机器学习简介
目录
- 机器学习简介
- 机器学习的大致分类
- 监督学习 (Supervised learning)
- Regression
- Classification / Predict categories
- 无监督学习 (Unsupervised learning)
- Clustering algorithm
- Anomaly Detection
- Dimensionality Reduction
- 对比总结
- 强化学习 (Reinforcement learning)
- 强化学习(Reinforcement Learning, RL)概述
- 1. 强化学习的核心要素
- 2. 强化学习的典型算法
- (1) 基于价值(Value-Based)的方法
- (2) 基于策略(Policy-Based)的方法
- (3) 基于模型(Model-Based)的方法
- 3. 强化学习的应用场景
- 4. 强化学习 vs 其他机器学习方法
- 机器学习常用术语 (Terminology)
机器学习简介
机器学习:计算机在没有明确编程的情况下学习
机器学习的大致分类
- 监督学习(supervised learning)
- 无监督学习(unsupervised learning)
- 强化学习(Reinforcement learning)
监督学习 (Supervised learning)
特点:learn from data labeled with “right answers”
输入x→输出y
分为两类:回归(regression) 和 分类(classification / predict categories)
Regression
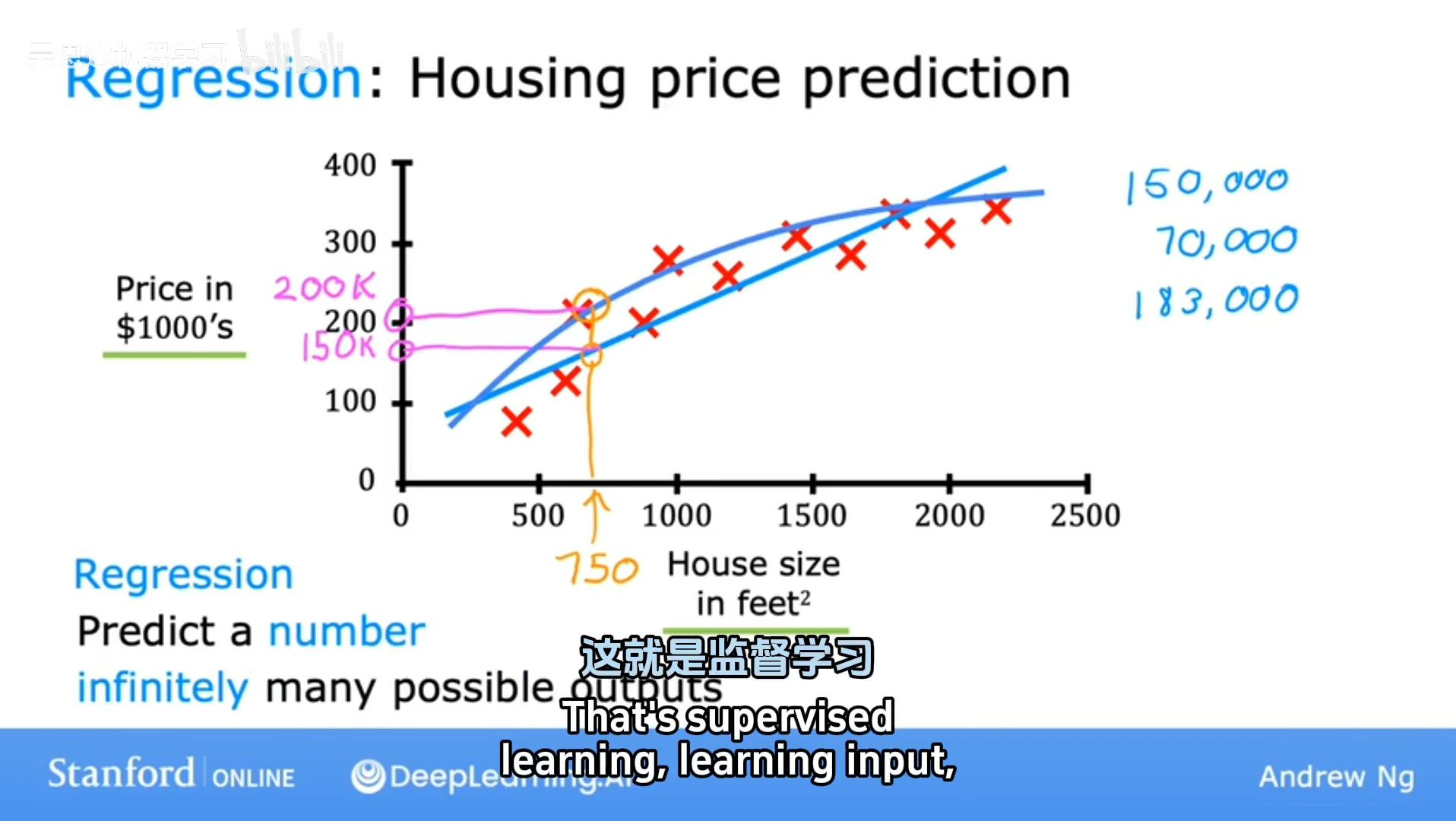
预测无限多个可能的数字中的任意一个
Classification / Predict categories
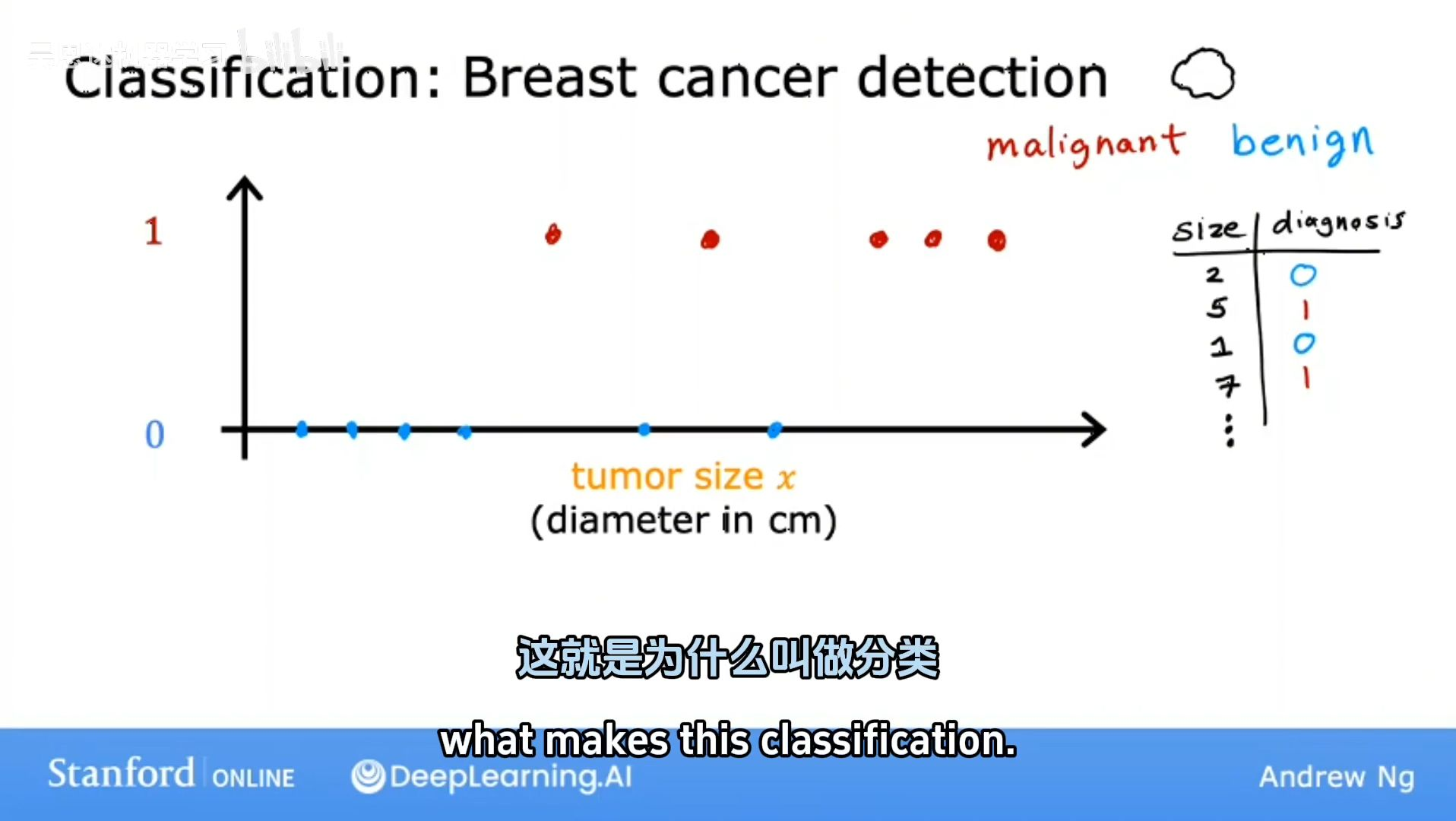
预测输出的结果有限【a small number of possible outputs】
无监督学习 (Unsupervised learning)
特点:not any label
分为 clustering algorithm(聚类算法) anomaly detection(异常检测) dimensionality reduction(降维)

Clustering algorithm
定义:
聚类是一种无监督学习技术,旨在将数据分成若干组(簇),使得同一组内的数据点彼此相似,而不同组之间的数据点差异较大。相似性通常通过距离度量(如欧氏距离、余弦相似度)来定义。
