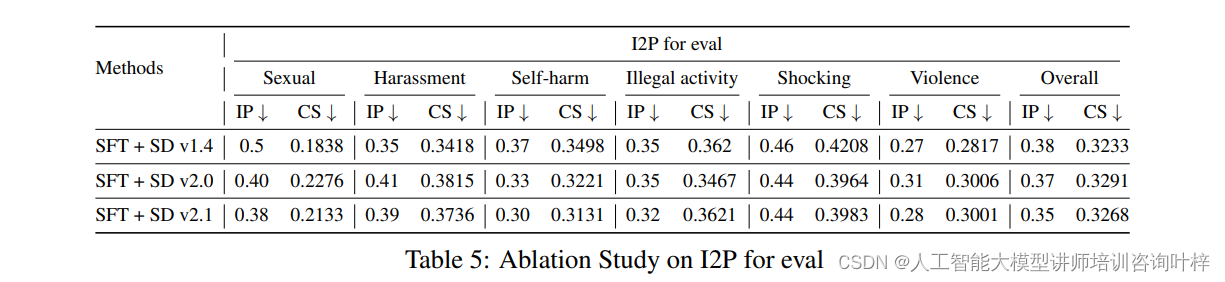
课题内容和要求
最小代价生成树的实现,分别以普利姆算法和克鲁斯卡尔算法实现最小代价生成树,并分析两种算法的适用场合。
数据结构说明
普利姆算法实现最小代价生成树的图采用邻接表存储结构,还有辅助数据结构,数组nearest,数组lowcost,数组mark。克鲁斯卡尔算法实现最小代价生成树的图采用邻接矩阵存储结构,其中还定义了辅助数据结构用于存放边。
算法设计
普利姆算法。
辅助数据结构说明:
(1)一维数组nearest,nearest[v]存放与v距离最近的顶点编号u,距离最近是指边(u,v)是所有与顶点v关联的边中权值最小的边。初始时,nearest[v] = -1.
(2)一维数组lowcost,lowcost[v]用于存放边(nearest[v],v)的权值。初始时lowcost[v]=INFINITY。INFINITY是假定的极大值。
(3)一维数组mark,mark[v]用于标记顶点v是否在生成树中,若mark[v]=0,表示顶点v未加入生成树;否则,表示v已加入生成树。初始时,mark[v]=0。
算法步骤:
(1)分别将数组nearest,lowcost,mark初始化并将源点加入生成树。
(2)循环n-1次,重复以下操作。
a.查找顶点k的未加入生成树的所有邻接顶点j,若边(k,j)的权值比lowcost[j]小,则将lowcost[j]更新为此权值,并令lowcost[j]=k。
b.在未加入生成树的顶点中,查找具有最小lowcost的顶点k。
c.将k加入生成树。
克鲁斯卡尔算法。
辅助数据结构说明:
(1)一维数组Edge,从邻接矩阵中获取所有边以及边对应的顶点保存在数组Edge中,并且采用排序算法对边按照权值递增排序。
(2)一维数组parent,用于标识各个顶点所属的连通分量,若两个顶点属于不同的连通分量,则将这两个顶点关联的边加入到生成树中。parent[i]表示顶点i所属的连通分量,初始时parent[i]=i,表示各顶点自成一个连通分量。
算法步骤:
(1)从邻接矩阵中获取所有边存储于数组Edge。
(2)调用快速排序对数组Edge边按权值从小到大排序
(3)变量k表示当前构造的最小代价生成树中的边数,其初始值为0,若k<n-1,则循环执行以下操作。
a.依次从Edge中取出边(u,v)
对u和v所在连通分量paren[u]和parent[v]进行判断,若两者不相等,表示两顶点属于不同连通分量,输出此边,并合并paren[u]和parent[v]两个连通分量;若paren[u]和parent[v]相等,表示属于同一连通分量,舍去此边而选择下一条最小的边。
详细设计
普利姆算法生成最小代价生成树文件Prim_main.c、Prim.c、Prim.h
Prim_main.c
#include <stdio.h>
#include <stdlib.h>
#include "Prim.h"
int main()
{// 以下为图例1LGraph *lg = (LGraph *)malloc(sizeof(LGraph));if (!Init(lg, 6)){printf("邻接表初始化失败\n");return 0;}// 定义边集数组然后利用循环加入到图中int e[18][3] = {{0, 1, 10}, {1, 0, 10}, {1, 4, 2}, {4, 1, 2}, {4, 3, 9}, {3, 4, 9}, {0, 5, 4}, {5, 0, 4}, {4, 5, 7}, {5, 4, 7}, {0, 2, 7}, {2, 0, 7}, {2, 5, 6}, {5, 2, 6}, {3, 5, 5}, {5, 3, 5}, {2, 3, 8}, {3, 2, 8}};for (int i = 0; i < 18; i++){if (!Insert(lg, e[i][0], e[i][1], e[i][2])){printf("边插入失败\n");return 0;}}int nearest[6] = {0};int lowcost[6] = {0};if (!Prim(0, nearest, lowcost, *lg)) // 构造最小生成树,以结点0为源点{printf("最小生成树构造失败\n");}printf("图例1最小代价生成树的边集如下:\n");int sum = 0; // 计算最小权值之和for (int i = 0; i < lg->n; i++) // 输出最小代价生成树的边集{printf("(%d,%d,%d) ",nearest[i],i,lowcost[i]);sum+=lowcost[i];}printf("\n最小权值和为%d\n",sum);// 以上为图例1printf("----------------------------\n");// 以下为图例2LGraph *lg_2 = (LGraph *)malloc(sizeof(LGraph));if (!Init(lg_2, 6)){printf("邻接表初始化失败\n");return 0;}// 定义边集数组然后利用循环加入到图中int e_2[20][3] = {{0, 1, 6}, {1, 0, 6}, {0, 2, 1}, {2, 0, 1}, {0, 3, 5}, {3, 0, 5}, {1, 2, 5}, {2, 1, 5}, {2, 3, 5}, {3, 2, 5}, {1, 4, 3}, {4, 1, 3}, {3, 5, 2}, {5, 3, 2}, {2, 4, 6}, {4, 2, 6}, {2, 5, 4}, {5, 2, 4}, {4, 5, 6}, {5, 4, 6}};for (int i = 0; i < 20; i++){if (!Insert(lg_2, e_2[i][0], e_2[i][1], e_2[i][2])){printf("边插入失败\n");return 0;}}int nearest_2[6] = {0};int lowcost_2[6] = {0};if (!Prim(0, nearest_2, lowcost_2, *lg_2)) // 构造最小生成树,以0为源点{printf("最小生成树构造失败\n");}printf("图例2最小代价生成树的边集如下:\n");sum = 0;for (int i = 0; i < lg_2->n; i++) // 输出最小代价生成树的边集{printf("(%d,%d,%d) ",nearest_2[i],i,lowcost_2[i]);sum+=lowcost_2[i];}printf("\n最小权值和为%d\n",sum);printf("输入回车结束程序。\n");getchar();Destroy(lg);Destroy(lg_2);
}
Prim.h
#ifndef __PRIM_H__
#define __PRIM_H__
typedef struct eNode // 边结点
{int adjVex; // 顶点vint w; // 点u与点v之间的权值struct eNode *nextArc; // 指向下一个结点
} ENode;
typedef struct lGraph // 邻接表
{int n; // 图顶点数int e; // 图边数ENode **a; // 指向一维指针的数组
} LGraph;
#define INFINITY 65535 // 假定一个无限值int Init(LGraph *lg, int nSize); // 邻接表初始化
void Destroy(LGraph *lg); // 邻接表的撤销
int Exist(LGraph *lg, int u, int v); // 边搜索
int Insert(LGraph *lg, int u, int v, int w); // 边插入
int Prim(int k, int *nearest, int *lowcost, LGraph g); // 普利姆算法
#endif
Prim.c
#include "Prim.h"
#include <stdlib.h>
#include <stdio.h>
/*** @brief 邻接表初始化* @param lg 指向邻接表的指针* @param nSize 顶点个数* @return 0,初始化失败;1,初始化成功
*/
int Init(LGraph *lg, int nSize)
{lg->n = nSize;lg->e = 0;lg->a = (ENode **)malloc(nSize * sizeof(ENode *)); // 动态生成长度为n的一维指针数组if (!lg->a) // 判断空间申请是否成功{return 0; // 申请空间失败}else{for (int i = 0; i < lg->n; i++){lg->a[i] = NULL; // 将指针数组a置空}return 1; // 申请空间成功}
}
/*** @brief 邻接表的撤销* @param lg 指向邻接表的指针* @return void
*/
void Destroy(LGraph *lg)
{int i;ENode *p,*q;for(i = 0;i<lg->n;i++){p = lg->a[i];q=p;while(p){p = p->nextArc;free(q);q=p;}}free(lg->a);
}
// 边搜索
/*** @brief 边搜索* @param lg 指向邻接表的指针* @param u 边的始点* @param v 边的终点* @return 0,搜索失败或顶点有误;1,搜索成功
*/
int Exist(LGraph *lg, int u, int v)
