曾几何时,“并发高就分库,数据大就分表”已经成了处理 MySQL 数据增长问题的圣经。
面试官喜欢问,博主喜欢写,候选人也喜欢背,似乎已经形成了一个闭环。
但你有没有思考过,分库分表真的适合你的系统吗?
分表
在业务刚刚发展起来的时候,流量全部达到了一个 MySQL 上,用户信息全落到了 user 表。

后来,user 表的数据量越来越大了。
于是,你做了一次垂直拆分,将原来的 user 表拆分成了新的 user 表和 user_details 表。
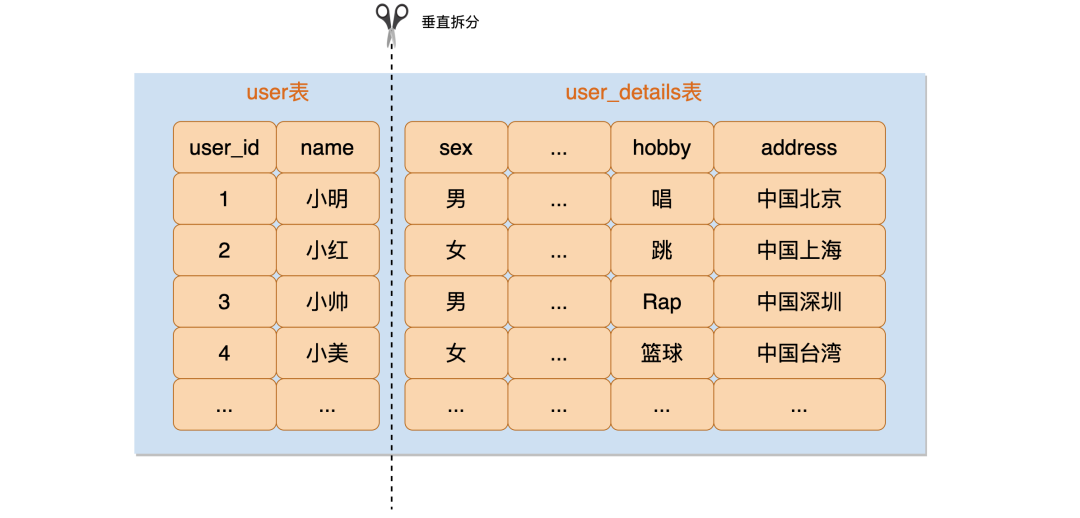
这样一拆之后,用户的信息分散到两个表,user 表面的数据量一下就变小了,user 表面数据量过大的问题暂时就解决了。
但随着业务的发展,线上的流量越来越大,单个 MySQL 已经扛不住流量的压力了。
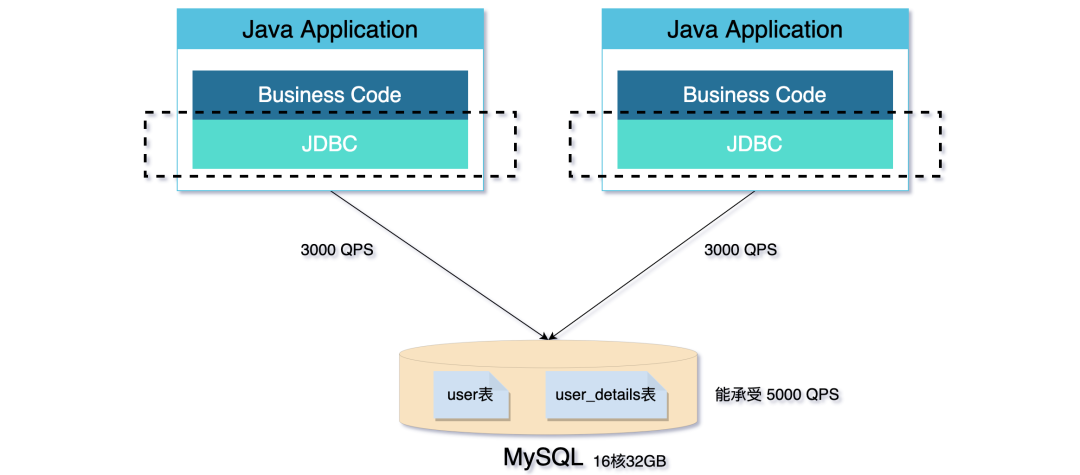
当个库承受不住压力的时候,就需要分库了。
分库
顾名思义,分库就是将一个库拆成多个库,让多个库分担流量的压力。
拆成多个库也意味着进行了分表,也就是说分库一定分表,分表不一定分库。
我们可以根据偏应用还是偏 DB,将分库分表的实现方式分成三种类型:
- JDBC 代理模式
- DB 代理模式
- Sharding On MySQL 的 DB 模式
JDBC 代理模式
JDBC 代理模式是一种无中心化的架构模式。ShardingSphere-JDBC 就是 JDBC 代理模式的典型实现。
