引言
随着云计算技术的发展,Amazon Web Services (AWS) 作为一个开放的平台,一直在帮助开发者更好的在云上构建和使用开源软件,同时也与开源社区紧密合作,推动开源项目的发展。
本文主要探讨2024年值得关注的一些开源软件及其在AWS上的应用情况,希望能够给大家参考使用!
2024年数据开源软件的趋势
这张图是根据海外的数据工程师总结的数据开源软件landscape,我们可以观察到一些关键的趋势:

数据存储与管理
国内软件的崛起:越来越多的中国开源软件在数据存储领域崛起,例如Pingcap、OceanBase和ShardingSphere。这些项目不仅由中国的社区主导,也得到了背后商业公司的大力支持。
存储系统:开源软件在数据存储或数据库系统方面依旧是讨论的热点,表明存储解决方案的重要性在不断增加。
数据湖与数据处理
- 数据湖技术:数据湖的构建和管理是近年来广泛讨论的主题,显示出企业对于整合不同来源数据的高需求。
DataOps
数据调度:传统工具如Airflow和Azkaban以及新兴的Apache DolphinScheduler,都在数据工作流和DataOps平台领域中被广泛使用。特别是Apache DolphinScheduler,近年来受到了开发者和企业的广泛关注。
数据集成工具:以 Apache SeaTunnel 等为代表的工具在数据处理和数据接入方面扮演着重要角色,帮助企业有效地管理和转换数据。
作为一个开放的云平台,AWS不仅提供技术支持,还积极与全球社区进行深度合作,帮助开发者和企业在云上构建和扩展他们的开源项目。
接下来我们总结一下开源软件为什么这么重要?是因为它们不仅提供了灵活性和创新的加速,而且还帮助企业优化成本并提高产品的健壮性。
开源软件的四大优势
灵活性和可定制性
开源软件的一个主要优点是其灵活性和高度的可定制性。因为源码直接掌握在开发者或客户手中,用户可以根据自己企业的特定需求来修改和优化软件,使其更加符合自己的业务场景。
加速创新
从流式数据处理到数据仓库和湖仓一体化,再到DataOps和人工智能,许多创新技术都是首先在开源社区中提出并发展起来的。关注开源软件,就是紧跟创新的步伐。
成本优化
无论是传统IDC机房的客户还是在云上有较大规模的客户,他们都关注如何优化成本。开源软件提供了一种降低商业软件成本、优化资源使用的有效途径,帮助企业减轻经济负担。
社区里边有一句名言“社区重于代码”,一个开源项目的的成功不仅仅是代码的产出,而是整个社区生态的繁荣,开源软件通常拥有活跃的社区支持,代码和功能不断迭代和更新。像Apache DolphinScheduler这样的项目,其成为Apache基金会顶级项目证明了其在代码质量、功能成熟度和社区活跃度等多个维度的高标准。社区的活跃不仅仅体现在代码产出上,更重要的是社区的建设和生态的完善。
我们刚才讲到帮助我们的开发者在云上去构建开源软件,那AWS能提供给开发者什么样的内容,帮助开发者做哪些东西?
数据分析服务
数据接入和处理
首先我们可以看一下下面这张图,这张图是亚马逊云科技数据分析的服务的一个整体介绍,这里边会去按照像刚才的开源项目的一些分类,就是我们把从数据接入、数据处理、数据湖再到数据分析,还有一些结合 AI 模型 learning 的一些服务,做了一个分类。
