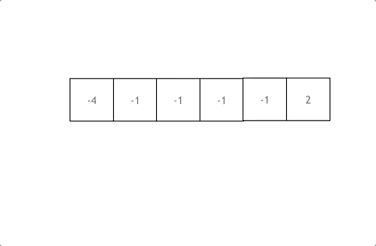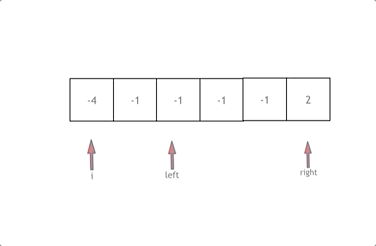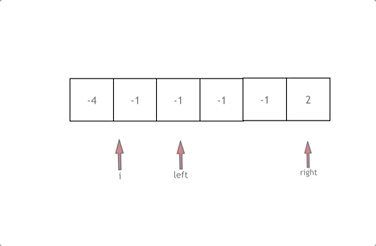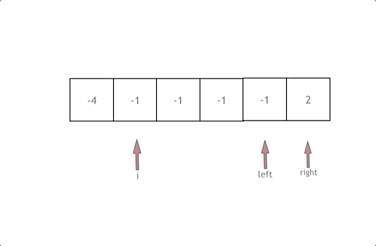
导学:索引什么时候失效?为什么类型转换索引会失效?不满足最左匹配原则?
- 我们都知道,MySQL它主要有2大模快组成,第一块就是我们的MySQL服务,里面包含了像连接管理、解析器、预处理、优化器、执行器,这个会把一条SQL语句执行的前置工作会做完,然后会生成一个执行计划,给到我们的存储引擎组件。
- 存储引擎负责数据的存储、操作以及解锁。MySQL支持的存储引擎有很多,比如InnoDB、MyISAM、Memory等等,不同的存储引擎,存储与操作的方式也不一样。
官网:MySQL :: MySQL 8.0 Reference Manual :: 16 Alternative Storage Engines
- 存储引擎是MySQL组件,可以为不同的表类型处理SQL操作。InnoDB是默认的,也是最通用的存储引擎,Oracle推荐使用它来存储表,除了特殊的用例。(MySQL 8.0中的CREATE TABLE语句默认创建InnoDB表)
- MySQL服务器使用可插拔的存储引擎架构,允许存储引擎在运行的MySQL服务器中加载和卸载。
- 要确定服务器支持哪些存储引擎,请使用SHOW engines语句。
- Support列的值表示是否可以使用该引擎:“YES”、“NO”和“DEFAULT”表示该引擎存在、不可用或可用,当前设置为默认的存储引擎。
-- 用于显示当前数据库可用的存储引擎列表,并显示它们的状态、默认值以及是否支持事务等信息
show engines;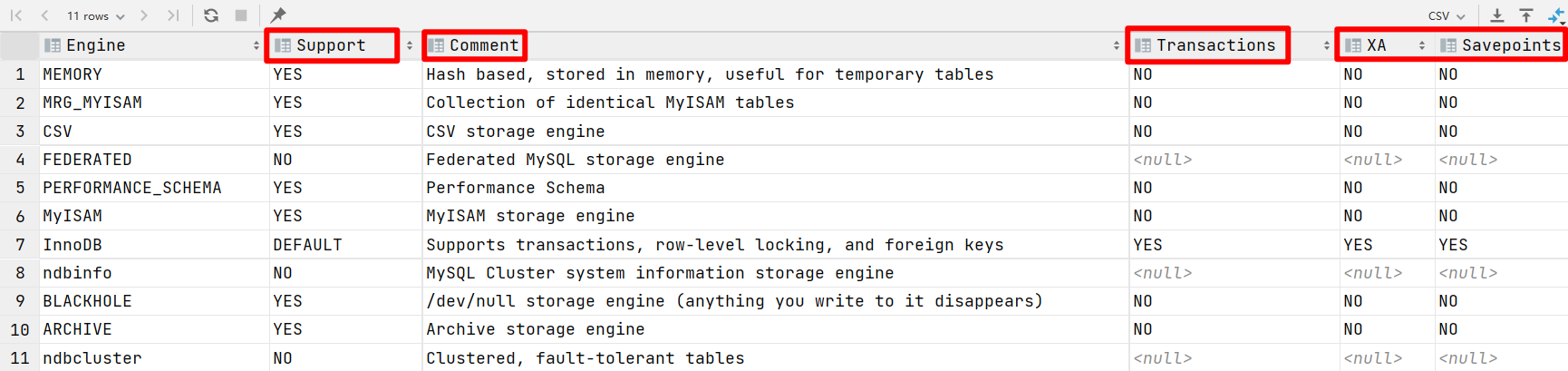
- Comment:注释
- Transactions:是否支持事务
- XA:表示是否支持XA分布式事务协议(涉及到两阶段提交)
- Savepoints:表示该存储引擎是否支持Savepoints
Savepoints
- Savepoints:它是一种在事务中创建的检查点(checkpoint),通过创建和使用SavePoints,可以在事务执行期间对事务进行部分回滚或回滚到先前的状态。