通常以 jar 包括提供服务,让客户端直连数据库,这种模式无需额外部署和依赖,可理解为增强版的 JDBC 驱动。
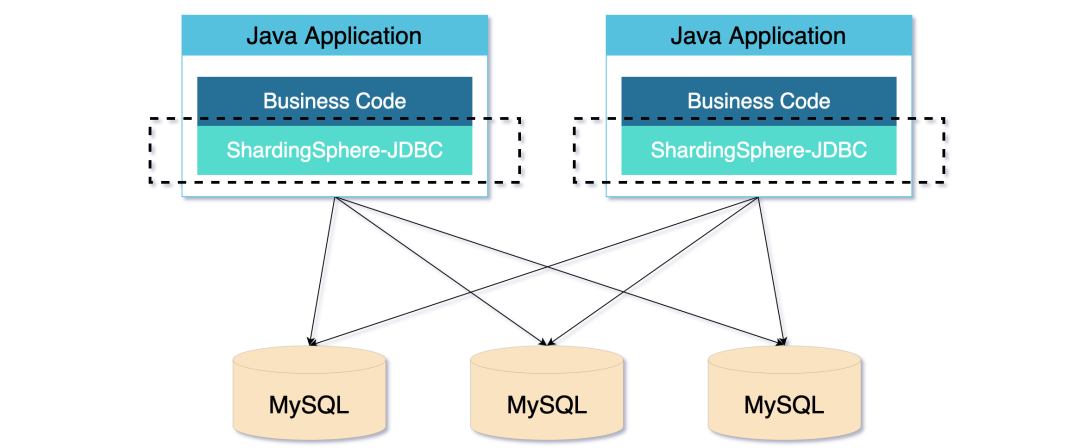
JDBC 代理模式虽然简单,但违背了 DB 透明的原则,侵入性比较高,需要针对不同的语言编写不同的 Driver。
美团的 Zebra、MTDDL,阿里 TDDL 都是基于这种模式的实现。
DB 代理模式
DB 代理模式是中心化的架构模式。ShardingSphere-Proxy 就是 DB 代理模式的经典实现。
这种模式旨在实现透明化的数据库代理端,并独立于应用部署,因为独立部署,所以对异构语言没有限制,不会对应用造成侵入。
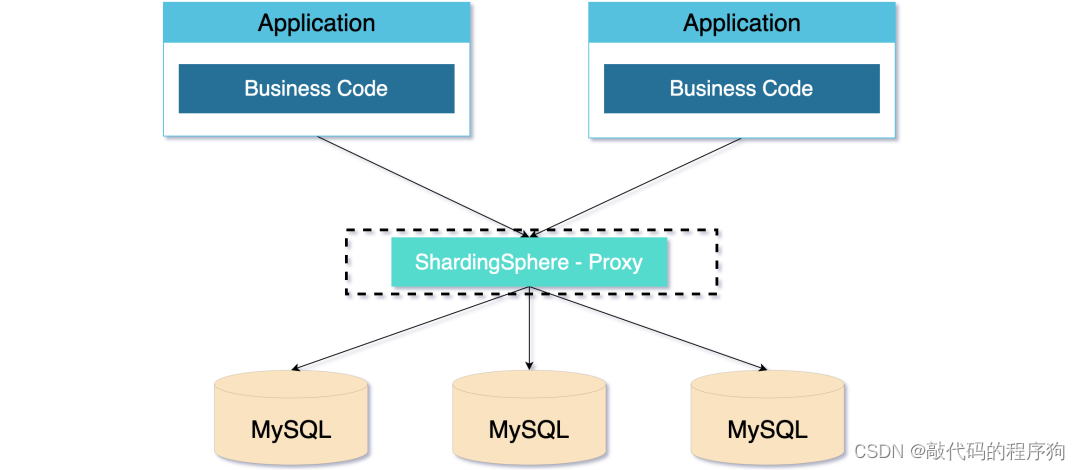
DB 代理模式比 JDBC 代理模式消耗的连接数会少,相对来说性能也会更好。
但中心化的设计也带来了单点的问题,为了保持高可用和高性能,还需要引入 LVS/F5 等 VIP 来实现流量的负载均衡,如果跨越 IDC,还依赖诸如 DNS 进行 IDC 分发,大大拉长了应用到数据库的链路,进而提高了响应时间。
阿里的 MyCat、美团的 Meituan Atlas 和百度 Heisenberg 就是基于 DB 代理模式的实现。
Sharding On MySQL
Sharding On MySQL 相当于屏蔽了分库分表的操作,是运维和中间件结合的沉淀,比较典型的例子是阿里的 DRDS。