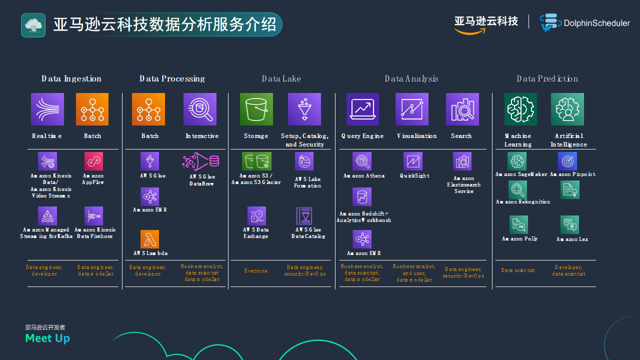
AWS为数据接入和处理提供了多种服务:
实时处理:利用完全托管的Flink服务,即Amazon Kinesis,为实时数据流提供强大支持。
批处理和离线处理:通过Data Firehouse等服务支持批量离线数据处理,这些服务的底层技术部分源自开源社区。
数据湖和数据分析
AWS不仅支持数据存储和管理,还提供了强大的数据分析工具:
Amazon Glue:作为一个完整的托管ETL服务,Glue支持数据准备和加载工作,使得数据分析工作变得更加高效。
Amazon EMR:提供了一个可扩展的Apache Hadoop框架来分析大规模数据集。
DolphinScheduler的集成
为了满足更广泛的客户需求,在数据解决方案中引入了Apache DolphinScheduler::
调度和工作流管理:DolphinScheduler与AWS服务如Amazon Kinesis和Amazon EMR集成,为开发者提供了强大的数据调度能力。
定制化任务调度:开发者可以通过DolphinScheduler定制EMR作业的参数,使任务调度更加灵活和高效。
当然我们通过链接社区的反馈,不断调整其服务以更好地服务于用户。
例如,基于用户反馈,AWS持续优化DolphinScheduler的集成,比如说现在已经集成了EMR,在 DolphinScheduler 的一个Task怎么去调度?EMR 的里面的一些参数能不能定制化,或者是做参数传递,或者是有一些更好地去更或者更方便的形式用 DolphinScheduler 去很好地去调度EMR提供更灵活的任务调度选项。
 其实大部分用户都是基于开源软件,然后做了很多的二次开发,然后帮助客户更快地去实现他们的业务价值,AWS通过与开源软件的深度结合,开发了多种服务和解决方案以满足不同客户的需求:
其实大部分用户都是基于开源软件,然后做了很多的二次开发,然后帮助客户更快地去实现他们的业务价值,AWS通过与开源软件的深度结合,开发了多种服务和解决方案以满足不同客户的需求:
数据接入与处理:利用如Amazon Kinesis和Data Firehouse等服务,AWS结合开源项目如Apache Flink,提供实时与批量数据处理能力。
数据存储优化:通过开源软件如ClickHouse、Apache Hudi和Apache Iceberg等,这些软件能够直接利用AWS的对象存储服务S3,为数据湖等应用提供支持。
存储服务的云原生优化
AWS不仅在功能上进行优化,还通过云原生技术确保存储服务的高效与成本效益:
对象存储S3:作为业界标准,S3为大量开源软件提供了可靠的底层存储支持。
弹性块存储EBS:EBS支持高性能的服务器挂载,适用于需要高吞吐量和低延迟的应用场景。
高效的成本管理
成本优化:AWS通过提供高性能的存储服务如新一代EBS,帮助客户降低存储成本。
原生备份服务:AWS的备份服务为数据提供了额外的安全保障,同时优化了数据恢复的成本和时间。
AWS负载均衡服务
