|  |
|---|
介绍
K-D树是一种二叉树的数据结构,其中每个节点代表一个k维点,可用于组织K维空间中的点,其中K通常是一个非常大的数字。二叉树结构允许对多维空间中的点进行非常有效的搜索,包括最近邻搜索和范围搜索,树中的每个非叶节点都充当一个超平面,将空间分割为两个区域。 这个超平面垂直于所选的轴,该轴与K维相关联。
而区域在划分时,有不同的选择轴的策略
划分轴策略
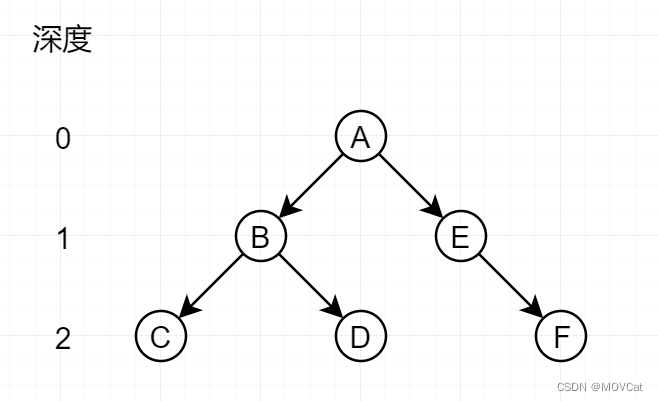
1.按深度划分
说明:
重复地循环K维中的每一个轴,并选择沿着它的中点来划分空间。例如,对于具有和轴的二维点xy,我们首先沿着x-轴进行分割,然后是y-轴,然后再次是-x轴,(即偶数深度的x-轴分割,奇数深度y-轴分割)以这种方式继续,直到所有点都被考虑在内:
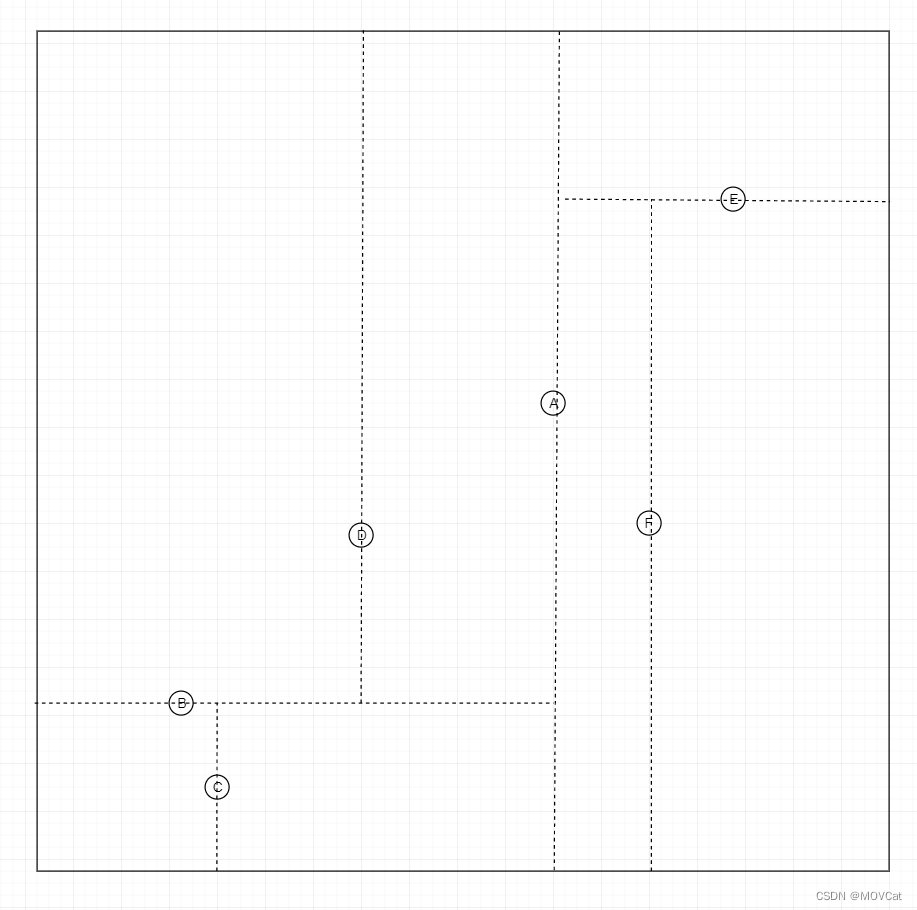
范例:
已有位置数据:Vector2[] position = {A,B,C,D,E,F} ,将其进行空间划分
- 第一次分割:深度 0 ,Y 轴分割 A
- 第二次分割:深度 1 ,X 轴分割 B
- 第三次分割:深度 2 ,Y 轴分割 C
- 第四次分割:深度 2 ,Y 轴分割 D
- 第五次分割:深度 1 ,X 轴分割 E
- 第六次分割:深度 2 ,Y 轴分割 F
 |  |
|---|---|
 | 这种方式会有一种问题 --二叉树不平衡(当树的深度很深时很影响效率,就必须将树进行重新排序) |
2.以K维中的最大包围边划分
- 这里还有不同的策略,有的是按最大密度边有的是按最长边,这里的是按最长边;
每一次分割空间以按内部元素的包围盒最大的那一边的中点位置进行分割,直至分割到一个区域内只有一个对象
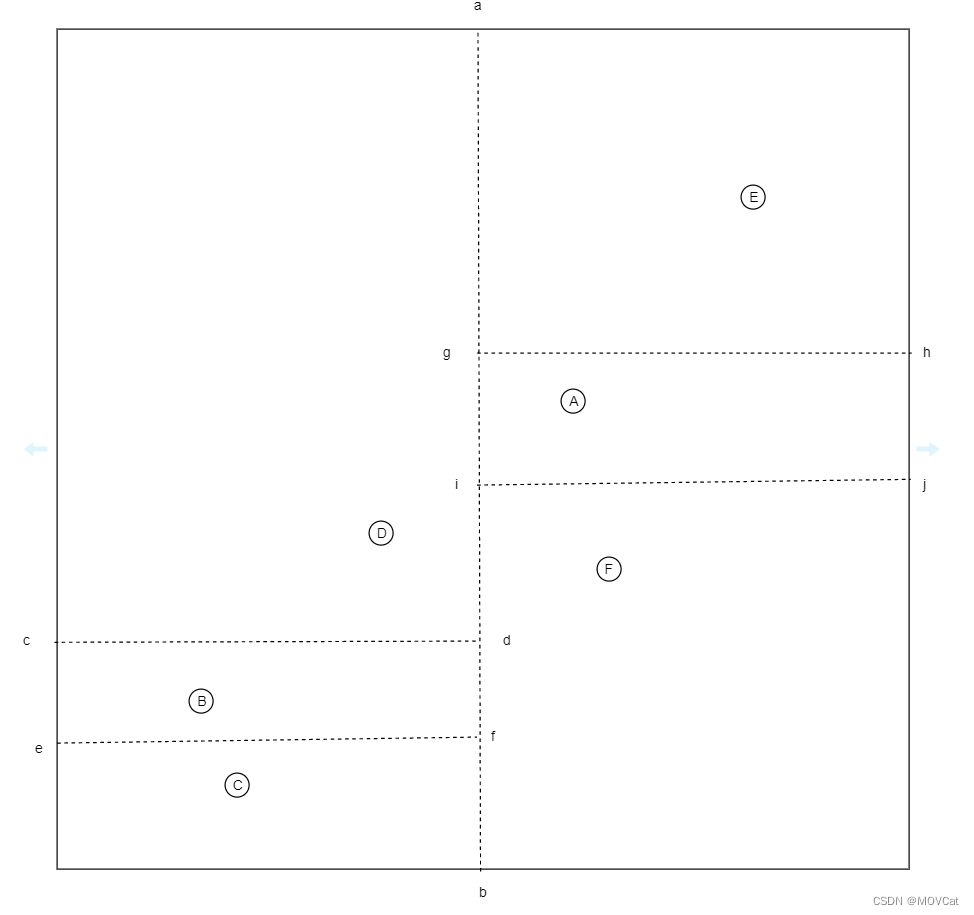
已有位置数据:Vector2[] position = {A,B,C,D,E,F} ,将其进行空间划分
- 第一次分割:(A,B,C,D,E,F)其包围盒的X边 > Y边,以(E.x-B.x)/2的位置划分为 ab
- 第二次分割:(B,C,D)其包围盒的X边 < Y边,以(D.y-C.x)/2的位置划分为 cd
- 第三次分割:(B,C)其包围盒的X边 < Y边,以(B.y-C.x)/2的位置划分为 ef
- 第四次分割:(A,E,F)其包围盒的X边 < Y边,以(E.y-F.x)/2的位置划分为 gh
- 第五次分割:(A,F)其包围盒的X边 < Y边,以(A.y-F.x)/2的位置划分为 ij
 |  |
|---|---|
 | 这种二叉树就很平衡,因为每次划分后都需要将<位置数据>进行重新排序,而树则不用管;在左图中可直接看出每次划分都将原始数据进行了拆分,直至最后拆分到一个区域只有一个对象时停止 |
算法实现
这里采用的是第二种空间分割策略 【以K维中的最大包围边划分】
这里有两个问题要说明一下
1. “位置数据”的多少与树的总节点数的关系
因为位置数据会实时变动(数组长度不变,仅是里面的数据元素值在变化,暂不考虑动态长度的数组在二叉树中的求解),所以二叉树也很会随之频繁的重新构建,那么构建就必须足够的轻量化(无CG),进而需要一个固定的数组容器来存放树节点

因为我们设定的是最极端的情况,一个叶子节点所对应的空间内最多X个对象(X == 1)
所以可用一个满的二叉树去计算,那么其总节点数与叶子节点比关系为 2N-1 :N
那么存放树节点的容器长度就为“位置数据”长度的2倍-1
2. 一个叶子节点所对应的空间内最多X个对象