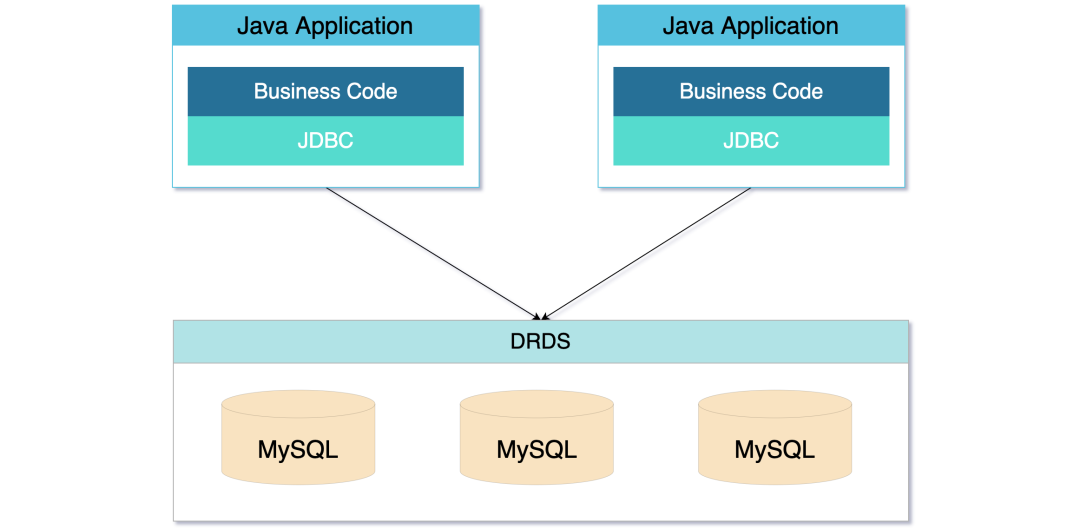
这种模式让分库分表变得模糊,对应用来说,更像是一个封装了 MySQL 的新型数据库。
虽然用户使用变得更简单了,但简单的背后是运维的沉淀,分库分表该存在的问题它依然存在。
分库分表的成本
实现分库分表的方式有很多,但不同模式的实现似乎都是在弥补 MySQL 不支持分布式的缺陷。
分库分表这种强行让 MySQL 达到一个伪“分布式”的状态,也带来了一些新的问题,比如:
- 功能限制问题:分库分表后跨维度 join、聚合、子查询不复存在,唯一键、外键等全局约束也只能靠业务保障,DB 慢慢弱化为存储。
- 运维复杂度问题:分库分表后的多个库表的管理麻烦,运维成本非常高,数据查询也很麻烦。
- Sharding Key 问题:非 Sharding key 的查询需要做额外的冗余处理,需要引入 Elasticsearch、ClickHouse 等其他节点,进一步提高了系统的复杂度。
- 唯一 ID 问题:分库分表后唯一一个 ID 得不到保障,需要唯一 ID 进行改造。
- 分布式事务问题:MySQL 自带的 XA 柔性事务性能太低,需要引入新的分布式事务解决方案。
NewSQL
从上文得知,分库分表需要牺牲 MySQL 的一些功能,还带来许多新的问题。
那有没有一种方案,既能拥有 MySQL 的功能,又能支持数据的可扩展?