- 在事务中,Savepoints可以用来标记一个临时的保存点,以保留事务中的某个特定状态,这样,如果事务后续出现错误或需要回滚,可以根据需要回滚到先前的Savepoints,而不需要回滚整个事务。
- 通过Savepoints,可以更细粒度的控制事务的回滚操作,提供更灵活的事务管理能力。
- 使用"SAVEPOINT"命令来创建Savepoints,并使用"ROLLBACK TO SAVEPOINT"命令回滚到特定的Savepoint。
- 注意:Savepoints只在某些支持事务的存储引擎中可用,比如InnoDB。
MySQL 8.0支持的存储引擎
1. InnoDB: MySQL 8.0默认的存储引擎。
- InnoDB是一个事务安全(兼容ACID)的MySQL存储引擎,具有提交、回滚和崩溃恢复功能,以保护用户数据。
- InnoDB行级别的锁(没有升级到更粗粒度的锁)和oracle风格一致的非锁读取提高了多用户并发性和性能。
- 非锁读取(non-locking read)是指在读取数据时不对数据进行加锁的操作,也就是说其它事务仍然可以对数据进行修改操作。
- InnoDB将用户数据存储在聚集索引中,以减少常见的基于主键的查询的I/O。为了维护数据的完整性,InnoDB还支持外键引用完整性约束。
2. MyISAM:这些表占用空间很小。
- 表级锁限制了读/写工作负载的性能,因此它经常用于Web和数据仓库配置中的只读或以读为主的工作负载中。
3. Meomry - 内存:
- 将所有数据存储在RAM内存中,以便在需要快速查找非关键数据的环境中快速访问。这个引擎以前被称为堆引擎。
- 它的用例正在减少;InnoDB的缓冲池内存区提供了一种通用且持久的方式来将大部分或所有数据保存在内存中,而NDBCLUSTER为大型分布式数据集提供了快速的键值查找。
那么InnoDB存储引擎的数据怎么存的呢?
- 肯定会存到磁盘,磁盘里面会有文件,也就是表空间。
- 每次查询都去跟磁盘交互太慢了,所以多了一个Buffer-Pool内存区间的概念。
- 有了Buffer-Pool以后,每次查询数据,先去内存查,如果没有,那么再去从磁盘读取,读取后,放到内存,所以Buffer-Pool提升了性能,尽可能的减少跟磁盘的实时IO。因为我内存更改了以后,我所有的数据是异步同步到磁盘的。
- 内存跟磁盘的同步最小单位是page页。