这一点如果真的采用 X == 1 的方式那可就太浪费了,因为对象数可能会很密集,放在同一个区域内的话岂不是能更快的查找?所以 X 的值的大小的增加会减少树的深度,那么树查找也就快了;但X 值的增加也会同时增大空间分割的区域导致不能更快的定位位置,所以必须要找到一个平衡;
这和分割策略有很大的影响,最理想的分割情况就是按区域内的成员密度进行分割,这样的二叉树与叶子内对象分布最合理(但更复杂,暂不谈论)
| / | 树深度 | 叶子内对象 |
|---|---|---|
| X 增大 | 减小(树遍历加快) | 增大(对象定位减慢) |
| X 减小 | 增大(树遍历减慢) | 减少(对象定位加快) |
代码示例
namespace Test.KDTree
{public class KDTree{//树节点 --用于分割空间与记录容纳对象private struct AgentTreeNode{// [begin,end) 是代理容器内的一段区间范围,表示该节点内的对象internal int begin;internal int end;internal int left; //左分支索引internal int right; //右分支索引// 该节点的 AABB 包围盒范围,包围的就是 [begin,end] 成员的最大范围internal Vector2 min;internal Vector2 max;public float LengthX => max.x - min.x;public float LengthY => max.y - min.y;public float CenterX => (max.x + min.x)*0.5f;public float CenterY => (max.y + min.y)*0.5f;//返回该节点下的对象个数public int Count => end - begin;//返回position距离包围盒的距离平方,如果在包围盒内(含边框)返回0;public float SqrDisBounds(Vector2 p){return sqr(Math.Max(0.0f, min.x - p.x)) + sqr(Math.Max(0.0f, min.y - p.y)) + sqr(Math.Max(0.0f, p.x - max.x)) + sqr(Math.Max(0.0f, p.y - max.y));}float sqr(float scalar){return scalar * scalar;}}//二叉树要分割的对象代理(要与游戏中的对象解耦)public struct Agent{public int id; //游戏中的对象IDpublic Vector2 position; //游戏中的对象位置}//节点内容纳的最大对象数private const int MAX_LEAF_SIZE = 10;private Agent[] agents_; //代理对象容器private AgentTreeNode[] agentTree_; //代理节点容器//通过游戏中的对象数量初始化容器大小public void InitAgentCapacity(int count){agents_ = new Agent[count];agentTree_ = new AgentTreeNode[2 * agents_.Length-1];}//添加代理public void AddAgent(int id){agents_[id].id = id;}//构建二叉树public