有。那就是 NewSQL。
NewSQL 是一类关系数据库管理系统,旨在为在线事务处理(OLTP) 工作负载提供 NoSQL 系统的可扩展性,同时保持传统数据库系统的 ACID 保证。
国内比较知名的 NewSQL 有阿里的 OceanBase、腾讯的 TDSQL、PingCAP 的 TiDB。它们既有 MySQL 的功能,又有分布式可扩展的能力。
笔者对阿里的 OceanBase 只能说是略懂皮毛,就不过多描述。
我们重点看一下腾讯的 TDSQL 和 PingCAP 的 TiDB。
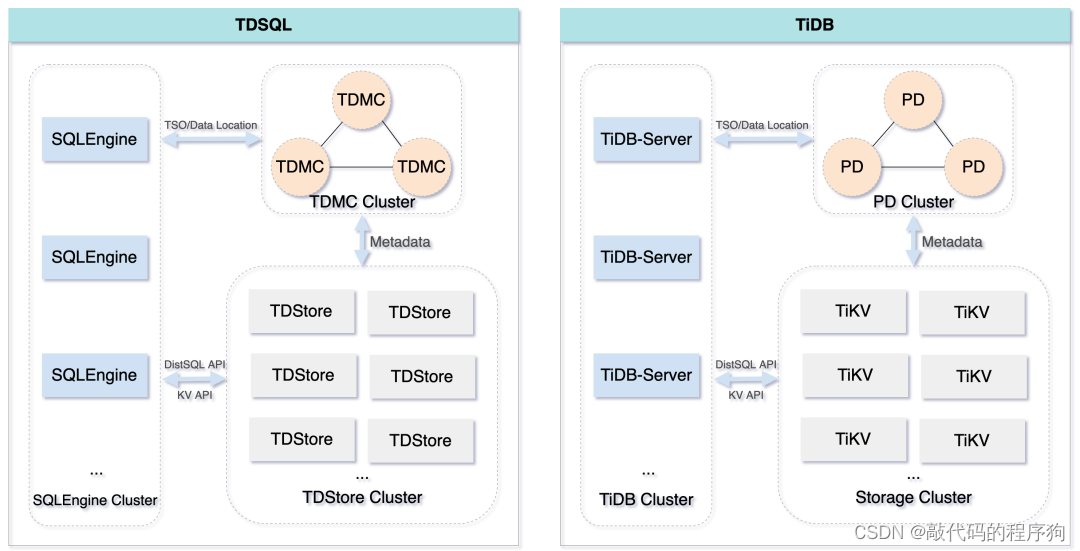
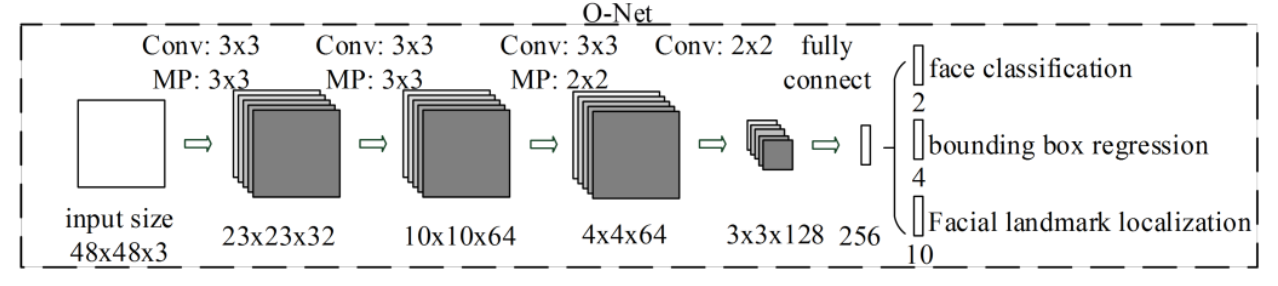
从两者的架构图(省略了部分模块)上可以看出,TDSQL 和 TiDB 的架构只有一些命名差别,可以说几乎一模一样。
两者整体来说分为三个部分:
- 计算:负责接受客户端的连接,执行 SQL 解析和优化,最终生成分布式执行计划转发给底层的存储层执行。(TDSQL:SQL Engine 、TiDB:TiDB-Server)
- 存储:分布式KV 存储,类似 NoSQL 数据库,支持弹性扩容和缩容。(TDSQL:TDStore 、TiDB:TiKV)
- 管控:整个集群的元信息管理模块,是整个集群的大脑。(TDSQL:TDMetaCluster 、TiDB:Placement Driver )
两者核心的存储模块(TDStore/TiKV),都是基于 RocksDB 开发而来,都是KV 存储的模式。
RocksDB 是由 Facebook 基于 LevelDB 开发的一款提供键值存储与读写功能的 LSM-tree 架构引擎。
