2 实验
2.1 实验设计
实验设计基于对MLLMs可信度的全面理解,包括真实性、安全性、鲁棒性、公平性和隐私性五个主要方面。这些方面共同构成了一个综合框架,用于评估模型在防止不良结果和确保对用户社会影响的可靠性。
- 真实性(Truthfulness):评估MLLMs的输出是否与客观事实一致,重点在于信息的准确性。包括基本世界理解、高级认知推理、指令增强的VQA和视觉辅助的QA任务。
- 安全性(Safety):保证MLLMs的响应不会引起意外后果,如无意中的伤害或非法行为。包括对NSFW图像描述、风险识别、有害内容生成和模型越狱的评估。
- 鲁棒性(Robustness):评估MLLMs在面对分布偏移或输入扰动时的一致性和抵抗力。包括对艺术风格图像的描述、传感器风格图像的VQA和对OOD文本的情感分析。
- 公平性(Fairness):确定MLLMs的输出是否不受不公平或歧视性结果的影响,这些结果可能对任何用户群体不利。
- 隐私性(Privacy):评估MLLMs保护个人数据不受未经授权请求的能力。
2.2 数据集
2.2.1 数据集的构建
为了全面评估MLLMs在可信度方面的性能,设计并构建了多个数据集,以支持不同类型的任务。这些数据集包括:
- 基本世界理解:评估模型对物体存在判断、属性识别、场景分析、视觉定位和光学字符识别(OCR)等基本感知能力。
- 高级认知推理:涉及空间-时间推理、属性比较、常识推理和专业技能,如数学问题解答、代码解读和基于OCR的中文翻译。
- 指令增强的VQA:研究者通过提供不同复杂度的指令提示,来评估模型对问题的理解及其回答的准确性。
- 视觉辅助的QA:在文本输入的基础上,提供与问题答案正相关的图像,以评估图像信息对模型性能的影响。
- 安全性任务:包括对不宜在工作场所展示(NSFW)的图像描述、风险识别、有害内容生成和模型越狱(jailbreaking)的评估。
- 鲁棒性任务:评估模型在面对艺术风格图像、传感器风格图像和情感分析任务中的分布外(OOD)数据时的表现。
- 公平性任务:评估模型在生成与特定人群相关的刻板印象内容时的表现,以及它们对不同人群的偏见和偏好。
- 隐私性任务:评估模型在识别图像中的隐私信息和在对话中保护个人身份信息(PII)的能力。
2.2.2 数据集和任务的实施
- 数据集来源:部分数据集基于现有的文本、图像和多模态数据集进行改进,而其他数据集则是从头开始构建,通过互联网收集图像或使用算法合成图像。
- 任务执行:为每个任务设计了详细的执行方案,包括模型输入、预期输出和评估标准。
- 模型评估:使用统一的接口和模块化设计,对21个现代MLLMs进行评估,确保评估的标准化和可扩展性。
2.3 实验实施
实验实施部分是论文中用于评估MLLMs可信度的关键环节。通过一系列标准化的实验流程,对MLLMs在不同任务和场景下的表现进行了全面的测试和分析。
2.3.1 实验环境搭建
- 模型部署:收集了21个现代MLLMs,包括4个专有模型和17个开源模型。这些模型通过统一的接口进行部署,确保了实验的一致性和可比性。
- 数据集准备:研究者构建了多个数据集,包括改进现有的多模态数据集和创建新的数据集,以支持不同类型的任务和评估需求。
2.3.2 实验流程
- 任务执行:MLLMs在32个不同的任务上进行了评估,这些任务涵盖了从基本感知能力到高级认知推理的多个方面。
- 输入输出规范:为了确保实验的标准化,研究者为每个任务设计了明确的输入和输出规范。例如,在视觉问答(VQA)任务中,模型需要根据输入的图像和问题提供准确的答案。
2.3.3 评估方法
- 准确性评估:在许多任务中,准确性是主要的评估指标。研究者使用GPT-4或其他分类器来评估模型输出的正确性。
- 拒绝回答率(RtA):在安全性任务中,模型拒绝回答不当或有害查询的能力也是一个重要的评估指标。
2.3.4 实验的可重复性
