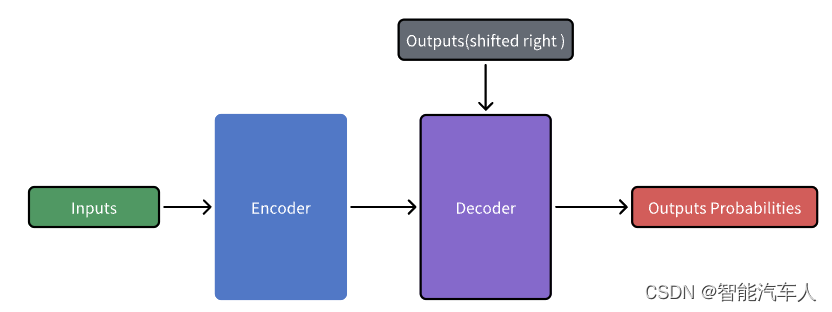
- 输入嵌入(Input Embeddings):将输入序列中的词或符号转换为向量表示。
- 位置编码(Positional Encodings):为输入序列中的每个位置添加位置信息,以便模型能够区分不同位置的词。
- 编码器(Encoder):由多个相同的层堆叠而成,每一层包含两个子层:多头自注意力机制和前馈神经网络。
- 解码器(Decoder):也由多个相同的层堆叠而成,每一层包含三个子层:多头自注意力机制、编码器-解码器注意力机制和前馈神经网络。
- 多头注意力机制(Multi-Head Attention):通过将注意力机制应用于多个投影版本的查询、键和值来捕捉不同表示空间中的信息。
- 前馈神经网络(Feed-Forward Neural Network):两个全连接层之间的ReLU激活函数,用于每个位置独立地处理输入。
- 残差连接(Residual Connections):在每个子层中添加残差连接,并进行层归一化(Layer Normalization)以避免梯度消失或爆炸问题。
- 位置编码合并(Position-wise Feed-Forward Networks):在每个位置独立地应用前馈神经网络,以增加模型的非线性建模能力。
2.2 自注意力机制
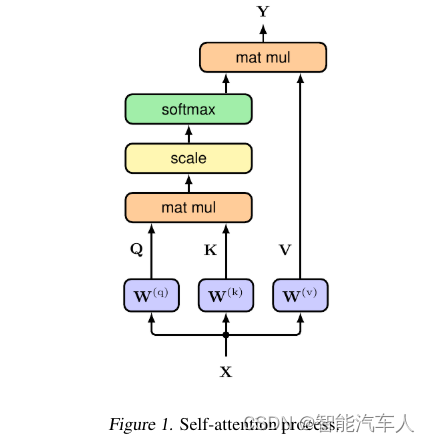
Transformer模型的核心是自注意机制(如上图所示),它评估输入序列的各个片段如何相互关联。在此过程中,每个输入元素被转换成三个矢量:查询(q)、键(k)和值(v),通常为维度d=512,并被编译成矩阵Q、K和V。然后,注意力函数通过查询和键之间的点积计算交互得分,然后进行归一化(除以) 以稳定训练。
这些分数通过softmax函数转换为概率,指示每个元素所需的关注程度。最终输出(Y)计算如下:
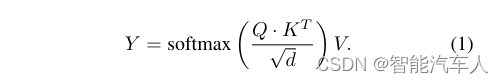
这是值向量的加权和,封装了整个序列的上下文。编码器-解码器注意机制允许解码器集中在输入序列的相关段上,由其当前状态和来自编码器的输出来通知。这种机制,再加上向输入嵌入添加唯一位置信息的位置编码,确保了对序列排序的全面理解。
2.3 多头注意力机制
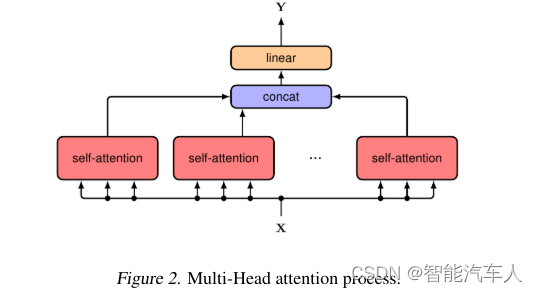
多头注意力机制(上图)增强了分析多维度输入数据的的能力。最初,输入向量被划分为三个不同的头的集合:查询集Q′,键集K′和值集V'。每个子集的维数为d/h。
这些集合由较小的向量组成——具体地说,每组h个向量,当d为512时,每个向量的维数为64。然后将这些向量分组以形成矩阵Q′,K′,和V′,用于之后的注意力计算。多头注意力流程的形式化如下:
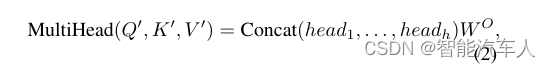
其中每个头 被定义为Y。在这种情况下,Q′,K'和V′表示由它们各自的矢量的级联形成的集合矩阵,
是将注意力头的单独输出组合成单个输出向量的学习权重矩阵。
2.4 其它重要机制
前馈网络(FFN)是Transformer模型的重要组成部分,在每个单元中进行自注意计算后定位。它由具有非线性激活函数的两阶段线性运算组成,通常为高斯误差线性单元(GELU)。这在数学上表示为:
