这篇博客是继《大语言模型之十二 SentencePiece扩充LLama2中文词汇》、《大语言模型之十三 LLama2中文推理》和《大语言模型之十四-PEFT的LoRA》
前面博客演示了中文词汇的扩充以及给予LoRA方法的预训练模型参数合并,并没有给出LoRA模型参数是如何训练得出的。
本篇博客将分析LoRA模型是和训练得到的。还是以7B参数量的模型为例。本篇博客依然基于Chinese-LLaMA-Alpaca-2开源项目。
pre-train
deepspeed
LLM的训练成本较大,需要昂贵的多卡多节点GPU集群,即使拥有集群GPU训练效率往往也达不到50%,各大小公司想要更轻松、快速、经济的训练和部署私有的LLM,微软开发的deepspeed框架就是一个高效、且易于使用的开源深度学习优化库。它可以通过多种技术方法来加速训练,包括模型并行化、梯度积累、动态精度缩放、本地模式混合精度等,此外,DeepSpeed还提供了一些辅助工具,如分布式训练管理、内存优化和模型压缩等,DeepSpeed基于Pytorch构建,迁移成本低,已经在很多项目和公司中得到应用,包括大语言模型、图像生成等。

2.1 ZeRO(零冗余优化器)
零冗余优化器(Zero Redundancy Optimizer,缩写为Zero)是一种用于大规模分布式深度学习的新型内存优化技术。ZeRO可以在当前一代GPU集群上以当前最佳系统吞吐量的三到五倍的速度训练具有1000亿个参数的深度学习模型。它还为训练具有数万亿参数的模型提供了一条清晰的道路,展示了深度学习系统技术的前所未有的飞跃。ZeRO作为DeepSpeed的一部分,用于提高显存效率和计算效率。
ZeRO可以克服数据并行和模型并行的局限性,同时实现两者的优点。通过在数据并行进程之间划分模型状态参数、梯度和优化器状态来消除数据并行进程中的内存冗余,而不是复制它们。在训练期间使用动态通信调度来在分布式设备之间共享必要的状态,以保持数据并行的计算粒度和通信量。
ZeRO的三个阶段以及对应功能。
ZeRO有三个主要的优化阶段(如下图所示),它们对应于优化器状态、梯度和参数的划分。
1.Optimizer State Partitioning(Pos):减少4倍内存,通信量与数据并行性相同
2.添加梯度分区(Pos+g):减少8倍内存,通信量与数据并行性相同
3.添加参数分区(Pos+g+p):内存减少与数据并行度Nd呈线性关系。例如,在64个GPU(Nd=64)之间进行拆分将产生64倍的内存缩减。通信量有50%的适度增长。
ZeRO消除了内存冗余,并使集群的全部聚合内存容量可用。在启用所有三个阶段的情况下,ZeRO可以在1024个NVIDIA GPU上训练万亿参数模型。像Adam这样具有16位精度的优化器的万亿参数模型需要大约16 TB的内存来保存优化器的状态、梯度和参数。16TB除以1024是16GB,这对于GPU来说是在合理的范围内的。
优化1: ZeRO2
它扩展了ZeRO-1,包括减少梯度内存占用,同时还添加了针对激活内存和碎片内存的优化。与ZeRO-1相比,ZeRO-2将DeepSpeed可以训练的模型大小增加了一倍,同时显著提高了训练效率。使用ZeRO-2,1000亿参数模型的训练速度可以比仅基于模型并行性的现有技术快10倍。
优化2:Zero-3 offload
ZeRO-3 offload是ZeRO Stage 3和ZeRO offload相结合的一种高效且易于使用的实施方式,旨在通过向每个人提供高效的大规模深度学习训练来实现人工智能民主化的持续目标。ZeRO-3 offload的主要好处是:
极高的内存效率,可以在有限的GPU资源上运行非常大的模型-例如,在单个GPU上具有超过40B的参数,在512个GPU上具有2万亿的参数的微调模型。
极易使用
扩展到超过一万亿个参数,而不需要以复杂的方式组合多种并行技术。
对于现有的DeepSpeed用户,只需在DeepSpeedConfig文件中使用几个标志即可打开ZeRO-3卸载。
每个GPU的高性能吞吐量和跨GPU的超线性可扩展性,用于分布式训练。
使用1万亿参数,ZeRO-3 Offload在512个NVIDIA V100 GPU上的计算性能可维持25 PetaFlops,实现49 TFlop/GPU。
Chinese-LLaMA-Alpaca-2
预训练的所有脚本都位于Chinese-LLaMA-Alpaca-2/scripts/training/目录下,这里仅仅解释相关代码的作用,由于需要的GPU资源较多,欢迎投喂高Memory资源的GPU资源。
#学习率
lr=2e-4
#这对应于大语言模型之十四-PEFT的LoRA中B和A矩阵的秩r
lora_rank=64
#这是超参数,用于控制学习的程度
lora_alpha=128
#这里显示了学习的参数量,可以和《大语言模型之七- Llama-2单GPU微调SFT》这里的设置对比一下
lora_trainable="q_proj,v_proj,k_proj,o_proj,gate_proj,down_proj,up_proj"