AWS的负载均衡服务提供以下关键功能:
多协议支持:支持多种协议,确保不同场景下的负载均衡需求得到满足。
基于流量的收费模式:此服务基于流量收费,为开源项目提供成本优势,特别是在流量波动大的应用场景下。
加密协议支持:原生支持加密协议,增强了数据传输的安全性。
弹性和可扩展性
通过AWS负载均衡,开源软件能够更好地应对访问量的波动,自动调整资源以保持高性能和稳定性。
Serverless的优势
对于依赖数据库的开源调度工具(如DolphinScheduler),选择合适的数据库配置是一个挑战。AWS的Serverless数据库服务提供了灵活的解决方案:
自动化的资源管理:Serverless架构允许数据库自动根据负载调整计算资源,无需人工干预。
弹性扩缩容:支持快速扩容和缩容,响应时间可以达到秒级,非常适合需求波动大的场景。
计算单元的粒度:最小计算单元为0.5 ACU(含2GB内存),允许精细控制资源使用,优化成本。
场景应用
在高峰期,如夜间数据处理作业增多时,Serverless数据库能够自动增加资源,确保数据库性能满足需求。这种模式为开发者节省了显著的资源预算,并简化了数据库的管理工作。
我们希望通过利用AWS的负载均衡和Serverless数据库服务,开源软件项目可以获得更高的弹性、安全性和成本效率。
容器服务
容器技术已成为支持分布式系统的关键技术,海豚调度恰恰是分布式架构,AWS的Elastic Kubernetes Service (EKS) 提供了一个完全托管的Kubernetes服务,帮助开发者轻松部署和管理容器化应用。
AWS EKS的核心优势
AWS EKS允许用户在几分钟内部署一个完全兼容Kubernetes的集群,极大地简化了容器集群的设置和管理过程。
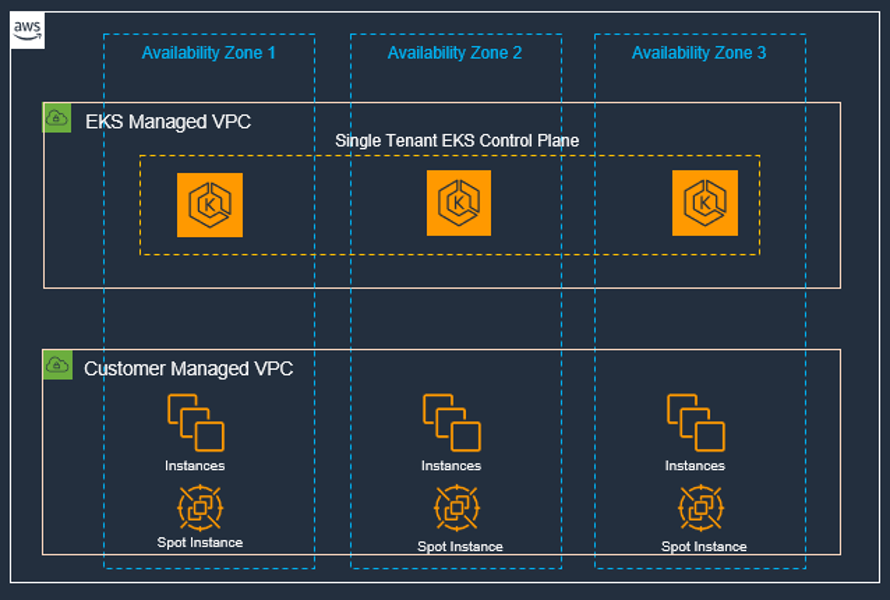
EKS保证与开源Kubernetes社区的100%兼容性,确保任何标准的Kubernetes应用都可以无缝迁移至AWS。
EKS集成了多种AWS服务,包括但不限于AWS的负载均衡和自动扩缩容服务,这些服务增强了开源软件的性能和可观测性。
Data On EKS(DoEKS)解决方案
DoEKS是一个由AWS架构师团队开发的开源项目,它旨在提供一个一键部署解决方案,使开发者能够快速在EKS上部署流行的开源软件,如Spark和Flink。
功能与优势
一键部署:用户可以通过执行一个脚本快速启动一个完整的开源软件集群。
降低技术门槛:DoEKS项目简化了传统的开源软件部署流程,从而让开发者可以避免复杂的安装和配置步骤。
应用场景无论是AI模型学习、数据分析还是大数据处理,DoEKS都提供了快速和高效的部署选项,帮助开发者专注于业务逻辑而非底层基础设施。
AWS EKS和DoEKS项目为开源社区提供了强大的支持,甚至是可以一键执行脚本,直接把这个开源组件拉起来,使得开发者可以更加便捷地部署和管理分布式系统。
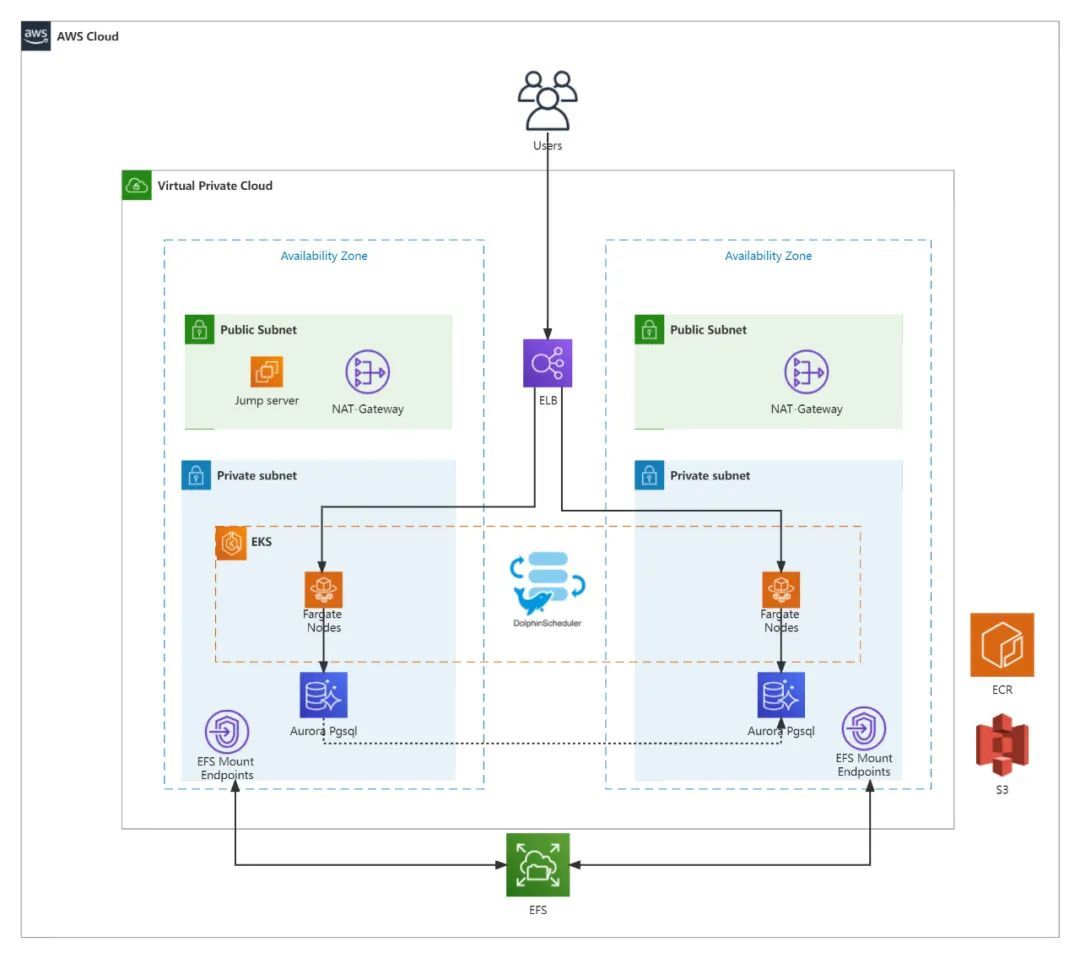
数据采集与处理
Kafka on EKS: 完全托管的服务,用于处理大规模的实时数据流。