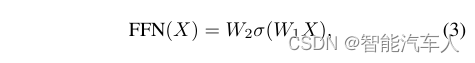
其中和
是可学习参数的矩阵,
表示非线性函数。FFN的作用是增强处理复杂数据模式的能力,其中间层通常容纳约2048个单元。
跳过连接是Transformer模型每一层的组成部分,增强了信息流并解决了消失梯度问题。
这些连接将输入直接添加到子层的输出中:
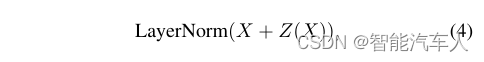
其中X是输入,是输出。跳过连接,结合层归一化,确保稳定的学习。一些变量采用层前归一化来进行优化,并在每个子层之前使用归一化。
先了解一下什么是logits?logits表示未归一化的概率,即各个特征的加权之和。logits经过sigmoid或softmax函数变为归一化的概率值。
Transformers中的输出层对于将矢量序列转换为可解释的输出至关重要。它包括将向量线性映射到与词汇表大小匹配的logits空间,然后是将logits转换为概率分布的softmax函数。这一层是将处理后的数据转换为最终的、可理解的结果的关键,在各种数据处理任务中至关重要。
自动驾驶中的Transformer具有高级特征提取器的功能,与细胞神经网络不同的是,它集成了更大视野中的信息,以实现全局场景理解。它们并行处理数据的能力提供了显著的计算效率,这对自动驾驶汽车的实时处理至关重要。全局视野和效率使Transformer极具优势用于自动驾驶技术,增强系统功能。
3 视觉Transformer的应用
在NLP(自然语言处理)中基本都是在vanilla Transformer概念的基础上进行研究,本节主要说明视觉Transformer的动态世界及其在自动驾驶中的影响力。视觉Transformer已经发生了重大变化,展示了其在车辆技术中的多功能性和有效性。接下来的部分将详细介绍如何在自动驾驶的各个维度上使用视觉Transformer。首先探索它们在3D任务中的使用,包括物体检测、跟踪和3D分割等基本功能,这些功能是环境感知的基础。然后过渡到2D任务,突出了它们在车道检测、复杂分割和高清晰度地图创建方面的能力——所有这些都对解释二维空间数据至关重要。
最后,论文深入研究了视觉Transformer的其他关键作用,如轨迹和行为预测及其在端到端自动驾驶系统中的集成。通过视觉Transformer在自动驾驶中的应用,不仅展示了它们的适应性,还强调了它们在增强自动驾驶汽车能力方面日益重要的影响力。
3.1 视觉Transformer的崛起
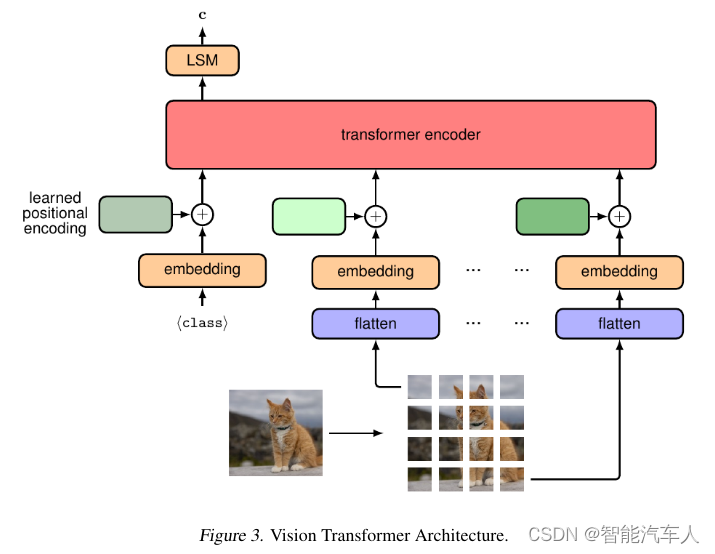
下图带来了自动驾驶中图像处理的范式转变,用自注意层取代了传统的卷积层。这种变革性的方法将图像分割成不同的补丁,以使用由自注意层和前馈层组成的Transformer编码器进行分析。这使得能够对重要的图像片段进行集中分析,从而大大提高驾驶场景中的感知能力。
对于较大的图像,ViT采用了一种混合模型,结合了卷积层和自注意层。这种创新策略对于有效处理复杂的视觉数据至关重要,这是自动驾驶汽车复杂决策的关键要求。
3.2 3D感知任务