{ENode *p = NULL;if(u<0||v<0||u>lg->n-1||v>lg->n-1||u==v){return 0; // 判断顶点是否有误}p=lg->a[u];while(p&&p->adjVex != v){p = p->nextArc;}if(!p){return 0; // 未找到边}else{return 1; // 找到边}
}
// 边插入
/*** @brief 边插入* @param lg 指向邻接表的指针* @param u 边的始点* @param v 边的终点* @param w 边的权值* @return 0,插入失败或边已存在;1,插入成功
*/
int Insert(LGraph *lg, int u, int v, int w)
{ENode *p = NULL;if(u<0||v<0||u>lg->n-1||v>lg->n-1||u==v){return 0; // 判断顶点是否有误}if(Exist(lg,u,v)){printf("边已存在。\n");return 0;}p = (ENode*)malloc(sizeof(ENode)); // 为新结点分配空间p->adjVex = v;p->w = w;// 将新结点插入单链表的最前面,头插p->nextArc = lg->a[u]; lg->a[u] = p;lg->e++;return 1;
}
// 普利姆算法
/*** @brief 普利姆算法生成最小代价生成树* @param k 源点* @param nearest 存放顶点的最近顶点编号* @param lowcost 存放顶点距离最近点的距离* @param g 邻接表* @return 0,失败;1,成功
*/
int Prim(int k, int *nearest, int *lowcost, LGraph g)
{ENode *p;int i,j;int *mark = (int*)malloc(g.n*sizeof(int)); // 辅助数组if(k<0||k>g.n-1) // 判断源点是否有效{return 0;}for(i = 0;i<g.n;i++) // nearest数组,lowcost数组和mark数组初始化{nearest[i] = -1;lowcost[i] = INFINITY;mark[i]=0; // 赋值为1表示结点加入生成树,0表示未加入}// 源点k加入生成树lowcost[k] = 0;nearest[k]=k;mark[k] = 1;for(i = 1;i<g.n;i++) // 将其余n-1条边加入生成树{for(p = g.a[k];p;p = p->nextArc) // 更新生成树外的顶点lowcost值{j=p->adjVex;if((!mark[j])&&(lowcost[j]>p->w)){lowcost[j] = p->w;nearest[j] = k;}}int min = INFINITY;for(j = 0;j<g.n;j++) // 找生成树外顶点中具有最小lowcost值的顶点k{if((!mark[j])&&(lowcost[j]<min)){min = lowcost[j];k = j;}}mark[k]=1; // 将顶点k加入生成树}return 1;
}
克鲁斯卡尔算法生成最小代价生成树文件Kruskal_main.c、Kruskal.h、Kruskal.c
Kruskal_main.c
#include <stdio.h>
#include <stdlib.h>
#include "Kruskal.h"
int main()
{// 图例1MGraph *mg = (MGraph*)malloc(sizeof(MGraph));if(!Init(mg,6)){printf("邻接矩阵初始化失败\n");}// 定义边集数组然后利用循环加入到图中int e[9][3] = {{0,1,10},{1,4,2},{0,2,7},{0,5,4},{4,5,7},{3,4,9},{2,5,6},{3,5,5},{2,3,8}};for(int i = 0;i<9;i++){if(!Insert(mg,e[i][0],e[i][1],e[i][2])){printf("边插入失败\n");}}Edge *edg = (Edge*)malloc(mg->e*sizeof(Edge)); // 辅助数据结构,存放边集int k = 0;for(int i = 0;i<mg->n;i++){for(int j = 0; j<i;j++){if(mg->a[i][j]!=0&&mg->a[i][j]!