多模态融合算法应用 · CT +临床文本数据 + pyradiomics提取图像特征
- 单模态建模
- 临床数据建模
- pyradiomics提取图像特征建模
- CT建模
- 多模态建模
- 前融合
- 为什么能直接合并在一起?
- 后融合
- Med-CLIP:深度学习 + 可解释性
单模态建模
临床数据建模
临床文本数据:
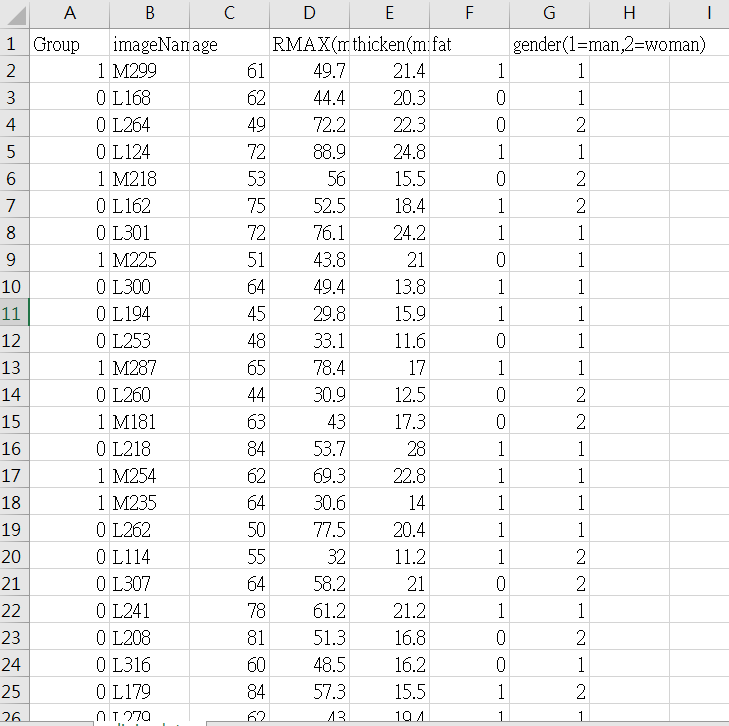
- Group: 目标分类标签,表示样本属于哪一组(0或1)。
- imageName: 图像名称,表示每个样本对应的图像的名称。
- age: 年龄,表示样本的年龄。
- RMAX(mm): 某一特征的数值,单位为毫米。
- thicken(mm): 另一特征的数值,单位为毫米。
- fat: 体脂率,表示样本的体脂含量。
- gender(1=man,2=woman): 性别编码,1表示男性,2表示女性。
-
第1行
- Group: 1(正类)
- imageName: M299(对应哪个病)
- age: 61
- RMAX(mm): 49.7
- thicken(mm): 21.4
- fat: 1(有体脂)
- gender: 1(男性)
-
第2行
- Group: 0(负类)
- imageName: L168(对应哪个病)
- age: 62
- RMAX(mm): 44.4
- thicken(mm): 20.3
- fat: 0(无体脂)
- gender: 1(男性)
-
第3行
- Group: 0(负类)
- imageName: L264(对应哪个病)
- age: 49
- RMAX(mm): 72.2
- thicken(mm): 22.3
- fat: 0(无体脂)
- gender: 2(女性)
这张图展示了数据集的前几行样本及其特征,包括年龄、RMAX值、thicken值、体脂率和性别。
样本比(数据平衡):
-
0 类 122
-
1 类 106
# 导入常用库
import sys # 系统特定参数和函数
import pandas as pd # 数据处理和分析库
import os # 操作系统接口模块
import random # 生成随机数的模块
import shutil # 文件操作模块
import sklearn # 机器学习库
import scipy # 科学计算库
import numpy as np # 数组和矩阵处理库
import matplotlib.pyplot as plt # 数据可视化库
from sklearn.linear_model import LassoCV # 导入LassoCV回归模型
from sklearn.preprocessing import StandardScaler # 导入标准化工具
import seaborn as sns # 数据可视化库clinic_df = pd.read_csv("clinic_data.csv") # 读取临床数据CSV文件
new_clinic_df = clinic_df.drop('imageName', axis=1) # 删除无用的'imageName'列
selected_columns1 = new_clinic_df.columns # 获取数据框的列名from pycaret.classification import * # 导入PyCaret分类模块
s1 = ClassificationExperiment() # 创建分类实验对象
s1.setup(data = new_clinic_df, target = 'Group', session_id=123, fix_imbalance_method=False, normalize=True)
# 设置分类实验的初始参数:使用new_clinic_df数据框,目标列为'Group',设置随机种子为123,不进行数据平衡处理,对数据进行标准化
best1 = s1.compare_models() # 比较不同的分类模型,选择表现最好的模型
s1.evaluate_model(best1) # 评估最优模型的性能
s1.plot_model(best1, 'auc') # 绘制最优模型的ROC曲线并显示AUC值
s1.predict_model(best1) # 使用最优模型对数据进行预测
预测结果:模型的准确率 (Accuracy) 为 68.12%。
尝试的模型有:
- Logistic Regression (LR):逻辑回归
- K Nearest Neighbors (KNN):K近邻
- Naive Bayes (NB):朴素贝叶斯
- Decision Tree (DT):决策树
- Random Forest (RF):随机森林
- Gradient Boosting Classifier (GB):梯度提升分类器
- Support Vector Machine (SVM):支持向量机
- Light Gradient Boosting Machine (LightGBM):轻量梯度提升机