底层利用了WAL(Write Ahead Log)技术和Sorted String Table,比 B 树类存储引擎更高的写吞吐。
NewSQL 平滑接入方案
因为笔者落地过 TiDB,所以会以 TiDB 为例描述如何接入 NewSQL,做到不影响线上使用的平滑迁移。
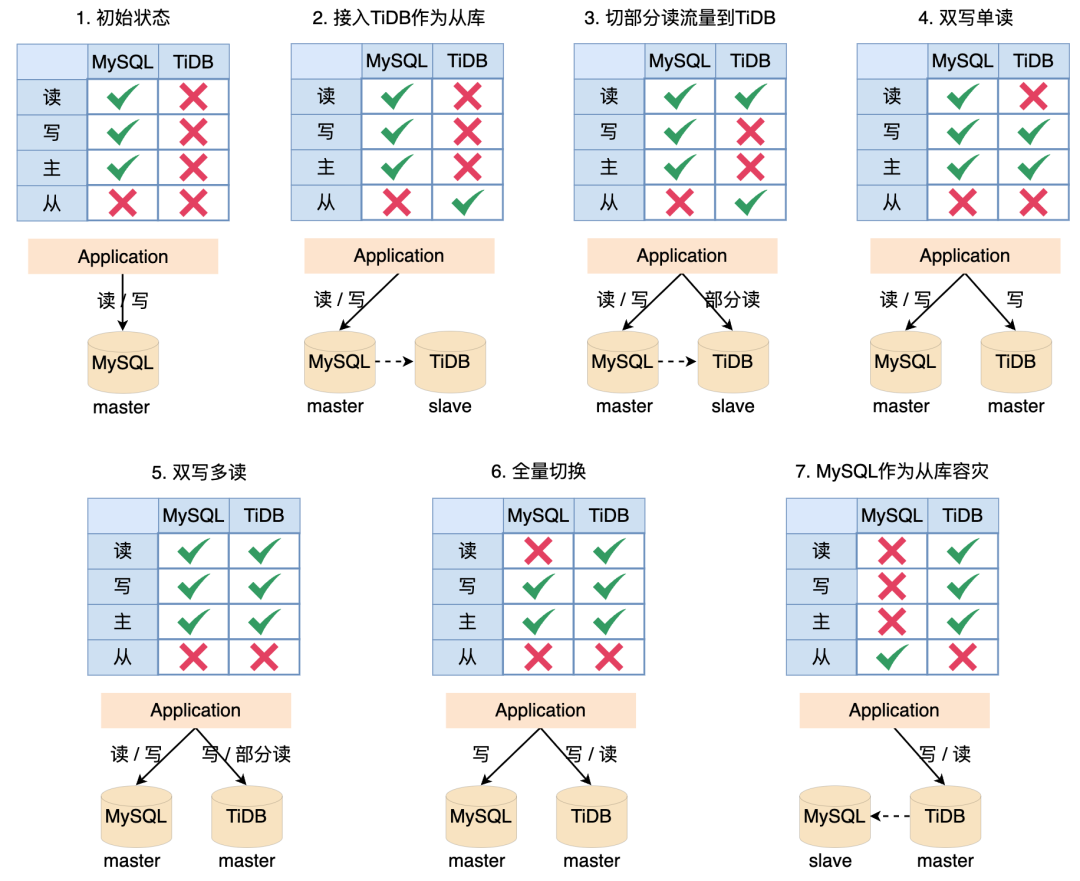
第一步:初始状态,所有线上读和写都落到 MySQL。
第二步:将 TiDB 作为 MySQL 的从节点接入系统,所有线上读写还是都落到 MySQL,日末通过脚本或者任务验证 MySQL 的数据和 TiDB 的数据是否一致,这一步主要验证 MySQL 数据同步到 TiDB 没有问题。
第三步:将部分读切换到 TiDB,这一步主要验证 TiDB 同步的数据读没有问题,验证系统 SQL 能正常在 TiDB 执行。
第四步:断掉 MySQL 和 TiDB 之间的同步,双写 MySQL 和 TiDB,所有的线上读流量都落到 MySQL。
第五步:将部分读流量切到 TiDB,验证 TiDB 写入的数据能够正常读取。这一阶段可以将部分幂等任务同时在两个数据源上执行,验证两者数据是否一致。
第六步:将所有的线上读流量切到 TiDB,同时保持双写,如果出问题随即切到 MySQL。
第七步:断掉 MySQL 的写流量,将 MySQL 作为 TiDB 的一个从库,作为降级使用。
整个方案的基础是:TiDB 兼容 MySQL 协议和 MySQL 生态。
这个方案是建立在完全不信任 TiDB的基础上设计的,验证了 TiDB 和 MySQL 的契合点,所以整体会比较繁琐,实际落地的时候可以根据情况省略一部分步骤。
NewSQL 真的有那么好吗?
