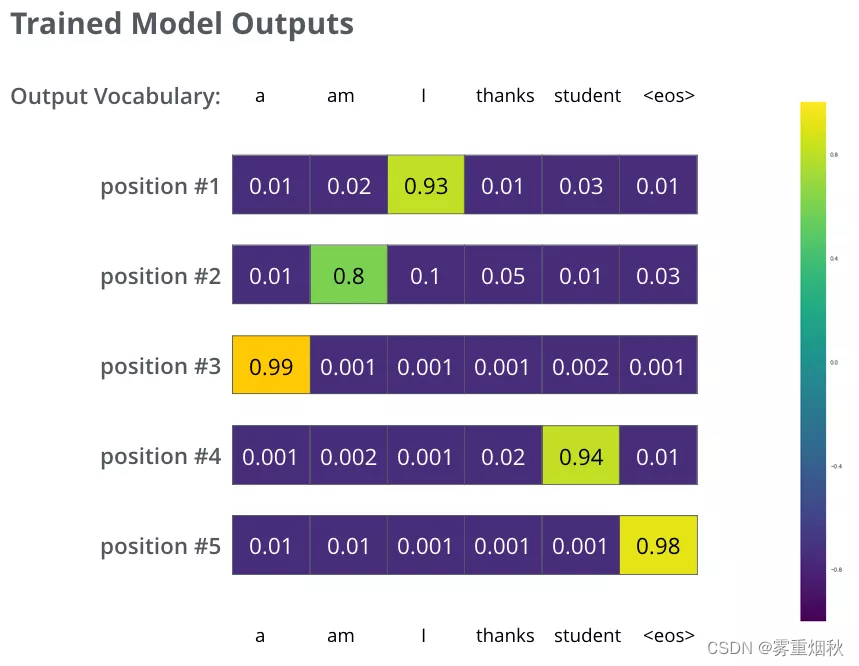
目录
进行推理
关键思想
进行推理
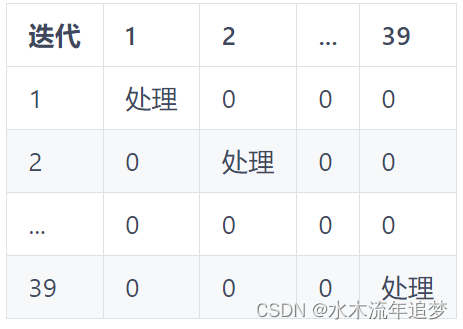
由于我们的样本量非常小(39),因此在确定我们的结果是否具有统计学意义时,我们必须更加聪明,而不仅仅是由于随机运气。在这里,我们将使用 Fisher 精确检验的思想。它的直觉非常简单。我们彻底置换处理和控制。由于我们只有一个处理过的单元,这意味着对于每个单元,我们假装它是处理过的,而其他的是对照。
最后,我们将为每个状态提供一个合成控制和效果估计。所以它的作用是假装干预实际上发生在另一个州,而不是加利福尼亚,看看这种干预没有发生的估计效果是什么。然后,我们看看加州的干预与其他虚拟干预相比是否足够大。这个想法是,对于实际上没有得到干预的州,一旦我们假装它们是,我们将无法找到任何显著的干预效果。
为了实现这一点,我构建了这个函数,该函数将州作为输入并估计该州的合成控制。此函数返回一个数据框,其中一列用于状态,一列用于年份,一列用于结果“cigsale”和该州的合成结果。
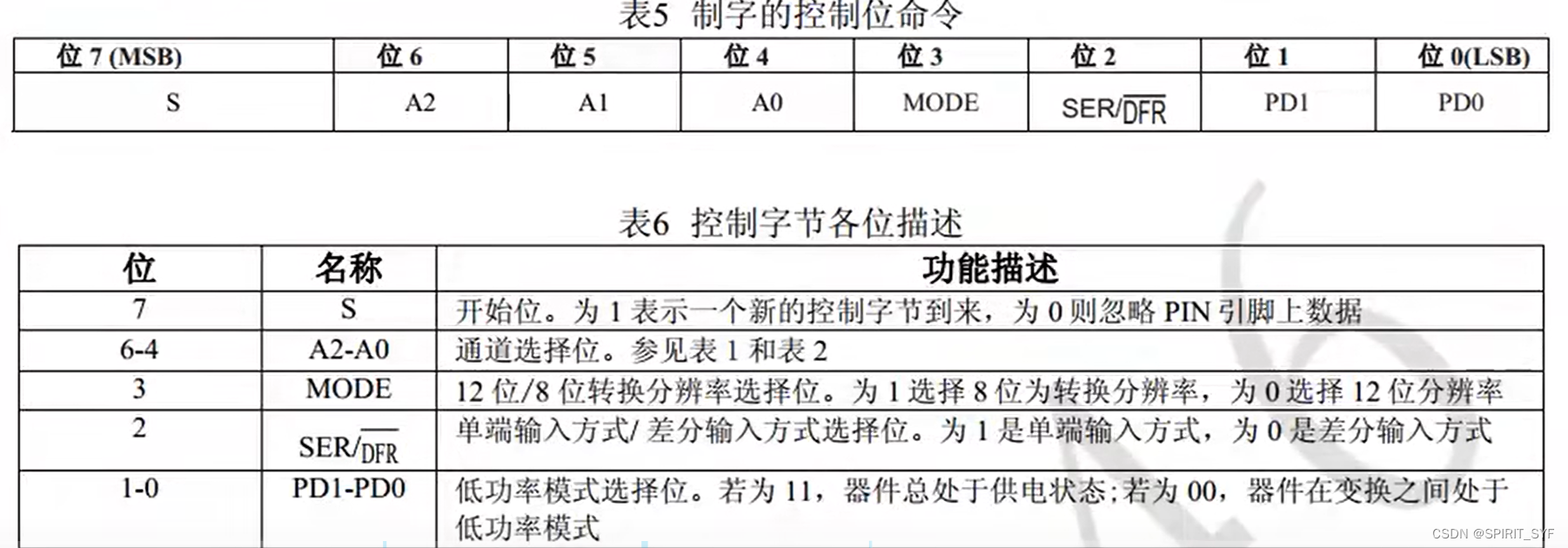
def synthetic_control(state: int, pool: List[int], data: pd.DataFrame) -> np.array:features = ["cigsale", "retprice"]inverted = (data.query("~after_treatment").pivot(index='state', columns="year")[features].T)y = inverted[state].values # treatedX = inverted.drop(columns=state).values # donor poolweights = get_w(X, y)synthetic = (data.query(f"~(state=={state})").pivot(index='year', columns="state")["cigsale"].values.dot(weights))return (data.query(f"state=={state}")[["state", "year", "cigsale", "after_treatment"]].assign(synthetic=synthetic))
##下面是我们应用该函数到第一个州的结果。control_pool = cigar["state"].unique()synthetic_control(1, control_pool, cigar).head()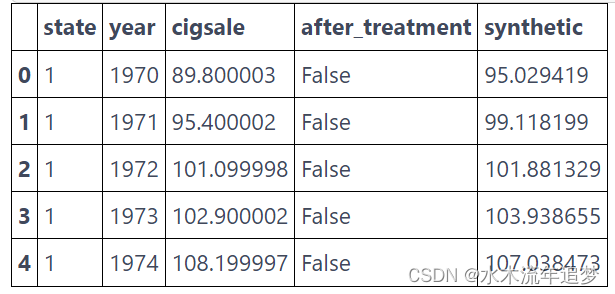
为了获得所有州对应的结果,我们在 8 个进程中并行计算。 如果您的计算机有更多或更少的内核,您可以使用不同的数量。 此代码将返回与上面类似的数据帧列表。