- Extreme Gradient Boosting (XGBoost):极限梯度提升
- CatBoost Classifier (CatBoost):CatBoost分类器
- Extra Trees Classifier (ET):极端随机树
- AdaBoost Classifier (ADA):AdaBoost分类器
- Linear Discriminant Analysis (LDA):线性判别分析
- Quadratic Discriminant Analysis (QDA):二次判别分析
pyradiomics提取图像特征建模
pyradiomics提取图像特征,有近50种。

import sys
import pandas as pd
import os
import random
import shutil
import sklearn
import scipy
import numpy as np
import radiomics # 这个库专门用来提取特征
from radiomics import featureextractor
from sklearn.linear_model import LassoCV # 导入Lasso工具包LassoCV
from sklearn.preprocessing import StandardScaler # 标准化工具包StandardScalerfeature_df = pd.read_csv("radiomics_feature_data.csv") # 读取放射学特征数据的CSV文件
new_feature_df = feature_df.drop("imageName", axis=1) # 删除无用的'imageName'列
from pycaret.classification import * # 导入PyCaret分类模块s2 = ClassificationExperiment() # 创建分类实验对象
s2.setup(data = new_feature_df, target = 'Group', session_id=123, fix_imbalance_method=False, normalize=True, feature_selection = True, feature_selection_method='classic', n_features_to_select=0.2)
# 设置分类实验的初始参数:使用new_feature_df数据框,目标列为'Group',设置随机种子为123,不进行数据平衡处理,对数据进行标准化,
# 使用特征选择,特征选择方法为'classic',选择20%的特征(机器学习不合适太多特征,需要选择一些主要信息的特征)selected_columns = s2.dataset_transformed.columns # 获取转换后数据集的列名(代表选择的特征有哪些)
best2 = s2.compare_models() # 比较不同的分类模型,选择表现最好的模型
s2.predict_model(best2) # 评估最优模型的性能
预测结果:模型的准确率 (Accuracy) 为 67.33%。
比临床数据预测的 68.12% 低一些。
从所有特征选了20%特征,具体是哪些:
['A_wavelet-LHL_glszm_SmallAreaEmphasis','A_wavelet-HHH_glszm_SizeZoneNonUniformityNormalized','A_wavelet-LLL_glszm_GrayLevelNonUniformityNormalized','A_wavelet-LHH_glcm_InverseVariance','A_original_glszm_SizeZoneNonUniformityNormalize','A_original_ngtdm_Strength','A_wavelet-LHH_glszm_GrayLevelNonUniformity','A_log-sigma-5-0-mm-3D_firstorder_90Percentile','A_wavelet-HLL_glcm_MCC', 'A_log-sigma-4-0-mm-3D_ngtdm_Contrast']
CT建模
多模态建模
前融合
把临床文本数据(删除imageName了,5个)和 pyradiomics提取到的图像特征(20%,9个)
columns = ['Group', 'age', 'RMAX(mm)', 'thicken(mm)', 'fat','gender(1=man,2=woman)','A_wavelet-LHL_glszm_SmallAreaEmphasis','A_wavelet-HHH_glszm_SizeZoneNonUniformityNormalized','A_wavelet-LLL_glszm_GrayLevelNonUniformityNormalized','A_wavelet-LHH_glcm_InverseVariance','A_original_glszm_SizeZoneNonUniformityNormalized','A_original_ngtdm_Strength','A_wavelet-LHH_glszm_GrayLevelNonUniformity','A_log-sigma-5-0-mm-3D_firstorder_90Percentile','A_wavelet-HLL_glcm_MCC', 'A_log-sigma-4-0-mm-3D_ngtdm_Contrast']