=INFINITY){edg[k].u = i;edg[k].v = j;edg[k].w = mg->a[i][j];k++;}}}int sum = 0; // 计算最小代价生成树权值和printf("图例1最小代价生成树的边集如下:\n");Kruskal(mg,edg,&sum);printf("\n最小代价生成树权值和为:%d\n",sum);// 以上为图例1printf("-------------------------\n");// 以下为图例2MGraph *mg_2 = (MGraph*)malloc(sizeof(MGraph));if(!Init(mg_2,6)){printf("邻接矩阵初始化失败\n");}// 定义边集数组然后利用循环加入到图中int e_2[10][3] = {{0,1,6},{0,2,1},{0,3,5},{1,2,5},{2,3,5},{1,4,3},{2,4,6},{2,5,4},{3,5,2},{4,5,6}};for(int i = 0;i<10;i++){if(!Insert(mg_2,e_2[i][0],e_2[i][1],e_2[i][2])){printf("边插入失败\n");}}Edge *edg_2 = (Edge*)malloc(mg_2->e*sizeof(Edge));k = 0;for(int i = 0;i<mg_2->n;i++){for(int j = 0; j<i;j++){if(mg_2->a[i][j]!=0&&mg_2->a[i][j]!=INFINITY){edg_2[k].u = i;edg_2[k].v = j;edg_2[k].w = mg_2->a[i][j];k++;}}}sum = 0; // 计算最小代价生成树权值和printf("图例2最小代价生成树的边集如下:\n");Kruskal(mg_2,edg_2,&sum);printf("\n最小代价生成树权值和为:%d\n",sum);printf("输入回车结束程序。\n");getchar();Destroy(mg);Destroy(mg_2);
}
Kruskal.h
#ifndef __KRUSKAL_H__
#define __DRUSKAL_H__
typedef struct mGraph
{int **a; // 邻接矩阵int n; // 图的顶点数int e; // 图的边数
} MGraph;
typedef struct edge // 辅助数据结构,保存邻接矩阵的边
{int u; // 边的始点int v; // 边的终点int w; // 边的权值
} Edge;
#define INFINITY 65535 // 假定一个最大值,给边赋值表示顶点间不可达
int Init(MGraph *mg, int nSize); // 邻接矩阵初始化
void Destroy(MGraph *mg); // 邻接矩阵的撤销
int Insert(MGraph *mg, int u, int v, int w); // 边插入
int FindParent(int *parent, int a); // 查结点树根
void Swap(Edge *edg, int i, int j); // 交换函数
int Partition(Edge *edg, int left, int right); // 分划函数
void QuickSort(Edge *edg, int left, int right); // 快速排序
void Kruskal(MGraph *mg, Edge *edg,int *sum); // 克鲁斯卡尔算法生成最小代价生成树
#endif
Kruskal.c
#include <stdio.h>
#include <stdlib.h>
#include "Kruskal.h"
/*** @brief 邻接矩阵初始化* @param mg 指向待初始化的矩阵指针* @param nSize 顶点数* @return 0,初始化失败;1,初始化成功
*/
int Init(MGraph *mg, int nSize)
{mg->n = nSize; // 初始化顶点数mg->e = 0;mg->a = (int**)malloc(nSize*sizeof(int*));if(!mg->a){return 0; // 初始化失败}for(int i = 0;i<mg->n;i++) // 循环初始化每条边{mg->a[i] = (int*)malloc(nSize*sizeof(int));for(int j = 0; j<mg->n; j++){mg->a[i][j] = INFINITY;}mg->a[i][i] = 0;}return 1; // 初始化成功
}
/*** @brief 邻接矩阵的撤销* @param mg 指向待撤销的矩阵的指针* @return void
*/
void Destroy(MGraph *mg)
{for(int i = 0; i<mg->n; i++){free(mg->a[i]);}free(mg->a);
}
/*** @brief 边插入 * @param mg 指向待邻接矩阵的指针* @param u 要插入边的始点* @param v 要插入边的终点* @param w 边的权值* @return 0,插入失败或边已存在;1,边插入成功