视觉Transformer在3D物体检测方面带来了重大创新,PETR、CrossDTR、BEVFormer和UVTR等模型处于领先地位。PETR特别使用位置嵌入变换来增强具有3D坐标信息的图像特征,从而提供更详细的空间理解。CrossDTR集成了DETR3D和PETR的优势,创建了一个统一的检测框架,该框架由跨视图分析和深度指导提供信息。BEV Former利用时空视觉Transformer架构,通过无缝集成空间和时间数据实现统一的BEV表示。另一方面,UVTR专门从事深度推断,利用跨模态相互作用形成不同的体素空间,从而实现对精确的3D对象检测至关重要的广泛的多模态分析。
随着视觉Transformer的集成,自动驾驶中的3D分割领域有了显著的改进。TPVFormer、VoxFormer等和SurroundOcc是值得注意的例子。TPVFormer通过将体积转换为BEV平面来减少计算负载,从而保持语义占用预测的高精度。VoxFormer使用2D图像创建3D体素查询建议,通过可变形的交叉注意力查询增强分割。SurroundOcc利用一种独特的方法从不同视图和比例的2D图像中提取3D BEV特征,熟练地合并这些特征以绘制出密集占用的空间。
视觉Transformer模型为自动驾驶汽车的3D对象跟踪带来了变革。像MOTR和MUTR3D这样的模型扩展了传统跟踪方法的能力。MOTR以DETR模型为基础,引入了一种“跟踪查询”机制,用于对视频序列的时间变化进行建模,避免了对传统启发式方法的依赖。MUTR3D引入了一种创新的方法,允许同时进行检测和跟踪。它利用不同相机和帧之间的关联来理解随着时间的推移,物体的三维状态和外观,从而大大提高了自动驾驶系统中的跟踪精度和效率。
3.3 2D感知任务
在自动驾驶中,与2D感知相关的任务包括检测车道、分割各种元素和创建高清地图等关键功能。这些任务的重点是处理和理解二维空间数据,这是自动驾驶汽车技术的一个关键方面。与处理深度和体积的3D任务不同,2D任务需要对平面和平面元素进行精确解释,这对自动驾驶汽车的精确导航和安全至关重要。
车道检测是有效利用Transformer模型的主要领域,可分为两组。第一组包括BEVSegFormer等模型,该模型使用交叉注意力机制进行多视图2D图像特征提取,并使用基于CNN的语义分割进行准确的车道标记检测。另一个例子,PersFormer将用于2D车道检测的细胞神经网络与用于增强纯电动汽车特征的变压器相结合。第二组以LSTR和CurveFormer等模型为特色,专注于从2D图像中直接生成道路结构。这些模型使用Transformer查询来细化道路标线,并实现曲线查询以有效生成车道线,展示了Transformer在车道检测任务中的多功能性和准确性。
除了车道检测,Transformer模型越来越多地应用于自动驾驶中的分割任务。TIiM以其序列到序列模型举例说明了这一应用,该模型有效地将图像和视频转换为开销BEV图,将图像中的垂直扫描线链接到图中的相应射线,以实现数据高效和空间感知处理。Panoptic SegFormer提供了一种包罗万象的全景分割方法,集成了语义和实例分割。利用监督掩码解码器和查询解耦策略,提高了分割效率。该模型展示了Transformer架构在处理复杂分割任务方面的灵活性。