from joblib import Parallel, delayedparallel_fn = delayed(partial(synthetic_control, pool=control_pool, data=cigar))sinthetic_states = Parallel(n_jobs=8)(parallel_fn(state) for state in control_pool)
sinthetic_states[0].head()
通过对所有州应用合成控制,我们可以估计所有州的合成状态与真实状态之间的差距。 对于加州来说,这就是干预效果。 对于其他州,这就像安慰剂效应,我们在其中估计了干预实际上没有发生的合成对照干预效果。 如果我们将所有安慰剂效应与加利福尼亚治疗效应一起绘制,我们会得到下图。
plt.figure(figsize=(12,7))
for state in sinthetic_states:plt.plot(state["year"], state["cigsale"] - state["synthetic"], color="C5",alpha=0.4)plt.plot(cigar.query("california")["year"], cigar.query("california")["cigsale"] - calif_synth,label="California");plt.vlines(x=1988, ymin=-50, ymax=120, linestyle=":", lw=2, label="Proposition 99")
plt.hlines(y=0, xmin=1970, xmax=2000, lw=3)
plt.ylabel("Gap in per-capita cigarette sales (in packs)")
plt.title("State - Synthetic Across Time")
plt.legend();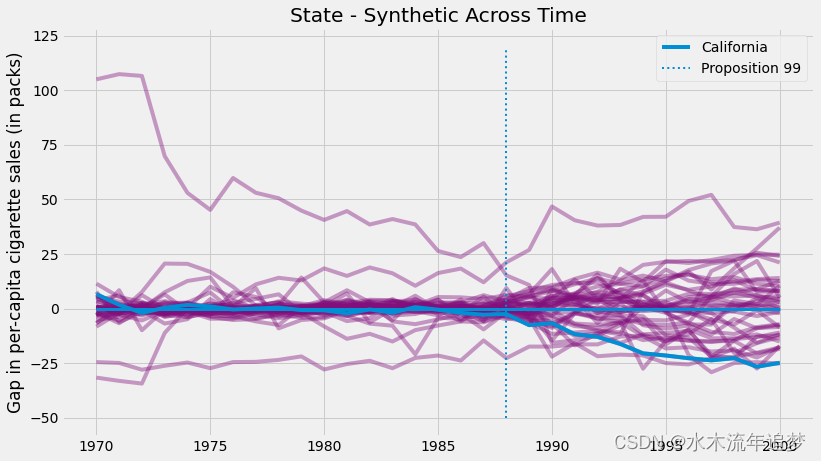
这个数字的两个方面让人眼前一亮。 首先,我们可以看到干预后的方差高于干预前的方差。 这是意料之中的,因为合成控制旨在最大限度地减少干预前期间的差异。 另一个有趣的方面是,即使在干预前的时期,我们也不能很好地拟合一些单位。 这也是意料之中的。 例如,如果某些州的卷烟消费量非常高,那么其他州的凸组合将永远无法匹配它们。
由于这些单位的拟合度很差,因此最好将它们从分析中删除。 客观地做到这一点的一种方法是设置干预前错误的阈值
并删除那些具有高错误的单元。 如果我们像这样继续并绘制相同的图形,这就是我们得到的。
def pre_treatment_error(state):pre_treat_error = (state.query("~after_treatment")["cigsale"] - state.query("~after_treatment")["synthetic"]) ** 2return pre_treat_error.mean()plt.figure(figsize=(12,7))