典型算法:
- K-Means:基于中心点的迭代聚类,需预先指定簇数(K)。
- 层次聚类:通过树状图(Dendrogram)构建簇的层次结构,可分聚合(自底向上)或分裂(自顶向下)两种。
- DBSCAN:基于密度的聚类,可识别任意形状的簇并自动剔除噪声点。
- 谱聚类:基于图论,利用数据相似性矩阵的特征向量进行划分。
应用场景:
- 相似内容推送:将用户浏览/购买历史聚类,推荐同一簇中的其他内容(如新闻、商品)。
- 客户画像:根据消费行为、 demographics 等将客户分群,制定精准营销策略。
- 图像分割:将像素点按颜色或纹理聚类,划分图像区域。
Anomaly Detection
定义:
识别数据中明显偏离正常模式的罕见事件或异常点。核心假设是异常数据在特征空间中与正常数据存在显著差异。
常用方法:
- 统计方法:假设数据服从某种分布(如高斯分布),超出阈值(如3σ)视为异常。
- 隔离森林(Isolation Forest):通过随机划分快速隔离异常点(所需划分次数较少)。
- 一类SVM(One-Class SVM):仅用正常数据训练,将边界外的点判为异常。
- 自编码器(Autoencoder):通过重构误差检测异常(异常数据重构误差大)。
应用场景:
- 金融欺诈检测:识别异常交易(如短时间内大额转账)。
- 工业设备监控:传感器数据异常预示故障。
- 网络安全:检测入侵行为(如异常登录IP)。
Dimensionality Reduction
定义:
将高维数据映射到低维空间,保留主要信息的同时减少计算复杂度、避免“维度灾难”。可分为线性和非线性方法。
典型技术:
- PCA(主成分分析):线性方法,通过特征值分解找到方差最大的正交方向(主成分)。
- t-SNE:非线性降维,侧重保留局部相似性,常用于可视化(如将高维数据降至2D/3D)。
- UMAP:类似t-SNE但计算效率更高,保留全局和局部结构。
- 自动编码器(Autoencoder):神经网络通过编码-解码学习紧凑表示。
应用场景:
- 数据可视化:将高维特征(如文本TF-IDF、基因数据)降至2D/3D绘图。
- 特征工程:减少噪声特征,提升模型训练效率(如人脸识别中的PCA降维)。
- 去冗余:消除高度相关的特征(如传感器网络中相似读数)。
对比总结
| 技术 | 核心目标 | 关键特点 | 典型场景 |
|---|---|---|---|
| 聚类算法 | 数据分组 | 无监督、依赖相似性度量 | 客户分群、推荐系统 |
| 异常检测 | 识别离群点 | 处理不平衡数据、需定义正常模式 | 欺诈检测、设备故障预警 |