NewSQL 并是不万能的,也不必去过于神化 NewSQL,国内比较知名的几种 NewSQL 或多或少都存在部分功能缺陷,以 TiDB 为例:
- TiDB 的自增 ID 只能保证单个 TiKV 上的自增,并不能保证全局自增。
- 由于 TiKV 存储是根据 key 的二进制顺序排列的,使用自增 ID 可能会造成热块效应。
- TiDB 默认 RC(读已提交)的事务隔离级别,并且不支持 RR(可重复读)隔离级别,虽然提供了基本等价于RR的SI(Snapshot Isolation),但还是存在写偏斜问题
- TiDB 的点查(select point)性能比 MySQL 要差不少,在几个亿级别的数据量才能勉强和 MySQL 打平。
- 因为底层基于 Raft 协议做数据同步,所以 TiDB 延迟会比 MySQL 要高。
- …
所以说,NewSQL 也并不是屠龙刀,需要根据实际应用去评估这些缺陷带来的影响。
NewSQL 的应用
NewSQL 在国内其实已经发展了很多年,OceanBase 诞生于 2010 年,TDSQL 可追溯到 2004 年,TiDB 诞生于 2015 年。
三者在国内外积累了不少的客户案例。
OceanBase
- OceanBase 已经覆盖蚂蚁集团100%核心链路,支撑全部五大业务板块。目前运行数十亿条不同的 SQL、数据量达数百 PB、服务器核数过百万。
- 中国工商银行全行业务都使用 OceanBase,包含不限于存、贷、支付结算及创新业务等。
- OceanBase 凭借混合云架构、高可用、Oracle 兼容等特性,通过分布式中间件、金融套件、移动开发平台集成解决方案,支撑网商银行核心系统数字化转型。