modules_to_save="embed_tokens,lm_head"
lora_dropout=0.05pretrained_model=../merged_chinese_llama_7b/
chinese_tokenizer_path=../tokenizer/
dataset_dir=../dataset
data_cache=temp_data_cache_dir
per_device_train_batch_size=1
gradient_accumulation_steps=8
block_size=512
output_dir=output_dir#deepspeed这里目的是单机多卡加速
deepspeed_config_file=ds_zero2_no_offload.jsontorchrun --nnodes 1 --nproc_per_node 1 run_clm_pt_with_peft.py \--deepspeed ${deepspeed_config_file} \--model_name_or_path ${pretrained_model} \--tokenizer_name_or_path ${chinese_tokenizer_path} \--dataset_dir ${dataset_dir} \--data_cache_dir ${data_cache} \--validation_split_percentage 0.001 \--per_device_train_batch_size ${per_device_train_batch_size} \--do_train \--seed 4 \--fp16 \--num_train_epochs 1 \--lr_scheduler_type cosine \--learning_rate ${lr} \--warmup_ratio 0.05 \--weight_decay 0.01 \--logging_strategy steps \--logging_steps 10 \--save_strategy steps \--save_total_limit 3 \--save_steps 200 \--gradient_accumulation_steps ${gradient_accumulation_steps} \--preprocessing_num_workers 8 \--block_size ${block_size} \--output_dir ${output_dir} \--overwrite_output_dir \--ddp_timeout 30000 \--logging_first_step True \--lora_rank ${lora_rank} \--lora_alpha ${lora_alpha} \--trainable ${lora_trainable} \--lora_dropout ${lora_dropout} \--modules_to_save ${modules_to_save} \--torch_dtype float16 \--load_in_kbits 16 \--gradient_checkpointing \--ddp_find_unused_parameters False
其运行之后生成tokenize化的数据集,其中的一段输出如下:
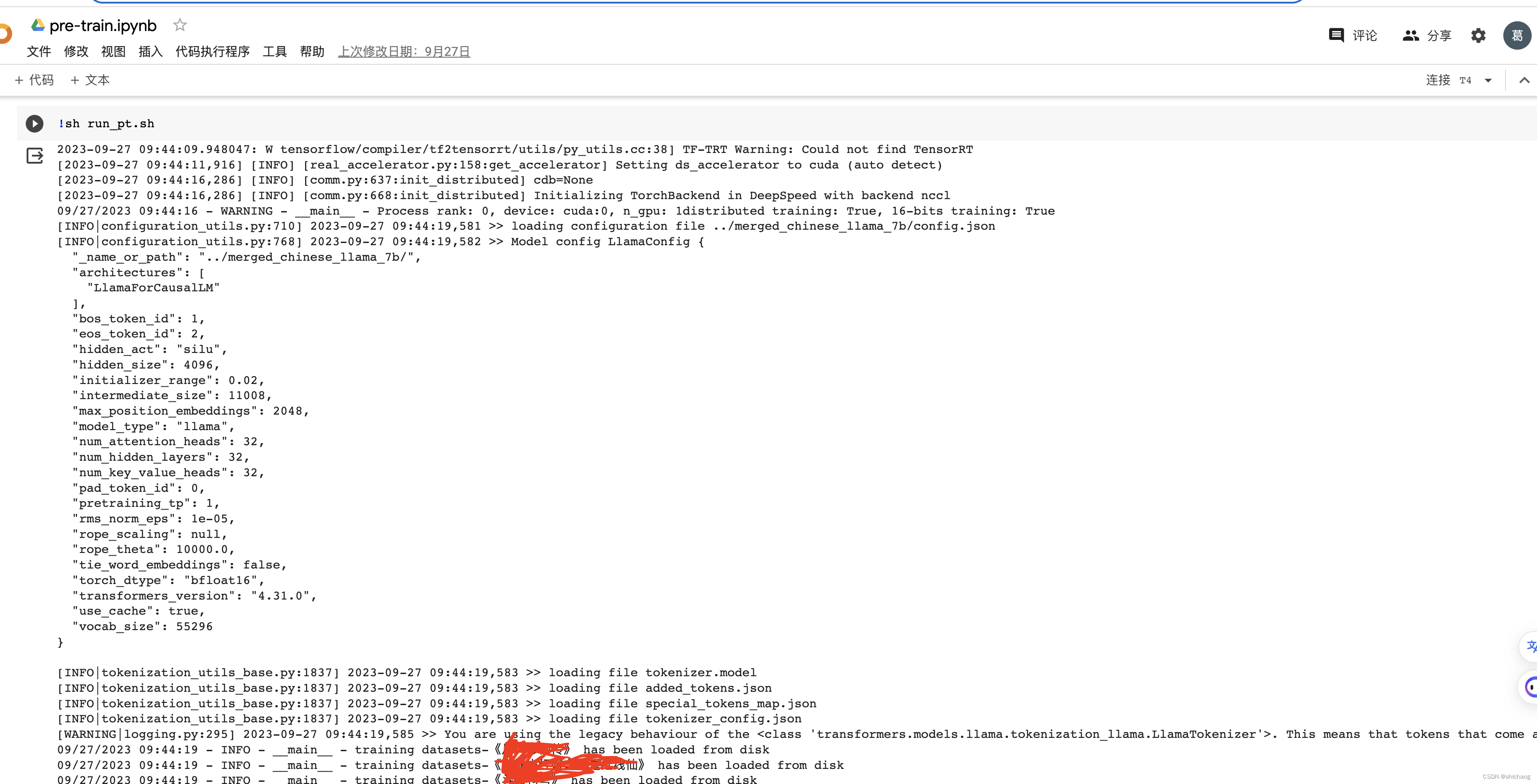
其上shell调用的python脚本是run_clm_pt_with_peft.py
with training_args.main_process_first(desc="dataset map tokenization and grouping"):lm_datasets = []path = Path(data_args.dataset_dir)files = [file.name for file in path.glob("*.txt")]if training_args.debug_mode is True:files = [files[0]]for idx, file in enumerate(files):data_file = os.path.join(path, file)filename = ''.join(file.split(".")