| 降维 | 压缩数据维度 | 保留主要信息、降低计算成本 | 可视化、特征预处理 |
这些技术常结合使用,例如先用PCA降维再聚类,或在降维后的空间中检测异常。
强化学习 (Reinforcement learning)
强化学习(Reinforcement Learning, RL)概述
强化学习是一种机器学习范式,其核心思想是智能体(Agent)通过与环境的交互学习最优策略(Policy),以最大化累积奖励(Reward)。RL 不同于监督学习(有标签数据)和无监督学习(无明确目标),它通过试错(Trial-and-Error)和延迟奖励(Delayed Reward)进行学习。
1. 强化学习的核心要素
| 要素 | 说明 |
|---|---|
| 智能体(Agent) | 学习的主体,负责做出决策(如游戏AI、自动驾驶系统)。 |
| 环境(Environment) | 智能体交互的外部系统(如游戏世界、股票市场)。 |
| 状态(State) | 环境在某一时刻的描述(如游戏画面、机器人传感器数据)。 |
| 动作(Action) | 智能体在某个状态下可执行的操作(如移动、买入股票)。 |
| 奖励(Reward) | 环境对智能体动作的即时反馈(如得分增加、任务完成)。 |
| 策略(Policy) | 智能体的决策规则,即从状态到动作的映射(如“如果状态A,则执行动作B”)。 |
| 价值函数(Value Function) | 评估长期累积奖励的期望(如当前状态未来能获得多少总奖励)。 |
2. 强化学习的典型算法
强化学习算法可分为:
(1) 基于价值(Value-Based)的方法
- 目标:学习最优价值函数(如Q值),间接推导策略。
- 代表算法:
- Q-Learning:通过更新Q表(状态-动作价值表)学习最优策略。
- Deep Q-Network (DQN):用神经网络近似Q值,解决高维状态问题(如Atari游戏)。
- Double DQN:改进DQN,减少Q值高估问题。
- SARSA:与Q-Learning类似,但采用“在策略(On-Policy)”更新。
(2) 基于策略(Policy-Based)的方法
- 目标:直接优化策略函数(如神经网络),适用于连续动作空间。
- 代表算法:
- REINFORCE:蒙特卡洛策略梯度法,通过采样轨迹更新策略。
- Actor-Critic:结合价值函数(Critic)和策略(Actor),提高稳定性。
- Proximal Policy Optimization (PPO):改进策略梯度,约束更新幅度,防止策略突变。