*/
int Insert(MGraph *mg, int u, int v, int w)
{if(u<0||v<0||u>mg->n-1||v>mg->n-1||u==v){return 0; // 插入失败}if(mg->a[u][v] != INFINITY){printf("边已存在\n");return 0;}mg->a[u][v] = w; // 插入新边mg->a[v][u] = w;mg->e++;return 1; // 插入成功
}
/*** @brief 查找顶点的树根* @param parent 存放所有结点树根的数组* @param a 待查找树根的结点* @return 返回a的树根
*/
int FindParent(int *parent,int a)
{int t = a;while(t != parent[t]){t = parent[t];}return t;
}
/*** @brief 交换函数* @param edg 存放边以及边相关信息的数组* @param i 数组下标* @param j 数组下标* @return void
*/
void Swap(Edge *edg,int i, int j)
{Edge tmp;tmp = edg[i];edg[i] = edg[j];edg[j] = tmp;
}
/*** @brief 分划函数,由快速排序调用* @param edg 存放边以及边相关信息的数组* @param left 数组下标,左边界* @param right 数组下标,右边界* @return j,快速排序分划元素的下标
*/
int Partition(Edge *edg,int left,int right)
{int i = left;int j = right+1;do{do{i++;}while(edg[i].w<edg[left].w);do{j--;} while(edg[j].w>edg[left].w);if(i<j){Swap(edg,i,j);}}while(i<j);Swap(edg, left, j);return j;
}
/*** @brief 快速排序* @param edg 存放边以及边相关信息的数组* @param left 数组下标,左边界* @param right 数组下标,右边界* @return void
*/
void QuickSort(Edge *edg, int left, int right)
{if(left<right){int j = Partition(edg, left, right);QuickSort(edg, left, j-1);QuickSort(edg, j+1,right);}
}
/*** @brief 克鲁斯卡尔算法生成最小代价生成树* @param mg 指向邻接矩阵的指针* @param edg 存放边以及边相关信息的数组* @param sum 计算最小代价生成树权值之和* @return void
*/
void Kruskal(MGraph *mg, Edge *edg,int *sum)
{int u1,v1; // 记录顶点的根结点int *parent = (int*)malloc(mg->n*sizeof(int)); // 记录所有顶点的根结点,用于判断选取的边是否使生成的树构成回路for(int i = 0;i<mg->n;i++) // 初始化使每个顶点的根结点为自己{parent[i] = i;}QuickSort(edg, 0, mg->e-1); // 将保存边的数组按权值由小到大排序int count = 0;for(int i = 0;i<mg->e;i++){u1 = FindParent(parent,edg[i].u); // 查找顶点的根结点v1 = FindParent(parent,edg[i].v);if(u1 != v1) // 根结点不同,表示不属于同一颗树{count++;parent[u1] = v1; // 合并根节点printf("(%d,%d,%d) ",edg[i].u,edg[i].v,edg[i].w); // 输出属于最小生成树的边集*sum += edg[i].w;}if(count == mg->n-1) // 最小生成树边数e等于顶点数n-1,提前退出{break;}}
}
测试数据及其结果分析
普利姆算法生成最小代价生成树图例1


图例2


程序运行结果:

克鲁斯卡尔算法生成最小代价生成树图例1


图例2


程序运行结果:

总结
由普利姆算法的时间复杂度O(n2),普利姆算法更适合当图中边的数量远大于点的数量的情形,在电路设计中可以应用于印刷电路板的布线问题以减少导线长度。由克鲁斯卡尔算法的时间复杂度O(eloge),克鲁斯卡尔算法更适合当图中点的数量远大于边的数量的情形,与普利姆算法类似,也可以用于优化连接路径的问题。