[:-1])cache_path = os.path.join(data_args.data_cache_dir, filename+f"_{block_size}")os.makedirs(cache_path, exist_ok=True)try:processed_dataset = datasets.load_from_disk(cache_path, keep_in_memory=False)logger.info(f'training datasets-{filename} has been loaded from disk')except Exception:cache_dir = os.path.join(data_args.data_cache_dir, filename+f"_text_{block_size}")os.makedirs(cache_dir, exist_ok=True)raw_dataset = load_dataset("text", data_files=data_file, cache_dir=cache_dir, keep_in_memory=False)logger.info(f"{file} has been loaded")tokenized_dataset = raw_dataset.map(tokenize_function,batched=True,num_proc=data_args.preprocessing_num_workers,remove_columns="text",load_from_cache_file=True,keep_in_memory=False,cache_file_names = {k: os.path.join(cache_dir, 'tokenized.arrow') for k in raw_dataset},desc="Running tokenizer on dataset",)grouped_datasets = tokenized_dataset.map(group_texts,batched=True,num_proc=data_args.preprocessing_num_workers,load_from_cache_file=True,keep_in_memory=False,cache_file_names = {k: os.path.join(cache_dir, 'grouped.arrow') for k in tokenized_dataset},desc=f"Grouping texts in chunks of {block_size}",)processed_dataset = grouped_datasetsprocessed_dataset.save_to_disk(cache_path)if idx == 0:lm_datasets = processed_dataset['train']else:assert lm_datasets.features.type == processed_dataset["train"].features.typelm_datasets = concatenate_datasets([lm_datasets, processed_dataset["train"]])lm_datasets = lm_datasets.train_test_split(test_size = data_args.validation_split_percentage)
在生成好中文训练集之后,接下来是加载转换好的Huggingface模型,
device_map = {"":int(os.environ.get("LOCAL_RANK") or 0)}model = LlamaForCausalLM.from_pretrained(model_args.model_name_or_path,from_tf=bool(".ckpt" in model_args.model_name_or_path),config=config,cache_dir=model_args.cache_dir,revision=model_args.model_revision,use_auth_token=True if model_args.use_auth_token else None,torch_dtype=torch_dtype,low_cpu_mem_usage=True,device_map=device_map,load_in_4bit=load_in_4bit,load_in_8bit=load_in_8bit,quantization_config=quantization_config,)
模型加载好之后,设置PEFT训练参数,这些参数值来源于最开始的shell脚本。
logger.info("Init new peft model")target_modules = training_args.trainable.split(',')modules_to_save = training_args.modules_to_saveif modules_to_save is not None:modules_to_save = modules_to_save.split(',')lora_rank = training_args.lora_ranklora_dropout = training_args.lora_dropoutlora_alpha = training_args.lora_alphalogger.info(f"target_modules: {target_modules}")logger.info(f"lora_rank: {lora_rank}")peft_config = LoraConfig(task_type=TaskType.CAUSAL_LM,target_modules=target_modules,inference_mode=False,r=lora_rank, lora_alpha=lora_alpha,lora_dropout=lora_dropout,modules_to_save=modules_to_save)model = get_peft_model(model, peft_config)