- Soft Actor-Critic (SAC):引入熵正则化,鼓励探索,适用于复杂任务。
(3) 基于模型(Model-Based)的方法
- 目标:学习环境模型(如状态转移概率),再基于模型规划(Planning)。
- 代表算法:
- Dyna-Q:结合模型学习和Q-Learning。
- Monte Carlo Tree Search (MCTS):用于AlphaGo等博弈AI。
- World Models:用生成模型(如VAE+RNN)模拟环境动态。
3. 强化学习的应用场景
| 领域 | 应用示例 |
|---|---|
| 游戏AI | AlphaGo(围棋)、OpenAI Five(DOTA2)、Atari游戏AI |
| 机器人控制 | 机械臂抓取、四足机器人行走(如波士顿动力) |
| 自动驾驶 | 路径规划、避障决策(如Tesla Autopilot) |
| 金融交易 | 量化交易策略优化(如股票、加密货币自动交易) |
| 推荐系统 | 动态调整推荐策略以最大化用户长期满意度(如YouTube、淘宝) |
| 医疗 | 个性化治疗策略(如调整药物剂量) |
4. 强化学习 vs 其他机器学习方法
| 对比维度 | 强化学习(RL) | 监督学习(SL) | 无监督学习(UL) |
|---|---|---|---|
| 数据需求 | 无需标注数据,依赖环境交互 | 需要大量标注数据 | 无需标注数据 |
| 目标 | 最大化累积奖励 | 最小化预测误差 | 发现数据模式(如聚类) |
| 反馈类型 | 延迟奖励(稀疏、非线性) | 即时误差信号 | 无明确反馈 |
| 典型问题 | 决策优化(如游戏、控制) | 分类、回归 | 降维、生成 |
机器学习常用术语 (Terminology)
Notation:
x:input/input feature/feature(输入特征【相当于变量】)
y:target(目标变量)或label(分类任务中的标签)f:function / model
x − > f − > y ^ x -> f -> \hat{y} x−>f−>y^
x x x : input / input feature
f f f : function / model
y ^ \hat{y} y^ : “y-hat” / prediction / estimated y

( x , y ) (x, y) (x,y) -> single training example
( x ( i ) , y ( i ) ) (x^{(i)}, y^{(i)}) (x(i),y(i)) -> i t h i^{th} ithtraining example