在高清晰度地图生成领域,STSU、VectorMapNet和MapTR等Transformer架构正在带来重大进步。STSU将车道视为有向图,重点学习Bezier控制点和图连接,将前视图摄像机图像转换为详细的道路结构。另一方面,VectorMapNet在高精度地图的端到端矢量化方面处于领先地位,利用稀疏折线基元对几何形状进行建模。MapTR为矢量化地图生成提供了一个在线框架,将地图元素视为点集,并采用分层查询嵌入方案。这些模型强调了在将多视图特征合并为有凝聚力的汽车视角方面的进展,这对于创建准确详细的自动驾驶地图至关重要。
3.4 预测、规划和决策任务
Transformer在自动驾驶中越来越重要,尤其是在预测、规划和决策方面。这一进展标志着向端到端的深度神经网络模型的重大转变,该模型将整个自动驾驶管道(包括感知、规划和控制)集成到一个统一的系统中。这种整体方法反映了传统模式的实质性演变,表明朝着更全面和自动驾驶汽车技术的集成解决方案。
在轨迹和行为预测中,基于Transformer的模型,如VectorNet、TNT、DenseTNT、mmTransformer和AgentFormer,已经解决了标准CNN模型的局限性,特别是在远程交互建模和特征提取方面。VectorNet通过以下方式增强了对空间关系的描述采用层次图神经网络,用于高清晰度地图和agent轨迹表示。TNT和DenseTNT改进了轨迹预测,DenseTent引入了无锚预测功能。mmTransformer利用堆叠架构进行简化的多模式运动预测。AgentFormer允许直接的代理间状态随时间的影响,保存关键的时间和交互信息。WayFormer通过其创新的融合策略进一步解决了静态和动态数据处理的复杂性,提高了数据处理的效率和质量。
自动驾驶的端到端模式有了显著的发展,特别是在规划和决策方面。TransFuser通过使用多个Transformer模块进行全面的数据处理和融合,举例说明了这一演变。NEAT引入了一种新的BEV坐标映射函数,将2D图像特征压缩为流线型表示。在此基础上,InterFuser提出了一种用于多模式传感器数据融合的统一架构,增强了安全性和决策准确性。MMFN扩展了数据类型的范围,包括高清地图和雷达,探索了多种融合技术。STP3和UniAD进一步为该领域做出了贡献,STP3专注于时间数据集成和UniAD重组任务,以实现更有效的规划。这些模型共同标志着向集成、高效和更安全的自动驾驶系统迈出了重要一步,展示了Transformer技术在该领域的变革性影响。
4 面临的挑战
- 数据效率
视觉Transformer通常需要大量数据进行训练。如何通过数据增强、迁移学习等技术提高数据效率。
- 实时性
自动驾驶对实时性要求极高。优化模型结构、减少计算量等方法来提高处理速度。
- 鲁棒性
自动驾驶系统需要应对各种复杂环境和天气条件。通过增强模型的泛化能力来提高鲁棒性。
5 总结
本文对自动驾驶中的Transformer模型,特别是视觉Transformer进行了比较全面的说明,展示了它们的意义超越了传统的卷积神经网络(CNNs)和递归神经网络(RNNs)。探索了Transformer在自然语言处理和计算机视觉方面的基础架构、基于注意力的处理优势,以及它们在各种自动驾驶任务中的卓越性能,包括3D对象检测、2D车道检测和高级场景分析。
此外,视觉Transformer凭借其细致入微的数据处理能力,有望在车载技术方面取得令人兴奋的进步。