for state in sinthetic_states:# remove units with mean error above 80.if pre_treatment_error(state) < 80:plt.plot(state["year"], state["cigsale"] - state["synthetic"], color="C5",alpha=0.4)plt.plot(cigar.query("california")["year"], cigar.query("california")["cigsale"] - calif_synth,label="California");plt.vlines(x=1988, ymin=-50, ymax=120, linestyle=":", lw=2, label="Proposition 99")
plt.hlines(y=0, xmin=1970, xmax=2000, lw=3)
plt.ylabel("Gap in per-capita cigarette sales (in packs)")
plt.title("Distribution of Effects")
plt.title("State - Synthetic Across Time (Large Pre-Treatment Errors Removed)")
plt.legend();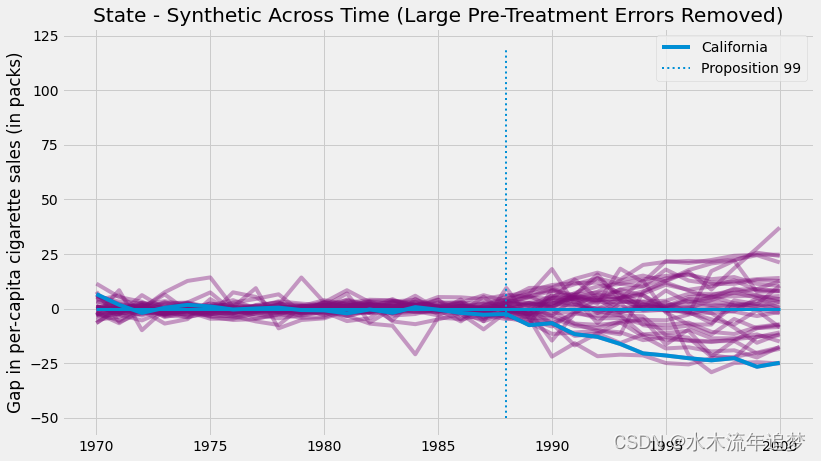
去除噪音,我们可以看到加利福尼亚州的值是多么极端。 这张图片告诉我们,如果我们假装这种干预发生在任何其他州,我们几乎永远不会得到像加利福尼亚那样极端的效果。
这张图片本身就是一种推理形式,但我们也可以从这些结果中得出 P 值。 我们所要做的就是看看我们所获得的效果比加利福尼亚的效果低多少倍。这张图片本身就是一种推理形式,但我们也可以从这些结果中得出 P 值。 我们所要做的就是看看我们所获得的效果比加利福尼亚的效果低多少倍。
calif_number = 3effects = [state.query("year==2000").iloc[0]["cigsale"] - state.query("year==2000").iloc[0]["synthetic"]for state in sinthetic_statesif pre_treatment_error(state) < 80] # filter out noisecalif_effect = cigar.query("california & year==2000").iloc[0]["cigsale"] - calif_synth[-1] print("California Treatment Effect for the Year 2000:", calif_effect)
np.array(effects)
California Treatment Effect for the Year 2000: -24.83015975492409