- 招商银行的“海量行情系统”和“历史收益系统”就是采用 OceanBase 作为底层数据库。
TDSQL
- 微众银行实现了 TDSQL 私有化部署,是一个典型的两地多中心架构。
- 富途证券的港股交易系统、东吴证券新一代核心交易系统底层存储都是 TDSQL。
- 数字广东粤省事、深圳地铁码上乘车等业务都是在 TDSQL 上面跑的。
- 平安银行、中国农业银行、华夏银行、中国银行都有相关业务在 TDSQL 上。
TiDB
- 北京银行的网联支付业务,所有北京银行的银行卡绑定在比如支付宝、微信上的支付操作,后端的数据库就是运行在 TiDB,而且是一个典型的两地三中心同城双活的架构,这个业务非常的关键,如果业务中断超过一定时间,就是需要上报银监会的。
- 日本排名第一的支付公司——Paypay,钱包和支付的业务都在 TiDB 上面。
- 中国人寿的寿财险业务,正在用 TiDB 陆续替换 Oracle 。
- 肯德基所有的会员登录系统,包括 KFC 的 APP 以及第三方登录,后台数据库都是用的 TiDB ,这套业务 2020 年 4 月份上线,已经经历过多次肯德基的大促等活动,目前肯德基的后台支付系统也已经切换到 TiDB 上。
- 麦当劳的账户以及订单系统全部基于 TiDB,如果 TiDB 出问题了,那么国内所有的麦当劳门店,包括线上和线下的点单系统都将没法正常运行。
- 微众银行最核心和最赚钱的微粒贷业务,后台的全量批处理业务就运行在 TiDB 上面。
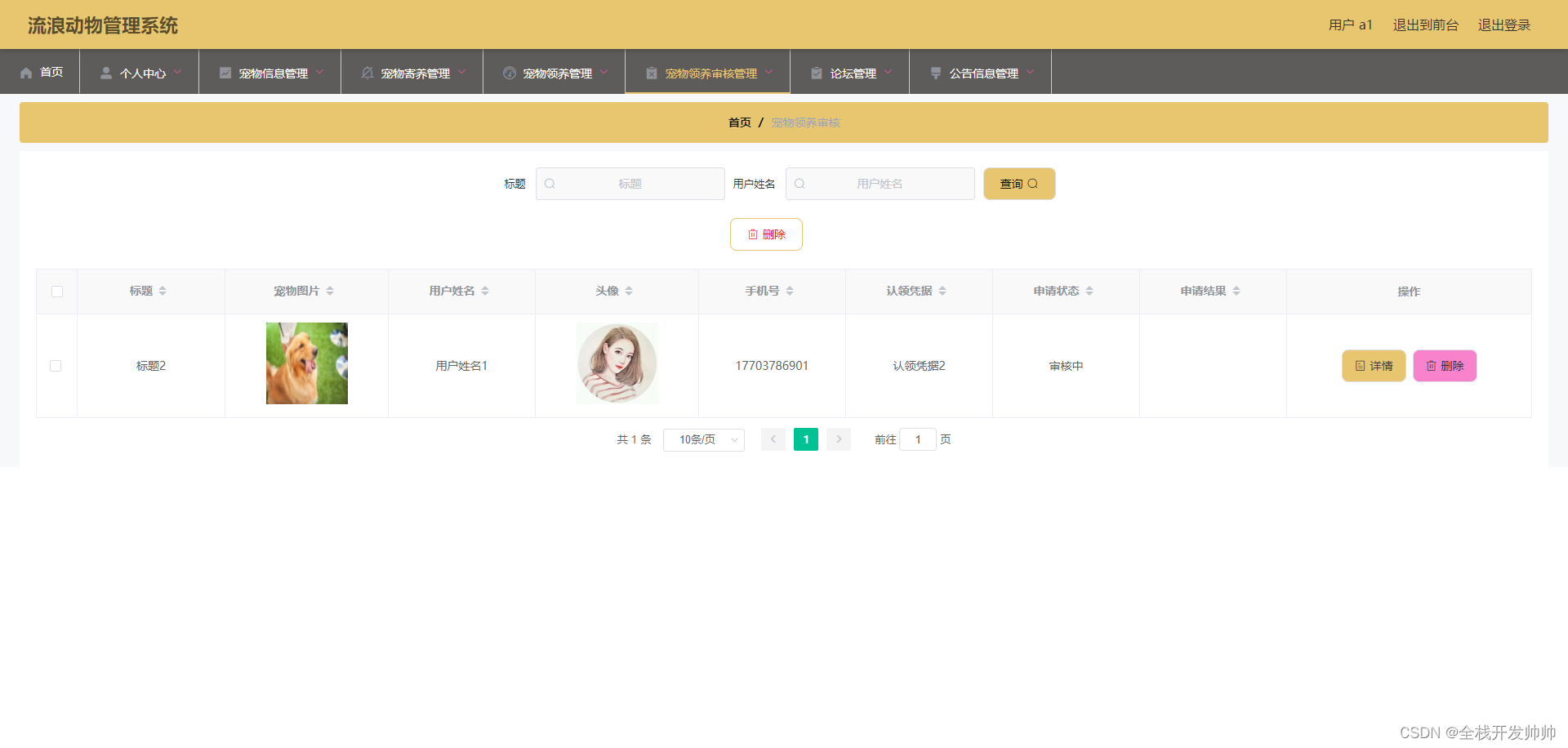
分库分表和 NewSQL 到底怎么选?