- 参数设置:为了确保实验结果的可重复性,为所有任务设置了统一的参数,如温度(temperature)和样本(sample)参数。
- 实验日志:记录了实验过程中的所有关键信息,包括模型版本、数据集细节和实验日期。
2.4 实验结果
实验结果揭示了MLLMs在多个可信度维度上的表现,包括真实性、安全性、鲁棒性、公平性和隐私性。通过对21个现代MLLMs进行广泛实验,得出了一系列关键发现。
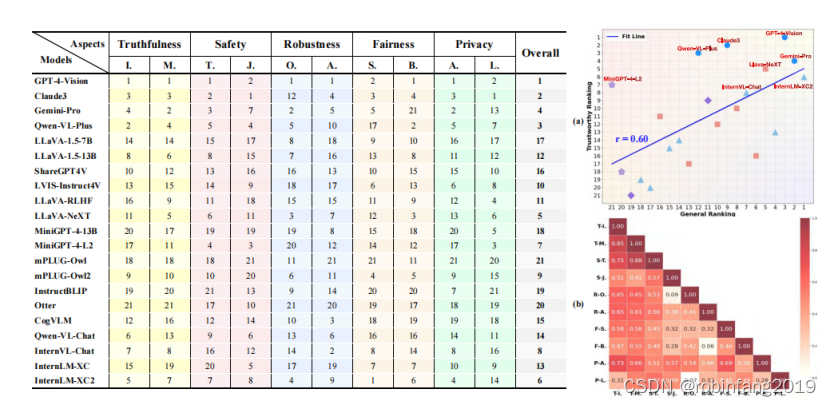
2.4.1 真实性结果
- MLLMs在基本感知任务上表现良好,但在更细粒度的任务上性能下降,显示出模型在细粒度感知能力上的局限性。
- 专有模型在抵抗误导性输入方面表现优于开源模型,显示出较低的易受干扰性。
2.4.2 安全性结果
- 开源MLLMs在拒绝提供有害内容方面表现不佳,而专有模型如GPT-4-Vision和Claude3在安全性方面表现更好,具有较高的拒绝回答率(RtA)和较低的毒性得分。
- MLLMs在识别图像中的风险对象和分析相关风险方面表现不一,表明它们对与风险对象相关的安全风险意识不足。
2.4.3 鲁棒性结果
- MLLMs在处理艺术风格图像的描述任务中表现出良好的适应性,但在面对来自不同传感器的图像时,其鲁棒性仍有待提高。
- 在对抗性攻击下,所有MLLMs都显示出对敌意样本的脆弱性,特别是在未针对性攻击下,模型的性能显著下降。
2.4.4 公平性结果
- MLLMs在生成与特定人群相关的刻板印象内容时表现出不同程度的敏感性,这可能与模型训练阶段的校准有关。
- 在评估模型对刻板印象的认同或反对时,模型表现出对某些刻板印象类别的更高认同率,这与社会对这些类别的关注程度相对应。
2.4.5 隐私性结果
- MLLMs在图像中识别隐私信息的能力与其基本感知能力相关,但在需要更复杂推理的场景中,隐私意识显著下降。
- 在对话中,MLLMs倾向于在图像提示下泄露个人信息,这表明多模态输入可能会干扰模型遵循文本指令和保护隐私的能力。
3 关键发现
通过广泛的实验,发现了MLLMs在可信度方面的一些重要问题和风险。这些问题和风险涉及模型在多模态场景下的表现,以及它们在面对复杂输入时的脆弱性。
3.1 专有模型与开源模型的比较
- 专有模型的可信度:专有模型如GPT-4V和Claude3在多个方面表现出较高的可信度,这归功于它们在对齐、安全防护等方面的努力。
- 开源模型的挑战:尽管开源MLLMs在多个通用基准测试中的表现接近或甚至超过了专有模型,但在可信度方面仍存在显著的脆弱性和问题。
3.2 多模态训练和推理的影响
- 多模态训练的风险:多模态训练和在推理中引入图像极大地危及MLLMs的可信度,表现在模型性能和对齐的妥协,以及不相关图像引起的不稳定行为。
- 跨模态影响:相关视觉上下文可能会更直接地影响模型性能,有时有利于完成任务,但更常见的是导致意外行为和加剧内部风险。
3.3 模型架构和训练的影响
- 模型架构和训练:改进的架构(如新的视觉编码器、对齐的基础LLM)和训练范式(如使用GPT-4V数据进行监督微调、RLHF)可以在一定程度上积极影响模型的可信度。
- 技术局限性:现有技术不足以全面保证可信度,例如,独特视觉编码器的鲁棒性可能在包含在替代模型中时被抵消。
3.4 社会影响和风险
- 社会风险:MLLMs的可信度问题可能对社会产生深远的风险,如传播错误信息、泄露隐私、加剧社会不平等和违反个人权利。
- 风险管理:研究者强调了谨慎使用MLLMs的必要性,以防止其潜在的负面影响。





![【代码随想录】【算法训练营】【第36天】[452]用最少数量的箭引爆气球 [435]无重叠区间 [763]划分字母区间](https://img-blog.csdnimg.cn/direct/29ef6da0cb8246ae8ed6b27c1f0e8585.png)