array([ 5.79715885, 0.89458997, -24.83015975, -7.16628121,-10.92204857, 37.11640557, -15.06971695, -0.49805108,-18.45795062, 21.13366444, 12.57782771, -1.47547827,10.49627353, -11.6701235 , 4.29850824, 8.04811405,14.02322417, 8.25002748, 0.32576356, -8.40826855,-2.12402704, -7.42865016, 2.9615753 , 24.10478116,4.25211769, -17.75844573, 7.93334016, 2.81640126,12.6495596 , -17.47677512, -25.16040937, -12.26469121,24.69067369, 10.36299581, -8.59880336])如果我们想检验加利福尼亚的效应低于零的单方面假设,我们可以将 P 值估计为加利福尼亚的效应大于所有估计效应的倍数。
事实证明,2000 年加州的干预效果是 -24.8,这意味着干预措施减少了近 25 包香烟的消费量。 在我们估计的所有其他 34 种安慰剂效应中,只有一种高于我们在加利福尼亚发现的效应。 所以 p 值为 1/35。
np.mean(np.array(effects) < calif_effect)
0.02857142857142857##最后,我们可以展示效果的分布,从而让大家感受一下加州的干预效果估计值是多么的极端。_, bins, _ = plt.hist(effects, bins=20, color="C5", alpha=0.5);
plt.hist([calif_effect], bins=bins, color="C0", label="California")
plt.ylabel("Frquency")
plt.title("Distribution of Effects")
plt.legend();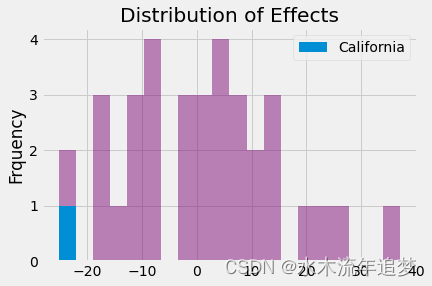
关键思想
我们了解到,如果我们只有城市或州等实体的聚合级别数据,diff-in-diff 将不允许我们进行推理。 此外,它还有一些其他限制,因为它必须定义一个控制单元,而一个单独的控制单元可能不能很好地表示处理单元的反事实。
为了纠正这一点,我们了解到我们可以构建一个合成控件,将多个控制单元组合在一起,使它们与处理过的单元相似。 通过这种综合控制,我们能够看到在没有治疗的情况下我们的治疗单元会发生什么。
最后,我们看到了如何使用 Fisher 精确检验通过合成控制进行推理。 也就是说,我们假设未处理的单位实际上是处理过的并计算了它们的效果。 这些是安慰剂效应:即使没有治疗我们也会观察到的效应。 我们使用这些来查看我们估计的治疗效果是否具有统计学意义。