分库分表是一个重量级的方案,它会带来很多新的问题,对基建和运维的要求也很高。
NewSQL 功能强大但也有功能缺陷。
如何去抉择需要根据系统现状和公司情况去综合判断。
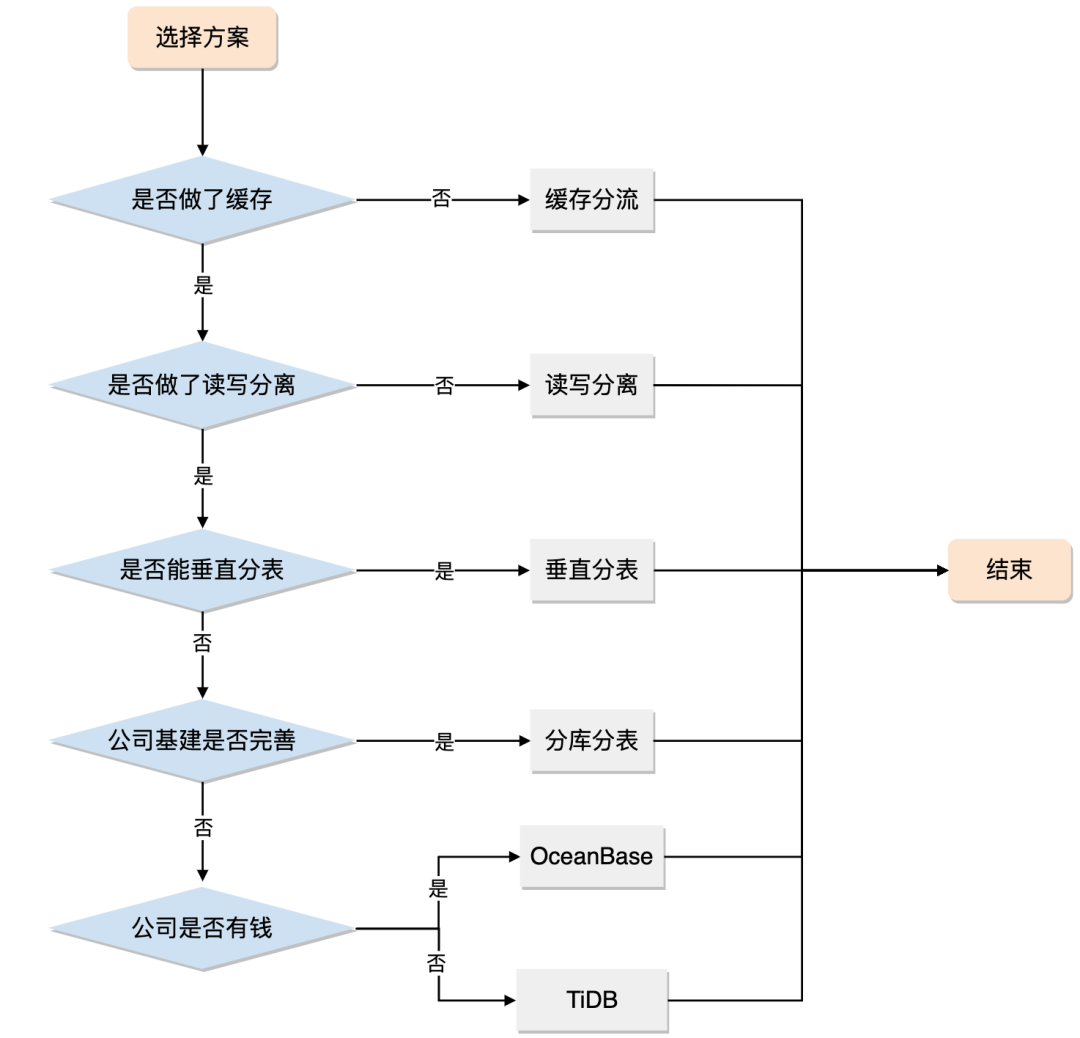
分库分表是一个重量级的方案,如果读写分离、冷热分离等轻量级方案能解决的问题就没必要上分库分表。
如果缓存分流和读写分离都扛不住了,且你身处互联网企业,基建尚可且运维也跟得上,分库分表仍然是第一选择;
但如果你身处一个传统的企业,基建很差甚至没有基建,那么你可以考虑考虑NewSQL。
技术没有高低之分,能解决问题的技术就是好技术,技术方案选择上切莫炫技,也切勿过度设计!