- 一个page页里面到底能存多少数据,根据我的page页的大小以及行大小来决定的。
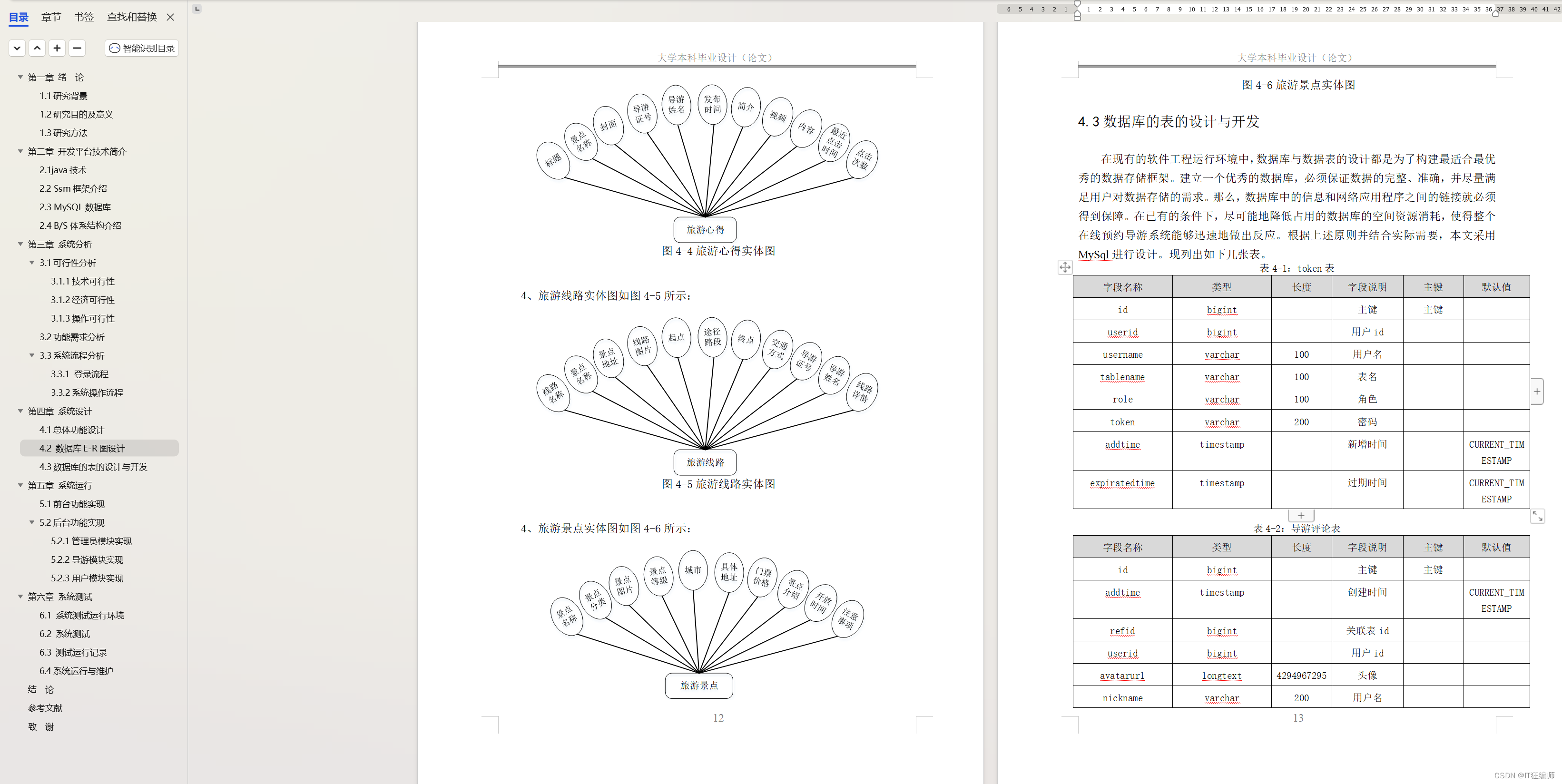
索引的概念
- 索引(Index)是帮助MySQL高效获取数据的一种数据结构。
索引创建
- 官网:MySQL :: MySQL 8.0 Reference Manual :: 13.1.15 CREATE INDEX Statement
- 在MySQL当中,index_type:USING{BTREE | HASH}
创建索引:
-- 创建索引 index_name命名规范:idx_表名_字段名 create [unique | FULLTEXT | SPATIAL] index 索引名 USING [BTREE | HASH] on 表名(字段名1,字段名2,...);CREATE INDEX idx_price USING BTREE ON product_new(product_price ASC);-- 建立多个字段联合索引 CREATE INDEX idx_age_name USING BTREE ON gp_teacher(teacher_age ASC, teacher_addr(4) ASC);创建、修改table创建索引
官网:MySQL :: MySQL 8.0 Reference Manual :: 13.1.20 CREATE TABLE Statement
CREATE TABLE huihui_test (`id` BIGINT NOT NULL AUTO_INCREMENT KEY,`name` varchar(100) NOT NULL COMMENT '商品名称',`image` varchar(100) NOT NULL COMMENT '商品图片',`title` varchar(100) NOT NULL COMMENT '商品标签',INDEX (`name`) )ENGINE = INNODBCHARACTER SET utf8mb4;MySQL :: MySQL 8.0 Reference Manual :: 13.1.9 ALTER TABLE Statement
ALTER table huihui_test ADD INDEX idx_title(title)
索引作用
-
索引的作用只有一个,提升查询性能!