void buildAgentTree(){//更新对象代理成员的位置数据for (int i = 0; i < agents_.Length; ++i){agents_[i].position = getAgentPosition(agents_[i].id);}buildAgentTreeRecursive(0, agents_.Length, 0);}//递归构建二叉树private void buildAgentTreeRecursive(int begin, int end, int node){agentTree_[node].begin = begin;agentTree_[node].end = end;agentTree_[node].min = agentTree_[node].max = agents_[begin].position;//计算该节点的Boundsfor (int i = begin + 1; i < end; ++i){agentTree_[node].max = Vector2.Max(agentTree_[node].max, agents_[i].position);agentTree_[node].min = Vector2.Min(agentTree_[node].min, agents_[i].position);}//当现有对象大于<最大对象数>时才进行分割,也说明其不是叶子节点if (end - begin > MAX_LEAF_SIZE){//是否是垂直定向的bool isVertical = agentTree_[node].LengthX > agentTree_[node].LengthY;//定向的中间位置float splitValue = isVertical ? agentTree_[node].CenterX : agentTree_[node].CenterY;int left = begin; //在对象容器[begin,end]内的包含范围起始索引int right = end; //在对象容器[begin,end]内的包含范围结束索引//根据中间位置将对象容器[begin,end]进行重排序//将小于中间位置的放置在容器[begin,end]左边;将大于等于中间位置的放置在容器[begin,end]右边;while (left < right){while (left < right && (isVertical ? agents_[left].position.x : agents_[left].position.y) < splitValue) ++left;while (right > left && (isVertical ? agents_[right - 1].position.x : agents_[right - 1].position.y) >= splitValue) --right;if (left < right){Agent tempAgent = agents_[left];agents_[left] = agents_[right - 1];agents_[right - 1] = tempAgent;++left;--right;}}//获取容器[begin,end]左边(小于中间位置的对象)的数量int leftSize = left - begin;//因为与中间值比较时等于的部分放置在了右边,所以会出现左边无成员的情况(通常是有大量重叠),就让右边给左边让一个出来(其实你都全重叠到一个点上了,不让也可以,反正这时的二叉树时不可能平衡的)if (leftSize == 0){++leftSize;++left;++right;}//这里的二叉树存储结构时按照容器[begin,end]的左边数量进行决定该节点右分支的放置位置,这样在满二叉树的状态下,一个叶子节点对应一个对象agentTree_[node].left = node + 1;agentTree_[node].right = node + 2 * leftSize;//left 和 right 将容器[begin,end]划分为了两块,这里让其递归计算其自身的分块buildAgentTreeRecursive(begin, left, agentTree_[node].left);buildAgentTreeRecursive(left, end, agentTree_[node].right);}}public Func<int, Vector2> getAgentPosition; //获取指定代理对象的位置public Action<int> call_Near;//迭代查询指定位置下给定半径中的所有对象//rangeSq 为半径的平方,为的是在计算两点位置时不用进行开根号处理public void queryAgentTreeRecursive(Vector2 position_, float rangeSq, int node){//表示其为叶子节点,可直接进行包含对象遍历if (agentTree_[node].Count <= MAX_LEAF_SIZE){for (int i = agentTree_[node].begin; i < agentTree_[node].end; ++i){if (Vector2.SqrMagnitude(agents_[i].position - position_) < rangeSq){call_Near(agents_[i].id);}}}else{//每个节点下都有两个分支,可二分查找最近的区域float distSqLeft = agentTree_[agentTree_[node].left].SqrDisBounds(position_);float distSqRight = agentTree_[agentTree_[node].right].SqrDisBounds(position_);if (distSqLeft < distSqRight){if (distSqLeft < rangeSq) //left区域是否在半径内,right 比left大就没必要else了{queryAgentTreeRecursive(position_, rangeSq, agentTree_[node].left);if (distSqRight < rangeSq) //left right 都在半径范围内时,right也要考虑{queryAgentTreeRecursive(position_, rangeSq, agentTree_[node].right);}}}else{if (distSqRight < rangeSq){queryAgentTreeRecursive(position_, rangeSq, agentTree_[node].right);if (distSqLeft < rangeSq){queryAgentTreeRecursive(position_, rangeSq, agentTree_[node].left);}}}}}}
}