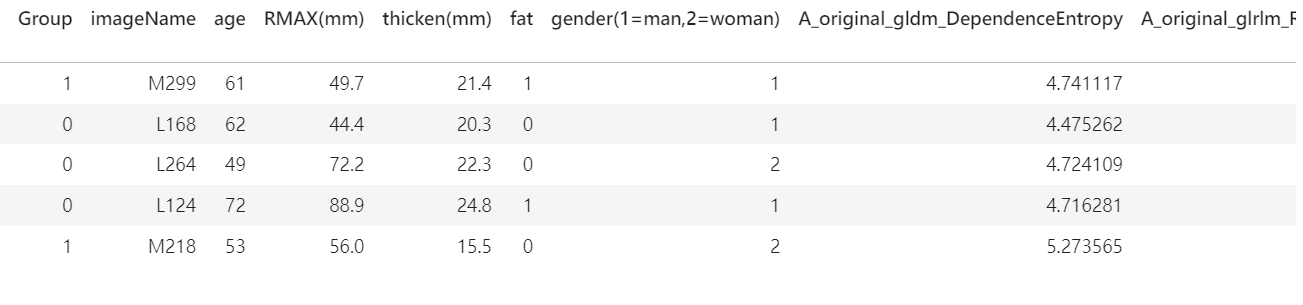
merge_df = pd.read_csv("merge.csv") # 读取合并数据的CSV文件
columns = ['Group', 'age', 'RMAX(mm)', 'thicken(mm)', 'fat','gender(1=man,2=woman)', 'A_wavelet-LHL_glszm_SmallAreaEmphasis','A_wavelet-HHH_glszm_SizeZoneNonUniformityNormalized','A_wavelet-LLL_glszm_GrayLevelNonUniformityNormalized','A_wavelet-LHH_glcm_InverseVariance','A_original_glszm_SizeZoneNonUniformityNormalized','A_original_ngtdm_Strength','A_wavelet-LHH_glszm_GrayLevelNonUniformity','A_log-sigma-5-0-mm-3D_firstorder_90Percentile','A_wavelet-HLL_glcm_MCC', 'A_log-sigma-4-0-mm-3D_ngtdm_Contrast']
# 指定需要的列,包含目标列和若干特征列new_merge_df = merge_df[columns] # 从数据框中选择指定的列
from pycaret.classification import * # 导入PyCaret分类模块s3 = ClassificationExperiment() # 创建分类实验对象
s3.setup(data = new_merge_df, target = 'Group', session_id=123, fix_imbalance_method=False, normalize=True)
# 设置分类实验的初始参数:使用new_merge_df数据框,目标列为'Group',设置随机种子为123,不进行数据平衡处理,对数据进行标准化best3 = s3.compare_models() # 比较不同的分类模型,选择表现最好的模型
s3.predict_model(best3) # 使用最优模型对数据进行预测
前融合预测结果:71.01%。
-
pyradiomics提取图像(20%)特征建模:67.33%
-
临床数据建模:68.12%
如果想进一步优化,可以多选一些特征,这个只选了20%。
为什么能直接合并在一起?
临床数据
(Group’, ‘age’, ‘RMAX(mm)’, ‘thicken(mm)’, ‘fat’,
‘gender(1=man,2=woman)’)
和pyradiomics提取图像特征
(Group、‘A_wavelet-LHL_glszm_SmallAreaEmphasis’,
‘A_wavelet-HHH_glszm_SizeZoneNonUniformityNormalized’,
‘A_wavelet-LLL_glszm_GrayLevelNonUniformityNormalized’,
‘A_wavelet-LHH_glcm_InverseVariance’,
‘A_original_glszm_SizeZoneNonUniformityNormalized’,
‘A_original_ngtdm_Strength’,
‘A_wavelet-LHH_glszm_GrayLevelNonUniformity’,
‘A_log-sigma-5-0-mm-3D_firstorder_90Percentile’,
‘A_wavelet-HLL_glcm_MCC’, ‘A_log-sigma-4-0-mm-3D_ngtdm_Contrast’)
为什么能直接合并在一起?
临床数据和从图像中提取的放射学特征可以直接合并在一起是因为它们都描述了同一组样本的不同方面。
后融合
Med-CLIP:深度学习 + 可解释性
不止 pyradiomics 能提取图像特征,深度学习方法更好,但深度学习方法提取的特征没有可解释性。
从高维空间提取的特征,最后压缩成一行给你,完全看不懂到底是什么。
那使用多模态大模型方式更好。
虽然也是临床数据(年龄、性别、疾病标签等)+ 患者图像数据进行预测,但大模型会给你详细的解释 — 之所以说 yyy 病,是因为 xxx 特征,是真能解释清楚。