-
SQL语句查询一般要求不能超过10毫秒或者20毫秒(1秒 = 1000毫秒),如果超过就是进行优化。
索引原理
MySQL :: MySQL 8.0 Reference Manual :: 8.3.1 How MySQL Uses Indexes
- 索引用于快速查找具有特定列值的行。
- 在没有索引的情况下,MySQL必须从第一行开始,然后遍历整张表来找到相关的行。表越大,开销也就越大,花费的时间就越多。
- 如果表中有相关列的索引,MySQL可以快速确定要查找的数据文件的中间位置,而无需查看所有数据。这比顺序读取每一行要快得多。
Hash索引
- InnoDB和MyISAM存储引擎都不支持Hash索引(Key-Value结构),只有Memory支持Hash索引,Full Text全文索引意义不大。
- Hash索引(Key-Value结构),根据单条记录/数据去查询速度会非常的快,所以Hash索引如果只查单条数据,那么它的速度是要比B+Tree快很多的;但是由于Hash索引是K-V结构,一个Key存一个Value,所以不支持范围查询,比如你去查大于1,你没有给我一个明确的Key,我怎么查?
- InnoDB和MyISAM之所以不支持Hash索引,因为InnoDB和MyISAM大多数都是一些关系型事务数据,场景大多数是一些范围查询而不是精准查询。
主键索引
- 在一张表里面,我们一般会有一个主键,那么这个主键我们不需要去建索引,它去查询的时候也会非常的快。
Page页存储

Page页链表
- 由于一个Page页里面存放row行数据是有限的,所以一个extent区里面肯定会有很多很多的page页,假如我们的数据越来越多,我们就需要新起一个page页,并且page页是以LRU链表保存的,所以page页跟page页之间就形成了一个双向链表,并且还必须要满足一个条件:链表的下一个页的最小数据必须要大于上一个页的最大数据,因为我们查询数据时很有可能要跨页查询,所以这一个原则可以使得页与页之间有关联,是为了更好的去查到我想要的数据。

类比书目录
- 现在,就相当于你有一本厚厚的书,但是没有目录。
- 比如水浒传,现在你想去找那个潘金莲棍打西门庆的那个章节,但是由于没有目录,你能做的就是一页一页的去翻,那么随着书的厚度查询到的时间也可能会越来越慢!
- 所以,书才有了一个目录,这个目录无非就是用额外的页,来记录你想看的数据在哪里,那么,你去找你你想要的数据,只需要遍历目录即可,不需要遍历整本书。
- 这个章节在哪一页,通过页码可以找到对应的位置,大大提升了我们去查询我们想要看的章节的速度
参考书目录的索引
- 为每个页建立一个目录后,这个目录也是一条数据,只不过这个数据是目录数据,目录所在的页叫目录页(就这个页我只去记录目录),为了确保Page页的唯一性,目录页也会有一个页ID,record行会有个字段,record_type,0代表真实的用户数据,而1代表的是目录数据。
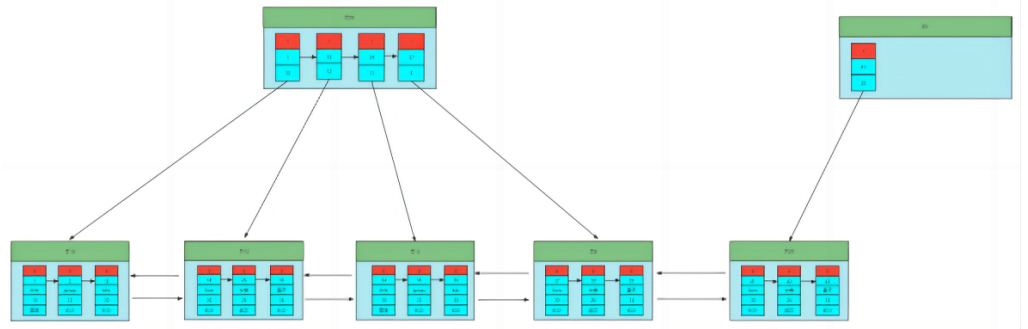
- 因为一个页只能放4条数据,那么目录页就会有2个,那么如果数据页越来越多,那我要查询的数据还是不知道在哪;
- 所以我们又可以参照书的二级目录或者三级目录思想,目录上面再 加/建 一层目录,也就是目录的目录,即父目录,直到根目录的位置能在一个page页放下!