紧接着就可以训练了
# Initialize our Trainertrainer = Trainer(model=model,args=training_args,train_dataset=train_dataset if training_args.do_train else None,eval_dataset=eval_dataset if training_args.do_eval else None,tokenizer=tokenizer,data_collator=fault_tolerance_data_collator,compute_metrics=compute_metrics if training_args.do_eval and not is_torch_tpu_available() else None,preprocess_logits_for_metrics=preprocess_logits_for_metricsif training_args.do_eval and not is_torch_tpu_available()else None,)trainer.add_callback(SavePeftModelCallback)# Trainingif training_args.do_train:checkpoint = Noneif training_args.resume_from_checkpoint is not None:checkpoint = training_args.resume_from_checkpointelif last_checkpoint is not None:checkpoint = last_checkpointtrain_result = trainer.train(resume_from_checkpoint=checkpoint)metrics = train_result.metricsmax_train_samples = (data_args.max_train_samples if data_args.max_train_samples is not None else len(train_dataset))metrics["train_samples"] = min(max_train_samples, len(train_dataset))trainer.log_metrics("train", metrics)trainer.save_metrics("train", metrics)trainer.save_state()
SFT和这里的预训练代码结构上非常相似,只是训练集变成有监督的了,因而差异主要在于有监督训练集的构建。这通过字典的方式获得的,具体代码见build_dataset.py
@dataclass
class DataCollatorForSupervisedDataset(object):"""Collate examples for supervised fine-tuning."""tokenizer: transformers.PreTrainedTokenizerdef __call__(self, instances: Sequence[Dict]) -> Dict[str, torch.Tensor]:input_ids, labels = tuple([instance[key] for instance in instances] for key in ("input_ids", "labels"))input_ids = torch.nn.utils.rnn.pad_sequence(input_ids, batch_first=True, padding_value=self.tokenizer.pad_token_id)labels = torch.nn.utils.rnn.pad_sequence(labels, batch_first=True, padding_value=-100)return dict(input_ids=input_ids,labels=labels,attention_mask=input_ids.ne(self.tokenizer.pad_token_id),)