Flink & Spark on EKS: 提供实时和批量数据处理能力,已与EKS完美集成,支持高效的数据分析任务。
DolphinScheduler on EKS: 我们计划提供调度和工作流管理,使任务自动化和优化更加容易。
一键部署与管理
DolphinScheduler: 已开发出专门的一键部署解决方案和指导文档,帮助用户快速在EKS上部署并管理DolphinScheduler。
ECR镜像版本管理: 提供操作指南,帮助管理和维护DolphinScheduler及其他开源软件的容器镜像版本。
Serverless 计算与ELB
Serverless 解决方案: 主要以Serverless计算为目标,提供无需管理服务器的高性能计算选项,特别适用于弹性需求高的应用。
Elastic Load Balancing (ELB): 支持多种协议,提供弹性扩缩容操作,确保应用在不同负载下的高可用性和性能。
综合解决方案
解决方案地图: 涵盖从数据集成到数据湖的全方位解决方案,例如利用Kafka Connect集成数据至Redshift数据仓或数据湖。
Apche Paimon与AWS Glue: 结合使用Apche Paimon和AWS Glue进行数据湖建设,提供全面的数据管理解决方案。
对于海豚调度我们也做了很多内容。比如说像刚才提到的 AWS 部署无服务器的 DolphinScheduler,我们就提供了一个无服务器的在 EKS 上快速部署的解决方案。然后还有包括 EMR Serverless,还有我们有客户或者有客户也跟我们一起合作了,帮助我们的开发者或者用户实现这种精确的监控或者是成本优化。
监控和运维支持
AWS不仅关注软件的部署和性能优化,还提供一系列监控和告警解决方案,帮助客户有效管理云上资源:
可观测性:AWS提供工具和服务来监控云组件的性能,确保系统的可靠性和效率。
安全和权限管理:结合先进的权限管理策略,AWS加强了数据和应用的安全性。
AWS Marketplace的第三方产品支持
- 订阅服务:在AWS Marketplace,用户可以轻松订阅第三方提供的产品,如商业版的DolphinScheduler,进一步简化了软件的获取和部署过程。
AWS的架构师团队也致力于为客户提供最佳的架构选择和优化建议,确保云上开源软件的高性能和可扩展性。
社区贡献和生态发展
社区参与:AWS积极参与开源社区,不仅贡献代码,还分享案例和最佳实践,促进开源软件的发展和创新。
技术探讨和解决方案分享:通过公开讨论和技术分享,AWS帮助开发者更好地理解和应用最新的云技术。
云原生服务和操作指南
AWS不仅提供基础的虚拟机服务,还通过云原生技术和详细的操作指南帮助客户构建和优化业务流程:
- Workshops和指导:AWS定期举办Workshop,提供实操指导,帮助客户充分利用云平台的潜力。
结论
AWS致力于成为企业使用和构建开源软件的首选平台。通过提供强大的服务、解决方案和社区支持,AWS确保客户能够在全球范围内顺利实施和扩展他们的业务。最后希望本文的分享对大家有所帮助。
延展阅读:使用 Apache DolphinScheduler 构建和部署大数据平台,将任务提交至 AWS 的实践经验
本文由 白鲸开源科技 提供发布支持!