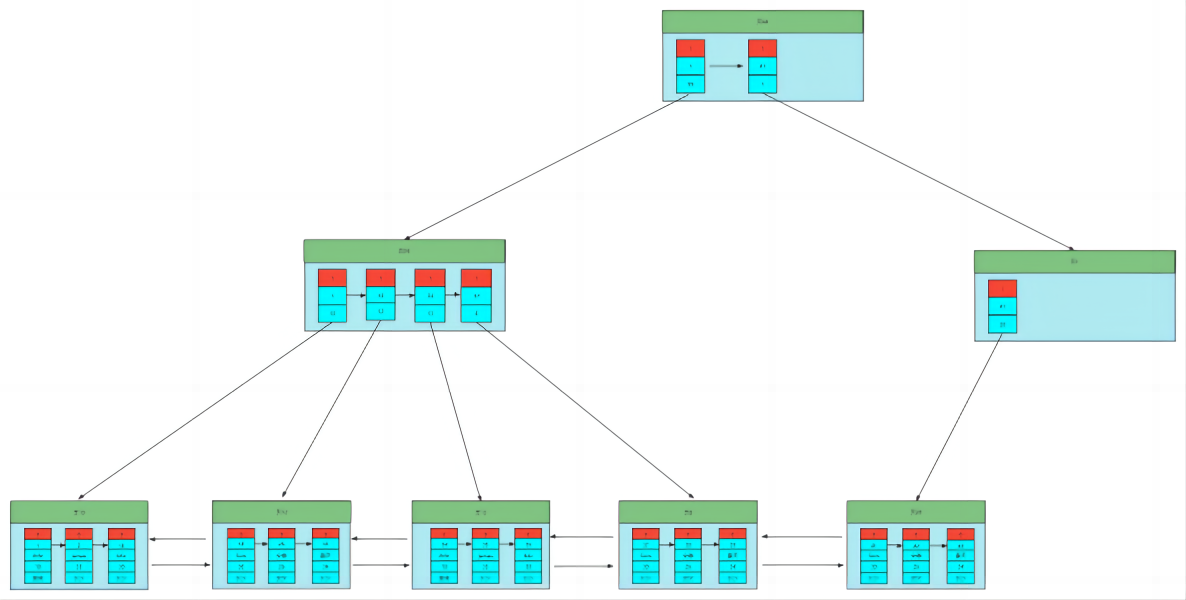
- 我们发现,慢慢的形成了一个树形结构,并且这个树跟二叉树是不一样的,一个节点可以有多个节点,并且只有叶子节点才有真实的数据,并且叶子节点与叶子节点之间形成了一个有序的双向链表,这个树就叫做B+Tree。


索引效果
- 在没有索引树之前,我们要去查询主键为43的数据,我们需要一条一条的去遍历,需要从1开始,直到找到43。
BTree VS B+Tree:
- BTree的数据存储在每个节点上,BTree的每个节点都会存储数据;而B+Tree中的数据只存储在叶子节点上,非叶子节点只存储索引,并且叶子节点中的数据通过双向链表的方式进行关联,可以方便的进行范围查询;而BTree的叶子节点之间没有指针连接,每个叶子节点独立存储数据项。
- B+Tree:B+Tree的第一层跟第二层没有真实的数据,它只有一个目录,真实的数据必须在第三层的叶子节点当中。
为什么MySQL中的索引结构要采用B+Tree而不是BTree?
- 从磁盘的I/O效率方面来看:B+Tree的非叶子节点不存储数据,所以树的每一层就能够存储更多的索引数量。也就是说,在层高相同的情况下/同样的层级,B+Tree要比BTree存储的数据量更多,因为在同样的一个Page页里面的数据,BTree要的空间更多,也就是同样的数据量,BTree的层级要比B+Tree更高,这间接增加了磁盘I/O的次数,但是不一定BTree就比B+Tree慢,BTree它只是整体慢,因为整体而言BTree的层级要越高。那什么情况下BTree要比B+Tree查询数据快呢?BTree可能只查一两次就查到对应的数据了,就不用向下查了,也就是在根节点或二级目录如果就找到了你想要的数据,就比B+Tree要快;而B+Tree必须到叶子节点,BTree可能在非叶子节点就查到对应的数据了,BTree可能会因为非叶子节点上有数据而减少查询次数。
- 从范围查询的效率来看:在MySQL中,范围查询是一个比较常用的操作,而B+Tree的所有存储在叶子节点上的数据使用了双向链表来进行关联,所以B+Tree在查询的时候只需要查询两个节点(page页)并进行遍历,通过遍历叶子节点形成的双向链表来获取连续的数据项,而不需要回溯到非叶子节点;而BTree需要获取所有节点,因此B+Tree在范围查询上效率更高。
- 从全表扫描方面来看:因为B+Tree是叶子节点存储所有数据,所以B+Tree的全表扫描能力更强一些,它只需要扫描叶子节点,而BTree需要遍历整个树。
- 从查询稳定性方面来看:B+Tree不管查询什么数据它都是比较稳定的,因为它都需要经过树的层级,它必须到要叶子节点才可以查询数据;而BTree可能在非叶子节点就能查到对应的数据了,查询是非常不稳定的。
- MongoDB使用的是B树。
B+Tree的特性:这个字段必须是排好序的!
主键 & 主键索引树
- 我们刚才索引树里面的排序默认是根据主键ID来排序的,主键ID是一定可以有序的,因为它是唯一的,所以每个表都会基于主键ID去创建一个这样的索引树,所以这个索引树也叫做主键索引树或者聚簇索引树 / 聚集索引树,并且这个树下的叶子节点会有我们完整的数据,也就是在创建表时,如果添加了主键,数据库就会默认创建主键索引,并且主键索引是所有索引当中性能最高的,因此我们现在根据主键去查询就很快了!
- 主键索引树是每个表都会有的,任何一个表,它都会有一个主键索引树,就算在创建表时没有添加主键,那么主键索引树也一定会有,如果没有主键,我们默认会用非空的唯一字段去做我们的主键索引树!
- 如果非空的唯一字段也没有,我们会有一个隐藏的字段,叫row_id,这个字段它是递增的!所以主键可以没有,但是主键索引树每个表它必有!
为什么MySQL用B+Tree,而MongoDB用BTree?
- InnoDB是MySQL的存储引擎,MySQL是一种关系型数据库;而MongoDB是非关系型数据库。
- 关系型数据库和非关系型数据库比较大的区别就是关系型数据库有大量的范围查询,而非关系型数据库基本上都是单条查询。
- 还有一个区别就是,InnoDB引擎下的MySQL的数据是存储在磁盘上的,而MongoDB的数据是存储在内存上的。
- 由于B+Tree的叶子节点之间通过双向指针链接进而形成了双向链表,而BTree的叶子节点之间没有指针连接,每个叶子节点独立存储数据项,所以B+Tree在范围查询时更加高效,因为B+Tree在范围查询时可以通过顺序遍历叶子节点来获取连续的数据,从而提高了查询的效率。
- 而BTree更适合内存存储和随机访问的场景,因为BTree的特点是叶子节点和非叶子借点都包含键值和数据信息,这种设计使得BTree在内存中的访问更加高效,因为BTree可能直接在根节点或二级目录中就找到了你想要的数据,也就是BTree可能在非叶子节点就查到对应的数据了,而B+Tree必须到叶子节点才可以。
- MongoDB在旧版本中用的确实是BTree,但是在MongoDB 3.2以后,已经采用WiredTiger作为默认的存储引擎了。
count(1)、count(*) 与 count(字段/列名) 的区别
- count(1)和count(*)表示的是直接查询符合条件的数据库表的行数,说白了count(1)与count(*)的统计结果中,会包含值为NULL的行数。
- 而count(列名)表示的是查询符合条件的列的值不为NULL的行数。
- 除了查询得到的结果集有区别之外,在性能方面count(*)是约等于count(1)的,但是count(*)是SQL92定义的标准统计行数的语法,因为它是标准语法,所以MySQL数据库对它进行过很多优化。
COUNT(*)和COUNT(1)
- 关于这两者的区别,网上的说法众说纷纭。
- 有的说count(*)在执行时会转换成count(1),所以count(1)少了转换步骤,所以更快。
- 还有的说,因为MySQL针对count(*)做了特殊优化,所以count(*)更快。
其实,这两种说法都不对,我们来看看MySQL官方文档是怎么说的:
- InnoDB handles SELECT COUNT(*) and SELECT COUNT(1) operations in the same way.There is no performance difference.
- InnoDB处理SELECT COUNT(*)和SELECT COUNT(1)操作的方式相同。没有性能上的差异。
既然MySQL对于COUNT(*)和COUNT(1)的优化是完全一样的,那建议用哪个呢?
- 建议使用COUNT(*)!因为这个是SQL92定义的标准统计行数的语法。
COUNT(字段/列名)
- COUNT(字段/列名)的查询就比较简单粗暴了,它是进行全表扫描,然后判断指定字段的值是不是为NULL,不为NULL则累加。
- 相比COUNT(*),COUNT(字段)多了一个步骤就是判断所查询的字段是否为NULL,所以它的性能要比COUNT(*)慢。